本笔记为阿里云天池龙珠计划Python训练营的学习内容,链接为:https://tianchi.aliyun.com/specials/promotion/aicamppython

- 2022 年 02 月 14 日版本
- 本文档是以 CC 开源的模式的发布,你能且将获得本文档的 PDF 版本已经 Jupyter Notebook 版本
- 本文档并不申明自己的版权信息,为了更好的知识传播,我们授权你使用本文档,你可以使用它,进行二次创作,进行分发,进行修改,并可以以此为蓝本进行授课。
- 请保留本文档的原始来源。
- 本文档首先在国际人学校组织的“阿里云天池 Python 训练营课程”中使用。
- 本文档由林肯老师首次组织和编辑。你可以通过网址 数据大咖 找到他。


- 在塔尖,第一种学习方式——“听讲”,也就是老师在上面说,学生在下面听,这种我们最熟悉最常用的方式,学习效果却是最低的,两周以后学习的内容只能留下 5%。
- 第二种,通过“阅读”方式学到的内容,可以保留 10%。
- 第三种,用“声音、图片”的方式学习,可以达到 20%。
- 第四种,是“示范”,采用这种学习方式,可以记住 30%。
- 第五种,“小组讨论”,可以记住 50% 的内容。
- 第六种,“做中学”或“实际演练”,可以达到 75%。
- 最后一种在金字塔基座位置的学习方式,是“教别人”或者“马上应用”,可以记住 90% 的学习内容。
爱德加·戴尔提出,学习效果在 30% 以下的几种传统方式,都是个人学习或被动学习;而学习效果在 50% 以上的,都是团队学习、主动学习和参与式学习。
字符串是 Python 中常见的一种数据类型。字符串切片就是截取字符串。在 Python 中,可以利用字符串的切片特性进行提取、拆分、合并等操作,但不能对字符串进行修改。
单字符切片是对字符串中指定位置的单个字符进行截取。语法结构为:字符串[索引位置], 索引位置的序号是从 0 开始的。关于索引位置,既能以开头为基准进行切片,也能以结尾为基准进行切片。
txt='Python与Excel' #要做切片处理的字符串。
print(txt[0],txt[1],txt[2]) #索引位置以开头为基准切片,返回值 'P y t'。
print(txt[-1],txt[-2],txt[-3]) #索引位置以结尾为基准切片,返回值 'l e c'。如果截取的不是单个字符,而是多个字符,则切片的语法结构为:字符串[开始索引:结束索引:步长]。多字符截取有几种常见的切片方式。
txt='Python与Excel' #要做切片处理的字符串。
print(txt[2:9]) #以开头为基准切片,返回值为 'thon 与 Ex'。
print(txt[-10:-3])# 以结尾为基准切片,返回值为 'thon 与 Ex'。
print(txt[:7]) #以开头为基准切片,返回值为 'Python 与'。
print(txt[:-5])# 以结尾为基准切片,返回值为 'Python 与'。
print(txt[7:]) #以开头为基准切片,返回值为 'Excel'。
print(txt[-5:])# 以开头为基准切片,返回值为 'Excel'。
print(txt[2:-5])# 开始索引以开头为基准,结束索引以结尾为基准,返回 'thon 与'。
print(txt[-10:7])# 开始索引以结尾为基准,结束索引以开头为基准,返回 'thon 与'。
print(txt[:])# 截取整个字符串切片,返回值为 'Python 与 Excel'。
print(txt[::2])# 截取整个字符串切片,步长为 2,返回值为 'Pto 与 xe'。
print(txt[::-1])# 截取整个字符串切片,步长为 -1,返回值为 'lecxE 与 nohtyP'。
print(txt[::-2])# 截取整个字符串切片,步长为 -2,返回值为 'lcEnhy'。本案例对员工信息表中 B 列的身份证号进行性别判断。在 18 位身份证号中判断第 17 位数字,在 15 位身份证号中判断第 15 位数字。如果数字是奇数,则性别为男;如果数字是偶数,则性别为女。
本案例的编程思路是,使用字符串切片从身份证号的第 15 位开始截取到第 17 位,再截取最后一位数字。这样不管身份证号是 15 位,还是 18 位,最终都截取到了要判断性别的数字,之后的数据处理就比较容易了。
import xlrd,xlwt #导入所需库。
wb = xlrd.open_workbook('./6-ID-1.xls') #读取工作簿。
ws = wb.sheet_by_name('员工信息表') #读取工作表。
nwb = xlwt.Workbook('utf-8') #新建工作簿。
nws = nwb.add_sheet('员工信息表-1') #新建工作表。
nws.write(0,0,'姓名') #在表头写入 '姓名'。
nws.write(0,1,'身份证号') #在表头写入 '身份证号'。
nws.write(0,2,'性别') #在表头写入 '性别'。
row_num = 0 #初始化 row_num 变量为 0。
while row_num < ws.nrows-1: #当 row_num 小于 '员工信息表' 已用行数时,开始循环。
row_num += 1 #累加 row_num 变量。
card = ws.cell_value(row_num,1) #获取单元格的身份证号信息。
sex_num = int(card[14:17][-1]) #截取判断性别的数字。
sex = '男' if sex_num % 2 == 1 else '女' #根据数字判断性别。
name = ws.cell_value(row_num,0) #获取姓名。
nws.write(row_num,0,name) #将姓名写入新工作表中的 A 列单元格。
nws.write(row_num,1,card) #将身份证号写入新工作表中的 B 列单元格。
nws.write(row_num,2,sex) #将性别写入新工作表中的 C 列单元格。
nwb.save('./6-ID-2.xls') #保存新建的工作簿。- 第 1~9 行代码都是在为数据的读取和写入做准备。
- 第 13 行代码 sex_num=int(card[14:16][-1])是性别判断的关键语句。首先截取第 15~17 位数字,然后截取最右侧的数字。
- 比如,对 18 位身份证号进行截取,'230102********7789[14:16]的截取结果为“778”,然后执行语句'778'[-1], 截取结果为“8”。
- 再比如,对 15 位身份证号进行截取,'632123******051'[14:17]的截取结果为“1”,然后执行语句'1'[-1], 截取结果为“1”。这样对 18 位身份证号和 15 位身份证号都能截取到判断性别的数字,再使用 int 函数将其转换为整数。
- 第 14 行代码 sex='男' if sex_num%2==1 else '女', 对存储性别数字的 sex_num 变量除以 2 求奇偶,然后根据奇偶做性别判断。
- 第 16~18 行代码是将信息写入新工作簿中的新工作表。
- 第 19 行代码是保存新工作簿。
有时需要统计字符串的一些信息,比如统计字符串长度、统计指定子字符串在父字符串中出现的次数等。
统计字符串、列表、元组等对象的长度或项目个数,可以使用 len 函数。
函数语法:len(s)
参数说明:
s: 参数可以是序列,例如字符串、元组、列表、字典、集合等。
例如,统计字符串 'Python' 的长度。
print('Python',len('Python')) #返回 'Python 6'。统计指定子字符串在父字符串中出现的次数,可以使用 count 函数。
函数语法:count(sub[,start[,end]])
参数说明:
- sub: 必选参数,搜索的子字符串。
- start: 可选参数,字符串开始搜索的位置,默认从第 0 个字符开始搜索。
- end: 可选参数,字符串结束搜索的位置,默认搜索到字符串最后。
例如,在 '张三19, 李四, 张三9, 林林6, 张三12, 李四8' 字符串中搜索关键词“张三”。
txt='张三19, 李四, 张三9, 林林6, 张三12, 李四8'# 被查找的字符串。
print(txt.count('张三'))# 返回值为 3。
print(txt.count('张三',4))# 返回值为 2。
print(txt.count('张三',4,13))# 返回值为。- 第 2 行代码 print(txt.count('张三')), 是在整个字符串中搜索“张三”,该字符串中有 3 个“张三”,所以返回值为 3。
- 第 3 行代码 print(txt.count('张三',4)), 是从字符串的第 4 个位置开始搜索到最后,也就是在字符串,'李四, 张三 9, 林林 6, 张三 12, 李四 8' 中搜索“张三”,该字符串中有 2 个“张三”,所以返回值为 2。
- 第 4 行代码 print(txt.count('张三',4,13)), 是从字符串的第 4 个位置开始搜索到第 13 个位置,也就是在字符串,'李四, 张三9, 林' 中搜索“张三”,该字符串中只有 1 个“张三”,所以返回值为 1。
本案例统计分数表中每个人获得优、良、中、差的次数,将结果写入 C 列单元格,如图所示。
本案例的编程思路是将 4 个等级作为搜索关键字在每个单元格中进行计数,然后将每个等级的计数结果写入 C 列。

import xlrd #导入读取 xls 文件的库。
from xlutils.copy import copy #导入复制工作簿的函数。
wb = xlrd.open_workbook('./7-ScoreAnalists-1.xls') #读取工作簿。
ws = wb.sheet_by_name('分数表') #读取工作表。
nwb = copy(wb) #复制工作簿产生一个副本。
nws = nwb.get_sheet('分数表') #读取副本工作簿中的工作表。
row_num = 0 #初始化 row_num 变量为 0。
txt = '' #初始化 txt 变量为空。
while row_num<ws.nrows-1: #当 row_num 变量小于已使用单元格区域行数时。
row_num += 1 #则对 row_num 变量累加 1。
score = ws.cell_value(row_num,1) #获取 B 列单元格的值。
for level in '优良中差': #循环 '优良中差'4 个等级。
lev_sco = '{}:{}\t'.format(level,score.count(level)) #统计每个级别的个数,并进行格式化。
txt += lev_sco #累积连接各等级数量。
nws.write(row_num,2,txt) #将统计结果写入 C 列单元格。
txt = '' #重新初始化 txt 变量,便于存储下个单元格各等级的统计结果。
nws.write(0,2,'等级统计') #在 C 列写入表头。
nwb.save('./7-ScoreAnalists-1.xls') #保存副本工作簿。- 第 1~8 行代码为读取工作表数据和写入工作表做准备。
- 第 10 行和第 11 行代码用于获取单元格的值。
- 第 12~14 行代码循环判断每个等级在单元格中出现的次数,关键语句是 score.count(level), 并且使用 txt+=lev_sco 来累计各等级出现的次数。
- 第 15 行和第 16 行代码用来写入统计结果与重新初始化。nws.write(row_num,2,txt)是将 txt 变量中的统计结果写入副本工作簿中工作表的 C 列。txt='' 用于重新初始化 txt 变量。
- 第 17 行和第 18 行代码用来在 C 列写入表头和保存工作簿。
搜索指定子字符串在父字符串中第一次出现的位置,可以使用 index 函数或 find 函数。
index 函数用于从字符串中找出子字符串第一个匹配项的索引位置,如果查找的字符串不存在,则返回错误提示。
函数语法:index(sub[,start[,end]])
参数说明:
- sub: 必选参数,搜索的子字符串。
- start: 可选参数,字符串开始搜索的位置,默认从第 0 个字符开始搜索。
- end: 可选参数,字符串结束搜索的位置,默认搜索到字符串最后。
例如,在字符串 '张三 19, 李四, 张三 9, 林林 6, 张三 12, 张三 8' 中搜索关键词“张三”。
txt='张三 19, 李四, 张三 9, 林林 6, 张三 12, 张三 8'# 被查找的字符串。
print(txt.index('张三'))# 返回值为 0。
print(txt.index('张三',18))# 返回值为 21。
print(txt.index('张三',6,16))# 返回值为 8。- 第 2 行代码 print(txt.index(' 张三)), 是在整个字符串中搜索“张三”第 1 次出现的位置,返回值为 3。
- 第 3 行代码 print(txt.index('张三',18)), 是从字符串的第 18 个位置开始搜索“张三”第 1 次出现的位置,返回值为 21。
- 第 4 行代码 print(txt.count('张三',6,16)), 是在字符串的第 6 个位置到第 16 个位置中搜索“张三”第 1 次出现的位置,返回值为 8。
find 函数用于从父字符串中找出某个子字符串第一个匹配项的索引位置,该函数的功能与 index 函数的功能一样,只不过子字符串不在父字符串中时不会报异常,而是返回 -1。
函数语法:find(sub[,start[,end]])
参数说明:
- sub: 必选参数,搜索的子字符串。
- start: 可选参数,字符串开始搜索的位置,默认从第 0 个字符开始搜索。
- end: 可选参数,字符串结束搜索的位置,默认搜索到字符串最后。
例如,在字符串 'Python' 中搜索 'Excel',分别使用 find 函数和 index 函数,代码如下所示。
print('Python'.find('Excel'))# 查找不到返回 -1。
print('Python'.index('Excel'))# 查找不到返回错误提示。- 第 1 行代码 print('Python'.find('Excel')), 当使用 find 函数搜索不到时,返回 -1。
- 第 2 行代码 print('Python'.index('Excel')), 当使用 index 函数搜索不到时,返回错误提示。提示错误为“ValueError: substring not found”,表示未找到子字符串
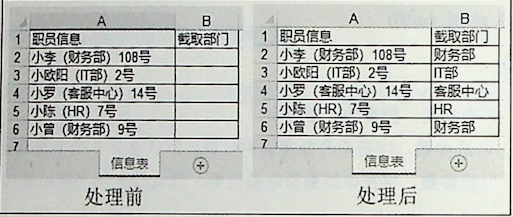
本案例截取信息表中 A 列的部门信息,将截取结果写入 B 列对应的单元格中,如图所示。
本案例的编程思路是首先获取“(”和“)”的位置,然后使用字符串切片的方法截取两个位置之间的字符串。
import xlrd #导入读取 xls 文件的库。
from xlutils.copy import copy #导入工作簿复制函数。
wb = xlrd.open_workbook('./8-Departments-1.xls') #读取工作簿。
ws = wb.sheet_by_name('信息表') #读取工作表。
nwb = copy(wb) #复制工作簿产生一个副本。
nws = nwb.get_sheet('信息表') #读取副本中的工作表。
row_num = 0 #初始化 row_num 变量为 0。
while True: #条件为 True,表示会一直循环,在循环中做终止循环处理。
row_num += 1 #对 row_num 变量累加 1。
if row_num > ws.nrows-1: #当 row_num 变量大于已使用单元格区域行数时。
break #则终止循环。
info = ws.cell_value(row_num, 0) #获取 A 列单元格的值。
strat = info.find('(')+1 #搜索 '(' 的位置,应该从 '(' 之后,所以最后要加 1。
end = info.find(')') #搜索 ')' 的位置。
dept = info[strat:end] #截取 A 列单元格 '(' 和 ')' 之间的部门信息。
nws.write(row_num,1,dept) #将截取到的部门信息写入 B 列单元格。
nwb.save('./8-Departments-1.xls') #保存工作簿。- 第 1~7 行代码为读取工作表数据和写入工作表做准备。
- 第 8 行代码开始循环读取单元格。
- 第 9~16 行代码是循环体中的处理语句。
- 第 10 行和第 11 行代码用来终止循环。
- 第 12~16 行代码首先获取单元格的值,再获取“(”和“)”的索引位置,然后截取部门信息,最后将部门信息写入副本工作簿中工作表 B 列对应的单元格。
- 第 17 行代码保存工作簿副本。
字符串替换的本质就是有条件地对字符串进行修改。前面不是说过字符串是只读属性,不能修改吗?实际上,替换后的字符串内存地址已经不是替换前的字符串内存地址,也就是说,并没有修改替换前的字符串,替换后生成了一个新的字符串。
replace 函数用于把字符串中指定的旧字符串替换成指定的新字符串,默认全部替换。
函数语法:replace(old,new[,count])
参数说明:
- old: 必选参数,被替换的旧字符串。
- new: 必选参数,新字符串,用于替换旧字符串。
- count: 可选参数,替换的次数,默认替换所有出现的旧字符串。
例如,将字符串 'A组-优秀;B组-良好;C组-优秀;D组-优秀' 中的“优秀”替换为“晋级”。
txt='A组-优秀;B组-良好;C组-优秀;D组-优秀' #被替换的字符串。
print(txt.replace('优秀','晋级')) #将所有 '优秀' 替换为 '晋级'。
print(txt.replace('优秀','晋级',1)) #将前 1 个 '优秀' 替换为 '晋级'。
print(txt.replace('优秀','晋级',2)) #将前 2 个 '优秀' 替换为 '晋级'。- 第 2 行代码 print(txt.replace('优秀','晋级')), 如果不指定第 3 个参数,则默认将所有的“优秀”替换为“晋级”,替换结果为 'A组-晋级;B组-良好;C组-晋级;D组-晋级'。
- 第 3 行代码 print(txt.replace('优秀','晋级',1)), 如果指定第 3 个参数为 1,则表示将第 1 个“优秀”替换为“晋级”,替换结果为 'A组 - 晋级;B组-良好;C组-优秀;D组-优秀。
- 第 4 行代码 print(txt.replace('优秀','晋级',2)), 如果指定第 3 个参数为 2,则表示将前两个“优秀”替换为“晋级”,替换结果为 'A组-晋级;B组-良好;C组-晋级;D组-优秀。
字符串的拆分与合并可以使用字符串切片的方法来完成,但字符太多就不方便了,表达也不够简洁、灵活。本小节讲解使用 split 函数和 join 函数来完成字符串的拆分与合并。
split 函数用于拆分字符串,可以指定分隔符对字符串进行切片,并返回拆分后的字符串列表。
函数语法:split([sep] [,maxsplit])
参数说明:
- sep: 可选参数,表示分隔符,默认为空格(''), 但是不能为空(") 。分隔符可以是单个字符,也可以是多个字符。如果是多个字符,则被看作一个整体。
- maxsplit: 可选参数。表示要执行的最大拆分数。-1(默认值)表示无限制。例如,对字符串 '10 20 50' 和 '78|98|100' 进行拆分。
print('10 20 50'.split()) #默认以 ' ' 进行拆分。
print('10 20 50'.split('|')) #指定的拆分符号在字符串中不存在。
print('78|98|100'.split('|')) #指定的拆分符号在字符串中存在。
print('78|98|100'.split('|',1)) #指定拆分个数。- 第 1 行代码 print('10 20 50'.split()), 对字符串'10 20 50'进行拆分,由于 split 函数中没有指定任何参数,所以默认以空格对整个字符串进行拆分,返回值为['10','20','50']。
- 第 2 行代码 print('10 20 50'.split('|')), 对字符串 '10 20 50' 按分隔符“I”进行拆分,由于字符串中并不存在“I”,因此返回的结果不是字符串,而是列表['102050'],列表中只有一个元素 '10 20 50'。
- 第 3 行代码 print('78|98|100'.split('|')), 对字符串 '78|98|100' 按分隔符“I”进行拆分,返回值为['78','98','100']。
- 第 4 行代码 print('78|98|100'.split('|',1)), 对字符串 '78|98|100' 按分隔符“I”进行拆,split 函数的第 2 个参数 1 表示只拆分到第 1 次出现的“I”,因此返回值为['78','98|100']。
前面通过 split 函数将字符串拆分成列表,列表中存储的是拆分出来的子字符串。现在要反向操作,将列表中的子字符串合并成一个大的字符串,可以使用 join 函数来完成。
函数语法:join(iterable)
参数说明: Iterable: 必选参数,可以是列表、元组等可迭代对象,但其中的值只能为字符串,不能是其他数据类型。
例如,以“-”为分隔符对列表['张三',18',' 财务部]进行合并。
print('-'.join(['张三','18','财务部'])) #返回 '张三-18-财务部'。列表用中括号 ([]) 表示,列表里的元素用逗号分隔。下面介绍列表的创建和删除。
lst1 = [];print(lst1) #创建空列表方法 1。
lst2 = list();print(lst2) #创建空列表方法 2。
lst3 = [1,2,3];print(lst3) #创建多个元素的列表。
lst3.clear();print(lst3)# 清空列表中的所有元素。
del lst3 #删除列 lst3 列表。- 第 1 行代码 lst1=[],使用一对空的中括号创建空列表。运行 print(lst1)后,在屏幕上输出结果[]。
- 第 2 行代码 lst2=list(),使用 list 类创建一个空列表,运行 print(lst2)后,在屏幕上输出结果[]。
- 第 3 行代码 lst3=[1,2,3], 创建有多个元素的列表,运行 print(lst3)后,在屏幕上输出结果[1,2,3]。
- 第 4 行代码 Ist3.clear(),清空 lst3 列表中的所有元素,运行 print(lst3)后,在屏幕上输出结果[]。
- 第 5 行代码 del lst3,使用 del 语句删除指定的列表。删除后,lst3 列表就不存在了。
列表、字符串和元组对象都支持以索引序号的方式进行切片。
列表的切片方法与字符串的切片方法一样,语法结构为列表[索引位置], 索引位置的序号是从 0 开始的。
lst=['张三',19,[80,89,97]]# 要进行切片的列表。
print(lst[0],lst[1],lst[2])# 以开头为基准切片,返回值:张三 19 [80, 89, 97]。
print(lst[-1],lst[-2],lst[-3])# 以结尾为基准切片,返回值:[80, 89, 97] 19 张三。在列表中可以截取一部分元素,语法结构为列表[开始索引: 结束索引: 步长]。注意,切片的结果中不包含结束索引位置的元素。
lst=[7,3,12,54,6,9,88,2,47,33,55] #要做切片处理的列表。
print(lst[2:5]) #以开头为基准切片,返回[12,54,6]。
print(lst[-9:-6]) #以结尾为基准切片,返回[12,54,6]。
print(lst[:4]) #以开头为基准切片,返回[7,3,12,54]。
print(lst[:-7])# 以结尾为基准切片,返回[7,3,12,54]。
print(lst[6:]) #以开头为基准切片,返回[88,2,47,33,55]。
print(lst[-5:]) #以开头为基准切片,返回[88,2,47,33,55]。
print(lst[5:-2])# 开始索引以开头为基准,结束索引以结尾为基准,返回[9,88,2,47]。
print(lst[-6:9])# 开始索引以结尾为基准,结束索引以开头为基准,返回[9,88,2,47]。
print(lst[:]) #截取整个列表切片,返回[7,3,12,54,6,9,88,2,47,33,55]。
print(lst[::2]) #截取整个列表切片,步长为 2,返回[7,12,6,88,47,55]。
print(lst[::-1]) #截取整个列表切片,步长为 -1,返回[55,33,47,2,88,9,6,54,12,3,7]。
print(lst[::-2]) #截取整个列表切片,步长为 -2,返回[55,47,88,6,12,7]。| 切片要求 | 以开头为基准 | 以结尾为基准 | 返回值 |
|---|---|---|---|
| 从指定位置开始,截取到指定结束位置 | print(lst[2:5]) | print(lst[-9:-6]) | [12,54,6] |
| 从最左侧开始,截取到指定结束位置 | print(lst[:4]) | print(lst[:-7]) | [7,3,12,54] |
| 从指定位置开始,截取到最右侧 | print(lst[6:]) | print(lst[-5:]) | [88,2,47,33,55] |
| 开始索引以开头为基准,结束索引以结尾为基准 | print(lst[5:-2]) | print(lst[-6:9]) | [9,88,2,47] |
| ------------- | ------------- | --------------- | -------------------- |
| 截取整个列表切片 | print(lst[:]) | [7,3,12,54,6,9,88,2,47,33,55] | |
| 截取整个列表切片,步长为 2 | print(lst[::2]) | [7,12,6,88,47,55] | |
| 截取整个列表切片,步长为 -1 | print(lst[::-1]) | [55,33,47,2,88,9,6,54,12,3,7] | |
| 截取整个列表切片,步长为 -2 | print(lst[::-2]) | [55,47,88,6,12,7] |
列表在 Python 中的操作非常灵活,除可以对列表做切片外,还可以对列表进行增加、删除和修改元素等操作。
对列表中的元素进行修改,语法结构为列表 [索引位置] = 修改的值 。案例代码如下
lst = ['张三',18,[100,90]] # 被修改的列表
lst[0] = '小明' # 修改列表中的第 0 个元素。
lst[1] = '18岁' # 修改列表中的第 1 个元素。
lst[2] = 190 # 修改列表中的第 2 个元素。
print(lst) # 在屏幕打印修改后的 lst 列表。在列表中增加元素可以使用加运算符 (+)、append 函数、extend 函数、insert 函数来完成,下表列出了不同的实现方法。
| 名称 | 语法结构 | 注释 |
|---|---|---|
| + | list += list | 使用加运算符的累积功能 |
| append | append(object) | 在列表末端增加一个元素 |
| extend | extend(iterable) | 在列表末端增加多个元素 |
| insert | insert(index,object) | 在列表指定位置增加一个元素 |
lst = ['张三'];print(lst)# 原始列表。
lst += ['6年级'];print(lst) #使用积累方式增加。
lst.append('9班');print(lst)# 使用 append 方法增加单个元素。
lst.extend([85,96]);print(lst)# 使用 extend 方法增加多个元素。
lst.insert(3,'12岁');print(lst)# 使用 insert 在列表指定位置插入。上面代码的运行结果: ['张三'] ['张三','6年级'] ['张三','6年级','9班'] ['张三','6年级','9班',85,96] ['张三','6年级','9班','12岁',85,96]
在列表中删除元素,可以使用 remove 函数、del 函数、pop 函数来完成,它们的语法结构及注释如表所示。
删除列表元素的几种方法的语法结构及注释
| 名称 | 语法结构 | 注释 |
|---|---|---|
| remove | remove(object) | 从列表中删除指定的元素,不是指定元素的位置 |
| pop | pop() | 默认删除列表中的最后一个元素 |
| pop | pop(index) | 删除列表中指定位置的元素 |
| del | del | 删除指定列表范围的元素 |
下面看看使用不同方法的小案例,代码如下所示。
lst = ['张三', '6年级', '9班', '12岁', 85, 96];print(lst) #原始列表。
lst.remove('12岁');print(lst) #使用 remove 方法删除列表元素。
lst.pop();print(lst) #使用 pop 方法删除最列表最后一个元素。
lst.pop(2);print(lst) #使用 pop 方法删除指定位置元素。
del lst[1:];print(lst) #使用 del 语句删除指定列表区域元素。上面的代码的运行效果:
['张三','6 年级','9 班','12 岁',85,96] ['张三','6 年级','9 班',85,96] ['张三','6 年级','9 班',85] ['张三','6 年级',85] ['张三']
列表与列表之间可以进行连接、比较等操作,也可以对列表进行重复操作,还可以判断指定元素是否在列表中等,这些操作可能只需要使用一个符号就可以完成。
列表操作符有 +、*、in 和比较运算符。下面列举几个小案例,代码如下所示。
print([1,2,3]+[4,5])# 列表连接使用 + 运算符。
print([1,2,3]*3)# 重复列表使用 * 运算符。
print(2 in [1,2,3])# 判断某个值是否在列表中存在。
print([1,2,3]==[1,2,3])# 列表比较运算。
print([1,2,3]<[1,3,2])# 列表比较运算列表推导式在逻辑上相当于一个 for 循环语句,只是形式上更加简洁。列表推导式执行完成后会创建新的列表。无论列表推导式的写法如何变化,最后都会返回列表对象。如果循环的目的是将数据写入指定单元格,那么最好用标准的循环语句,而不要用列表推导式。
列表推导式的语法结构:[表达式 for 变量 in 列表]
例如,将 ['89','96','100',72'] 中的文本型数字转换为标准整数,可以使用列表推导式或 for 循环语句,代码如下所示。
# 原始列表。
lst = ['89','96','100','72']
#使用列表推导。
lst1 = [int(n) for n in lst]
print(lst1)
#使用循环方式。
lst2 = []
for n in lst:
lst2.append(int(n))
print(lst2)如果推导列表中的元素不是单值,而是列表或其他可循环序列,则在使用列表推导式或 for 循环时,可以将要循环的元素拆分。比如列表 [[1,2,5],[10,5,6],[8,5,3]], 此列表中的元素也是列表,假如求每个子列表的值的乘积,可以使用两种列表推导式和两种 for 循环语句完成,代码如下所示。
#原始列表
lst = [[1,2,5],[10,5,6],[8,5,3]]
#列表推导式 1
lst1 = [l[0]*l[1]*l[2] for l in lst]
print(lst1)
#列表推导式 2
lst2 = [x*y*z for x,y,z in lst]
print(lst2)
#循环方式 1
lst3 = []
for l in lst:
lst3 += [l[0]*l[1]*l[2]]
print(lst3)
#循环方式 2
lst4 = []
for x,y,z in lst:
lst4 += [x*y*z]
print(lst4)- 第 1 种列表推导式 (第 4 行和第 5 行代码):首先看 lst1=[l[0]*l[1]*l[2] for l in lst] 部分,l 表示循环出来的每个子列表,l[0]*l[1]*l[2] 表示将子列表的第 0、1、2 个元素相乘。运行 print(lst1),在屏幕上输出的结果为[10,300,120]。
- 第 2 种列表推导式(第 7 行和第 8 行代码):首先看 lst2=[x*y*z for x,y,z in lst] 部分,x、y、z 分别表示子列表的第 0、1、2 个元素,xyz 表示将它们相乘。运行 print(lst2),在屏幕上输出的结果为[10,300,120]。
- 第 1 种 for 循环方式(第 10~13 行代码)与第 1 种列表推导式思路相同。
- 第 2 种 for 循环方式(第 15~18 行代码)与第 2 种列表推导式思路相同。
注意,每个子列表的元素个数必须相同,否则会出错。例如 [[1,2],[3,4]] 符合要求,而 [[1,2],[3]] 不符合要求。
嵌套列表推导式的语法结构:[表达式 for 变量1 in 列表1 for 变量2 in 变量1 for 变量3 in 变量2...]。可以多层嵌套,注意放在 in 后面的对象必须是可迭代对象。
例如,在列表 [[1,2],[3,4,5],[6,7]] 中有 3 个元素,每个元素也是列表,下面将这些列表元素合并放在同一个列表中,并且每个数字还要乘以 10,结果为 [10,20,30,40,50,60,70]。
可以使用嵌套列表推导式或嵌套 for 循环语句实现,代码如下所示。
#原始列表。
lst = [[1,2],[3,4,5],[6,7]]
#使用嵌套列表推导。
lst1 = [v*10 for l in lst for v in l]
print(lst1)
#使用嵌套循环方式。
lst2 = []
for l in lst:
for v in l:
lst2.append(v*10)
print(lst2)- 在第 4 行和第 5 行代码中,代码 lst1 =[v*10 for l in Ist for v in l] 在执行时首先运行 for l in lst,l 分别循环出 [1,2]、[3,4,5]、[6,7] 3 个元素,再运行 for v in l,v 分别循环出 [1,2] 中的 1、2,[3,4,5] 中的 3、4、5,[6,7] 中的 6、7,并将这些循环出来的数字乘以 10。
- 第 5 行代码运行 print(lst1),在屏幕上输出的结果为 [10,20,30,40,50,60,70]。
- 如果使用标准的 for 循环语句,则可以使用第 7~11 行代码来完成,最后 lst2 变量存储的就是转换后的数字。运行第 11 行代码 print(lst2),在屏幕上输出的结果为 [10,20, 30,40,50,60,70]。
条件列表推导式语法结构:[表达式 for 变量 in 列表 if 条件判断]
例如,对列表 [85,68,98,74,95,82,93,88,74] 进行筛选,筛选出大于或等于 90 的值,生成新的列表。下面分别使用条件列表推导式和 for 循环语句来实现,代码如下所示。
#原始列表。
lst = [85,68,98,74,95,82,93,88,74]
#使用条件列表推导。
lst1 = [n for n in lst if n>=90]
print(lst1)
#使用条件循环方式。
lst2 = []
for n in lst:
if n>= 90:
lst2.append(n)
print(lst2)- 第 4 行代码 lst1=[n for n in lst if n>=90], for n in lst 后面的 if n>=90 表示当条件成立时,n 变量保留。
- 运行第 5 行代码 print(lstl),屏幕上的输出结果为 [98,95,93]。
- 第 7~10 行代码,是在 for 循环体中使用 if 语句完成判断。
- 运行第 11 行代码 print(lst2),屏幕上的输出结果为 [98,95,93]。
本案例对工作簿中“1 月”,“2 月”,“3 月”工作表的 B 列数据进行求和,然后写入新工作簿的新工作表,如图所示。

import xlwt,xlrd #导入读取与写入 xls 文件的库。
wb = xlrd.open_workbook('./14-Turnover123-1.xls') #读取工作簿。
nwb = xlwt.Workbook('uft-8');nws=nwb.add_sheet('汇总表') #新建工作簿与工作表。
lst = [[ws.name,sum(ws.col_values(1)[1:])] for ws in wb.sheets()] #求和工作表中 B 列的金额。
row_num = 0 #初始化 row_num 变量为 0。
for rows in [['月份','总营业额']] + lst: #将表头连接到 lst 列表前面,并开始循环。
nws.write(row_num,0,rows[0]) #将月份写入 A 列。
nws.write(row_num,1,rows[1]) #将每个月的总营业额写入 B 列。
row_num += 1 #累加 row_num 变量,并做为写入数据时的行号。
nwb.save('./14-Turnover123-2.xls') #保存工作簿。- 第 1~3 行代码为读取和写入数据做准备。
- 第 4 行代码 lst = [[ws.name,sum(ws.col_values(1)[1:])] for ws in wb.sheets()]
- 其中 for ws in wb.sheets()] 用来循环读取工作簿中的每个工作表,再赋值给 ws 变量。
- ws.name 用来获取工作表名称,
- sum(ws.col_values(1)[1:]) 用来获取工作表 B 列的数据并进行求和。
- 整个列表推导的处理要求是将工作表名称与总金额组成列表,整行代码运行的结果是将 [['1月',702.0],['2月',549.0],['3月',547.0]] 赋值给 lst 变量。
- 第 5~9 行代码是将获取的 lst 列表中的值写入新工作表。
- 第 10 行代码用来保存新建的工作簿。
汇总指定文件夹中所有工作簿下所有工作表 B 列的数据,然后写入新工作簿的工作表,如图所示。

import os,xlwt,xlrd #导入操作系统接口模块,xls 读取与写入库。
files = os.listdir('销售表') #获取销售表文件夹下的所有工作簿名称。
lst = [[file.split('.')[0],ws.name,sum(ws.col_values(1)[1:])] for file in files for ws in xlrd.open_workbook('销售表 /'+file).sheets()] #对每个工作簿下每个工作表 B 列的数字求和。
print(lst)
lst = [['公司名','姓名','总营业额']]+lst #将表头连接到 lst 列表前面。
nwb = xlwt.Workbook('utf-8');nws = nwb.add_sheet('汇总表') #新建工作簿与工作表。
row_num = 0 #初始化 row_num 为 0。
for l in lst: #循环 lst 列表中的每个元素。
nws.write(row_num,0,l[0]) #将公司名写入 A 列。
nws.write(row_num,1,l[1]) #将工作表名写入 B 列。
nws.write(row_num,2,l[2]) #将每个人的业绩写入 C 列。
row_num += 1 #累加 row_num 变量,并做为写入数据时的行号。
nwb.save('./15-SalesReport.xls') #保存工作簿。-
第 1 行代码 import os,xlwt,xlrd,其中 os 表示导入操作系统接口模块,此模块是内置的,无须安装,主要是为了使用其中的 listdir 函数。
-
第 2 行代码 files = os.listdir('销售表'),表示获取“销售表”文件夹中的所有文件名。当前“销售表”文件夹中只有工作簿,所以获取了所有工作簿名称。将工作簿名称赋值给 files 变量,files 变量中的值为 ['上海分公司.xls','广州分公司.xls','成都分公司.xls'] 。
-
第 3 行代码 lst=[[file.split('.')[0],ws.name,sum(ws.col_values(1)[1:])] for file in files for ws in xlrd.open_workbook('销售表 /'+file).sheets()],这行代码是嵌套列表推导式结构。
- 先看 for file in files 部分,它循环获得工作簿名称并赋值给 file 变量;
- 再看 for ws in xlrd.open_workbook('销售表/'+file).sheets() 部分,它循环读取工作簿中所有工作表对象,然后赋值给 ws 变量;
- 最后看 [file.split('.')[0],ws.name,sum(ws.col_values(1)[1:])] 部分,file.split('.')[0] 是获取的工作簿名称,不要扩展名,ws.name 是获取的工作表名称,sum(ws.col_values(1)[1:]) 是求和工作表 B 列的营业额。
- 最终 lst 变量获得的值为 ['上海分公司','小张',822.0],['上海分公司','小王',751.0],['上海分公司','小李',677.0],['广州分公司','小曾,702.0],[' 广州分公司 ',' 小虎 ',549.0],[广州分公司','小梁',547.0],['成都分公司','小林,1207.0],[' 成都分公司 ',' 小刘 ',1544.0]]。
-
第 5 行代码用来新建工作簿与工作表,目的是把 lst 变量中的值写入新工作簿的新工作表。
-
从第 6 行代码开始都是将 Ist 变量中的数据写入工作表的操作,这里不再赘述。
前面学习了列表的切片,以及列表元素的添加、删除、修改等操作,如果想将其他对象转换为列表,或者想对列表的位置、顺序等进行调整,又该如何操作呢?
在处理数据时有时需要将其他对象转换为列表,比如将元组、集合、字典转换为列表,任何可迭代对象均可直接或间接地转换为列表。要完成这些转换可以使用 list 类,对类进行实例化可以创建对象,因此可以通过 list 类来创建列表对象。
类语法:list([iterable])
参数说明: iterable: 可选参数,可迭代对象。
下面是其他常见对象转换为列表的例子,代码如下所示。
print(list())#创建空列表。
print(list('123'))#将字符串转换为单个字符的列表。
print(list((1,2,3)))#将元组转换为列表。
print(list({1,2,3}))#将集合转换为列表。
print(list({'a':1,'b':2,'c':3}))#将字典中的键转换为列表。=- 第 1 行代码 print(list0),创建空列表,结果为 [] 。
- 第 2 行代码 print(list(123)),将字符串 '123' 转换为单个字符的列表,结果为 [1,2,3].
- 第 3 行代码 print(list((1,2,3))),将元组 (1,2,3) 转换为列表 [1,2,3] 。
- 第 4 行代码 print(list((1,2,3))),将集合(1,2,3}转换为列表[1,2,3]。
- 第 5 行代码 print(list({'a':1,'b':2,'c':3})),将字典 {'a':1,'b':2,'c':13} 中的键转换为列表 ['a','b','c']。
其中,元组、集合、字典这几种对象暂时还没有介绍到,它们也是Python中的重要对象,在这里暂时知道可以将它们转换为列表对象就可以了。
要将列表中的元素反转,可以使用 reverse 函数。
函数语法:reverse()
参数说明:
该函数没有参数,可以对列表中的元素进行反向排序。
例如,要将[1,2,3]转换为[3,2,1],可以使用reverse函数,代码如下所示。
lst = [1,2,3,4] #提供的列表。
lst.reverse() #反转lst列表。
print(lst) #在屏幕上打印lst列表。第 2 行代码 lst.reverse() 直接对lst列表使用 reverse 函数。注意,此函数没有任何参数,直接 reverse() 即可。
列表的复制分为浅复制和深复制。浅复制只引用对象的内存地址,而深复制是重新开辟一个新的内存空间,得到完全独立的新对象。浅复制使用的是copy函数。
函数语法:copy()
参数说明:
该函数没有参数。
copy 函数的案例代码如下所示。
#列表中元素是单值。
lst1 = [1,2,3,4] #被复制的列表。
lst2 = lst1.copy() #浅复制lst1列表,并赋值给lst2变量。
lst1[3] = 100 #修改lst1中的元素。也可以修改lst2中的元素。
print(lst1,lst2) #对浅复制前、后两个列表的数据。
#列表中元素是容器型元素。
lst3 = [1,[2,3],4] #被复制的列表,注意列表的第1个元素[2,3]也是列表。
lst4 = lst3.copy() #浅复制lst3列表,并赋值给lst4变量。
lst3[1][0] = 100 #修改lst3中的元素。也可以修改lst4中的元素。
print(lst3,lst4) #对浅复制前、后两个列表的数据。先看看当列表中的元素是单值时,在复制列表时的变化。
- 第 2 行代码 lst1 = [1,2,3,4] 是准备要复制的列表。
- 第 3 行代码 lst2 = lst1.copy(),表示对 lst1 列表进行复制,然后赋值给变量 lst2。
- 第 4 行代码 lst1[3] = 100,对 lst1 列表中的第 3 个元素进行修改,将原来的 4 修改为 100。
- 第 5 行代码 print(lst1,lst2) ,在屏幕上输出 lst1 和 lst2 两个列表,返回值为 [1,2,3,100][1,2,3,4]。
- 对比一下结果,lst1 的第 3 个元素与 lst2 的第 3 个元素不一致,原因是原来 lst1[3] 中对象4的内存地址换成了对象100的内存地址,
- 而 lst2[3] 还是引用原来对象4的内存地址,引用的内存地址没有跟着变化成对象100的内存地址。
再看看当列表中的元素是容器型元素时,在复制列表时的变化。
- 第 7 行代码 lst3 = [1,[2,3],4] 是准备要复制的列表。
- 第 8 行代码 lst4 = lst3.copy(),对 lst3 列表进行复制,然后赋值给变量 lst4。
- 第 9 行代码 lst3[1][0] = 100,对 lst3 列表中第 1 个元素的第 0 个元素进行修改,将原来的 2 修改为 100。
- 第 10 行代码 print(lst3,lst4),在屏幕上输出 lst3 和 lst4 两个列表,返回值为 [1,[100,3],4][1,[100,3],4]。对比一下结果,发现 lst3 和 lst4 的结果完全一样,原因是复制列表时引用的是列表元素的内存地址,比如 lst3 中的第 1 个元素 [2,3],此元素也是一个列表,程序会在内存中给该列表分配一个内存地址。虽然使用 lst3[1][0] = 100 将其中的 2 修改为 100,但外层列表分配的内存地址没有变,所以最后返回的结果还是一样的。
如果希望复制出的新列表与原来的列表没有任何关联,则可以使用深复制。深复制要先导入copy标准模块,然后使用中copy模块中的deepcopy函数。
函数语法: deepcopy(x)
参数说明:
x:必选参数,被深复制的对象。
deepcopy 函数的案例代码如下所示。
#列表中元素是单值。
import copy #导入复制模块。
lst1 = [1,2,3,4]#准备要被复制的列表。
lst2 = copy.deepcopy(lst1)#使用复制模块下的深复制方法来复制lst1,并赋值给lst2。
lst1[3] = 100#修改lst1中的元素。也可以修改lst2中的元素。
print(lst1,lst2)#对深复制前、后两个列表的数据。
#列表中元素是容器型元素
lst3 = [1,[2,3],4]#准备要被复制的列表。
lst4 = copy.deepcopy(lst3)#使用复制模块下的深复制方法来复制lst3,并赋值给lst4。
lst3[1][0]=100#修改lst3中的元素。也可以修改lst4中的元素。
print(lst3,lst4)#对深复制前、后两个列表的数据。以上代码与上段中的代码基本相同,只是在第 4 行和第 9 行代码中,将原来的浅复制函数修改成了深复制函数。复制后的新列表与原来的列表没有任何关联,因为深复制为新列表开辟了新的内存地址,而不是引用原来列表元素的内存地址。因此,无论是修改原列表中的元素,还是修改新列表中的元素,彼此都不会受影响。
zip 函数是 Python 中的一个内建函数,它接收一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些元组组成的一个可迭代对象。
函数语法:zip(*iterables)
参数说明:
iterables:至少1个可迭代对象。
下面是 zip 函数的使用案例,代码如下所示。
l = [['a','b','c'],[1,2,3]] #提供要重新组合的列表。
lst1 = list(zip(l[0],l[1])) #将要转换的值分别放到zip的不同参数位置。
print(lst1) #在屏幕打印重新组合后lst1的结果。
lst2 = list(zip(*l)) #直接将整个l列表放到zip中。
print(lst2) #在屏幕打印重新组合后lst2的结果。
lst3 = list(zip(*lst2)) #再组合回原来的结构。
print(lst3) #在屏幕打印重新组合后lst3的结果。
print(list(zip(iter([1,2,3]))))-
第 2 行代码 lst1=list(zip(l[0],l[1])),将l[0]和l[1]分别放入 zip 函数的第1个和第2个参数中,如果后面还有数据,可以继续放入第 3 个、第 4 个参数中。zip(l[0],l[1]) 转换出的是一个可迭代对象<zip object at 0x00000247618012C8>,这种可迭代对象的优势是不占用内存空间,在需要时才获取其中的数据,比如使用循环语句获取其中的元素,或者使用 list 类将其转换为列表,具体处理方式依据具体情况而定。
-
第 3 行代码 print(lst1),在屏幕上输出的结果为 [('a',1),('b',2),('c',3)]。
-
第 4 行代码 lst2=list(zip(*l)) ,直接将 l 变量中的列表放到 zip 参数中,这种表达方式需要在列表前面加 *。最后 lst2 返回的结果与 lst1 返回的结果是一样的。
-
第 5 行代码 print(lst2),在屏幕上输出的结果为 [('a',1),('b',2),('c',3)]。
-
第 6 行代码 lst3=list(zip(*lst2)),用同样的表达方式将 lst1 列表或 lst3 列表转换回去。返回的结果与l变量中的列表结构相同。
-
第 7 行代码 print(lst3),在屏幕上输出的结果为 [('a','b','c),(1,2,3)] ,与1变量中的[['a','b','c],[1,2,3]]结构相同,只不过列表中的元素由原来的列表类型变成了元组类型。
用户经常会对列表进行各种汇总统计,本节就来讲解列表的求和、求平均值、计数等统计函数,以及按条件对列表元素进行计数、位置查找等。
可以对列表进行一些常见的统计操作,比如计数、求和、求最大值、求最小值、求平均值。这些统计函数都比较简单,下面看看它们的应用,代码如下所示。
lst = [100,99,81,86]#被处理的列表。
print(len(lst))#计数处理。
print(sum(lst))#求和处理。
print(max(lst))#求最大值处理。
print(min(lst))#求小值处理。
print(sum(lst)/len(lst))#求平均值处理。
print(len(list(zip(*[[1],[2]]))))
print(len(list(iter(range(5)))))- 第 2 行代码 print(len(lst)) 是对 ls t列表计数。在统计字符串长度中讲解过 len函数,只不过这里对象为列表。
- 第 3 行代码 print(sum(lst)) 是对 lst 列表求和,sum函数比较简单,在前面章节的一些案例中已经使用过了。
- 第 4 行代码 print(max(lst) 是对 lst 列表求最大值。
- 第 5 行代码 print(min(lst)) 是对 lst 列表求最小值。
- 第 6 行代码 print(sum(lst)/len(lst) 是对 lst 列表求平均值。Python 没有内置的求平均值函数,只能用求和结果除以元素个数来获取平均值。
实际上,len、sum、max、min 函数可以对所有可迭代的对象进行统计,比如后面将学习的元组、集合等都可以使用这些函数。
在列表中,要统计指定元素在列表中出现的次数,可以使用count函数;要统计指定元素在列表中出现的位置,可以使用index函数。这两个函数的案例代码如下所示。
lst = ['a','b','c','b','b']#被处理的列表。
print(lst.count('b'))#统计'b'在列表中出现的次数。
print(lst.index('b'))#统计'b'在列表中第1次出现的位置。- 第 2 行代码 print(Ist.count('b')),统计 'b' 在lst列表中出现的次数,返回值为 3。
- 第 3 行代码 print(Ist.index('b')),统计 'b' 在列表中第 1 次出现的位置,返回值为 1。index函数的第2个和第3个参数可以用来指定起止位置。
-
什么是元组?
Python 中的元组与列表类似,同属序列类型,都可以按照特定顺序存放一组数据,数据类型不受限制,切片方式也相同。
-
元组与列表的区别在于:
元组存储的数据不能被修改,比如不能对元组的元素进行添加、删除。可以将元组看作是只读属性的列表。
-
为什么要使用元组?
虽然元组在操作上没有列表灵活,但元组占用的内存空间更小,存取速度更快。所以,某些内置函数的返回值是元组类型。比如,前面学习的zip函数,迭代出来的每个元素就是元组。
元组用小括号 () 表示,元组里的元素用逗号分隔。下面介绍元组的创建和删除方法,代码如下所示。
tup1 = ();print(tup1) #创建空元组方法1。
tup2 = tuple();print(tup2) #创建空元组方法2。
tup3 = (1,2,3);print(tup3) #创建多个元素的元组。
tup4 = (100,);print(tup4) #创建单个元素的元组。
del tup3 #删除元组。-
第 1 行代码 tupl = (),使用一对空小括号。运行 print(tup1) 后,屏幕上的输出结果为()。
-
第 2 行代码 tup2 = tuple(),使用tuple类创建元组。运行 print(tup2) 后,屏幕上的输出结果为()。
-
第 3 行代码 tup3 = (1,2,3),在小括号中输入元组的元素。运行 print(tup3) 后,屏幕上的输出结果为(1,2,3)。
-
第 4 行代码 tup4 = (100,),在小括号中输入元组的元素。注意,如果元组中的元素只有一个,则需要在这个元素的后面添加逗号,否则程序不能正确识别。运行 print(tup4) 后,屏幕上的输出结果为(100,)。
-
第 5 行代码 del tup3,使用 del 语句删除指定的元组。删除后,tup3 元组就不存在了。
元组虽然没有列表灵活,但一些基本的操作还是可以实现的,比如切片、合并、循环、推导、转换等。
元组的合并非常简单。比如 tup =(1,2,3)+(4,5,6) ,输出结果为 (1,2,3,4,5,6)。这种合并方式是比较好理解的。而对于累积式合并,很多读者会有疑惑,下面举一个例子, 代码如下所示。
tup = (1,2,3) #元组。
print(id(tup),tup) #合并前在屏幕打印元组内存地址和组。
tup += (4,5,6) #将tup元组与(4,5,6)合并。
print(id(tup),tup) #合并前在屏幕打印元组内存地址和组。- 第 1 行代码 tup=(1,2,3),这是最开始的元组。
- 第 2 行代码 print(id(tup),tup),输出 tup 元组的内存地址和tup元组的值,返回结 果为“2382958184472(1,2,3)”。
- 第 3 行代码 tup+=(4,5,6),将 tup 元组与(4,5,6) 合并,再赋值给tup。
- 第 4 行代码 print(id(tup),tup),再次输出 tup 元组的内存地址和 tup 元组的值,返回结果为“2382958104296(1,2,3,4,5,6)”。
对比合并前后的输出结果,合并前tup的内存地址是2382958184472,合并后tup的内存地址是 2382958104296。这两个内存地址不同,说明 tup 变量标识符已经从2382958184472转换绑定到2382958104296。也就是说,用户看到的tup变量没有变化,但它绑定的内存地址已经变了。如果不明白其中的道理,就会觉得元组也是可以修改的。
注意,代码中的 id 用于获取对象的内存地址,而且内存地址会动态变化。如果用户在计算机上测试上面的代码,则 id 可能与书上的 id 不同。这不重要,只要合并前后两个 id 的值不同就可以了。
元组也可以进行深复制和浅复制,只不过浅复制只能使用copy模块中的浅复制。下面看看元组复制的一些特性,代码如下所示。
import copy #导入复制模块。
tup1 = (1,2,3) #准备要复制的元组。
tup2 = copy.copy(tup1) #将浅复制tup1元组,并赋值给tup2变量。
tup3 = copy.deepcopy(tup1)#将深复制tup1元组,并赋值给tup3变量。
print(id(tup1),id(tup2),id(tup3)) #在屏幕打印tup1、tup2、tup3元组的内存地址。
tup4 = (1,[2],3) #准备要复制的元组。
tup5 = copy.copy(tup4) #将浅复制tup4元组,并赋值给tup5变量。
tup6 = copy.deepcopy(tup4) #将深复制tup4元组,并赋值给tup6变量。
print(id(tup4),id(tup5),id(tup6)) #在屏幕打印tup4、tup5、tup6元组的内存地址。先看元组的元素为不可变类型的对象时的情况。
-
第 2 行代码 tupl = (1,2,3),元组中的每个元素都是不可变类型的对象,此元组是准备被复制的对象。
-
第 3 行代码 tup2 = copy.copy(tup1),此代码使用了copy模块中的浅复制copy函数,并且将复制结果赋值给tup2变量。
-
第 4 行代码 tup3 = copy.deepcopy(tup1),此代码使用了 copy 模块中的深复制 deepcopy 函数,并且将复制结果赋值给tup3变量。
-
第 5 行代码 print(id(tupl),id(tup2),id(tup3)),在屏幕上输出 tupl、tup2、tup3的内存地址,结果为“2328759322728 2328759322728 2328759322728”。观察返回结果,可以发现3个元组的内存址相同。
再看元组的元素为可变类型的对象时的情况。
-
第 7 行代码 tup4 = (1,[2],3),其中的 [2] 是可变类型的对象,此元组是准备被复制的对象。
-
第 8 行代码 tup5 = copy.copy(tup4),此代码使用了copy模块中的浅复制copy函数,并且将复制结果赋值给tup5变量。
-
第 9 行代码 tup5 = copy.copy(tup4),此代码使用了copy模块中的深复制 deepcopy 函数,并且将复制结果赋值给tup6变量。
-
第 10 行代码 print(id(tup4),id(tup5),id(tup6)),在屏幕上输出tup4、tup5、tup6的内存地址,结果为“2328759323128 2328759323128 2328760171720。”观察返回结果,可以发现tup4和tup5的内存地址相同,而tup6的内存地址与其他两个内存地址不同。
因此,当元组中有不可变类型的对象时,执行深复制和浅复制都不会再开辟内存空间,用的是同一个内存地址;当元组中有可变类型的对象时,执行深复制会重新开辟一块内存空间。
元组也可以像列表一样做元组推导式和for循环,比如将元组(1,2,3)的每个元素乘 10,再返回一个新元组,可以分别使用元组推导式和 for 循环语句完成,代码如下所示。
tup = (1,2,3) #被循环的元组。
tup1 = (t*10 for t in tup) #元组推导式。
print(tup1) #在屏幕打印tup1元组。
print(tuple(tup1)) #将tup1迭代器转换为元组。
tup2 = () #创建空元组。
for t in tup: #循环tup元组的元素。
tup2 += (t*10,) #将tup中的元素乘以10,再积累合并到tup2变量。
print(tup2) #在屏幕打印tup2元组。第 1 行代码 tup = (1,2,3) 是被循环的元组,也可以是其他可迭代对象。
先看看使用元组推导式进行循环处理的情况。
-
第 2 行代码 tup1=(t*10 for t in tup),用元组推导式循环出每个元素,再乘10,然后将推导结果赋值给tupl变量。
-
第 3 行代码 print(tup1),在屏幕上输出tup1元组,结果为“<generator object<genexpr>at 0x000001F7BE98D5C8>”。也就是说,元组推导式的结果不是元组,而是生成器,生成器也是可迭代对象。
-
第4行代码 print(tuple(tupl)),使用tuple类对象将tupl转换为元组,返回结果为(10,20,30)。
再看看使用for循环语句进行处理的情况。
-
第 6 行代码 tup2=(),新建一个空元组。
-
第 7 行代码 for t in tup:,循环tup元组中的每个元素。
-
第 8 行代码 tup2 += (t*10,),将循环出来的元素乘10,再积累并合并到tup2变量。第9行代码print(tup2),在屏幕上输出tup2,返回结果为(10,20,30)。
在Python中,可以使用tuple类对象创建或转换一个元组对象,比如创建空元组以及将字符串、列表、集合、字典这些可迭代对象转换为元组。
类语法:tuple([iterable])
参数说明:
iterable:可选参数,要转换为元组的可迭代序列。
下面看几个转换的例子,代码如下所示。
print(tuple('123')) #将字符串转换为单个字符的元组。
print(tuple([1,2,3])) #将列表转换为元组。
print(tuple({1,2,3})) #将集合转换为元组。
print(tuple({'a':1,'b':2,'c':3})) #将字典中的键转换为元组。元组的统计函数与列表的统计函数相同,这里做一下简单介绍,案例代码如下所示。
tup = (50,60,74,63,50,95,74,80,50) #被统计的元组。
print(len(tup)) #计数
print(max(tup)) #最大值
print(min(tup)) #最小值
print(sum(tup)) #求和
print(tup.count(50)) #条件计数
print(tup.index(80)) #条件定位
format()Python中的字典是放在花括号中的,字和说明之间用冒号 : 分隔。
Python 中字典的标准表示方法为{key:value,······}。
- key(键)在字典中必须具有唯一性,且必须是不可变对象,如字符串、数字或元组。
- value(值)可以重复,也可以是任何数据类型,如字符串、元组、列表、集合等。
- 字典是无序的,只能通过键来存取对应的值,而不能像列表那样通过索引位置来存取对应的值。
本节将讲解创建字典及对字典进行存取操作的方法。通过一些相关的小案例,介绍在处理 Excel数据时如何应用字典。
下面介绍字典的创建与删除,案例代码如下所示。
dic1=dict();print(dic1)#使用dict类创建空字典。
dic2=dict(王五=22,麻子=24);print(dic2)#使用dict类创建字典。
dic3={};print(dic3)#直接使用{}创建空字典。
dic4={'张三':18,'李四':20};print(dic4)#直接使用{}创建字典。
del dic4#删除指定的字典。想获取字典中每个键对应的值,该怎么办?想获取字典中所有的键或所有的值,又该如何操作?案例代码如下所示。
dic={'张三': 18, '李四': 20}#准备的字典。
print(dic['李四'])#获取指定键对应的值。
print(dic.keys())#获取字典的所有键。
print(dic.values())#获取字典的所有值。
print(dic.items())#获取字典的所有键值。字典键值的修改、增加、删除与前面讲解的列表、元组的相关操作类似,但是也有不同之处,下面分别讲解。
向字典中增加更多的键值,一般使用update函数,也可以用修改键值的方式操作。
看看下面的小例子,代码如下所示。
dic={}#空字典
dic.update(李四=88);print(dic)#使用update函数向dic字典添加键值 方法1。
dic.update({'麻子':96});print(dic)#使用update函数dic字典添加键值 方法2。
dic['张三']=99;print(dic)#修改方法向dic字典添加键值。删除字典键值可以使用pop函数、clear函数和del语句。下面是删除字典键值的小例子,代码如下所示。
dic={'张三':84,'李四':88,'王二':79,'麻子':99} #准备的字典。
print(dic.pop('张三'));print(dic) #删除指定键值。
del dic['李四'];print(dic) #删除指定键值。
dic.clear();print(dic) #清空字典。修改字典中键对应的值,表示方法为:字典名[键]=修改的值。如果是修改键呢?
实际上没有直接修改键的方法,可以使用间接的方式,表示方法为:字典名[新键] = 字典名.pop(旧键)。案例代码如下所示。
dic={'张三':20,'李四':18,'麻子':35}#准备的字典。
dic['张三']=100;print(dic)#修改键值中的值。
dic['王五']=dic.pop('李四');print(dic)#修改键值中的键。字典的转换操作是指将列表、元组等可迭代对象的元素转换为对应的字典,本节使用dict类和 dict.fromkeys函数完成转换。
在上节中使用dict类创建了字对象,实际上,dict类有三种不同的写法都可以生成字典对象。本节将详细介绍dict类的相关语法。
类语法: dict(**kwargs) dict(mapping,**kwargs) cdict(iterable,**kwargs)
参数说明:
**kwargs:关键字,采用“键=值”的方式创建字典。 mapping:元素的容器,采用映射函数的方式创建字典。 iterable:可迭代对象,采用可迭代对象的方式创建字典。
下面演示使用dict类创建字典的三种方式,代码如下所示。
dic1=dict(a=1,b=2);print(dic1)
dic2=dict(zip(('a','b'),(1,2)));print(dic2)
dic3=dict([('a',1),('b',2)]);print(dic3)- 第1行代码 dicl=dict(a=1,b=2),使用**kwargs关键字的方式,也就是“键=值”的方式创建字典,可以用这种方式添加任意多个键值对。执行 print(dic1)后,返回结果为{'a:1,'b:2}。
- 第2行代码 dic2=dict(zip(('a','b'),(1,2))),使用元素的容器方式,一般使用zip函数,比如 zip(('a',b'),(1,2)),表示将键放在一组,将值放在另一组。执行 print(dic2)后,返回结果为{'a':1,'b:2}。
- 第3行代码 dic3=dict([('a',1),('b',2)]),使用可迭代对象的方式,比如[('a',1),('b',2)],将键与值放在同一个容器中,组织形式不定。元组、列表、字符串等可迭代对象只要结构正确均可以转换为字典。执行 print(dic3)后,返回结果为{'a':1,'b:2}。
在Python中,除使用dict类创建字典外,还可以用 dict.fromkeys函数创建一个新字典,下面介绍该函数的语法。
函数语法:
dict.fromkeys(seq[,value])
参数说明: seq:必选参数,字典的键,可以是元组、列表、字符串等可迭代对象。 value:可选参数,设置键对应的值,默认值为None。
下面是几个小例子,代码如下所示。
dic1=dict.fromkeys(('a','b'),1);print(dic1)
dic2=dict.fromkeys(['a','b'],1);print(dic2)
dic3=dict.fromkeys('abc',1);print(dic3)
dic4=dict.fromkeys(['a','a','b']);print(dic4)
dic5=dict.fromkeys([('a',1),('a',1)]);print(dic5)- 第1行代码 dicl=dict.fromkeys(('a','b'),1),将元组('a','b')作为键,键的值统一为1。运行 print(dic1)后,返回字典{'a:1,'b:1}。
- 第2行代码 dic2=dict.fromkeys(['a','b'],1),将列表['a','b]作为键,键的值统一为1。运行print(dic2)后,返回字典{'a:1,'b':1}。
- 第3行代码 dict.fromkeys('abc',1),将字符串'abc'的每个字符作为键,键的值统一为1。运行 print(dic3)后,返回字典{'a': 1,'b':1,'c:1}。
- 第4行代码 dic4=dict.fromkeys(['a','a','b']),将列表['a','a','b']作为键,列表中有相同的元素,只保留一个。所以运行 print(dic4)后,返回字典{'a': None, 'b': None}。
- 第5行代码 dic5=dict.fromkeys([('a',1),('a',1)]),将列表[('a',1),('a',1)]作为键,字典的键是元组,而且两个元组相同,这时会去掉重复的,只保留一个。运行 print(dic5)后,返回字典{('a',1):None}。
再次提醒读者,字典的键可以为数字、字符串、元组等不可变类型的数据,不能为列表、集合等可变类型的数据。
在Python中,集合是一个无序的不重复元素序列,元素被放在 {} 中,是可迭代的,不支持任何索引或切片操作。与列表相比,集合的主要优点是具有高度优化的方法,可以检查集合中是否包含特定元素,也可以进行并集、交集、差集、比较等操作。
集合与列表、元组、字典一样,可以创建和删除。集合创建与删除的案例代码如下所示。
set1 = set();print(set1) #创建空集合。
set2 = {1,2,3};print(set2) #创建有元素的集合。
set3 = frozenset(set2);print(set3) #转换为不可变集合。
del set1 #删除指定集合。-
第 1 行代码 set1 = set(),使用set类创建空集合,运行 print(set1)后,返回结果为 set()。创建空集合必须使用set(),而不能用 {},因为{}是创建空字典。
-
第 2 行代码 set2 = {1,2,3},将元素放在花括号中,运行print(set2)后,返回结果为 {1,2,3},此种集合是可变集合,也就是可变对象,不能作为字典的键。
-
第 3 行代码 set3 = frozenset(set2),在set2集合外层套上 frozenset类,运行 print(set3)后,返回结果为frozenset({1,2,3})。frozenset函数的参数不一定是可变集合,可以是任何可迭代对象。不可变集合类似字符串、元组,可以作为字典的键,缺点是一旦创建便不能更改,除内容不能更改外,其他功能及操作与可变集合set一样。
-
第 4 行代码 del set1,删除指定的集合,删除后集合将不存在。
我们知道了集合可以分为可变集合和不可变集合,本节讲解集合元素的添加与删除,当然是针对可变集合而言的。
向集合中添加单个元素或多个元素,可以使用add函数或 update函数,来看看它们的区别是什么。案例代码如下所示。
set1 = {1,2,3} #原集合
set1.add(4);print(set1) #向集合添加单个元素。
set1.update({5,6,7});print(set1) #向集合添加多个元素。-
第 2 行代码 set1.add(4),表示向set1集合中添加元素4,运行 print(set1)后,返回的结果为{1,2,3,4}。
-
第 3 行代码 set1.update({5,6,7}),表示向set1集合中添加另一个集合{5,6,7},运行print(set1)后,返回的结果为{1,2,3,4,5,6,7}。实际上,update函数的参数可以是任何可迭代对象,比如字符串、列表、元组等。
注意,如果集合中的所有元素都是数字,则这些数字会按照从小到大的顺序排列,否则排列是混乱的。为了让读者看到演示效果,这里将数字作为集合的元素。
删除集合中的元素可以用remove、discard、pop、clear函数,根据不同的要求用不同的函数。案例代码如下所示。
set1 = {'a','b','c','d'} #原集合
set1.remove('a');print(set1) #删除集合中元素'a'。
set1.discard('b');print(set1) #删除集合中元素'b'。
set1.pop();print(set1) #随机删除集合中的一个元素。
set1.clear();print(set1) #清空集合中所有元素-
第 2 行代码 set1.remove('a'),表示删除集合中的指定元素'a',如果元素不存在,则返回错误。运行print(set1)后,返回的结果为{'c','d','b'}。
-
第 3 行代码 set1.discard('b'),表示删除集合中的指定元素b',如果元素不存在,则忽略,不会返回错误。运行print(set1)后,返回的结果为{'d','c}。
-
第 4 行代码 set1.pop(),表示随机删除集合中的一个元素。运行 print(set1)后,如果删除的是'd',则返回{'c};如果删除的是'c',则返回{'d'}。
-
第 5 行代码 set1.clear(),表示清空集合中的所有元素。运行print(setl)后,返回的结果为set()。
注意,由于集合中的元素不是数字,所以每次运行第2、3、4行代码返回的结果的顺序会有所不同。
集合之间的大小比较就是判断某个集合是否完全包含另一个集合,可以使用大于(>)、小于(<)、大于或等于(>=)、小于或等于(<=)、等于(==)、不等于(!=)这些比较运算符来做判断。
下面用几个小例子讲解集合之间是如何进行比较的,代码如下所示。
print(2 in {1,2,3})#2是否包含在集合中。
print({1,2,3}=={3,2,1})#两个集合是否相同。
print({2,3}>{1,2,3})#集合大于比较。
print({2,3}<{1,2,3})#集合小于比较。-
第1行代码print(2 in{1,2,3}),判断集合{1,2,3}中是否包含2,返回的结果为True。
-
第2行代码 print({1,2,3}={3,2,1}),判断{1,2,3}与{3,2,1}是否相等,集合是无序的,只要两个集合中的数据相同就相等,返回的结果是True。
-
第3行代码print({2,3}>{1,2,3}),其本质是判断{1,2,3}中的元素是否被{2,3}包含,返回的结果为False。
-
第4行代码print({2,3}<{1,2,3}),其本质是判断{2,3}中的元素是否被{1,2,3}包含,返回的结果为True。
在“评级表”工作表中,1~4季度每个人有不同的等级,判断包含“优”和“良”两个等级的有哪些人,将结果写在F列,如图所示。

本案例的编程思路是将每个人4个季度的等级转换成集合,然后与集合{'优,良}进行比较判断,如果包含{'优,良},则条件成立。
import xlrd #导入xls文件读取库。
from xlutils.copy import copy #导入函数
wb = xlrd.open_workbook('./25-Scores-1.xls');ws=wb.sheet_by_name('评级表') #读取工作簿和工作表。
nwb = copy(wb);nws=nwb.get_sheet('评级表') #复制工作簿及读取副本工作簿下的工作表。
row_num = 0 #初始化row_num变量为0。
for row in tuple(ws.get_rows())[1:]: #循环读取每行记录。
row_num += 1 #对row_num变量累加1。
if {'优','良'}<={v.value for v in row[1:-1]}: #判断每行的等级是否包含'优'和'良'。
nws.write(row_num,5,'√') #如果包含则写入'√'。
else: #否则
nws.write(row_num,5,'×') #如果不包含则写入'×'。
nwb.save('./25-Scores-2.xls') #保存副本工作簿。-
第1~5行代码为数据的读取和写入做准备。
-
第6行代码 for row in tuple(ws.get_rows()[1:]:,将每行数据循环赋值给row变量。
-
第8行代码 if {'优','良'}<={v.value for v in row[l:-1]}:, 其中,{v.value for v in row[1:-1]}将 row 元组中的元素使用集合推导式转换为集合,集合推导式也具有去重功能。然后判断集合是否大于或等于{'优,'良'},也就是{'优,良'}这个集合是否被包含或刚好与集合相等。
-
第9行代码 nws.write(row_num,5,'✓'),如果第8行代码的条件成立,则将 “✓” 写入F列。
-
第11行代码 nws.write(row_num,5,'x'),如果第8行代码的条件不成立,则将 “x” 写入F列。
-
第12行代码 nwb.save('Chapter-8-6-1.xls'),保存副本工作簿。
将可迭代对象转换为集合,除使用集合推导式外,还可以使用set类,这种方式更直接、简单。
前面学习过使用set类创建空集合,实际上也可以使用set类将字符串、列表、元组等可迭代对象转换为集合。
类语法:set([iterable])
参数说明:
iterable:可选参数,要转换为集合的可迭代序列。
下面是使用set类进行转换的例子,代码如下所示。
set1 = set('123');print(set1)#将字符串转换为集合。
set2 = set([1,2,3]);print(set2)#将列表转换为集合。
set3 = set((1,2,3));print(set3)#将元组转换为集合。
set4 = set({'a':1,'b':2,'c':3});print(set4)#将字典转换为集合。
set5 = set(range(1,4));print(set5)#将可迭代对象转换为集合。
print(set('aadad'))-
第1行代码 set1=set('123'),将字符串'123'转换为集合,运行print(set1)后,返回的结果为{'1','3','2'}。
-
第2行代码 set2=set([1,2,3]),将列表[1,2,3]转换为集合,运行 print(set2)后,返回的结果为{1,2,3}。
-
第3行代码 set3=set(1,2,3)),将元组(1,2,3)转换为集合,运行 print(set3)后,返回的结果为{1,2,3}。
-
第4行代码 set4=set({'a':1,b':2,'c':3}),将字典{'a':1,'b:2,c:3}的键转换为集合,运行 print(set4)后,返回的结果为{'b','c','a'}。
-
第5行代码set5=set(range(1,4)),将可迭代对象range(1,4)换为集合,运行print(set5)后,返回的结果为{1,2,3}。

在Python中,集合之间可以做关系运算,例如做并集、交集、差集及对称差集运算。本节将逐个讲解集合的运算,每种集合运算都有配图,图中用斜线填充的部分就是集合运算后得到的结果。
并集运算指两个或更多集合合并,结果中包含了所有集合的元素,重复的元素只会出现一次,可以参考图所示的效果。下面以set1和set2两个集合为例讲解并集运算的原理,代码如下所示。
set1 = {1,2,3,4,5,6} #集合1。
set2 = {4,5,6,7,8,9} #集合2。
print(set1.union(set2)) #集合1与集合2做并集。
print(set2.union(set1)) #集合2与集合1做并集。
print(set1|set2) #集合1与集合2做并集。
print(set2|set1) #集合2与集合1做并集。-
第3行和第4行代码将 set1 与 set2 两个集合进行合并,使用union函数完成,无论写法是 set1.union(set2),还是 set2.union(set1),结果都相同,返回的结果都是{1,2,3,4,5,6,7,8,9}。
-
第5行和第6行代码使用 "|" 符号将 set1 和 set2 两个集合进行合并,set1|set2 与 set2|set1 两种写法的运算结果相同,都是{1,2,3,4,5,6,7,8,9}。

交集运算求两个或更多集合中都包含的元素。下面以 set1 和 set2 两个集合为例讲解交集运算的原理,代码如下所示。
set1 = {1,2,3,4,5,6}#集合1。
set2 = {4,5,6,7,8,9}#集合2。
set3 = set1.intersection(set2);print(set3)#集合1与集合2交集,结果可以存储在新集合3。
set3 = set2.intersection(set1);print(set3)#集合2与集合1交集,结果可以存储在新集合3。
set3 = set1&set2;print(set3)#集合1与集合2交集,结果可以存储在新集合3。
set3 = set2&set1;print(set3)#集合2与集合1交集,结果可以存储在新集合3。
set1.intersection_update(set2);print(set1)#集合1与集合2交集,交集结果存储在集合1。
set2.intersection_update(set1);print(set2)#集合2与集合1交集,交集结果存储在集合2。-
第3~6行代码表示 set1 和 set2 两个集合做交集运算,结果生成新的集合,如图所示。第3行和第4行代码使用intersection函数,而第5行和第6行代码使用&符号。
-
第3行代码 set1.intersection(set2)与第5行代码 set1&set2 两种写法的结果是等价的。运行 print(set3)后,返回的结果是 {4,5,6}。
-
第4行代码 set2.intersection(set1)与第6行代码 set2&set1 两种写法的结果是等价的。运行 print(set3)后,返回的结果是 {4,5,6}。
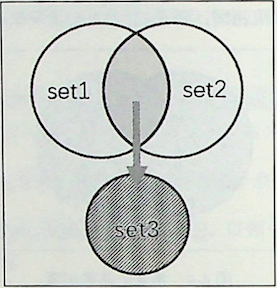
-
第7行和第8行代码虽然也是 set1 和 set2 两个集合做交集运算,但返回结果的存储方式有所不同。
-
第7行代码 set1.intersection_update(set2),以 set1 为存储集合与 set2 集合做交集运算,也就是交集结果存储在 set1 中,如图(a)所示。运行 print(set1)后,返回的结果为 {4,5,6}。
-
第8行代码 set2.intersection_update(set1),以 set2 为存储集合与 set1 集合做交集运算,也就是交集结果存储在 set2 中,如图(b)所示。此行代码在运行时,set2 集合中的 {4,5,6,7,8,9} 与 set1 集合中的 {4,5,6}做交集运算,为什么set1集合变成了 {4,5,6}?原因是第7行代码在运行时,set1 中存储了交集的结果。运行 print(set2)后,返回的结果虽然也是 {4,5,6},但要明白其中的变化。

差集运算就是两个集合相减,用一个集合中的元素减去另一个集合中的元素。下面以 set1 和 set2 两个集合为例讲解差集运算的原理,代码如下所示。
set1 = {1,2,3,4,5,6} #集合1。
set2 = {4,5,6,7,8,9} #集合2。
set3 = set1.difference(set2);print(set3) #集合1减去集合2,结果可以存储在新集合3。
set3 = set2.difference(set1);print(set3) #集合2减去集合1,结果可以存储在新集合3。
set3 = set1-set2;print(set3) #集合1减去集合2,结果可以存储在新集合3。
set3 = set2-set1;print(set3) #集合2减去集合1,结果可以存储在新集合3。
set1.difference_update(set2);print(set1) #集合1减去集合2,差集结果存储在集合1中。
set2.difference_update(set1);print(set2) #集合2减去集合1,差集结果存储在集合2中。-
第3~6行代码是 set1 和set2两个集合做差集运算,结果生成新的集合。第3行和第4行代码使用difference函数,而第5行和第6行代码使用减号(-)。
-
第3行代码 set1.difference(set2))与第5行代码setl-set2两种写法的结果是等价的,如图(a)所示。运行 print(set3)后,返回的结果是{1,2,3}。
-
第4行代码set2.difference(set1)与第6行代码set2-setl两种写法的结果是等价的,如图(b)所示。运行 print(set3)后,返回的结果是{1,2,3}。

-
第7行代码 set1.difference_update(set2),以set1为存储集合与set2 集合做差集运算,也就是差集结果存储在set1中,如图(a)所示。运行 print(set1)后,返回的结果为 {1,2,3}。
-
第8行代码 set2.difference_update(set1),以set2为存储集合与set1集合做差集运算,也就是差集结果存储在set2中,如图(b)所示。此行代码在运行时,set2集合中的 {4,5,6,7,8,9}与set1集合中的 {1,2,3}做差集运算,为什么set1集合变成了 {1,2,3}?原因是第7行代码在运行时,set1中存储了差集的结果。运行 print(set2)后,返回的结 果是 {4,5,6,7,8,9}。

对称差集运算返回两个集合中不重复的元素集合,即移除两个集合中都存在的元素。下面以 set1 和 set2 两个集合为例讲解对称差集运算的原理,代码如下所示。
set1 = {1,2,3,4,5,6} #集合1。
set2 = {4,5,6,7,8,9} #集合2。
set3 = set1.symmetric_difference(set2);print(set3)#去掉集合1与集合2相同元素,结果存储在新集合3。
set3 = set2.symmetric_difference(set1);print(set3)#去掉集合2与集合1相同元素,结果存储在新集合3。
set3 = set1^set2;print(set3)#去掉集合1与集合2相同元素,结果存储在新集合3。
set3 = set2^set1;print(set3)#去掉集合2与集合1相同元素,结果存储在新集合3。
set1.symmetric_difference_update(set2);print(set1)#去掉集合1与集合2相同元素,结果可以存储在集合1。
set2.symmetric_difference_update(set1);print(set2)#去掉集合2与集合1相同元素,结果可以存储在集合2。第 3~6 行代码是 set1 和 set2 两个集合做对称差集运算,结果生成新的集合。第3行和第4行代码使用 symmetric_difference函数,第5行和第6行代码使用^符号。对称差集运算示意图如图所示。
第3行代码 set1.symmetric_difference(set2) 与第5行代码 set1^set2 两种写法的结果是等价的。运行 print(set3) 后,返回的结果是{1,2,3,7,8,9}。
第4行代码 set2.symmetric_difference(set1) 与第6行代码 set2^set1 两种写法的结果是等价的。运行 print(set3) 后,返回的结果是{1,2,3,7,8,9}。

第7行代码 set1.symmetric_difference_update(set2),以set1为存储集合与set2集合做对称差集运算,也就是对称差集结果存储在set1中,如图(a)所示。运行print(set1)后,返回的结果为{1,2,3,7,8,9}。
第8行代码 set2.symmetric_difference_update(set1),以set2为存储集合与setl集合做对称差集运算,也就是对称差集结果存储在set2中,如图(b)所示。此行代码在运行时,set2集合中的{4,5,6,7,8,9}与setl集合中的{1,2,3,7,8,9}做对称差集运算,为什么setl集合变成了{1,2,3,7,8,9}?原因是第7行代码在运行时,setl中存储了对称交集的结果。运行 print(set2)后,返回的结果是{1,2,3,4,5,6}。

假如现在有setl和set2两个集合,可以将集合之间的运算用表格做一下总结,如表所示。

集合的运算可以用函数方法和符号方法来实现,它们之间的区别是什么呢?如果使用函数方法,则函数的参数不一定是集合类型,只要是可迭代对象即可。如果使用符号方法,则符号两侧必须是集合类型,否则会出错。 在通过表格的方式总结集合之间的运算时,会发现一个问题,为什么并集中没有将运算结果存储在原集合中的方法?也就是说,为什么没有setl.union_update(set2)这种方法?虽然没有 union_update 函数来实现,但有另一种方式可以实现,方法为setl.update(set2),没错,就是利用集合的update函数来实现的。虽然 update函数是向指定集合中添加元素,但从另一个角度看,就是两个集合的并集,而且并集结果也没有生成新集合,是存储在原集合中的。
总结:
- 列表是有序的,是可以重复的,是可以被遍历的,是可以改变的,copy 和 deepcopy 后的内存地址都不一样的
- 元组是有序的,是可以重复的,是可以被遍历的,是不可以改变的,copy 和 deepcopy 后的内存地址,要根据原来的元组中是否包含可改变对象来决定,如果包含了可变对象的,原id 和 copy 后的 id 一样,但是 deepcopy 不一样,如果原元组里包含的都是不可变,那么 3 个都一样。
- 字典是无序的,键是不可以重复的,值是可以重复的,是可以通过 keys 和 values 还有 items 进行遍历的,。。。
- 集合是无需的,是不可以重复的,是?,是可以改变的,。。。。