The RDFS/OWL-ontology maintained in Github is the normative, declarative representation of the IDS Information Model. It is framed by the conceptual representation laid down in the Reference Architecture Model (RAM v2) and mapped to programmatic representations supporting a native development within a programming language, e.g. Java.
The overall purpose of this formal model is to enable a (semi)automated exchange of digital assets within a network of distributed parties while maintaining their sovereignty on those assets. Given such a broad functional scope intersected with respective business domains (logistics, agriculture, energy etc.) the Information Model is a subject to perpetual evolution and refinement lead by clear design principles. These are, among others:
- reuse: body of existing work (standards, ontologies, scientific publications etc.) is evaluated and re-used. It either informs or is effectively used in the development of the Information Model, e.g. by extending classes and properties of vocabularies like DCAT.
- re-usability: model constituents are designed for re-usability within different contexts, thus reducing model extent and complexity
- separation of concerns: as a prerequisite to re-usability each constituent or set of constituents is modeled according to a dedicated concern addressed.
The mnemonic hexagonal arrangement of Carbon atoms was chosen to illustrate the main Concerns of the Information Model. The key asset - digital Content - is located at its top. It becomes interpretable by referencing shared, formally defined Concepts, whereas links to a particular Context (time range, place and real-world entities) make the content relevant for some clients. While the upper layer of the C-Hexagon deals with the "what", independently of sharing or utilization, the lower part looks at the "how" aspects, i.e. how is the content exchanged (Communication) and at which conditions (Commodization). Community of trust refers to the distinctive feature of the Data Space, an ecosystem of certified participants and components that exchange and leverage digital contents in accordance with usage policies imposed by the sovereign data provider.
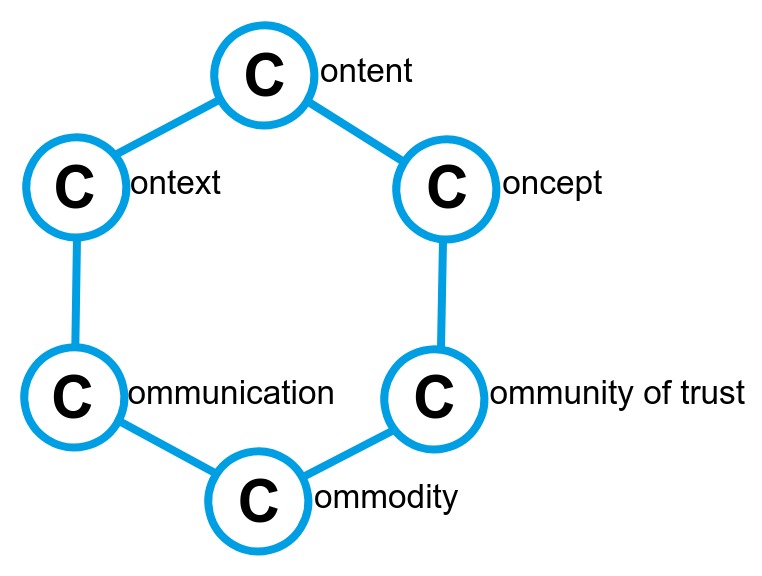
Some of the sub-models below directly map to the above mentioned concerns, some follow a more detailed view on particular aspects (e.g. participants).
Each of the sub-models represents an individual modeling facet:
-
communication: Interaction with data sources, data sinks and data processing applications -
content: Layered modeling of various types ofDigital Content -
context: References to time, space (geometry) and world entities -
contract: Digital contracts determining conditions of data retrieval, subscription and usage -
goverance: Concepts of certification, governance, and data sovereignty -
infrastructure: Building blocks of the Data Space (Connector, Broker, AppStore etc.) -
participant: Participants involved in Data Space interactions and operations -
quality: Quality aspects of data and services -
security: Security features of the components and their communication -
shared: Generic, re-usable models -
traceability: Provenance and logging of Data Space resources and events