
Open source framework for processing, monitoring, and alerting on time series data
This README gives you a high level overview of what Kapacitor is and what its like to use it. As well as some details of how it works. To get starting using Kapacitor see this guide.
There are two different ways to consume Kapacitor.
- Define tasks that process streams of data. This method provides low latency (order of 100ms) processing but without aggregations or anything, just the raw data stream.
- Define tasks that process batches of data. The batches are the results of scheduled queries. This method is higher latency (order of 10s) but allows for aggregations or anything else you can do with a query.
-
Start Kapacitor
$ kapacitord
-
Start a data stream. Configure telegraf with an output to Kapacitor.
-
Create a replayable snapshot
-
Select data from an existing InfluxDB host and save it:
$ kapacitor record query -type stream -query 'select value from cpu_idle where time > start and time < stop' b6d1de3f-b27f-4420-96ee-b0365d859d1c -
Or record the live stream for a bit:
$ kapacitor record stream -duration 60s b6d1de3f-b27f-4420-96ee-b0365d859d1c
-
Define a Kapacitor
streamtask. Astreamtask is an entity that defines what data should be processed and how.$ kapacitor define \ -type stream \ -name alert_cpu_idle_any_host \ -tick path/to/tick/script -
Replay the recording to test the task.
$ kapacitor replay \ -id b6d1de3f-b27f-4420-96ee-b0365d859d1c \ -name alert_cpu_idle_any_host -
Edit the
streamand test until its working$ kapacitor define \ -type stream \ -name alert_cpu_idle_any_host \ -tick path/to/tick/script $ kapacitor replay \ -id b6d1de3f-b27f-4420-96ee-b0365d859d1c \ -name alert_cpu_idle_any_host -
Enable or push the
streamonce you are satisfied that it is working$ # enable the stream locally $ kapacitor enable alert_cpu_idle_any_host $ # or push the tested stream to a prod server $ kapacitor push -remote http://address_to_remote_kapacitor alert_cpu_idle_any_host
-
Start Kapacitor
$ kapacitord
-
Define a
batchtask . Like astreamabatchtask defines what data to process and how, only it operates on batches of data instead of streams.$ kapacitor define \ -type batch \ -name alert_mean_cpu_idle_logs_by_dc \ -tick path/to/tick/script -
Save a batch of data for replaying using the definition in the
batch.$ kapacitor record batch alert_mean_cpu_idle_logs_by_dc e6d1de3f-b27f-4420-96ee-b0365d859d1c
-
Replay the batch of data to the
batch.$ kapacitor replay \ -id e6d1de3f-b27f-4420-96ee-b0365d859d1c \ -name alert_mean_cpu_idle_logs_by_dc -
Iterate on the
batchdefinition until it works$ kapacitor define batch \ -type batch \ -name alert_mean_cpu_idle_logs_by_dc \ -tick path/to/tick/script $ kapacitor replay \ -id e6d1de3f-b27f-4420-96ee-b0365d859d1c \ -name alert_mean_cpu_idle_logs_by_dc -
Once it works, enable locally or push to remote
$ # enable the batch locally $ kapacitor enable alert_mean_cpu_idle_logs_by_dc $ # or push the tested batch to a prod server $ kapacitor push -remote http://address_to_remote_kapacitor alert_mean_cpu_idle_logs_by_dc
Processing data follows a pipeline and depending on the processing needs that pipeline can vary significantly. Kapacitor models the different data processing pipelines as a DAGs (Directed Acyclic Graphs) and allows the user to specify the structure of the DAG via a DSL.
Kapacitor allows you to define the DAG implicitly via operators and invocation chaining in an pipeline API. Similar to how Flink and Spark work.
Kapacitor uses a DSL called TICK to define the DAG so that you are not required to write and compile Go code.
The following is an example TICK script that triggers an alert if idle cpu drops below 30%. In the language the variable stream represents the stream of values.
stream
.from("cpu_idle")
.where("cpu = 'cpu-total'")
.window()
.period(10s)
.every(5s)
.mapReduce(influxql.mean("value"))
.alert()
.crit("value < 30")
.email("[email protected]")
This script maintains a window of data for 10s and emits the current window every 5s.
Then the average is calculated for each emitted window.
Finally all values less than 30 pass through the where condition and make it to the alert node, which triggers the alert by sending an email.
The DAG that is constructed from the script looks like this:
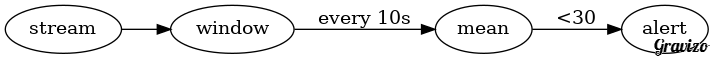
Based on how the DAG is constructed you can use the TICK language to both construct the DAG and define what each node does via built-in functions.
Notice how the map function took an argument of another function influxql.mean, this is an example of a built-in function that can be used to process the data stream.
It will also be possible to define your own functions via plugins to Kapacitor and reference them in the DSL.
By adding groupBy statements we can see how to easily partition our data set and process each group independently.
stream
.groupBy("dc")
.window()
.period(10s)
.every(5s)
.mapReduce(influxql.mean("value"))
.alert()
.crit("value < 30")
.email("[email protected]")
Batch processors work similarly to the stream processing.
Example TICK script for batchs where we are running a query every minute and want to alert on cpu. The query: select mean(value) from cpu_idle group by dc, time(1m).
batch
.query("select max(value) from cpu_idle where role = 'logs'")
.period(15m)
// or .cron("*/15 * * * 0")
.groupBy(time(1h), "dc")
.alert()
.crit("value < 30")
.email("[email protected]")
The main difference is instead of a stream object we start with a batch object. Since batches are already windowed there is not need to define a new window.
- Define the DAG for your data pipeline needs.
- Window data. Windowing can be done by time or by number of data points and various other conditions, see this.
- Aggregate data. The list of aggregation functions currently supported by InfluxQL is probably a good place to start.
- Transform data via built-in functions.
- Transform data via custom functions.
- Filter down streams/batches of data.
- Emit data into a new stream.
- Emit data into an InfluxDB database.
- Trigger events/notifications.
- Define custom functions in the language. You can call out to custom functions defined via a plugins but you cannot define the function itself within the DSL. The DSL will be too slow to actually process any of the data but is used simply to define the data flow.
Several examples demonstrating various features of Kapacitor follow:
If your stream stops sending data this may be serious cause for concern. Setting up a 'dead man's switch' is quite simple:
//Create dead man's switch
stream
.fork()
.window()
.period(1m)
.every(1m)
.mapReduce(influxql.count("value"))
.alert()
.crit("count = 0")
.email("[email protected]")
//Now define normal processing on the stream
stream
.fork()
...
stream
.window()
...
.alert()
.crit("true")
.flapping(0.2, 0.5)
.email("[email protected]")
If you are monitoring lots of stats for a service across multiple hosts and the host dies you would rather get a single alert that the host is dead and not 10 alerts for each stat.
For example say we are monitoring a redis cluster and we have stats cpu and redis.instantaneous_ops_per_sec.
Using the following script we setup alerts for each host if cpu get too high or if redis.instantaneous_ops_per_sec drops too low.
// Alert on redis stats
var redis = stream.fork()
.from("redis")
.where("instantaneous_ops_per_sec < 10")
.groupBy("host")
.alert()
.crit("true")
.email("[email protected]")
var cpu = stream.fork()
.from("cpu")
.where("idle < 20")
.groupBy("host")
.alert()
.crit("true")
.email("[email protected]")
Now lets say we want to combine the alerts so that if a either alert triggers we can send them in the same alert.
var redis = stream
.from("redis")
.where("instantaneous_ops_per_sec < 10")
var cpu = stream
.from("cpu")
.where("idle < 20")
redis.union(cpu)
.groupBy("host")
.window()
.period(10s)
.every(10s)
.alert()
.crit("true")
.email("[email protected]")
This will aggregate the union of all alerts every 10s by host. Then it will send out one alert with the aggregate information. You could easily add more alerts to the union like so.
redis.union(cpu, mem, disk, ...)
Or if you wanted to group by service instead of host just change the groupBy field.
redis.union(cpu)
.groupBy("service")
...
Now lets say we want to perform some custom processing on a stream of data and then keep the resulting time series data.
stream
... //Define custom processing pipeline
.influxDBOut()
.database("mydb")
.retentionPolicy("myrp")
.measurement("m")
Or you simply need to keep the data cached so you can request it when you need it.
stream
... //Define custom processing pipeline
.httpOut("custom_data_set")
Now you can make a request to http://kapacitorhost:9092/api/v1/<task_name>/custom_data_set.
The data returned will be the current value of the result.
What about when you want to do something not built-in to Kapacitor? Simply load your custom functions in the DSL like so:
var fMap = loadMapFunc("./mapFunction.py")
var fReduce = loadReduceFunc("./reduceFunction.py")
stream
.from("cpu")
.where("host", "=", "serverA")
.window()
.period(1s)
.every(1s)
.map(fMap("idle"))
.reduce(fReduce)
.httpOut("http://example.com/path")
The mapFunction.py and reduceFunction.py files contain python scripts that read data on an incoming stream perform their function and output the result.
More on how to write these custom functions later...