HTTP-based REST APIs are alive and well in the data ecosystem, but they don't always lend themselves streaming applications, especially in the case where a REST API returns state as of a point in time. Such an API doesn't naturally support stateful streaming applications, so, as developers, we need a way to bridge the gap between REST APIs and streaming.
This data integration use case demonstrates how to turn an HTTP-based REST API into a clean, governed, sharable, replayable data stream in Kafka. Once in Kafka, the data can be used to power streaming analytics or other applications that require more than a point-in-time snapshot of state.
In the space of APIs for consuming up-to-date data (say, events or state available within an hour of occurring) many API paradigms exist, for example:
- File- or object-based, e.g., S3 access
- Database access, e.g., direct Snowflake access
- Decoupled client-server APIs, e.g., REST APIs, gRPC, webhooks, and streaming APIs. In this context, "decoupled" means that the client usually communicates with the server over a language-agnostic standard network protocol like HTTP/S, usually receives data in a standard format like JSON, and, in contrast to direct database access, typically doesn't know what data store backs the API.
Of the above styles, more often than not API developers settle on HTTP-based REST APIs for one or more of the following reasons:
- Popularity: more developers know how to use REST APIs and are using them in production compared to other API technologies. E.g., Rapid API's 2022 State of APIs reports 69.3% of survey respondents using REST APIs in production, well above the percentage using alternatives like gRPC (8.2%), GraphQL (18.6%), or webhooks (34.6%).
- Scale: REST's caching and statelessness properties provide a clear path to scale and client performance optimization. REST naturally lends itself to supporting many clients issuing many concurrent requests.
- Maturity: 20+ years of REST API adoption have resulted in a rich tooling ecosystem
- For API development & deployment. E.g., OpenAPI and its tool for generating client bindings, API management solutions like Kong Konnect to handle security and rate limiting.
- For API consumption. E.g., Postman for learning and testing APIs, and mature client libraries like Python Requests for building applications that leverage REST APIs.
- Verb flexibility: while we are talking about reading up-to-date data in this demo, many applications also need to create, update, and delete data too! HTTP-based REST services can use the same tools to develop and deploy all of the verbs. Some of the API patterns above like streaming are really only geared toward reading. While some mature engineering organizations offer APIs that span API styles (e.g., X exposes streaming and REST APIs), doing so comes at higher cost.
Regardless of why data is exposed via REST API, the bottom line is:
As application developers, we don't always get to choose how to consume data. We have to use what API providers offer, and, more often than not, they give us REST APIs.
We'll use the OpenSky Network's live API to demonstrate the REST-to-streaming use case. The API exposes live information about aircraft in a way that is typical of many REST APIs:
- JSON-based REST API (there are also Python and Java clients exposing the REST API)
- The data returned is state rather than discrete events. For example, the State Vectors method that this demo builds on returns aircraft state (e.g., location, altitude, and speed) as of the time of the request.
- The data needs a bit of massaging and cleaning. In the case of this demo, adding schema and cleaning string fields are a couple of the ways that the data is shaped and cleaned on its way to becoming a Kafka-based stream.
The following steps and tools are required to run this demo:
- Clone this repo if you haven't already:
git clone https://github.com/confluentinc/demo-scene
- A Confluent Cloud account. Sign up for a free trial if you don't already have one.
- The Confluent CLI. Refer to the installation instructions here.
- The
confluent-flink-quickstartCLI plugin. This plugin spins up the Kafka and Flink resources in Confluent Cloud that are needed for this demo. Install the plugin by running:confluent plugin install confluent-flink-quickstart
- Review the OpenSky Network's terms of use.
We will use the Confluent CLI to provision the Confluent Cloud resources used in this demo.
First, login via the CLI
confluent login --prompt --saveNext, run the following command to spin up a Kafka cluster and Flink compute pool in Confluent Cloud:
confluent flink quickstart \
--name http-streaming \
--max-cfu 10 \
--region us-east-1 \
--cloud awsThe command will run for about a minute and drop you into an interactive Flink shell.
Once you're in the Flink shell, run your first Flink SQL statement to see what Flink SQL tables exist. In the Flink shell:
show tables;Since we don't have any data in the system yet, you will see the message:
The server returned empty rows for this statement.
Don't worry! This is expected since we haven't produced any data into the system yet.
Run the http-streaming/scripts/create-connector.sh script included in this repository to provision an HTTP Source Connector in Confluent Cloud. The script will complete in a few seconds, and then the resulting connector will need a minute or so to be provisioned.
Note the following connector configurations in the script:
-
We specify that we are polling the OpenSky Network's All State Vectors method in the
urlproperty:"url": "https://opensky-network.org/api/states/all" -
For the purposes of demo, we limit the flight data that we are interested in to a small bounding box containing Switzerland. The box is defined by a point in Boussy, France on the bottom left and Aitrang, Germany on the top right:
"http.request.parameters": "lamin=45.8389&lomin=5.9962&lamax=47.8229&lomax=10.5226"Here is a sketch of the box defined by these points:

-
The
request.interval.msproperty specifies how often we should poll the API:"request.interval.ms": "60000"Let's take a brief sidetrack on the polling interval to pick for a use case like this. For demo purposes, we poll every minute without giving the decision too much thought since we'll stop the connector once we're done. In choosing how often to scrape in a production setting, though, there are a few points to consider:
- The REST API's rate limit. E.g., in the OpenSky case, the documentation here specifies that anonymous users get 400 API credits per day, and users get 4000 credits per day. The credit cost of an API call to the
/states/allendpoint depends on the size of the area for which states are being requested. In our case, we are polling(47.8229 - 45.8389) * (10.5226 - 5.9962) = ~9square degrees, so each API call costs 1 credit. If you were an OpenSky user getting 4,000 credits per day, you would be able to poll as frequently as once every ~22 seconds while remaining under the rate limit (86,400 seconds per day, divided by 4,000, yields an API call every 21.6 seconds to exactly use up 4,000 credits in a day). - Understand data provider time granularity. E.g., if you are an anonymous OpenSky user, see that you can only retrieve data with a time resolution of 10 seconds. In other words, there would be no point in polling more frequently than every 10 seconds. This documented time resolution lower bounds the polling intervals we should consider.
- Infrastructure cost, in particular, understand the variable costs that will fluctuate based on how often you poll (e.g., Kafka cluster and connector network I/O, data storage). In the case of Confluent Cloud, you can estimate your cost and also validate the exact cost by running the connector for a few days and visiting the
Billing & paymentpage in the Confluent Cloud Console. By isolating the use case to an environment, you can view all infrastructure costs tied to that environment, e.g.: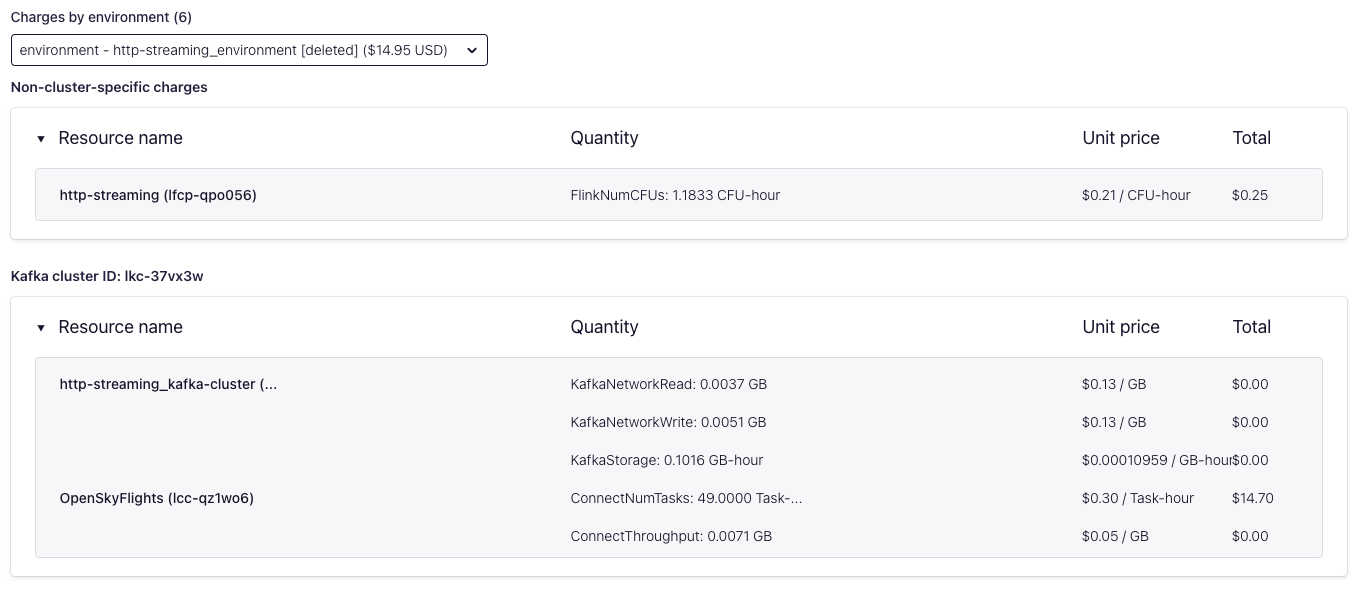
- Understand the impact of polling frequency on your use case, the requirements, and the space where trade offs are on the table. Any "live" or "real-time" apps would likely benefit from frequent polling, but it's not always true that more data more often is better. If you were building a model to predict flight delays based on aircraft position, perhaps polling every 5 minutes rather than every 30 seconds would be more than sufficient and be a sensible way to trade off data freshness for cost savings.
- The REST API's rate limit. E.g., in the OpenSky case, the documentation here specifies that anonymous users get 400 API credits per day, and users get 4000 credits per day. The credit cost of an API call to the


Before we explore the flight data, check that the connector is up and running. In the Confluent Cloud Console, select Environments in the lefthand navigation, and click the http-streaming_environment environment:

Next, click the http-streaming_kafka-cluster tile to go to the cluster detail page:

Finally, select Connectors in the lefthand navigation, and validate that the OpenSkyFlights connector is Running:

Now let's explore the data populated by the connector in more detail. We'll use Flink SQL for this. Return to the Flink SQL shell that the confluent-flink-quickstart plugin opened for you. If you closed out of the shell and need to reopen a session, you can copy the command to get back to it from the Confluent Cloud Console:
- Select the
http-streaming_environmentenvironment - Click the
Flinktab - At the bottom of the
http-streamingcompute pool tab is a command that you can copy to start the Flink shell:

In the Flink shell, first run the same SHOW TABLES; command that you ran previously. This time you can see that there is now an all_flights table automatically available:
+-------------+
| table name |
+-------------+
| all_flights |
+-------------+
Let's describe the table:
DESCRIBE all_flights;This shows three columns:
+-------------+-------------------------------+----------+------------+
| Column Name | Data Type | Nullable | Extras |
+-------------+-------------------------------+----------+------------+
| key | BYTES | NULL | BUCKET KEY |
| time | INT | NOT NULL | |
| states | ARRAY<ARRAY<STRING> NOT NULL> | NOT NULL | |
+-------------+-------------------------------+----------+------------+
And query the table:
SELECT * FROM all_flights;An example row looks like this:
key time states ║
NULL 1710358279 [[4b1803, SWR736 , Switzerland, 1710358141, 1710358237, 8.5569, 47.4543, 373.38, true, 0, 185.62, NULL, NULL, NULL, 1000, false, 0], ...]
It's worth noting that this reflects the data as it's returned via API. Calling the API directly:
curl -s "https://opensky-network.org/api/states/all?lamin=45.8389&lomin=5.9962&lamax=47.8229&lomax=10.5226"We can see the same array of arrays containing codes and numbers. The states field doesn't have a self-documenting schema and the data isn't as clean as it could be, e.g., the second column in each inner array is right-padded with spaces:
{
"time":1710361210,
"states":[
["4b1817","SWR4TH ","Switzerland",1710361210,1710361210,8.1462,47.3854,3931.92,false,188.81,233.75,9.75,null,4038.6,"1000",false,0],
["4b1806","SWR6MZ ","Switzerland",1710361210,1710361210,8.5502,47.4551,null,true,8.23,149.06,null,null,null,"1000",false,0],
["4b1620","SWR829 ","Switzerland",1710361210,1710361210,8.5914,47.4551,487.68,false,75.05,276.3,-4.55,null,594.36,"1000",false,0],
...
]
}
In the next section we will get this data into a more usable format.
Before we can shape and cleanse the data, let's list the issues that we need to address:
- For each row in the
all_flightstable, thestatescolumn represents all aircraft in the given bounding box. We should convert this so that each aircraft gets its own record. - Rather than have a single array column whose values require documentation to understand, let's introduce a more intuitive schema. For example, instead of needing to know that the second member of each array is the aircraft's call sign, let's have an independent column called
callsignfor this field. - Let's trim any whitespace padding from the values. E.g., the aforementioned
callsignfield.
We'll start by defining the table schema. Run this statement in the Flink SQL interactive shell:
CREATE TABLE all_flights_cleansed (
poll_timestamp TIMESTAMP_LTZ(0),
icao24 STRING,
callsign STRING,
origin_country STRING,
event_timestamp TIMESTAMP_LTZ(0),
longitude DECIMAL(10, 4),
latitude DECIMAL(10, 4),
barometric_altitude DECIMAL(10, 2),
on_ground BOOLEAN,
velocity_m_per_s DECIMAL(10, 2)
);Now, run the following insert from select statement to populate the table:
INSERT INTO all_flights_cleansed
SELECT TO_TIMESTAMP_LTZ(`time`, 0) AS poll_timestamp,
RTRIM(StatesTable.states[1]) AS icao24,
RTRIM(StatesTable.states[2]) AS callsign,
RTRIM(StatesTable.states[3]) AS origin_country,
TO_TIMESTAMP_LTZ(CAST(StatesTable.states[4] AS NUMERIC), 0) AS event_timestamp,
CAST(StatesTable.states[6] AS DECIMAL(10, 4)) AS longitude,
CAST(StatesTable.states[7] AS DECIMAL(10, 4)) AS latitude,
CAST(StatesTable.states[8] AS DECIMAL(10, 2)) AS barometric_altitude,
CAST(StatesTable.states[9] AS BOOLEAN) AS on_ground,
CAST(StatesTable.states[10] AS DECIMAL(10, 2)) AS velocity_m_per_s
FROM all_flights CROSS JOIN UNNEST(all_flights.states) as StatesTable (states);The INSERT query will continue to run, so press Enter to detach from the query and return to the prompt.
Note the following data shaping and cleansing aspects of the query:
- We expand the
statesarray in each row of theall_flightstable into new rows, one per array element, by performing a cross join against theUNNEST'ing of thestatesarray. - The two timestamp fields (one for the poll time and one for the reported event time) are converted from Unix epoch longs to
TIMESTAMP_LTZtimestamps. - String, numeric, and boolean fields are typecast accordingly, with string fields
RTRIM'ed to remove any whitespace padding on the right.
As a final step, let's look at the cleansed table. Enter the following query:
SELECT * FROM all_flights_cleansed;Check out how clean and self-documented the results are:
╔═════════════════════════════════════════════════════════════ Table mode (a31da41b-1e5f-46fd) ══════════════════════════════════════════════════════════════╗
║poll_timestamp icao24 callsign origin_country event_timestamp longitude latitude barometric_altitude on_ground velocity_m_per_s ║
║2024-03-28 09:36:07.000 4b44a5 HBZZX Switzerland 2024-03-28 09:33:01.000 7.3174 46.8865 777.24 FALSE 0.51 ║
║2024-03-28 09:36:07.000 4b44a1 HBZZT Switzerland 2024-03-28 09:35:14.000 8.8307 46.0071 685.80 FALSE 15.75 ║
║2024-03-28 09:36:07.000 400be5 EFW4TM United Kingdom 2024-03-28 09:36:06.000 6.3243 47.7256 10980.42 FALSE 207.06 ║
║2024-03-28 09:36:07.000 4ca245 RYR98TM Ireland 2024-03-28 09:36:07.000 6.5541 47.0935 11582.40 FALSE 231.68 ║
║2024-03-28 09:36:07.000 4b4414 AG06 Switzerland 2024-03-28 09:33:02.000 7.0247 46.3718 2103.12 FALSE 48.61 ║
║2024-03-28 09:36:07.000 4b4437 HBZVR Switzerland 2024-03-28 09:31:22.000 8.9497 46.0789 1112.52 FALSE 28.01 ║
║2024-03-28 09:36:07.000 4b4430 HBZVK Switzerland 2024-03-28 09:36:06.000 7.7009 47.2274 982.98 FALSE 19.10 ║
║2024-03-28 09:36:07.000 4b443e HBZVY Switzerland 2024-03-28 09:36:07.000 8.9621 46.0086 449.58 FALSE 1.03 ║
║2024-03-28 09:36:07.000 3949e6 AFR292 France 2024-03-28 09:36:07.000 10.1409 47.4019 10058.40 FALSE 302.59 ║
║2024-03-28 09:36:07.000 3949f7 AFR258 France 2024-03-28 09:36:07.000 9.8573 47.4518 10058.40 FALSE 296.96 ║
║2024-03-28 09:36:07.000 4b42f1 LAS7 Switzerland 2024-03-28 09:36:00.000 8.5554 47.2131 1127.76 FALSE 59.05 ║
║2024-03-28 09:36:07.000 4d221e RYR4XY Malta 2024-03-28 09:36:07.000 8.5341 47.0279 9197.34 FALSE 200.56 ║
║2024-03-28 09:36:07.000 4d2269 RYR63SG Malta 2024-03-28 09:36:06.000 6.2707 47.3113 11277.60 FALSE 206.81 ║
║2024-03-28 09:36:07.000 4d2261 RYR1GW Malta 2024-03-28 09:36:06.000 8.6701 46.1185 11285.22 FALSE 224.19 ║
║2024-03-28 09:36:07.000 3e2285 DIEGR Germany 2024-03-28 09:36:06.000 7.7209 47.4407 9448.80 FALSE 90.79 ║
║2024-03-28 09:36:07.000 4b3021 HBSFX Switzerland 2024-03-28 09:36:07.000 8.8216 47.1857 1318.26 FALSE 28.83 ║
║2024-03-28 09:36:07.000 4b4394 HBZPK Switzerland 2024-03-28 09:36:07.000 8.8202 47.5005 1066.80 FALSE 47.37 ║
║2024-03-28 09:36:07.000 3c4dc5 DLH5XA Germany 2024-03-28 09:36:07.000 7.8554 47.7511 5036.82 FALSE 175.94 ║
║2024-03-28 09:36:07.000 4b18fe EDW32G Switzerland 2024-03-28 09:36:07.000 6.0168 47.7456 9144.00 FALSE 195.26 ║
║2024-03-28 09:36:07.000 39856b AFR29NT France 2024-03-28 09:36:06.000 8.3028 47.7225 10668.00 FALSE 266.39 ║
║2024-03-28 09:36:07.000 300327 PROVA22 Italy 2024-03-28 09:36:07.000 8.5401 45.9050 655.32 FALSE 43.96 ║
║2024-03-28 09:36:07.000 4b3a10 PCH506 Switzerland 2024-03-28 09:36:06.000 8.4421 46.9879 1386.84 FALSE 95.53 ║
║2024-03-28 09:36:07.000 47bfb3 NSZ1KS Norway 2024-03-28 09:36:07.000 8.6562 47.7841 10972.80 FALSE 272.38 ║
║2024-03-28 09:36:07.000 4b1901 EDW6 Switzerland 2024-03-28 09:36:06.000 7.8113 47.4552 4259.58 FALSE 171.69 ║
╚════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝Since you created all resources in a Confluent Cloud environment, you can simply delete the environment and all resources created for this demo will be deleted (i.e., the Kafka cluster, connector, Flink compute pool, and associated API keys). Run the following command in your terminal to get the environment ID of the form env-123456 corresponding to the environment named http-streaming_environment:
confluent environment listNow delete the environment:
confluent environment delete <ENVIRONMENT_ID>The demo in this repository connects to data provided by the OpenSky Network originally published in:
Bringing up OpenSky: A large-scale ADS-B sensor network for research Matthias Schäfer, Martin Strohmeier, Vincent Lenders, Ivan Martinovic, Matthias Wilhelm ACM/IEEE International Conference on Information Processing in Sensor Networks, April 2014