| title | description | services | documentationcenter | author | manager | editor | ms.assetid | ms.service | ms.workload | ms.tgt_pltfrm | ms.devlang | ms.topic | ms.date | ms.author |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Access datasets with Machine Learning Python client library | Microsoft Docs |
Install and use the Python client library to access and manage Azure Machine Learning data securely from a local Python environment. |
machine-learning |
python |
bradsev |
jhubbard |
cgronlun |
9ab42272-c30c-4b7e-8e66-d64eafef22d0 |
machine-learning |
data-services |
na |
na |
article |
12/09/2016 |
huvalo;bradsev |
The preview of Microsoft Azure Machine Learning Python client library can enable secure access to your Azure Machine Learning datasets from a local Python environment and enables the creation and management of datasets in a workspace.
This topic provides instructions on how to:
- install the Machine Learning Python client library
- access and upload datasets, including instructions on how to get authorization to access Azure Machine Learning datasets from your local Python environment
- access intermediate datasets from experiments
- use the Python client library to enumerate datasets, access metadata, read the contents of a dataset, create new datasets and update existing datasets
[!INCLUDE machine-learning-free-trial]
The Python client library has been tested under the following environments:
- Windows, Mac and Linux
- Python 2.7, 3.3 and 3.4
It has a dependency on the following packages:
- requests
- python-dateutil
- pandas
We recommend using a Python distribution such as Anaconda or Canopy, which come with Python, IPython and the three packages listed above installed. Although IPython is not strictly required, it is a great environment for manipulating and visualizing data interactively.
The Azure Machine Learning Python client library must also be installed to complete the tasks outlined in this topic. It is available from the Python Package Index. To install it in your Python environment, run the following command from your local Python environment:
pip install azureml
Alternatively, you can download and install from the sources on github.
python setup.py install
If you have git installed on your machine, you can use pip to install directly from the git repository:
pip install git+https://github.com/Azure/Azure-MachineLearning-ClientLibrary-Python.git
The Python client library gives you programmatic access to your existing datasets from experiments that have been run.
From the Studio web interface, you can generate code snippets that include all the necessary information to download and deserialize datasets as Pandas DataFrame objects on your location machine.
The code snippets provided by Studio for use with the Python client library includes your workspace id and authorization token. These provide full access to your workspace and must be protected, like a password.
For security reasons, the code snippet functionality is only available to users that have their role set as Owner for the workspace. Your role is displayed in Azure Machine Learning Studio on the USERS page under Settings.

If your role is not set as Owner, you can either request to be reinvited as an owner, or ask the owner of the workspace to provide you with the code snippet.
To obtain the authorization token, you can do one of the following:
- Ask for a token from an owner. Owners can access their authorization tokens from the Settings page of their workspace in Studio. Select Settings from the left pane and click AUTHORIZATION TOKENS to see the primary and secondary tokens. Although either the primary or the secondary authorization tokens can be used in the code snippet, it is recommended that owners only share the secondary authorization tokens.

- Ask to be promoted to role of owner. To do this, a current owner of the workspace needs to first remove you from the workspace then re-invite you to it as an owner.
Once developers have obtained the workspace id and authorization token, they are able to access the workspace using the code snippet regardless of their role.
Authorization tokens are managed on the AUTHORIZATION TOKENS page under SETTINGS. You can regenerate them, but this procedure revokes access to the previous token.
-
In Machine Learning Studio, click DATASETS in the navigation bar on the left.
-
Select the dataset you would like to access. You can select any of the datasets from the MY DATASETS list or from the SAMPLES list.
-
From the bottom toolbar, click Generate Data Access Code. If the data is in a format incompatible with the Python client library, this button is disabled.
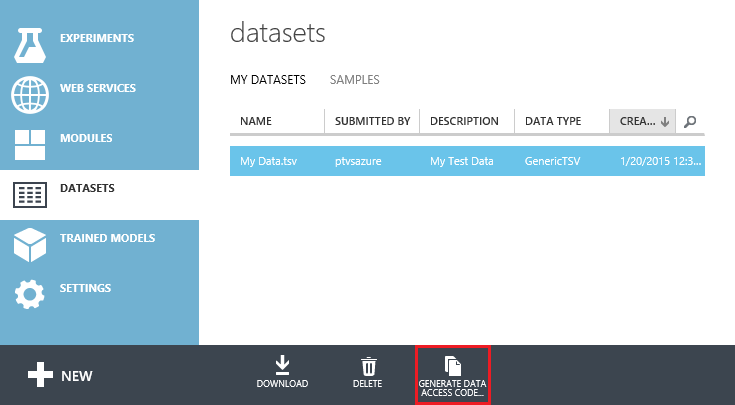
-
Select the code snippet from the window that appears and copy it to your clipboard.

-
Paste the code into the notebook of your local Python application.




After an experiment is run in the Machine Learning Studio, it is possible to access the intermediate datasets from the output nodes of modules. Intermediate datasets are data that has been created and used for intermediate steps when a model tool has been run.
Intermediate datasets can be accessed as long as the data format is compatible with the Python client library.
The following formats are supported (constants for these are in the azureml.DataTypeIds class):
- PlainText
- GenericCSV
- GenericTSV
- GenericCSVNoHeader
- GenericTSVNoHeader
You can determine the format by hovering over a module output node. It is displayed along with the node name, in a tooltip.
Some of the modules, such as the Split module, output to a format named Dataset, which is not supported by the Python client library.

You need to use a conversion module, such as Convert to CSV, to get an output into a supported format.

The following steps show an example that creates an experiment, runs it and accesses the intermediate dataset.
-
Create a new experiment.
-
Insert an Adult Census Income Binary Classification dataset module.
-
Insert a Split module, and connect its input to the dataset module output.
-
Insert a Convert to CSV module and connect its input to one of the Split module outputs.
-
Save the experiment, run it, and wait for it to finish running.
-
Click the output node on the Convert to CSV module.
-
When the context menu appears, select Generate Data Access Code.
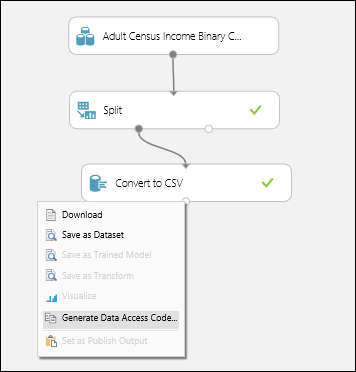
-
Select the code snippet and copy it to your clipboard from the window that appears.

-
Paste the code in your notebook.

-
You can visualize the data using matplotlib. This displays in a histogram for the age column:





The workspace is the entry point for the Python client library. Provide the Workspace class with your workspace id and authorization token to create an instance:
ws = Workspace(workspace_id='4c29e1adeba2e5a7cbeb0e4f4adfb4df',
authorization_token='f4f3ade2c6aefdb1afb043cd8bcf3daf')
To enumerate all datasets in a given workspace:
for ds in ws.datasets:
print(ds.name)
To enumerate just the user-created datasets:
for ds in ws.user_datasets:
print(ds.name)
To enumerate just the example datasets:
for ds in ws.example_datasets:
print(ds.name)
You can access a dataset by name (which is case-sensitive):
ds = ws.datasets['my dataset name']
Or you can access it by index:
ds = ws.datasets[0]
Datasets have metadata, in addition to content. (Intermediate datasets are an exception to this rule and do not have any metadata.)
Some metadata values are assigned by the user at creation time:
print(ds.name)
print(ds.description)
print(ds.family_id)
print(ds.data_type_id)
Others are values assigned by Azure ML:
print(ds.id)
print(ds.created_date)
print(ds.size)
See the SourceDataset class for more on the available metadata.
The code snippets provided by Machine Learning Studio automatically download and deserialize the dataset to a Pandas DataFrame object. This is done with the to_dataframe method:
frame = ds.to_dataframe()
If you prefer to download the raw data, and perform the deserialization yourself, that is an option. At the moment, this is the only option for formats such as 'ARFF', which the Python client library cannot deserialize.
To read the contents as text:
text_data = ds.read_as_text()
To read the contents as binary:
binary_data = ds.read_as_binary()
You can also just open a stream to the contents:
with ds.open() as file:
binary_data_chunk = file.read(1000)
The Python client library allows you to upload datasets from your Python program. These datasets are then available for use in your workspace.
If you have your data in a Pandas DataFrame, use the following code:
from azureml import DataTypeIds
dataset = ws.datasets.add_from_dataframe(
dataframe=frame,
data_type_id=DataTypeIds.GenericCSV,
name='my new dataset',
description='my description'
)
If your data is already serialized, you can use:
from azureml import DataTypeIds
dataset = ws.datasets.add_from_raw_data(
raw_data=raw_data,
data_type_id=DataTypeIds.GenericCSV,
name='my new dataset',
description='my description'
)
The Python client library is able to serialize a Pandas DataFrame to the following formats (constants for these are in the azureml.DataTypeIds class):
- PlainText
- GenericCSV
- GenericTSV
- GenericCSVNoHeader
- GenericTSVNoHeader
If you try to upload a new dataset with a name that matches an existing dataset, you should get a conflict error.
To update an existing dataset, you first need to get a reference to the existing dataset:
dataset = ws.datasets['existing dataset']
print(dataset.data_type_id) # 'GenericCSV'
print(dataset.name) # 'existing dataset'
print(dataset.description) # 'data up to jan 2015'
Then use update_from_dataframe to serialize and replace the contents of the dataset on Azure:
dataset = ws.datasets['existing dataset']
dataset.update_from_dataframe(frame2)
print(dataset.data_type_id) # 'GenericCSV'
print(dataset.name) # 'existing dataset'
print(dataset.description) # 'data up to jan 2015'
If you want to serialize the data to a different format, specify a value for the optional data_type_id parameter.
from azureml import DataTypeIds
dataset = ws.datasets['existing dataset']
dataset.update_from_dataframe(
dataframe=frame2,
data_type_id=DataTypeIds.GenericTSV,
)
print(dataset.data_type_id) # 'GenericTSV'
print(dataset.name) # 'existing dataset'
print(dataset.description) # 'data up to jan 2015'
You can optionally set a new description by specifying a value for the description parameter.
dataset = ws.datasets['existing dataset']
dataset.update_from_dataframe(
dataframe=frame2,
description='data up to feb 2015',
)
print(dataset.data_type_id) # 'GenericCSV'
print(dataset.name) # 'existing dataset'
print(dataset.description) # 'data up to feb 2015'
You can optionally set a new name by specifying a value for the name parameter. From now on, you'll retrieve the dataset using the new name only. The following code updates the data, name and description.
dataset = ws.datasets['existing dataset']
dataset.update_from_dataframe(
dataframe=frame2,
name='existing dataset v2',
description='data up to feb 2015',
)
print(dataset.data_type_id) # 'GenericCSV'
print(dataset.name) # 'existing dataset v2'
print(dataset.description) # 'data up to feb 2015'
print(ws.datasets['existing dataset v2'].name) # 'existing dataset v2'
print(ws.datasets['existing dataset'].name) # IndexError
The data_type_id, name and description parameters are optional and default to their previous value. The dataframe parameter is always required.
If your data is already serialized, use update_from_raw_data instead of update_from_dataframe. If you just pass in raw_data instead of dataframe, it works in a similar way.