This work is used for reproduce MTCNN,a Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks.
- You need CUDA-compatible GPUs to train the model.
- You should first download WIDER Face and Celeba.WIDER Face for face detection and Celeba for landmark detection(This is required by original paper.But I found some labels were wrong in Celeba. So I use this dataset for landmark detection).
- Tensorflow 1.2.1
- TF-Slim
- Python 2.7
- Ubuntu 16.04
- Cuda 8.0
- Download Wider Face Training part only from Official Website , unzip to replace
WIDER_trainand put it intoprepare_datafolder. - Download landmark training data from here,unzip and put them into
prepare_datafolder. - Run
prepare_data/gen_12net_data.pyto generate training data(Face Detection Part) for PNet. - Run
gen_landmark_aug_12.pyto generate training data(Face Landmark Detection Part) for PNet. - Run
gen_imglist_pnet.pyto merge two parts of training data. - Run
gen_PNet_tfrecords.pyto generate tfrecord for PNet. - After training PNet, run
gen_hard_exampleto generate training data(Face Detection Part) for RNet. - Run
gen_landmark_aug_24.pyto generate training data(Face Landmark Detection Part) for RNet. - Run
gen_imglist_rnet.pyto merge two parts of training data. - Run
gen_RNet_tfrecords.pyto generate tfrecords for RNet.(you should run this script four times to generate tfrecords of neg,pos,part and landmark respectively) - After training RNet, run
gen_hard_exampleto generate training data(Face Detection Part) for ONet. - Run
gen_landmark_aug_48.pyto generate training data(Face Landmark Detection Part) for ONet. - Run
gen_imglist_onet.pyto merge two parts of training data. - Run
gen_ONet_tfrecords.pyto generate tfrecords for ONet.(you should run this script four times to generate tfrecords of neg,pos,part and landmark respectively)
-
When training PNet,I merge four parts of data(pos,part,landmark,neg) into one tfrecord,since their total number radio is almost 1:1:1:3.But when training RNet and ONet,I generate four tfrecords,since their total number is not balanced.During training,I read 64 samples from pos,part and landmark tfrecord and read 192 samples from neg tfrecord to construct mini-batch.
-
It's important for PNet and RNet to keep high recall radio.When using well-trained PNet to generate training data for RNet,I can get 14w+ pos samples.When using well-trained RNet to generate training data for ONet,I can get 19w+ pos samples.
-
Since MTCNN is a Multi-task Network,we should pay attention to the format of training data.The format is:
[path to image][cls_label][bbox_label][landmark_label]
For pos sample,cls_label=1,bbox_label(calculate),landmark_label=[0,0,0,0,0,0,0,0,0,0].
For part sample,cls_label=-1,bbox_label(calculate),landmark_label=[0,0,0,0,0,0,0,0,0,0].
For landmark sample,cls_label=-2,bbox_label=[0,0,0,0],landmark_label(calculate).
For neg sample,cls_label=0,bbox_label=[0,0,0,0],landmark_label=[0,0,0,0,0,0,0,0,0,0].
-
Since the training data for landmark is less.I use transform,random rotate and random flip to conduct data augment(the result of landmark detection is not that good).
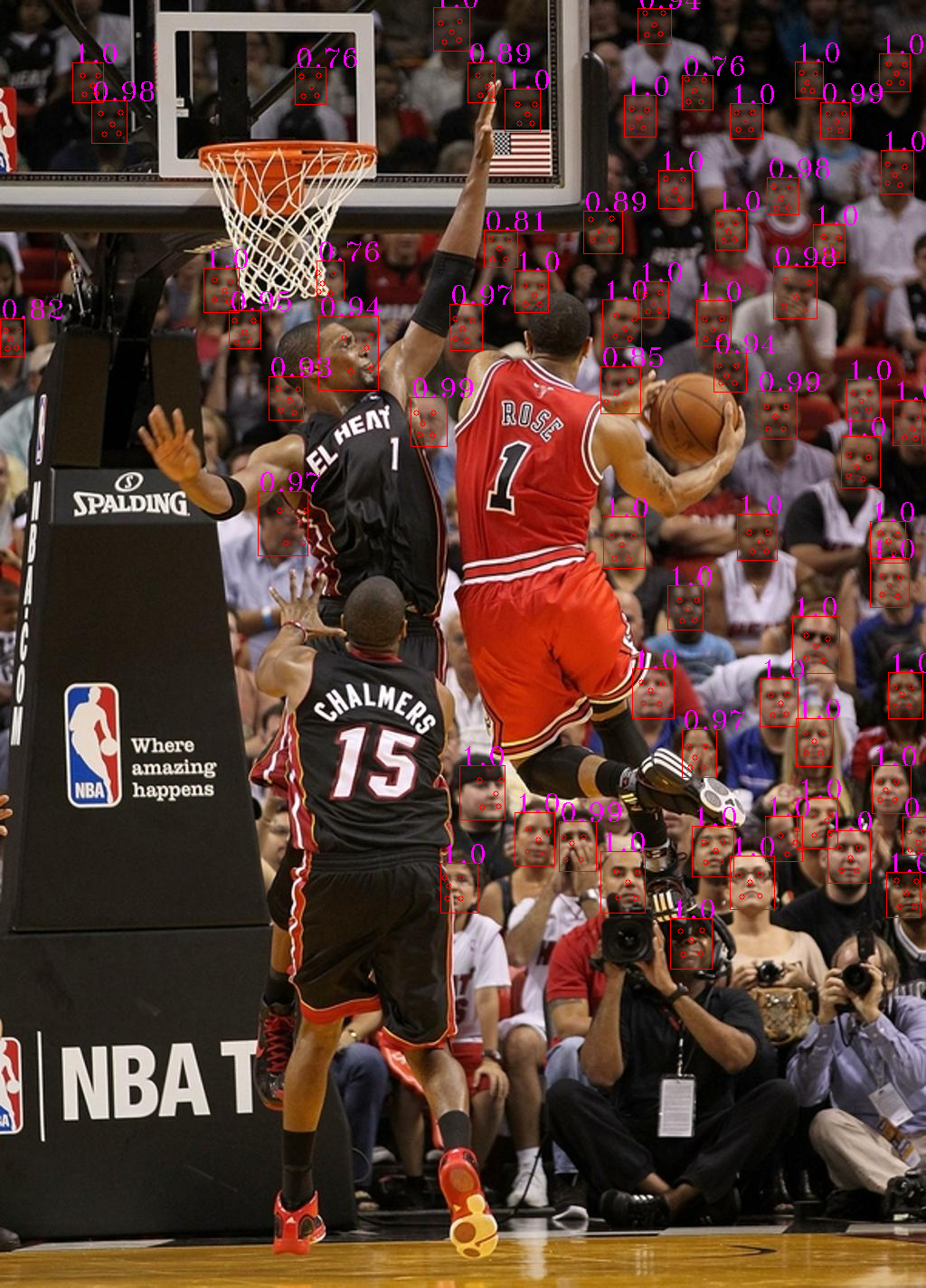






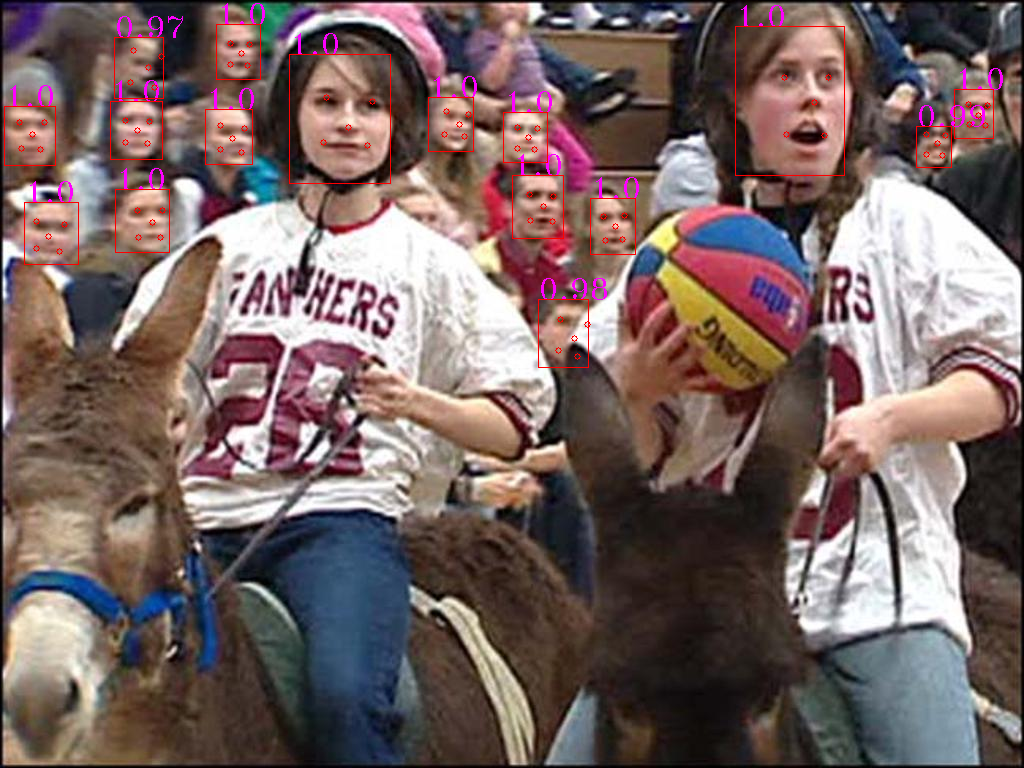

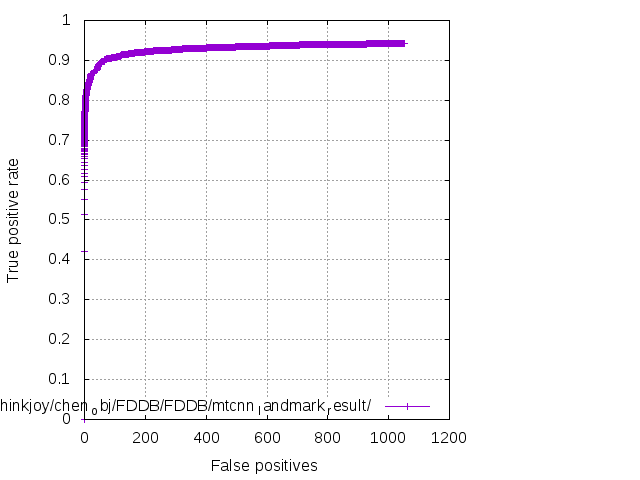
Result on FDDB
MIT LICENSE
- Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao , " Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks," IEEE Signal Processing Letter
- MTCNN-MXNET
- MTCNN-CAFFE
- deep-landmark