ArXiv | Poster | Video | Project
- The proposed style-disentangled Transformer (SDT) generates online handwritings with conditional content and style. Existing RNN-based methods mainly focus on capturing a person’s overall writing style, neglecting subtle style inconsistencies between characters written by the same person. In light of this, SDT disentangles the writer-wise and character-wise style representations from individual handwriting samples for enhancing imitation performance.
- We extend SDT and introduce an offline-to-offline framework for improving the generation quality of offline Chinese handwritings.




-
Online Chinese handwriting generation

-
Applications to various scripts

-
Extension on offline Chinese handwriting generation




python 3.8
pytorch >=1.8
easydict 1.9
einops 0.4.1
SDT/
│
├── train.py - main script to start training
├── test.py - generate characters via trained model
├── evaluate.py - evaluation of generated samples
│
├── configs/*.yml - holds configuration for training
├── parse_config.py - class to handle config file
│
├── data_loader/ - anything about data loading goes here
│ └── loader.py
│
├── model_zoo/ - pre-trained content encoder model
│
├── data/ - default directory for storing experimental datasets
│
├── model/ - networks, models and losses
│ ├── encoder.py
│ ├── gmm.py
│ ├── loss.py
│ ├── model.py
│ └── transformer.py
│
├── saved/
│ ├── models/ - trained models are saved here
│ ├── tborad/ - tensorboard visualization
│ └── samples/ - visualization samples in the training process
│
├── trainer/ - trainers
│ └── trainer.py
│
└── utils/ - small utility functions
├── util.py
└── logger.py - set log dir for tensorboard and logging output
We provide Chinese, Japanese and English datasets in Google Drive | Baidu Netdisk PW:xu9u. Please download these datasets, uzip them and move the extracted files to /data.
- We provide the pre-trained content encoder model in Google Drive | Baidu Netdisk PW:xu9u. Please download and put it to the /model_zoo.
- We provide the well-trained SDT model in Google Drive | Baidu Netdisk PW:xu9u, so that users can get rid of retraining one and play it right away.
Training
- To train the SDT on the Chinese dataset, run this command:
python train.py --cfg configs/CHINESE_CASIA.yml --log Chinese_log
- To train the SDT on the Japanese dataset, run this command:
python train.py --cfg configs/Japanese_TUATHANDS.yml --log Japanese_log
- To train the SDT on the English dataset, run this command:
python train.py --cfg configs/English_CASIA.yml --log English_log
Qualitative Test
- To generate Chinese handwritings with our SDT, run this command:
python test.py --pretrained_model checkpoint_path --store_type online --sample_size 500 --dir Generated/Chinese
- To generate Japanese handwritings with our SDT, run this command:
python test.py --pretrained_model checkpoint_path --store_type online --sample_size 500 --dir Generated/Japanese
- To generate English handwritings with our SDT, run this command:
python test.py --pretrained_model checkpoint_path --store_type online --sample_size 500 --dir Generated/English
Quantitative Evaluation
- To evaluate the generated handwritings, you need to set
data_pathto the path of the generated handwritings (e.g., Generated/Chinese), and run this command:
python evaluate.py --data_path Generated/Chinese
We are delighted to discover that P0etry-rain has proposed a pipeline that involves initially converting the generated results by our SDT to TTF format, followed by the development of software to enable flexible adjustments in spacing between paragraphs, lines, and characters. Below, we present TTF files, software interface and the printed results. More details can be seen in #78.
-
TTF File
-
Software Interface
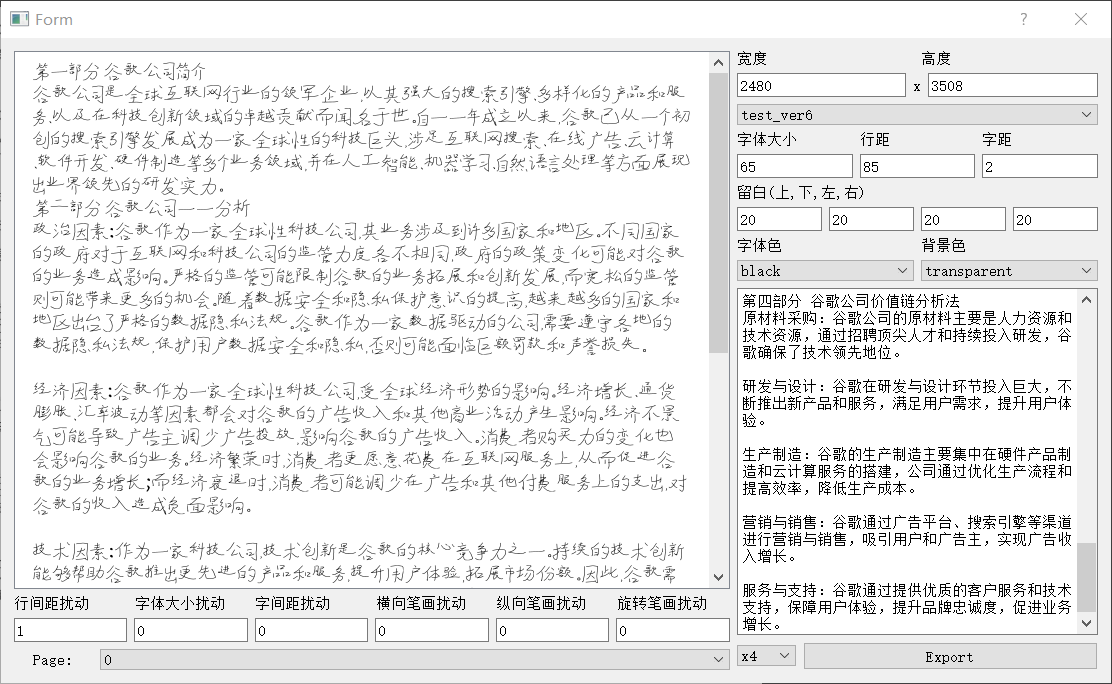
-
Printed Results




If you find our work inspiring or use our codebase in your research, please cite our work:
@inproceedings{dai2023disentangling,
title={Disentangling Writer and Character Styles for Handwriting Generation},
author={Dai, Gang and Zhang, Yifan and Wang, Qingfeng and Du, Qing and Yu, Zhuliang and Liu, Zhuoman and Huang, Shuangping},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
pages={5977--5986},
year={2023}
}