From 5859edd87f94c8da514826dc447c4c96d57d86c3 Mon Sep 17 00:00:00 2001
From: lijialin03 <124568209+lijialin03@users.noreply.github.com>
Date: Wed, 18 Sep 2024 11:23:11 +0800
Subject: [PATCH] [Example]Add brusselator3d example and LNO net (#988)
* [Example]Add brusselator3d example and LNOnD net
* update code
* update plot function and add doc
* add lno to arch.md
---
docs/zh/api/arch.md | 1 +
docs/zh/examples/brusselator3d.md | 198 +++++++++
examples/brusselator3d/brusselator3d.py | 379 ++++++++++++++++++
.../brusselator3d/conf/brusselator3d.yaml | 95 +++++
mkdocs.yml | 1 +
ppsci/arch/__init__.py | 2 +
ppsci/arch/lno.py | 308 ++++++++++++++
7 files changed, 984 insertions(+)
create mode 100644 docs/zh/examples/brusselator3d.md
create mode 100644 examples/brusselator3d/brusselator3d.py
create mode 100644 examples/brusselator3d/conf/brusselator3d.yaml
create mode 100644 ppsci/arch/lno.py
diff --git a/docs/zh/api/arch.md b/docs/zh/api/arch.md
index 97065a718..34ab16092 100644
--- a/docs/zh/api/arch.md
+++ b/docs/zh/api/arch.md
@@ -33,5 +33,6 @@
- UNetEx
- UNONet
- USCNN
+ - LNO
show_root_heading: true
heading_level: 3
diff --git a/docs/zh/examples/brusselator3d.md b/docs/zh/examples/brusselator3d.md
new file mode 100644
index 000000000..0d98dfcb4
--- /dev/null
+++ b/docs/zh/examples/brusselator3d.md
@@ -0,0 +1,198 @@
+# 3D-Brusselator
+
+
+
+=== "模型训练命令"
+
+ ``` sh
+ # linux
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz
+ # windows
+ # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz -o brusselator3d_dataset.tar
+ python brusselator3d.py
+ ```
+
+=== "模型评估命令"
+
+ ``` sh
+ # linux
+ wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz
+ # windows
+ # curl https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz -o brusselator3d_dataset.tar
+ python brusselator3d.py mode=eval EVAL.pretrained_model_path=https://paddle-org.bj.bcebos.com/paddlescience/models/Brusselator3D/brusselator3d_pretrained.pdparams
+ ```
+
+
+| 预训练模型 | 指标 |
+|:--| :--|
+| [brusselator3d_pretrained.pdparams](https://paddle-org.bj.bcebos.com/paddlescience/models/Brusselator3D/brusselator3d_pretrained.pdparams) | loss(sup_validator): 16.87812
L2Rel.output(sup_validator): 0.08544 |
+
+## 1. 背景简介
+
+该案例引入拉普拉斯神经算子(LNO)来构建深度学习网络,它利用拉普拉斯变换来分解输入空间。与傅里叶神经算子 (FNO) 不同,LNO 可以处理非周期信号、考虑瞬态响应并表现出指数收敛,它结合了输入和输出空间之间的极点-残差关系,从而实现了更大的可解释性和改进的泛化能力。LNO 中单个拉普拉斯层与 FNO 中的四个傅里叶模块上精度近似,对于非线性反应扩散系统,LNO的误差小于FNO。
+
+该案例研究 LNO 网络在布鲁塞尔反应扩散系统上的应用。
+
+## 2. 问题定义
+
+反应扩散系统描述了化学物质或粒子的浓度随时间和空间的变化,常应用于化学、生物学、地质学和物理学。扩散反应方程可以表示为:
+
+$$D\frac{\partial^2 y}{\partial x^2}+ky^2-\frac{\partial y}{\partial t}=f(x,t)$$
+
+其中 $y(x,t)$ 表示化学物质或颗粒在位置x和时间t的浓度,$f(x,t)$ 是源项,$D$ 是扩散系数,$k$ 是反应速率。
+
+## 3. 问题求解
+
+接下来开始讲解如何将问题一步一步地转化为 PaddleScience 代码,用深度学习的方法求解该问题。
+为了快速理解 PaddleScience,接下来仅对模型构建、方程构建、计算域构建等关键步骤进行阐述,而其余细节请参考 [API文档](../api/arch.md)。
+
+### 3.1 数据集介绍
+
+数据集为使用 LNO 论文原代码提供的数据集,数据集中包含训练集输入、标签数据,验证集输入、标签数据,数据存储在 `.npz` 文件中,在训练前需要读入数据。
+
+运行本问题代码前请下载 [数据集](https://paddle-org.bj.bcebos.com/paddlescience/datasets/Brusselator3D/brusselator3d_dataset.npz),并存放在相应路径:
+
+``` yaml linenums="39"
+--8<--
+examples/brusselator3d/conf/brusselator3d.yaml:39:40
+--8<--
+```
+
+### 3.2 模型构建
+
+
+ 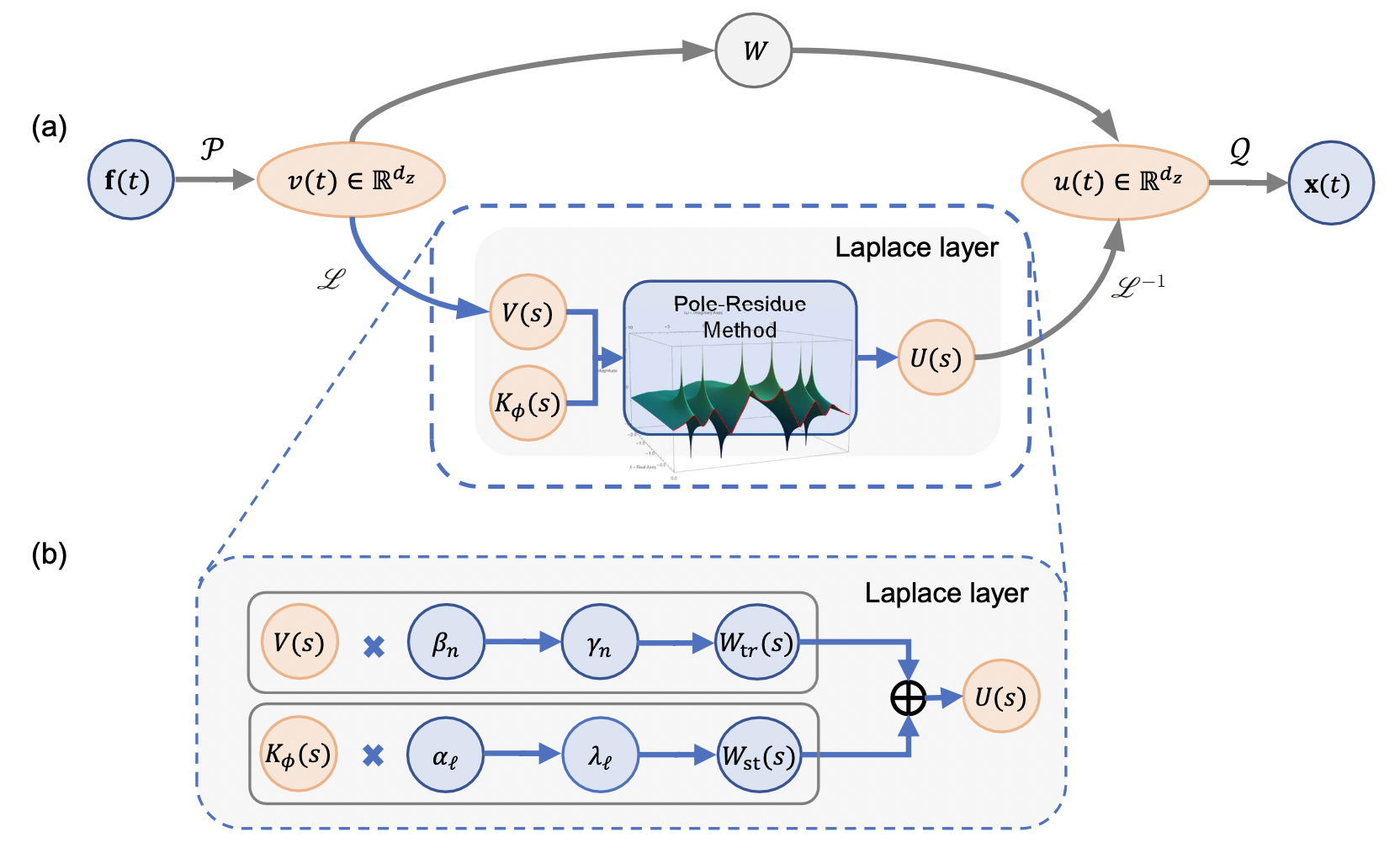{ loading=lazy style="margin:0 auto"}
+ (a) LNO 整体架构 (b) Laplace 层
+
+
+上图为 LNO 整体架构和 Laplace 层示意图。输入数据进入网络后,先通过浅神经网络 $P$ 提升到更高的维度,之后一方面进行局部线性变换 $W$,另一方面应用拉普拉斯层,之后再将这两条路径的结果进行加和,最后再通过浅神经网络 $Q$ 返回目标维度。
+
+拉普拉斯层中的,上面一行代表应用极残差法来计算基于系统极 $\mu_{n}$ 和残差 $\beta_{n}$ 的瞬态响应残差 $\gamma_{n}$ 表示拉普拉斯域中的瞬态响应,下面一行代表应用极残差方法,根据输入极 $i\omega_{l}$ 和残差 $i\alpha_{l}$ 计算稳态响应残差 $i\lambda_{l}$ 表示拉普拉斯域中的稳态响应。
+
+具体代码请参考 [完整代码](#4) 中 lno.py 文件。
+
+在构建网络之前,需要根据参数设定,使用 `linespace` 明确各个维度长度,以便 LNO 网络进行 $\lambda$ 的初始化。用 PaddleScience 代码表示如下:
+
+``` py linenums="114"
+--8<--
+examples/brusselator3d/brusselator3d.py:114:122
+--8<--
+```
+
+### 3.3 参数和超参数设定
+
+我们需要指定问题相关的参数,如数据集路径、各个维度长度等。
+
+``` yaml linenums="32"
+--8<--
+examples/brusselator3d/conf/brusselator3d.yaml:32:40
+--8<--
+```
+
+另外需要在配置文件中指定训练轮数、`batch_size` 等其他训练所需参数。
+
+``` yaml linenums="54"
+--8<--
+examples/brusselator3d/conf/brusselator3d.yaml:54:58
+--8<--
+```
+
+### 3.4 优化器构建
+
+训练过程会调用优化器来更新模型参数,此处选择 `AdamW` 优化器,并配合使用机器学习中常用的 StepDecay 学习率调整策略。
+
+`AdamW` 优化器基于 `Adam` 优化器进行了改进,用来解决 `Adam` 优化器中 L2 正则化失效的问题。
+
+``` py linenums="124"
+--8<--
+examples/brusselator3d/brusselator3d.py:124:128
+--8<--
+```
+
+### 3.5 约束构建
+
+本问题采用监督学习的方式进行训练,仅存在监督约束 `SupervisedConstraint`,代码如下:
+
+``` py linenums="130"
+--8<--
+examples/brusselator3d/brusselator3d.py:130:156
+--8<--
+```
+
+`SupervisedConstraint` 的第一个参数是监督约束的读取配置,其中 `dataset` 字段表示使用的训练数据集信息,各个字段分别表示:
+
+1. `name`: 数据集类型,此处 `NamedArrayDataset` 表示从 Array 中读取的数据集;
+2. `input`: Array 类型的输入数据;
+3. `label`: Array 类型的标签数据;
+
+`batch_size` 字段表示 batch 的大小;
+
+`sampler` 字段表示采样方法,其中各个字段表示:
+
+1. `name`: 采样器类型,此处 `BatchSampler` 表示批采样器;
+2. `drop_last`: 是否需要丢弃最后无法凑整一个 mini-batch 的样本,设为 False;
+3. `shuffle`: 是否需要在生成样本下标时打乱顺序,设为 True;
+
+`num_workers` 字段表示 输入加载时的线程数;
+
+第二个参数是损失函数,这里选用常用的 L2Rel 损失函数,且 reduction 设置为 "sum" ,即将参与计算的所有数据点产生的损失项求和;
+
+第三个参数是约束条件的名字,我们需要给每一个约束条件命名,方便后续对其索引。
+
+``` py linenums="158"
+--8<--
+examples/brusselator3d/brusselator3d.py:158:159
+--8<--
+```
+
+### 3.6 评估器构建
+
+在训练过程中通常会按一定轮数间隔,用验证集(测试集)评估当前模型的训练情况,因此需要构建评估器:
+
+``` py linenums="161"
+--8<--
+examples/brusselator3d/brusselator3d.py:161:189
+--8<--
+```
+
+其中大部分参数含义与约束器中类似,不同的参数有:
+
+第三个参数是输出的转写公式 `output_expr`,规定了最终输入数据的 key 和 value。
+
+第四个参数是误差评估函数,这里选用的 L2Rel Error 函数,reduction 未设置,即为默认值 "mean" ,将参与计算的所有数据点产生的 Error 求平均;
+
+
+### 3.7 模型训练、评估
+
+完成上述设置之后,只需要将上述实例化的对象按顺序传递给 `ppsci.solver.Solver`,然后启动训练、评估、可视化。
+
+``` py linenums="191"
+--8<--
+examples/brusselator3d/brusselator3d.py:191:204
+--8<--
+```
+
+## 4. 完整代码
+
+``` py linenums="1" title="brusselator3d.py"
+--8<--
+examples/brusselator3d/brusselator3d.py
+--8<--
+```
+
+## 5. 结果展示
+
+下面展示了在验证集上的预测结果和标签。
+
+
+ 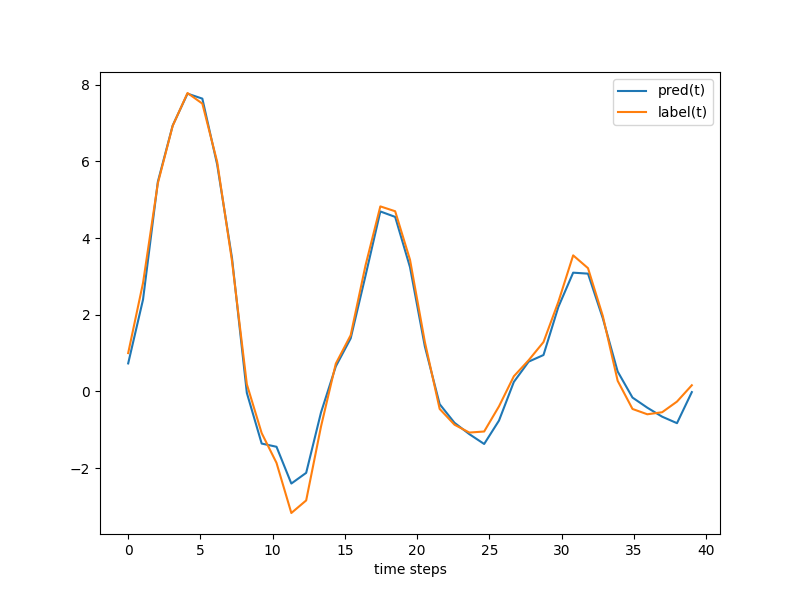{ loading=lazy }
+ 蓝线为预测结果,黄线为标签
+
+
+可以看到模型预测的结果与标签基本一致。
+
+## 6. 参考文献
+
+- [LNO: Laplace Neural Operator for Solving Differential Equations](https://arxiv.org/abs/2303.10528)
+
+- [参考代码](https://github.com/qianyingcao/Laplace-Neural-Operator/tree/main/3D_Brusselator)
diff --git a/examples/brusselator3d/brusselator3d.py b/examples/brusselator3d/brusselator3d.py
new file mode 100644
index 000000000..0c879e4bd
--- /dev/null
+++ b/examples/brusselator3d/brusselator3d.py
@@ -0,0 +1,379 @@
+"""
+Paper: https://arxiv.org/abs/2303.10528
+Reference: https://github.com/qianyingcao/Laplace-Neural-Operator/tree/main/3D_Brusselator
+"""
+from os import path as osp
+from typing import List
+from typing import Literal
+from typing import Tuple
+
+import hydra
+import matplotlib.pyplot as plt
+import numpy as np
+import paddle
+from omegaconf import DictConfig
+
+import ppsci
+from ppsci.utils import reader
+
+
+class DataFuncs:
+ def __init__(self, orig_r: int, r: int, nt: int, nx: int, ny: int) -> None:
+ """Functions of data.
+
+ Args:
+ orig_r (int): Oringinal resolution of data.
+ r (int): Multiples of downsampling at resolution.
+ nt (int): The number of values to take on t.
+ nx (int): The number of values to take on x.
+ ny (int): The number of values to take on y.
+ """
+ self.orig_r = orig_r
+ self.r = r
+ self.nt = nt
+ self.nx = nx
+ self.ny = ny
+
+ self.s = int((orig_r - 1) / r + 1)
+
+ x = np.linspace(0, 1, orig_r)
+ y = np.linspace(0, 1, orig_r)
+ t = np.linspace(0, 1, nt)
+ self.tt, self.xx, self.yy = np.meshgrid(t, x, y, indexing="ij")
+
+ def load_data(self, data_path, keys) -> List[np.ndarray]:
+ raw_data = reader.load_npz_file(data_path, keys)
+ return [raw_data[key] for key in keys]
+
+ def get_mean_std(self, data: np.ndarray) -> Tuple[float, ...]:
+ min_ = np.min(data)
+ max_ = np.max(data)
+ return (min_ + max_) / 2, (max_ - min_) / 2
+
+ def encode(self, data, mean, std) -> np.ndarray:
+ return (data - mean) / std
+
+ def decode(self, data, mean, std) -> np.ndarray:
+ return data * std + mean
+
+ def gen_grid(self, grid, num) -> np.ndarray:
+ grid_tile = np.tile(grid, (num, 1, 1, 1))
+ grid_subsampling = grid_tile[:, :, :: self.r, :: self.r]
+ grid_crop = grid_subsampling[:, :, : self.s, : self.s]
+ grid_reshape = np.reshape(grid_crop, (num, self.nt, self.s, self.s, 1))
+ return grid_reshape
+
+ def cat_grid(self, data) -> np.ndarray:
+ grid_t = self.gen_grid(self.tt, data.shape[0])
+ grid_x = self.gen_grid(self.xx, data.shape[0])
+ grid_y = self.gen_grid(self.yy, data.shape[0])
+ return np.concatenate([data, grid_t, grid_x, grid_y], axis=-1).astype(
+ data.dtype
+ )
+
+ def transform(
+ self, data: np.ndarray, key: Literal["input", "label"] = "input"
+ ) -> np.ndarray:
+ if key == "input":
+ data_expand = np.expand_dims(data, axis=0)
+ data_tile = np.tile(data_expand, (self.orig_r, self.orig_r, 1, 1))
+ data = np.transpose(data_tile, axes=(2, 3, 0, 1))
+ data_subsampling = data[:, :, :: self.r, :: self.r]
+ data_crop = data_subsampling[:, :, : self.s, : self.s]
+ data_reshape = np.reshape(
+ data_crop, (data.shape[0], self.nt, self.s, self.s, 1)
+ )
+ return data_reshape
+
+ def draw_plot(self, save_path, pred, label):
+ pred = np.mean(pred, axis=(1, 2))
+ label = np.mean(label, axis=(1, 2))
+ t = np.linspace(0, self.nt, self.nt)
+ plt.figure(figsize=(8, 6))
+ plt.plot(t, pred, label="pred(t)")
+ plt.plot(t, label, label="label(t)")
+ plt.xlabel("time steps")
+ plt.legend()
+ plt.savefig(save_path)
+
+
+def train(cfg: DictConfig):
+ # set data functions
+ data_funcs = DataFuncs(cfg.ORIG_R, cfg.RESOLUTION, cfg.NUM_T, cfg.NUM_X, cfg.NUM_Y)
+ inputs_train, labels_train, inputs_val, labels_val = data_funcs.load_data(
+ cfg.DATA_PATH,
+ ("inputs_train", "outputs_train", "inputs_test", "outputs_test"),
+ )
+ in_train = data_funcs.transform(inputs_train, "input")
+ label_train = data_funcs.transform(labels_train, "label")
+ in_val = data_funcs.transform(inputs_val, "input")
+ label_val = data_funcs.transform(labels_val, "label")
+ in_train_mean, in_train_std = data_funcs.get_mean_std(in_train)
+ label_train_mean, label_train_std = data_funcs.get_mean_std(label_train)
+
+ # set model
+ T = paddle.linspace(start=0, stop=19, num=cfg.NUM_T).reshape([1, cfg.NUM_T])
+ X = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : data_funcs.s
+ ]
+ Y = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : data_funcs.s
+ ]
+ model = ppsci.arch.LNO(**cfg.MODEL, T=T, Data=(X, Y))
+
+ # set optimizer
+ lr_scheduler = ppsci.optimizer.lr_scheduler.Step(**cfg.TRAIN.lr_scheduler)()
+ optimizer = ppsci.optimizer.AdamW(
+ lr_scheduler, weight_decay=cfg.TRAIN.weight_decay
+ )(model)
+
+ # set constraint
+ sup_constraint = ppsci.constraint.SupervisedConstraint(
+ {
+ "dataset": {
+ "name": "NamedArrayDataset",
+ "input": {
+ "input": data_funcs.cat_grid(
+ data_funcs.encode(in_train, in_train_mean, in_train_std)
+ )
+ },
+ "label": {
+ "output": data_funcs.encode(
+ label_train, label_train_mean, label_train_std
+ )
+ },
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "sampler": {
+ "name": "BatchSampler",
+ "drop_last": False,
+ "shuffle": True,
+ },
+ "num_workers": 1,
+ },
+ ppsci.loss.L2RelLoss("sum"),
+ name="sup_constraint",
+ )
+
+ # wrap constraints together
+ constraint = {sup_constraint.name: sup_constraint}
+
+ # set validator
+ sup_validator = ppsci.validate.SupervisedValidator(
+ {
+ "dataset": {
+ "name": "NamedArrayDataset",
+ "input": {
+ "input": data_funcs.cat_grid(
+ data_funcs.encode(in_val, in_train_mean, in_train_std)
+ )
+ },
+ "label": {"output": label_val},
+ },
+ "batch_size": cfg.TRAIN.batch_size,
+ "num_workers": 1,
+ },
+ ppsci.loss.L2RelLoss("sum"),
+ {
+ "output": lambda out: data_funcs.decode(
+ out["output"],
+ label_train_mean,
+ label_train_std,
+ )
+ },
+ metric={"L2Rel": ppsci.metric.L2Rel()},
+ name="sup_validator",
+ )
+
+ # wrap validator together
+ validator = {sup_validator.name: sup_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ constraint,
+ optimizer=optimizer,
+ validator=validator,
+ cfg=cfg,
+ )
+
+ # train model
+ solver.train()
+
+ # evaluate after finished training
+ solver.eval()
+
+
+def evaluate(cfg: DictConfig):
+ # set data functions
+ data_funcs = DataFuncs(cfg.ORIG_R, cfg.RESOLUTION, cfg.NUM_T, cfg.NUM_X, cfg.NUM_Y)
+ inputs_train, labels_train, inputs_val, labels_val = data_funcs.load_data(
+ cfg.DATA_PATH,
+ ("inputs_train", "outputs_train", "inputs_test", "outputs_test"),
+ )
+ in_train = data_funcs.transform(inputs_train, "input")
+ label_train = data_funcs.transform(labels_train, "label")
+ in_val = data_funcs.transform(inputs_val, "input")
+ label_val = data_funcs.transform(labels_val, "label")
+ in_train_mean, in_train_std = data_funcs.get_mean_std(in_train)
+ label_train_mean, label_train_std = data_funcs.get_mean_std(label_train)
+
+ # set model
+ T = paddle.linspace(start=0, stop=19, num=cfg.NUM_T).reshape([1, cfg.NUM_T])
+ X = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : data_funcs.s
+ ]
+ Y = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : data_funcs.s
+ ]
+ model = ppsci.arch.LNO(**cfg.MODEL, T=T, Data=(X, Y))
+
+ # set validator
+ sup_validator = ppsci.validate.SupervisedValidator(
+ {
+ "dataset": {
+ "name": "NamedArrayDataset",
+ "input": {
+ "input": data_funcs.cat_grid(
+ data_funcs.encode(in_val, in_train_mean, in_train_std)
+ )
+ },
+ "label": {"output": label_val},
+ },
+ "batch_size": cfg.EVAL.batch_size,
+ "num_workers": 1,
+ },
+ ppsci.loss.L2RelLoss("sum"),
+ {
+ "output": lambda out: data_funcs.decode(
+ out["output"],
+ label_train_mean,
+ label_train_std,
+ )
+ },
+ metric={"L2Rel": ppsci.metric.L2Rel()},
+ name="sup_validator",
+ )
+
+ # wrap validator together
+ validator = {sup_validator.name: sup_validator}
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ validator=validator,
+ cfg=cfg,
+ )
+ # evaluate
+ solver.eval()
+
+ # visualize prediction
+ output_dict = model(
+ {
+ "input": paddle.to_tensor(
+ data_funcs.cat_grid(
+ data_funcs.encode(in_val[0:1], in_train_mean, in_train_std)
+ )
+ )
+ }
+ )
+ pred = paddle.squeeze(
+ data_funcs.decode(output_dict["output"], label_train_mean, label_train_std)
+ ).numpy()
+ label = np.squeeze(label_val[0])
+
+ data_funcs.draw_plot(osp.join(cfg.output_dir, "result"), pred, label)
+
+
+def export(cfg: DictConfig):
+ # set model
+ T = paddle.linspace(start=0, stop=19, num=cfg.NUM_T).reshape([1, cfg.NUM_T])
+ X = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : int((cfg.ORIG_R - 1) / cfg.RESOLUTION + 1)
+ ]
+ Y = paddle.linspace(start=0, stop=1, num=cfg.ORIG_R).reshape([1, cfg.ORIG_R])[
+ :, : int((cfg.ORIG_R - 1) / cfg.RESOLUTION + 1)
+ ]
+ model = ppsci.arch.LNO(**cfg.MODEL, T=T, Data=(X, Y))
+
+ # initialize solver
+ solver = ppsci.solver.Solver(
+ model,
+ pretrained_model_path=cfg.INFER.pretrained_model_path,
+ )
+
+ # export model
+ from paddle.static import InputSpec
+
+ input_spec = [
+ {
+ key: InputSpec(
+ [
+ None,
+ cfg.NUM_T,
+ cfg.NUM_X // cfg.RESOLUTION,
+ cfg.NUM_Y // cfg.RESOLUTION,
+ 1,
+ ],
+ "float32",
+ name=key,
+ )
+ for key in model.input_keys
+ },
+ ]
+ solver.export(input_spec, cfg.INFER.export_path)
+
+
+def inference(cfg: DictConfig):
+ from deploy.python_infer import pinn_predictor
+
+ predictor = pinn_predictor.PINNPredictor(cfg)
+
+ # set data functions
+ data_funcs = DataFuncs(cfg.ORIG_R, cfg.RESOLUTION, cfg.NUM_T, cfg.NUM_X, cfg.NUM_Y)
+ inputs_train, labels_train, inputs_val, labels_val = data_funcs.load_data(
+ cfg.DATA_PATH,
+ ("inputs_train", "outputs_train", "inputs_test", "outputs_test"),
+ )
+ in_train = data_funcs.transform(inputs_train, "input")
+ label_train = data_funcs.transform(labels_train, "label")
+ in_val = data_funcs.transform(inputs_val, "input")
+ label_val = data_funcs.transform(labels_val, "label")
+ in_train_mean, in_train_std = data_funcs.get_mean_std(in_train)
+ label_train_mean, label_train_std = data_funcs.get_mean_std(label_train)
+
+ output_dict = predictor.predict(
+ {"input": data_funcs.encode(in_val, in_train_mean, in_train_std)},
+ cfg.INFER.batch_size,
+ )
+
+ # mapping data to cfg.INFER.output_keys
+ output_dict = {
+ store_key: output_dict[infer_key]
+ for store_key, infer_key in zip(cfg.MODEL.output_keys, output_dict.keys())
+ }
+
+ pred = paddle.squeeze(
+ data_funcs.decode(output_dict["output"], label_train_mean, label_train_std)
+ ).numpy()
+ label = np.squeeze(label_val[0])
+
+ data_funcs.draw_plot(osp.join(cfg.output_dir, "result"), pred, label)
+
+
+@hydra.main(version_base=None, config_path="./conf", config_name="brusselator3d.yaml")
+def main(cfg: DictConfig):
+ if cfg.mode == "train":
+ train(cfg)
+ elif cfg.mode == "eval":
+ evaluate(cfg)
+ elif cfg.mode == "export":
+ raise ValueError("Export is not currently supported.")
+ elif cfg.mode == "infer":
+ raise ValueError("Infer is not currently supported.")
+ else:
+ raise ValueError(f"cfg.mode should in ['train', 'eval'], but got '{cfg.mode}'")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/brusselator3d/conf/brusselator3d.yaml b/examples/brusselator3d/conf/brusselator3d.yaml
new file mode 100644
index 000000000..c9bd4883f
--- /dev/null
+++ b/examples/brusselator3d/conf/brusselator3d.yaml
@@ -0,0 +1,95 @@
+defaults:
+ - ppsci_default
+ - TRAIN: train_default
+ - TRAIN/ema: ema_default
+ - TRAIN/swa: swa_default
+ - EVAL: eval_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: outputs_brusselator3d/${now:%Y-%m-%d}/${now:%H-%M-%S}/${hydra.job.override_dirname}
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: train # running mode: train/eval
+seed: 2024
+output_dir: ${hydra:run.dir}
+log_freq: 20
+
+# set constant
+NUM_T: 39
+NUM_X: 28
+NUM_Y: 28
+ORIG_R: 28
+RESOLUTION: 2
+
+# set data path
+DATA_PATH: ./Data/Brusselator_force_train.npz
+
+# model settings
+MODEL:
+ input_keys: ["input"]
+ output_keys: ["output"]
+ width: 8
+ modes: [4, 4, 4]
+ in_features: 4
+ hidden_features: 64
+ activation: "relu"
+ use_norm: true
+ use_grid: false
+
+# training settings
+TRAIN:
+ epochs: 300
+ batch_size: 50
+ iters_per_epoch: 16 # NUM_TRAIN // TRAIN.batch_size
+ lr_scheduler:
+ epochs: ${TRAIN.epochs}
+ iters_per_epoch: ${TRAIN.iters_per_epoch}
+ learning_rate: 0.005
+ gamma: 0.5
+ step_size: 100
+ by_epoch: true
+ weight_decay: 1e-4
+ save_freq: 20
+ eval_freq: 20
+ eval_during_train: true
+ pretrained_model_path: null
+ checkpoint_path: null
+
+# evaluation settings
+EVAL:
+ pretrained_model_path: null
+ eval_with_no_grad: true
+ batch_size: 200
+
+# inference settings
+INFER:
+ pretrained_model_path: null
+ export_path: ./inference/brusselator3d
+ pdmodel_path: ${INFER.export_path}.pdmodel
+ pdiparams_path: ${INFER.export_path}.pdiparams
+ device: gpu
+ engine: native
+ precision: fp32
+ onnx_path: ${INFER.export_path}.onnx
+ ir_optim: true
+ min_subgraph_size: 10
+ gpu_mem: 4000
+ gpu_id: 0
+ max_batch_size: 128
+ num_cpu_threads: 4
+ batch_size: 128
diff --git a/mkdocs.yml b/mkdocs.yml
index a5d97d3bf..e073469f7 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -51,6 +51,7 @@ nav:
- SPINN: zh/examples/spinn.md
- XPINN: zh/examples/xpinns.md
- NeuralOperator: zh/examples/neuraloperator.md
+ - Brusselator3D: zh/examples/brusselator3d.md
- 技术科学(AI for Technology):
- 流体:
- AMGNet: zh/examples/amgnet.md
diff --git a/ppsci/arch/__init__.py b/ppsci/arch/__init__.py
index b6f1f1ce2..04a31308c 100644
--- a/ppsci/arch/__init__.py
+++ b/ppsci/arch/__init__.py
@@ -37,6 +37,7 @@
from ppsci.arch.gan import Generator # isort:skip
from ppsci.arch.graphcast import GraphCastNet # isort:skip
from ppsci.arch.he_deeponets import HEDeepONets # isort:skip
+from ppsci.arch.lno import LNO # isort:skip
from ppsci.arch.mlp import MLP # isort:skip
from ppsci.arch.mlp import ModifiedMLP # isort:skip
from ppsci.arch.mlp import PirateNet # isort:skip
@@ -80,6 +81,7 @@
"GraphCastNet",
"HEDeepONets",
"LorenzEmbedding",
+ "LNO",
"MLP",
"ModelList",
"ModifiedMLP",
diff --git a/ppsci/arch/lno.py b/ppsci/arch/lno.py
new file mode 100644
index 000000000..89df7e6ce
--- /dev/null
+++ b/ppsci/arch/lno.py
@@ -0,0 +1,308 @@
+# Copyright (c) 2024 PaddlePaddle Authors. All Rights Reserved.
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+
+# http://www.apache.org/licenses/LICENSE-2.0
+
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import annotations
+
+import operator
+from functools import reduce
+from typing import Optional
+from typing import Tuple
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from ppsci.arch import activation as act_mod
+from ppsci.arch import base
+from ppsci.utils import initializer
+
+
+class Laplace(nn.Layer):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ modes: Tuple[int, ...],
+ T: paddle.Tensor,
+ Data: Tuple[paddle.Tensor, ...],
+ ):
+ """Generic N-Dimensional Laplace Operator with Pole-Residue Method.
+
+ Args:
+ in_channels (int): Number of input channels of the first layer.
+ out_channels (int): Number of output channels of the last layer.
+ modes (Tuple[int, ...]): Number of modes to use for contraction in Laplace domain during training.
+ T (paddle.Tensor): Linspace of time dimension.
+ Data (Tuple[paddle.Tensor, ...]): Linspaces of other dimensions.
+ """
+ super().__init__()
+ self.char1 = "pqr"
+ self.char2 = "mnk"
+ self.modes = modes
+ self.scale = 1 / (in_channels * out_channels)
+ self.dims = len(modes)
+
+ self.weights_pole_real = nn.ParameterList()
+ self.weights_pole_imag = nn.ParameterList()
+ for i in range(self.dims):
+ weight_real = self._init_weights(
+ self.create_parameter((in_channels, out_channels, modes[i], 1))
+ )
+ weight_imag = self._init_weights(
+ self.create_parameter((in_channels, out_channels, modes[i], 1))
+ )
+ self.weights_pole_real.append(weight_real)
+ self.weights_pole_imag.append(weight_imag)
+
+ residues_shape = (in_channels, out_channels) + modes + (1,)
+ self.weights_residue_real = self._init_weights(
+ self.create_parameter(residues_shape)
+ )
+ self.weights_residue_imag = self._init_weights(
+ self.create_parameter(residues_shape)
+ )
+
+ self.initialize_lambdas(T, Data)
+ self.get_einsum_eqs()
+
+ def _init_weights(self, weight) -> paddle.Tensor:
+ return initializer.uniform_(weight, a=0, b=self.scale)
+
+ def initialize_lambdas(self, T, Data) -> None:
+ self.t_lst = (T,) + Data
+ self.lambdas = []
+ for i in range(self.dims):
+ t_i = self.t_lst[i]
+ dt = (t_i[0, 1] - t_i[0, 0]).item()
+ omega = paddle.fft.fftfreq(n=tuple(t_i.shape)[1], d=dt) * 2 * np.pi * 1.0j
+ lambda_ = omega.reshape([*omega.shape, 1, 1, 1])
+ self.lambdas.append(lambda_)
+
+ def get_einsum_eqs(self) -> None:
+ terms_eq = []
+ terms_x2_eq = []
+ for i in range(self.dims):
+ term_eq = self.char1[i] + "io" + self.char2[i]
+ terms_eq.append(term_eq)
+ term_x2_eq = "io" + self.char2[i] + self.char1[i]
+ terms_x2_eq.append(term_x2_eq)
+ self.eq1 = (
+ "bi"
+ + "".join(self.char1)
+ + ","
+ + "io"
+ + "".join(self.char2)
+ + ","
+ + ",".join(terms_eq)
+ + "->"
+ + "bo"
+ + "".join(self.char1)
+ )
+ self.eq2 = (
+ "bi"
+ + "".join(self.char1)
+ + ","
+ + "io"
+ + "".join(self.char2)
+ + ","
+ + ",".join(terms_eq)
+ + "->"
+ + "bo"
+ + "".join(self.char2)
+ )
+ self.eq_x2 = (
+ "bi"
+ + "".join(self.char2)
+ + ","
+ + ",".join(terms_x2_eq)
+ + "->bo"
+ + "".join(self.char1)
+ )
+
+ def output_PR(self, alpha) -> Tuple[paddle.Tensor, paddle.Tensor]:
+ weights_residue = paddle.as_complex(
+ paddle.concat(
+ [self.weights_residue_real, self.weights_residue_imag], axis=-1
+ )
+ )
+ self.weights_pole = []
+ terms = []
+ for i in range(self.dims):
+ weights_pole = paddle.as_complex(
+ paddle.concat(
+ [self.weights_pole_real[i], self.weights_pole_imag[i]], axis=-1
+ )
+ )
+ self.weights_pole.append(weights_pole)
+ sub = paddle.subtract(self.lambdas[i], weights_pole)
+ terms.append(paddle.divide(paddle.to_tensor(1, dtype=sub.dtype), sub))
+
+ output_residue1 = paddle.einsum(self.eq1, alpha, weights_residue, *terms)
+ output_residue2 = (-1) ** self.dims * paddle.einsum(
+ self.eq2, alpha, weights_residue, *terms
+ )
+ return output_residue1, output_residue2
+
+ def forward(self, x):
+ alpha = paddle.fft.fftn(x=x, axes=[-3, -2, -1])
+ output_residue1, output_residue2 = self.output_PR(alpha)
+
+ x1 = paddle.fft.ifftn(
+ x=output_residue1, s=(x.shape[-3], x.shape[-2], x.shape[-1])
+ )
+ x1 = paddle.real(x=x1)
+
+ exp_terms = []
+ for i in range(self.dims):
+ term = paddle.einsum(
+ "io"
+ + self.char2[i]
+ + ",d"
+ + self.char1[i]
+ + "->io"
+ + self.char2[i]
+ + self.char1[i],
+ self.weights_pole[i],
+ self.t_lst[i].astype(paddle.complex64).reshape([1, -1]),
+ )
+ exp_terms.append(paddle.exp(term))
+
+ x2 = paddle.einsum(self.eq_x2, output_residue2, *exp_terms)
+ x2 = paddle.real(x2)
+ x2 = x2 / reduce(operator.mul, x.shape[-3:], 1)
+ return x1 + x2
+
+
+class LNO(base.Arch):
+ def __init__(
+ self,
+ input_keys: Tuple[str, ...],
+ output_keys: Tuple[str, ...],
+ width: int,
+ modes: Tuple[int, ...],
+ T: paddle.Tensor,
+ Data: Optional[Tuple[paddle.Tensor, ...]] = None,
+ in_features: int = 1,
+ hidden_features: int = 64,
+ activation: str = "sin",
+ use_norm: bool = True,
+ use_grid: bool = False,
+ ):
+ """Laplace Neural Operator net.
+
+ Args:
+ input_keys (Tuple[str, ...]): Name of input keys, such as ("input1", "input2").
+ output_keys (Tuple[str, ...]): Name of output keys, such as ("output1", "output2").
+ width (int): Tensor width of Laplace Layer.
+ modes (Tuple[int, ...]): Number of modes to use for contraction in Laplace domain during training.
+ T (paddle.Tensor): Linspace of time dimension.
+ Data (Tuple[paddle.Tensor, ...]): Linspaces of other dimensions.
+ in_features (int, optional): Number of input channels of the first layer.. Defaults to 1.
+ hidden_features (int, optional): Number of channels of the fully-connected layer. Defaults to 64.
+ activation (str, optional): The activation function. Defaults to "sin".
+ use_norm (bool, optional): Whether to use normalization layers. Defaults to True.
+ use_grid (bool, optional): Whether to create grid. Defaults to False.
+ """
+ super().__init__()
+ self.input_keys = input_keys
+ self.output_keys = output_keys
+ self.width = width
+ self.modes = modes
+ self.dims = len(modes)
+ assert self.dims <= 3, "Only 3 dims and lower of modes are supported now."
+
+ if Data is None:
+ Data = ()
+ assert (
+ self.dims == len(Data) + 1
+ ), f"Dims of modes is {self.dims} but only {len(Data)} dims(except T) of data received."
+
+ self.fc0 = nn.Linear(in_features=in_features, out_features=self.width)
+ self.laplace = Laplace(self.width, self.width, self.modes, T, Data)
+ self.conv = getattr(nn, f"Conv{self.dims}D")(
+ in_channels=self.width,
+ out_channels=self.width,
+ kernel_size=1,
+ data_format="NCDHW",
+ )
+ if use_norm:
+ self.norm = getattr(nn, f"InstanceNorm{self.dims}D")(
+ num_features=self.width,
+ weight_attr=False,
+ bias_attr=False,
+ )
+ self.fc1 = nn.Linear(in_features=self.width, out_features=hidden_features)
+ self.fc2 = nn.Linear(in_features=hidden_features, out_features=1)
+ self.act = act_mod.get_activation(activation)
+
+ self.use_norm = use_norm
+ self.use_grid = use_grid
+
+ def get_grid(self, shape):
+ batchsize, size_t, size_x, size_y = shape[0], shape[1], shape[2], shape[3]
+ gridt = paddle.to_tensor(data=np.linspace(0, 1, size_t), dtype="float32")
+ gridt = gridt.reshape(1, size_t, 1, 1, 1).repeat(
+ [batchsize, 1, size_x, size_y, 1]
+ )
+ gridx = paddle.to_tensor(data=np.linspace(0, 1, size_x), dtype="float32")
+ gridx = gridx.reshape(1, 1, size_x, 1, 1).repeat(
+ [batchsize, size_t, 1, size_y, 1]
+ )
+ gridy = paddle.to_tensor(data=np.linspace(0, 1, size_y), dtype="float32")
+ gridy = gridy.reshape(1, 1, 1, size_y, 1).repeat(
+ [batchsize, size_t, size_x, 1, 1]
+ )
+ return paddle.concat(x=(gridt, gridx, gridy), axis=-1)
+
+ def transpoe_to_NCDHW(self, x):
+ perm = [0, self.dims + 1] + list(range(1, self.dims + 1))
+ return paddle.transpose(x, perm=perm)
+
+ def transpoe_to_NDHWC(self, x):
+ perm = [0] + list(range(2, self.dims + 2)) + [1]
+ return paddle.transpose(x, perm=perm)
+
+ def forward_tensor(self, x):
+ if self.use_grid:
+ grid = self.get_grid(x.shape)
+ x = paddle.concat([x, grid], axis=-1)
+ x = self.fc0(x)
+ x = self.transpoe_to_NCDHW(x)
+
+ if self.use_norm:
+ x1 = self.norm(self.laplace(self.norm(x)))
+ else:
+ x1 = self.laplace(x)
+
+ x2 = self.conv(x)
+ x = x1 + x2
+
+ x = self.transpoe_to_NDHWC(x)
+
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.fc2(x)
+ return x
+
+ def forward(self, x):
+ if self._input_transform is not None:
+ x = self._input_transform(x)
+
+ y = self.concat_to_tensor(x, self.input_keys, axis=-1)
+ y = self.forward_tensor(y)
+ y = self.split_to_dict(y, self.output_keys, axis=-1)
+
+ if self._output_transform is not None:
+ y = self._output_transform(x, y)
+ return y