

Attention mechanism for processing sequential data that considers the context for each timestamp.

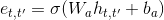


pip install keras-self-attentionBy default, the attention layer uses additive attention and considers the whole context while calculating the relevance. The following code creates an attention layer that follows the equations in the first section (attention_activation is the activation function of e_{t, t'}):
from tensorflow import keras
from keras_self_attention import SeqSelfAttention
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=10000,
output_dim=300,
mask_zero=True))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128,
return_sequences=True)))
model.add(SeqSelfAttention(attention_activation='sigmoid'))
model.add(keras.layers.Dense(units=5))
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['categorical_accuracy'],
)
model.summary()The global context may be too broad for one piece of data. The parameter attention_width controls the width of the local context:
from keras_self_attention import SeqSelfAttention
SeqSelfAttention(
attention_width=15,
attention_activation='sigmoid',
name='Attention',
)You can use multiplicative attention by setting attention_type:

from keras_self_attention import SeqSelfAttention
SeqSelfAttention(
attention_width=15,
attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL,
attention_activation=None,
kernel_regularizer=keras.regularizers.l2(1e-6),
use_attention_bias=False,
name='Attention',
)
To use the regularizer, set attention_regularizer_weight to a positive number:
from tensorflow import keras
from keras_self_attention import SeqSelfAttention
inputs = keras.layers.Input(shape=(None,))
embd = keras.layers.Embedding(input_dim=32,
output_dim=16,
mask_zero=True)(inputs)
lstm = keras.layers.Bidirectional(keras.layers.LSTM(units=16,
return_sequences=True))(embd)
att = SeqSelfAttention(attention_type=SeqSelfAttention.ATTENTION_TYPE_MUL,
kernel_regularizer=keras.regularizers.l2(1e-4),
bias_regularizer=keras.regularizers.l1(1e-4),
attention_regularizer_weight=1e-4,
name='Attention')(lstm)
dense = keras.layers.Dense(units=5, name='Dense')(att)
model = keras.models.Model(inputs=inputs, outputs=[dense])
model.compile(
optimizer='adam',
loss={'Dense': 'sparse_categorical_crossentropy'},
metrics={'Dense': 'categorical_accuracy'},
)
model.summary(line_length=100)Make sure to add SeqSelfAttention to custom objects:
from tensorflow import keras
keras.models.load_model(model_path, custom_objects=SeqSelfAttention.get_custom_objects())Set history_only to True when only historical data could be used:
SeqSelfAttention(
attention_width=3,
history_only=True,
name='Attention',
)Please refer to keras-multi-head.