Lightweight Covariance Matrix Adaptation Evolution Strategy (CMA-ES) [1] implementation.
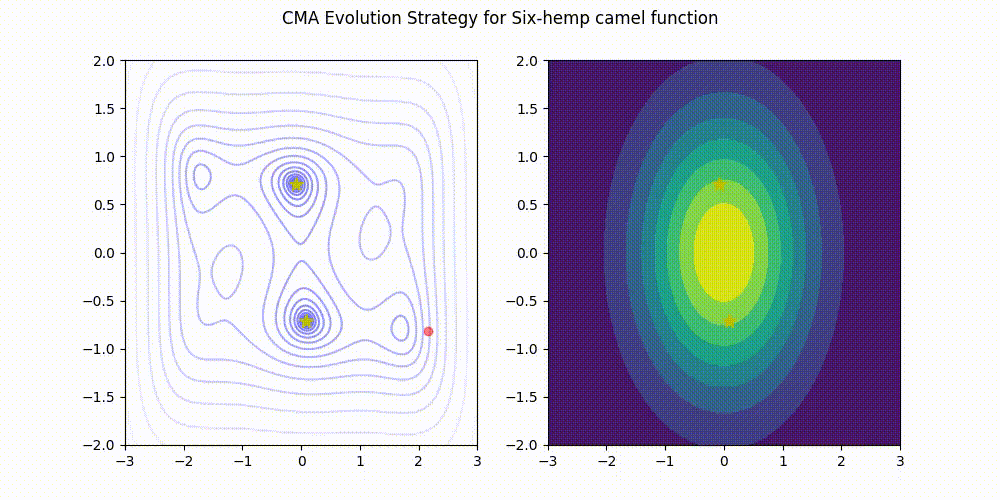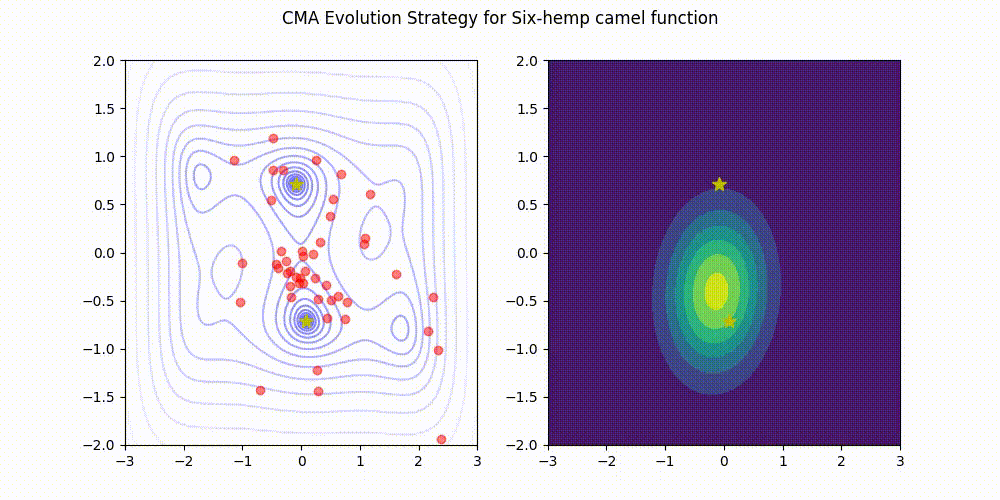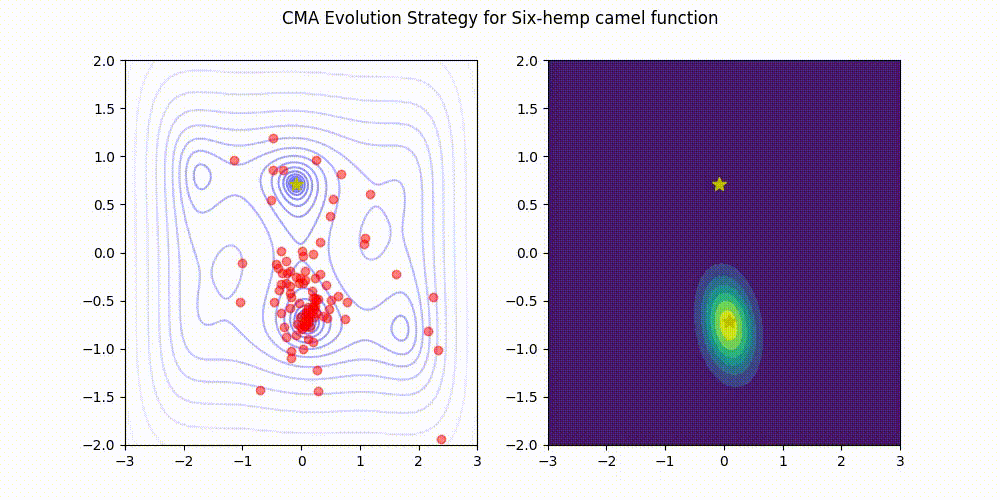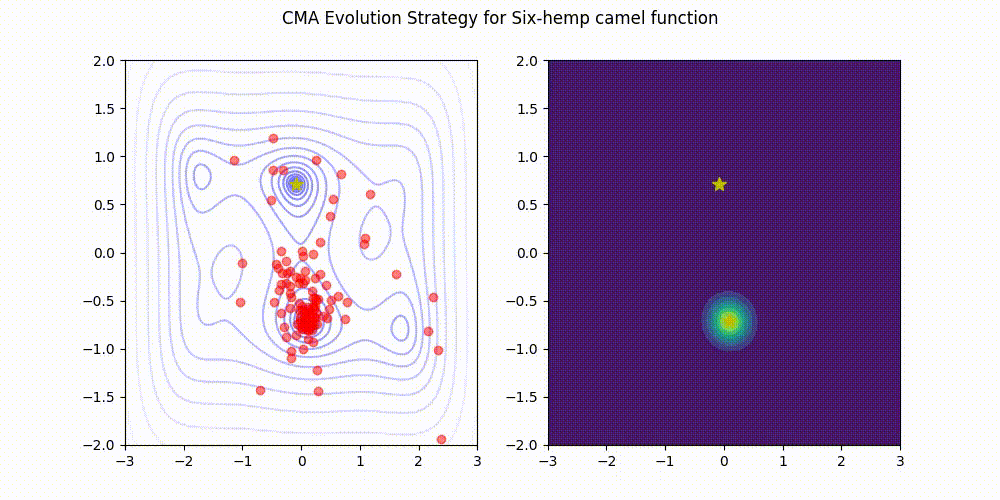
Rosenbrock function.

IPOP-CMA-ES [2] on Himmelblau function.
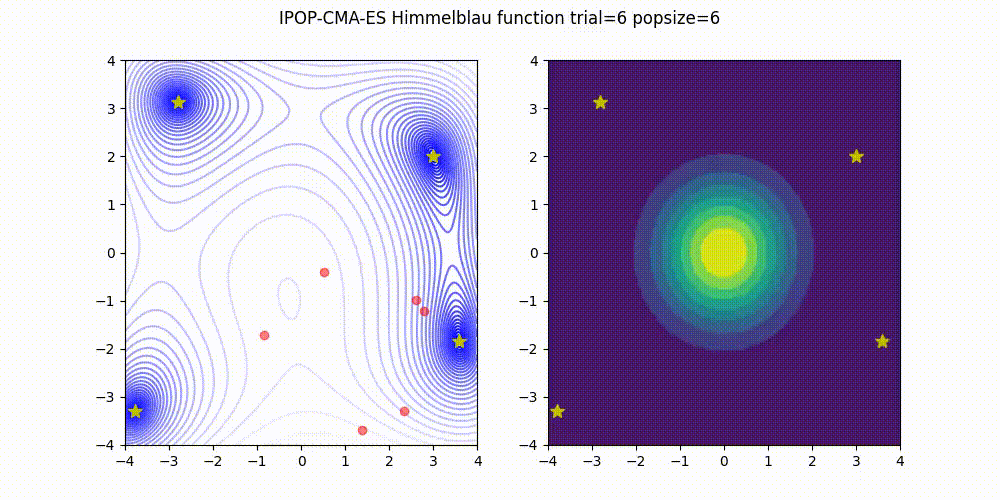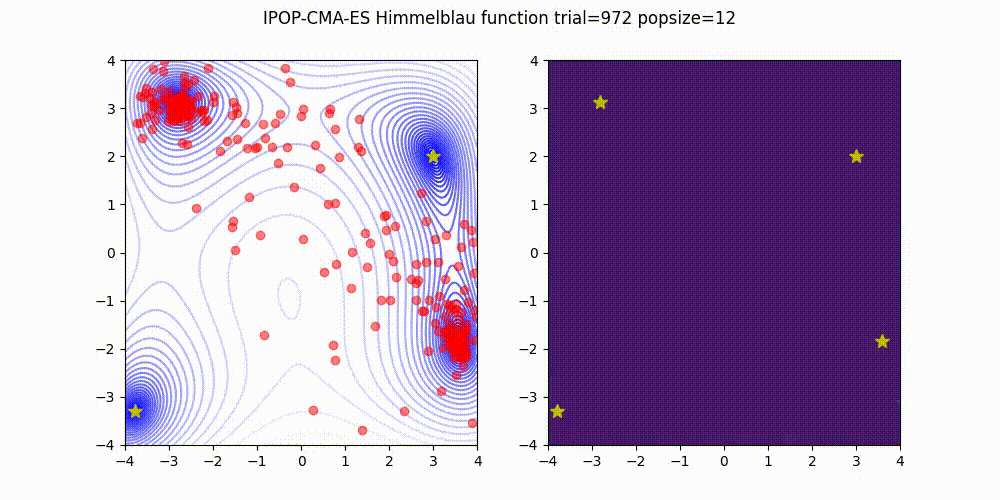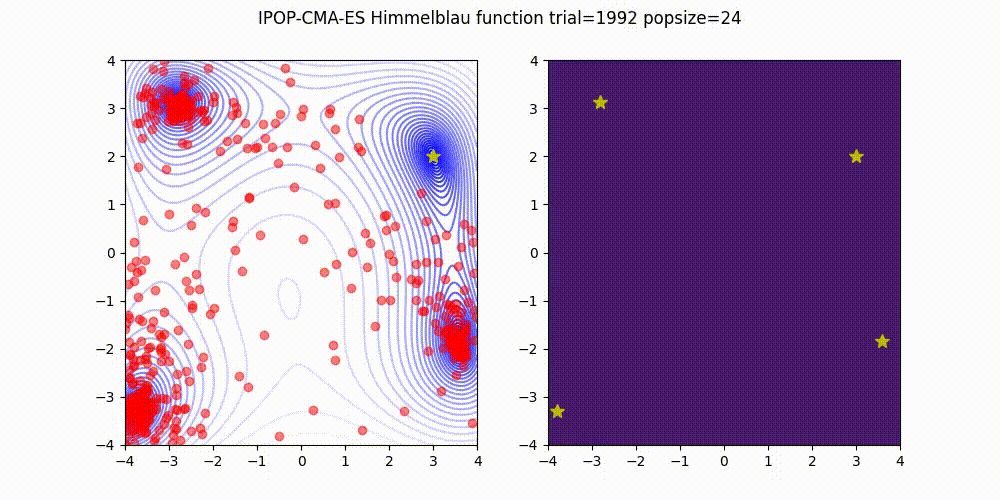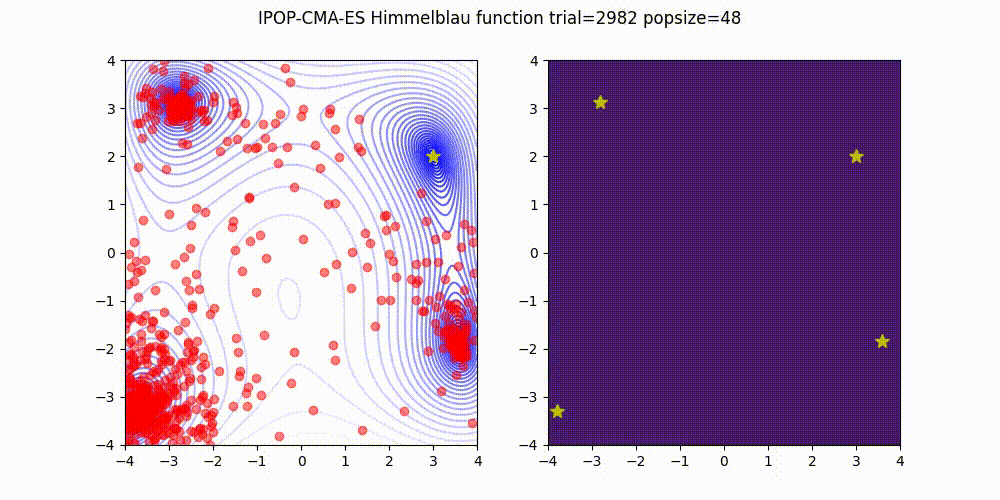
BIPOP-CMA-ES [3] on Himmelblau function.
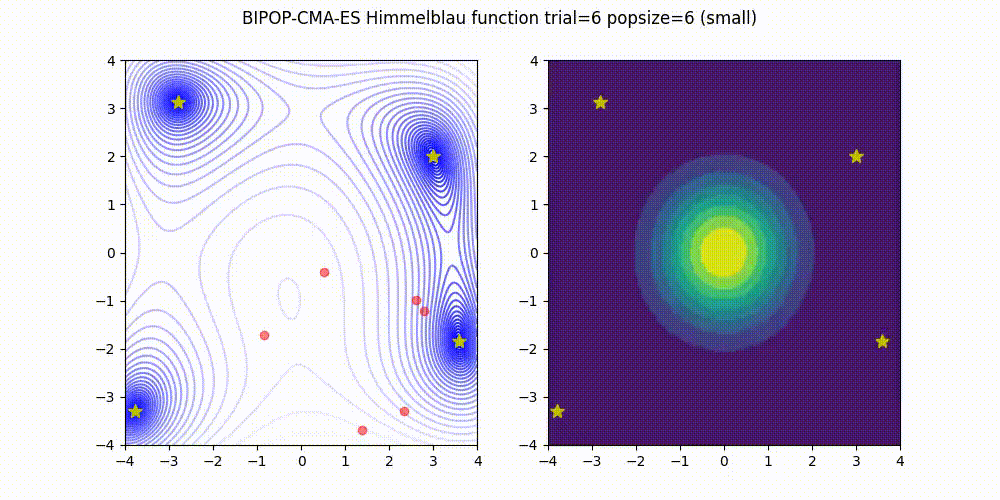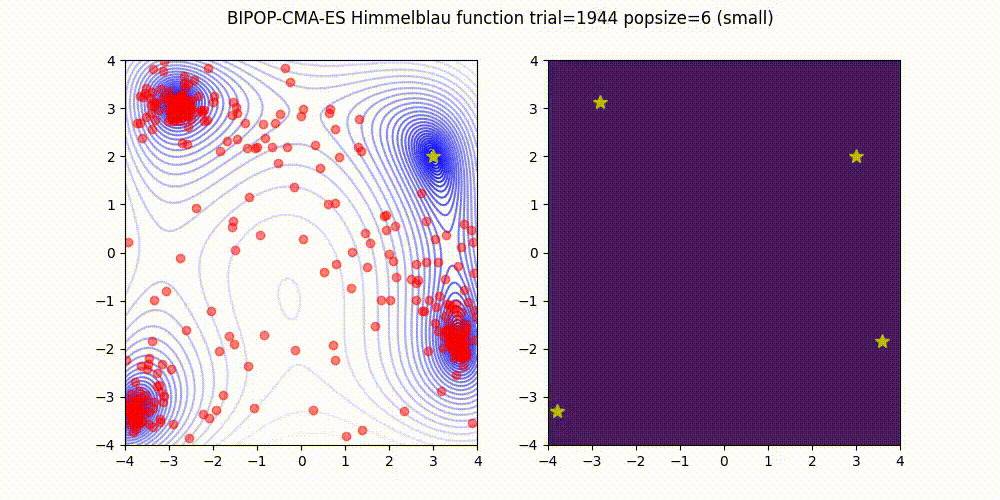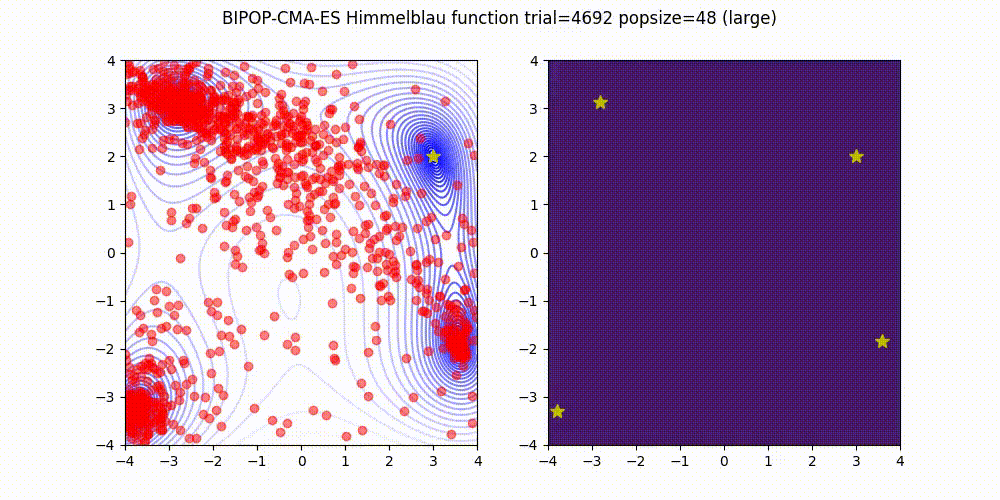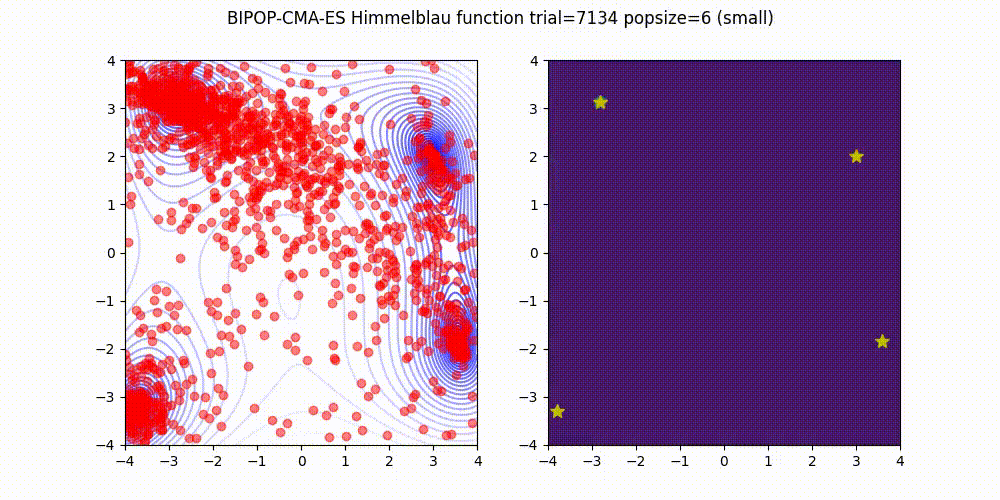
These GIF animations are generated by visualizer.py.
Supported Python versions are 3.5 or later.
$ pip install cmaes
Or you can install via conda-forge.
$ conda install -c conda-forge cmaes
This library provides an "ask-and-tell" style interface.
import numpy as np
from cmaes import CMA
def quadratic(x1, x2):
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
optimizer = CMA(mean=np.zeros(2), sigma=1.3)
for generation in range(50):
solutions = []
for _ in range(optimizer.population_size):
x = optimizer.ask()
value = quadratic(x[0], x[1])
solutions.append((x, value))
print(f"#{generation} {value} (x1={x[0]}, x2 = {x[1]})")
optimizer.tell(solutions)And you can use this library via Optuna [4], an automatic hyperparameter optimization framework. Optuna's built-in CMA-ES sampler which uses this library under the hood is available from v1.3.0 and stabled at v2.0.0. See the documentation or v2.0 release blog for more details.
import optuna
def objective(trial: optuna.Trial):
x1 = trial.suggest_uniform("x1", -4, 4)
x2 = trial.suggest_uniform("x2", -4, 4)
return (x1 - 3) ** 2 + (10 * (x2 + 2)) ** 2
if __name__ == "__main__":
sampler = optuna.samplers.CmaEsSampler()
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=250)Example of IPOP-CMA-ES
You can easily implement IPOP-CMA-ES which restarts CMA-ES with increasing population size.
import math
import numpy as np
from cmaes import CMA
def ackley(x1, x2):
# https://www.sfu.ca/~ssurjano/ackley.html
return (
-20 * math.exp(-0.2 * math.sqrt(0.5 * (x1 ** 2 + x2 ** 2)))
- math.exp(0.5 * (math.cos(2 * math.pi * x1) + math.cos(2 * math.pi * x2)))
+ math.e + 20
)
if __name__ == "__main__":
bounds = np.array([[-32.768, 32.768], [-32.768, 32.768]])
lower_bounds, upper_bounds = bounds[:, 0], bounds[:, 1]
mean = lower_bounds + (np.random.rand(2) * (upper_bounds - lower_bounds))
sigma = 32.768 * 2 / 5 # 1/5 of the domain width
optimizer = CMA(mean=mean, sigma=sigma, bounds=bounds, seed=0)
for generation in range(200):
solutions = []
for _ in range(optimizer.population_size):
x = optimizer.ask()
value = ackley(x[0], x[1])
solutions.append((x, value))
print(f"#{generation} {value} (x1={x[0]}, x2 = {x[1]})")
optimizer.tell(solutions)
if optimizer.should_stop():
# popsize multiplied by 2 (or 3) before each restart.
popsize = optimizer.population_size * 2
mean = lower_bounds + (np.random.rand(2) * (upper_bounds - lower_bounds))
optimizer = CMA(mean=mean, sigma=sigma, population_size=popsize)
print(f"Restart CMA-ES with popsize={popsize}")Example of BIPOP-CMA-ES
Here is an example of BIPOP-CMA-ES which applies two interlaced restart strategies, one with an increasing population size and one with varying small population sizes.
import math
import numpy as np
from cmaes import CMA
def ackley(x1, x2):
# https://www.sfu.ca/~ssurjano/ackley.html
return (
-20 * math.exp(-0.2 * math.sqrt(0.5 * (x1 ** 2 + x2 ** 2)))
- math.exp(0.5 * (math.cos(2 * math.pi * x1) + math.cos(2 * math.pi * x2)))
+ math.e + 20
)
if __name__ == "__main__":
bounds = np.array([[-32.768, 32.768], [-32.768, 32.768]])
lower_bounds, upper_bounds = bounds[:, 0], bounds[:, 1]
mean = lower_bounds + (np.random.rand(2) * (upper_bounds - lower_bounds))
sigma = 32.768 * 2 / 5 # 1/5 of the domain width
optimizer = CMA(mean=mean, sigma=sigma, bounds=bounds, seed=0)
n_restarts = 0 # A small restart doesn't count in the n_restarts
small_n_eval, large_n_eval = 0, 0
popsize0 = optimizer.population_size
inc_popsize = 2
# Initial run is with "normal" population size; it is
# the large population before first doubling, but its
# budget accounting is the same as in case of small
# population.
poptype = "small"
for generation in range(200):
solutions = []
for _ in range(optimizer.population_size):
x = optimizer.ask()
value = ackley(x[0], x[1])
solutions.append((x, value))
print(f"#{generation} {value} (x1={x[0]}, x2 = {x[1]})")
optimizer.tell(solutions)
if optimizer.should_stop():
n_eval = optimizer.population_size * optimizer.generation
if poptype == "small":
small_n_eval += n_eval
else: # poptype == "large"
large_n_eval += n_eval
if small_n_eval < large_n_eval:
poptype = "small"
popsize_multiplier = inc_popsize ** n_restarts
popsize = math.floor(
popsize0 * popsize_multiplier ** (np.random.uniform() ** 2)
)
else:
poptype = "large"
n_restarts += 1
popsize = popsize0 * (inc_popsize ** n_restarts)
mean = lower_bounds + (np.random.rand(2) * (upper_bounds - lower_bounds))
optimizer = CMA(
mean=mean,
sigma=sigma,
bounds=bounds,
population_size=popsize,
)
print("Restart CMA-ES with popsize={} ({})".format(popsize, poptype))| Rosenbrock function | Six-Hump Camel function |
|---|---|
 |
 |
This implementation (green) stands comparison with pycma (blue). See benchmark for details.
Other libraries:
I respect all libraries involved in CMA-ES.
- pycma : Most famous CMA-ES implementation by Nikolaus Hansen.
- pymoo : Multi-objective optimization in Python.
References:
- [1] N. Hansen, The CMA Evolution Strategy: A Tutorial. arXiv:1604.00772, 2016.
- [2] Auger, A., Hansen, N.: A restart CMA evolution strategy with increasing population size. In: Proceedings of the 2005 IEEE Congress on Evolutionary Computation (CEC’2005), pp. 1769–1776 (2005a)
- [3] Hansen N. Benchmarking a BI-Population CMA-ES on the BBOB-2009 Function Testbed. In the workshop Proceedings of the Genetic and Evolutionary Computation Conference, GECCO, pages 2389–2395. ACM, 2009.
- [4] Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. In The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’19), August 4–8, 2019.