散列表和链表的组合?为什么呢?
- 链表:涉及查找的操作慢,不连续存储;
- 顺序表:支持随机访问,连续存储。
散列表 + 链表:结合优点、规避缺点。
缓存的操作接口:
- 向缓存添加数据
- 从缓存删除数据
- 在缓存中查找数据
然而——不管是添加还是删除,都涉及到查找数据。因此,单纯的链表效率低下。
魔改一把!
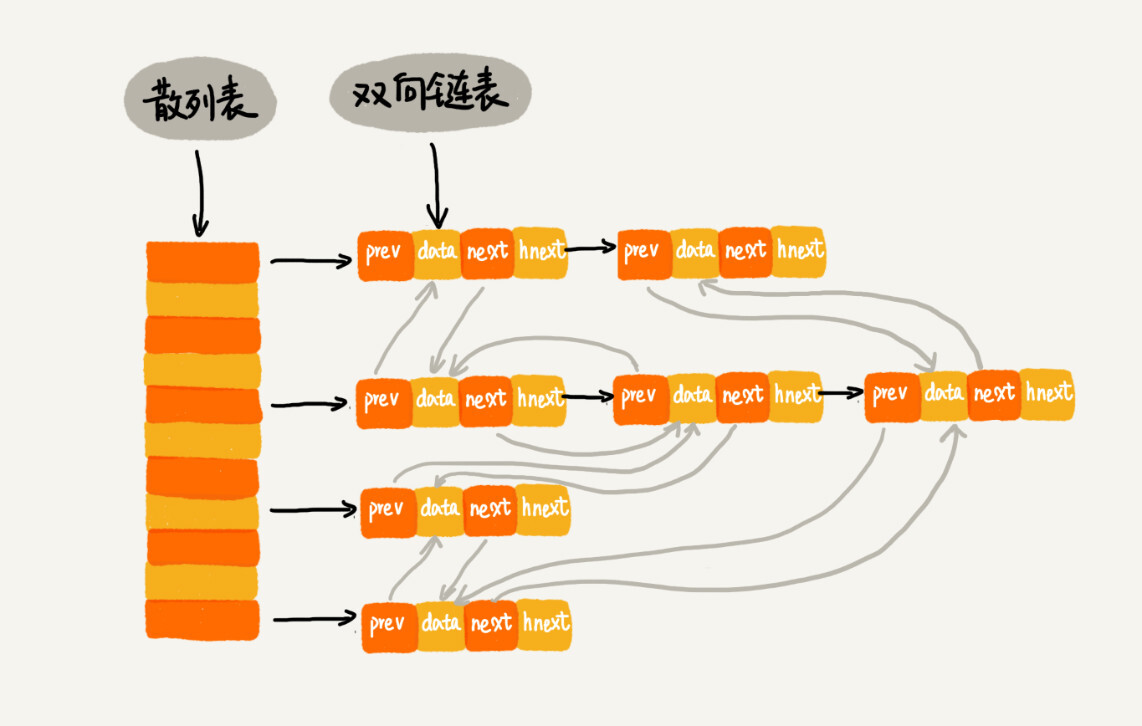
prev和next:双向链表——LRU 的链表hnext:单向链表——解决散列冲突的链表
操作:
- 在缓存中查找数据:利用散列表
- 从缓存中删除数据:先利用散列表寻找数据,然后删除——改链表就好了,效率很高
- 向缓存中添加数据:先利用散列表寻找数据,如果找到了,LRU 更新;如果没找到,直接添加在 LRU 链表尾部
遍历时,按照访问顺序遍历。实现结构,与上述 LRU 的结构完全相同——只不过它不是缓存,不限制容量大小。