Lightweight Covariance Matrix Adaptation Evolution Strategy (CMA-ES) [1] implementation.
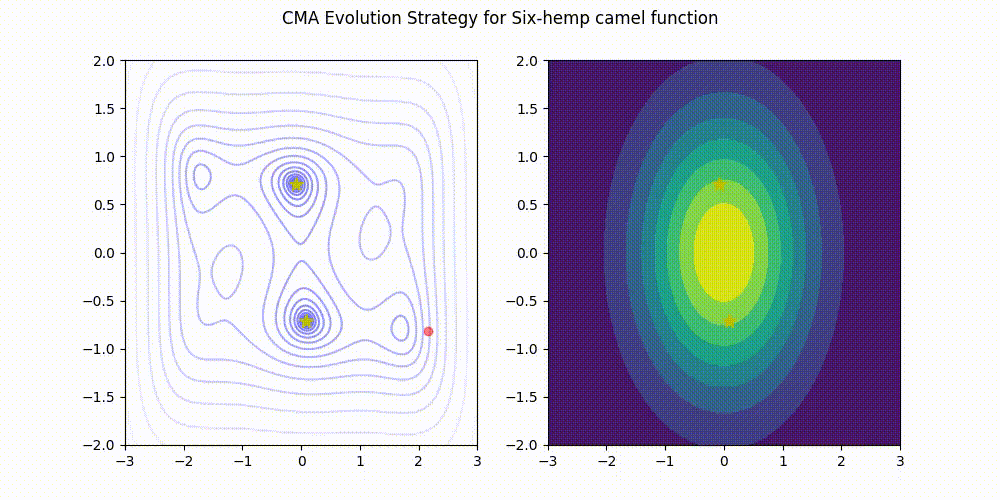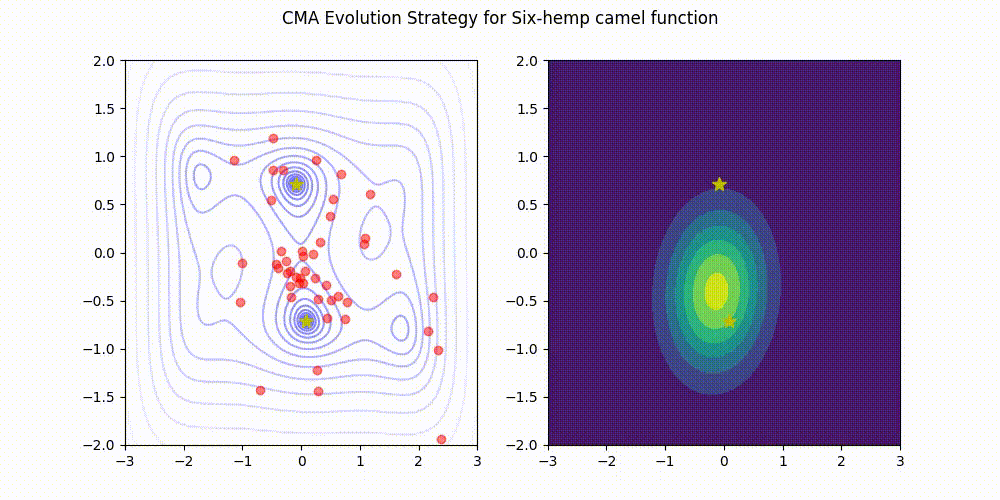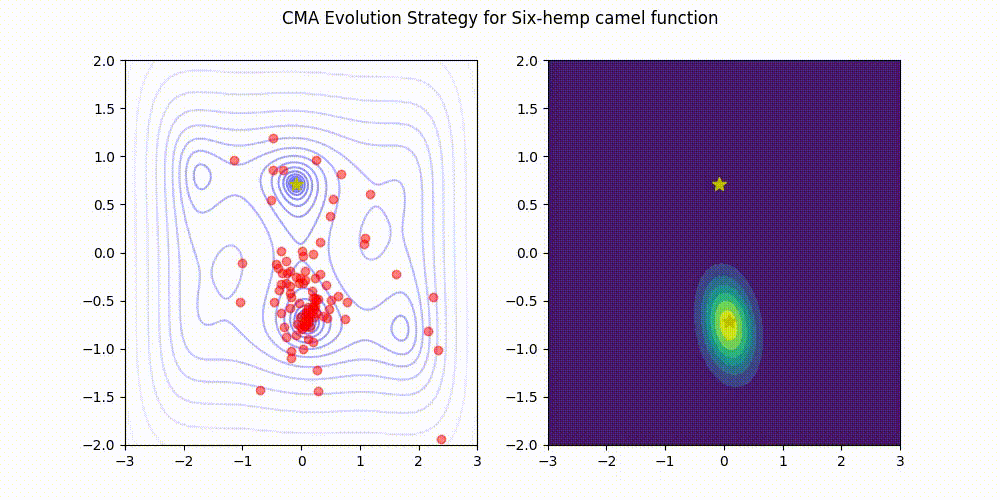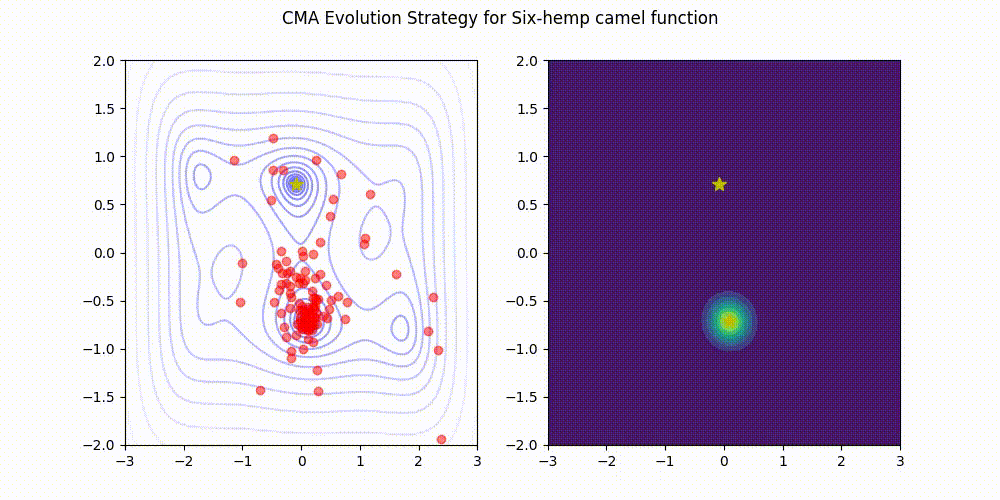
Himmelblau function.

Rosenbrock function.

Quadratic function.

These GIF animations are generated by visualizer.py.
Supported Python versions are 3.6 or later.
$ pip install cmaes
This library provides two interfaces that an Optuna's sampler interface and a low-level interface. I recommend you to use this library via Optuna.
Optuna [2] is an automatic hyperparameter optimization framework. Optuna officially implements a sampler based on pycma. It achieves almost the same performance. But this library is faster and simple.
import optuna
from cmaes.sampler import CMASampler
def objective(trial: optuna.Trial):
x1 = trial.suggest_uniform("x1", -4, 4)
x2 = trial.suggest_uniform("x2", -4, 4)
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
sampler = CMASampler()
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=250)Note that CMASampler doesn't support categorical distributions. Although pycma's sampler supports categorical distributions, it also has a problem (especially on high-cardinality categorical distribution). If your search space contains a categorical distribution, please use TPESampler.
import numpy as np
from cmaes import CMA
def quadratic(x1, x2):
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
cma_es = CMA(mean=np.zeros(2), sigma=1.3)
for generation in range(50):
solutions = []
for _ in range(cma_es.population_size):
x = cma_es.ask()
value = quadratic(x[0], x[1])
solutions.append((x, value))
print(f"#{generation} {value} (x1={x[0]}, x2 = {x[1]})")
cma_es.tell(solutions)| Rosenbrock function | Six-Hemp Camel function |
|---|---|
 |
 |
This implementation (green) stands comparison with pycma (blue). See benchmark for details.
| trials/params | storage | pycma's sampler | this library |
|---|---|---|---|
| 100 / 5 | memory | 4.976 sec (+/- 0.596) | 0.197 sec (+/- 0.078) |
| 500 / 5 | memory | 71.651 sec (+/- 3.847) | 0.656 sec (+/- 0.044) |
| 500 / 50 | memory | 291.002 sec (+/- 5.010) | 1.981 sec (+/- 0.041) |
| 100 / 5 | sqlite | 16.143 sec (+/- 3.487) | 11.843 sec (+/- 1.390) |
| 500 / 5 | sqlite | 129.436 sec (+/- 6.279) | 43.735 sec (+/- 2.676) |
| 500 / 50 | sqlite | 397.084 sec (+/- 6.618) | 150.531 sec (+/- 1.113) |
This script was run on my laptop with --times 4. So the times should not be taken precisely.
Even though, it is clear that this library is extremely faster than Optuna's pycma sampler (with Optuna v1.0.0 and pycma v2.7.0).
Other libraries:
I respect all libraries involved in CMA-ES.
- pycma : Most famous CMA-ES implementation by Nikolaus Hansen.
- cma-es : A Tensorflow v2 implementation.
References:
- [1] N. Hansen, The CMA Evolution Strategy: A Tutorial. arXiv:1604.00772, 2016.
- [2] Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. In The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’19), August 4–8, 2019.