2020 年底公司和阿里健康合作了一个检验项目,由我司提供检验项目(商品)、采样点(商户)、库存等底层数据,与阿里健康开发对接后在支付宝平台进行线上预售,开发流程其中也包括订单数据的交互。
项目开发期间踩了比较多的坑,做了很多优化,其中也包含一些有意思的技术实现方案。
某些业务场景下,我们需要频繁调用阿里健康接口,项目第一个版本上线后,发现有部分请求触发阿里健康接口流控告警,原因是他们提供的接口在一定的时间内只允许 N 次接口调用。针对这个问题,想到了以下几种实现方式:
- sleep 同步调用:对批量数据进行拆分,每条数据都 sleep 一段时间
- ScheduledExecutorService 异步调用:延迟任务,通过线程池调度
- HashedWheelTimer(Netty) 异步调用:将批量数据按照一定延迟时间添加到时间轮队列中,等待调度
第 1 种方案如果同步批量数据过多,sleep 后客户端一直得不到响应,直接 pass。第 2 种方案需要频繁的创建和销毁线程池,考虑到客户端交互频繁,选择了时间轮方案。
当有任务添加到队列中后,Netty 时间轮会开启一个工作线程,后续所有任务的执行都依赖这个线程,因此不会频繁创建与销毁线程资源。但是有一个缺陷是当没有任务时,这个线程会一直空转,只要不同时存在多个时间轮,这个空转是可以接受的。
Netty 时间轮原理如下:
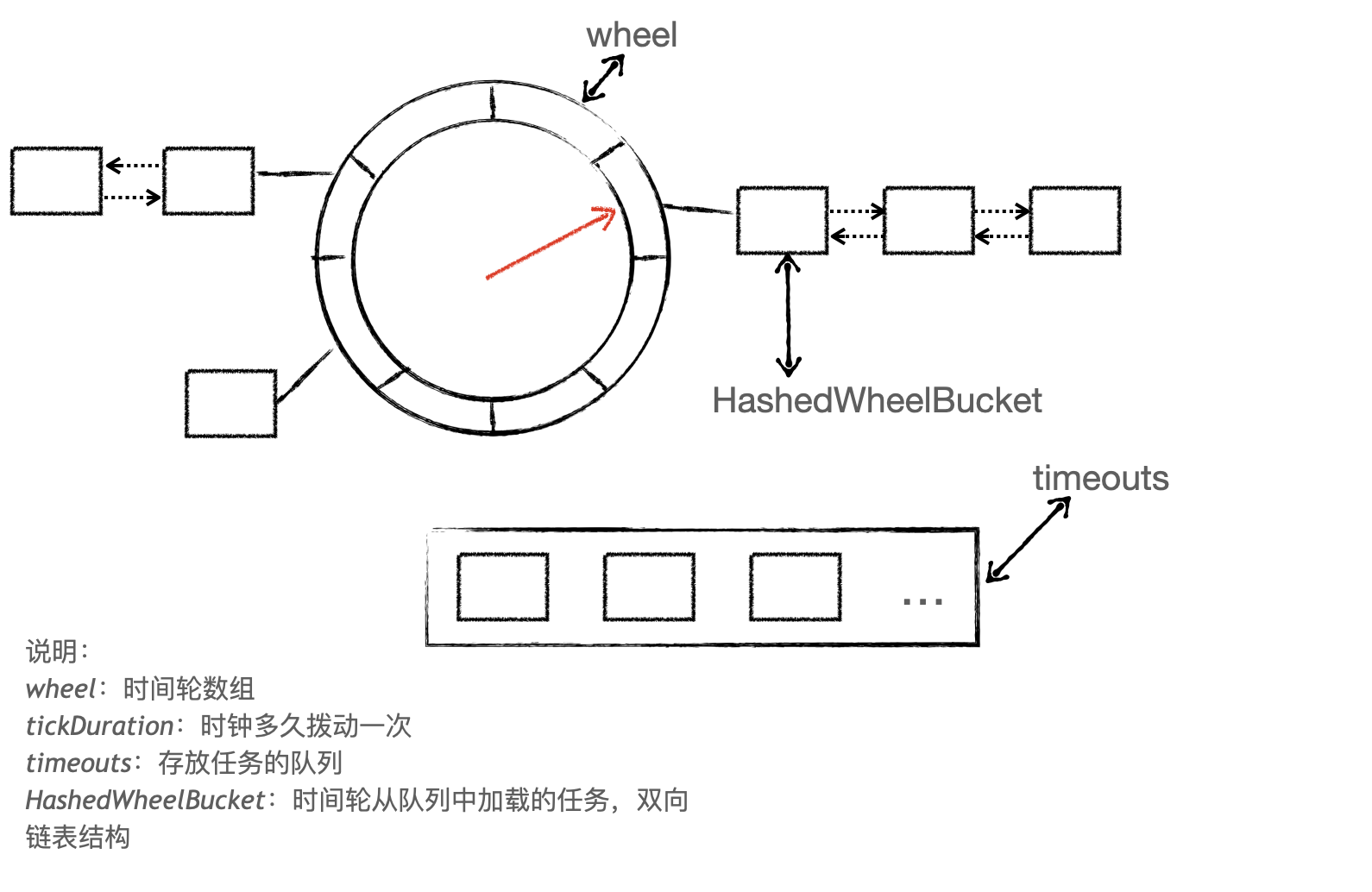
关于 Netty 时间轮设计原理,可以看下我这篇文章的总结:Netty 时间轮原理分析
刚开始的库存设计方案比较简单,运营人员先在后台绑定采样点与检验项目的关系,然后设置排期和具体日期对应的库存,后端接收到数据后直接入库。
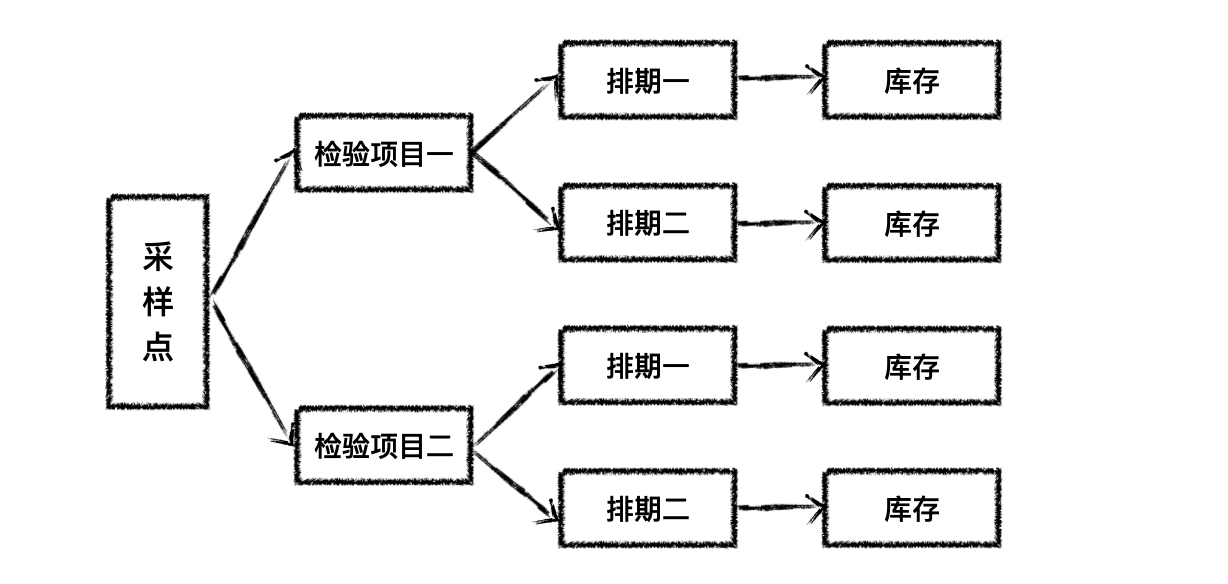
由于是在线预售业务,一般会对未来一个月内的日期进行排期。如果有 X 家采样点,一家采样点绑定了 N 个项目,排期天数设置为 M 天,就需要在数据库中保存 X * N * M 条记录。随着时间推移 M 越来越大,数据量也就越来越多。
这种设计方案比较容易理解,和订单交互的流程也比较简单,但是有一个很严重的问题是会预生成大量的库存数据,业务发展不到两个月就已经生成了 200w+ 的数据量。
对这些数据进行分析后发现 95% 的数据都是无用的,于是想了以下两种方案解决这个问题:
- 预先生成逻辑不变,通过定时任务扫描库存表,删除无效数据,无效数据主要指非未来时间且没有库存变更的数据
- 延迟生成库存,当未发生库存变更请求时不生成库存,针对查询操作,通过业务代码构造库存信息,当库存变更时延迟生成库存
第一种方案实现比较简单,原先的业务逻辑不变,只需要定义一个库存清除任务即可。当删除 MySQL 表数据时,这些数据所占用的空间可能会被标记为可复用,并不会释放磁盘空间,出于这个考虑选择了第二个方案。
延迟库存生成流程图如下:
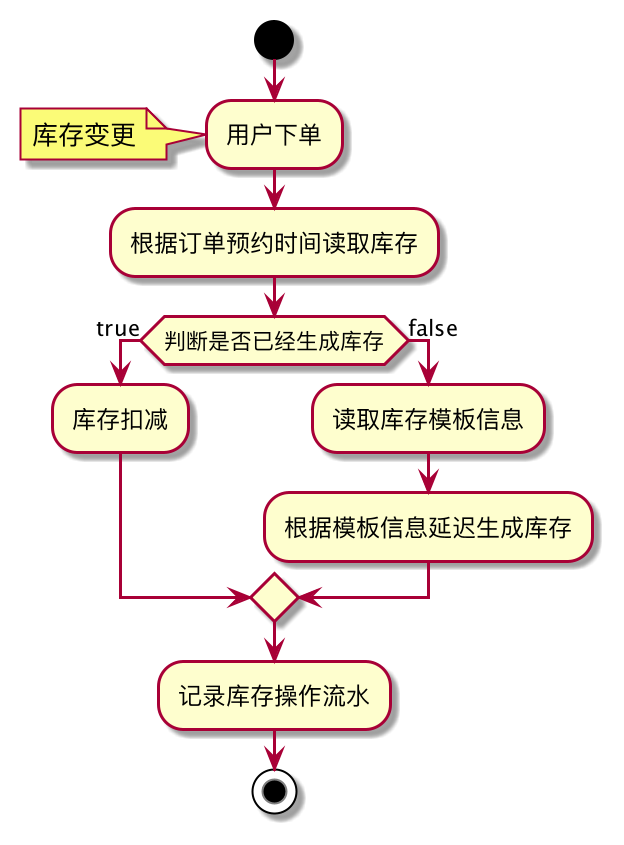
采用延迟设计方案后,数据量至少减少了 95%,考虑到并发情况,库存延迟生成时需要利用分布式锁防止创建多条库存数据。
库存延迟生成虽然解决了数据量的问题,但是针对一些特殊的产品需求,比如:修改某一天的库存,需要保存运营现场数据,处理起来会比较复杂。最好的方式是权衡各个方案的利弊,找一个适合业务发展的方案。
后来和阿里健康对接了一个上门服务业务,这个业务起来了,单量也越来越多,退单率也高了起来,甚至收到了比较多的客诉,原因是用户只能约某一天的订单,但是并不知道线下人员什么时间段上门。
有的客户约了明天的订单,但是客户可能只有明天上午有时间,线下人员如果下午上门服务,这时候客户就不高兴了,不高兴了怎么办,总得找个方式发泄,投诉。
为了解决这个问题,阿里健康团队提出了分时策略,将一天划分为几个时间段,比如:上午十点到十二点,下午两点到四点。这样客户有更多的选择,尽可能避免出现上面投诉的问题。
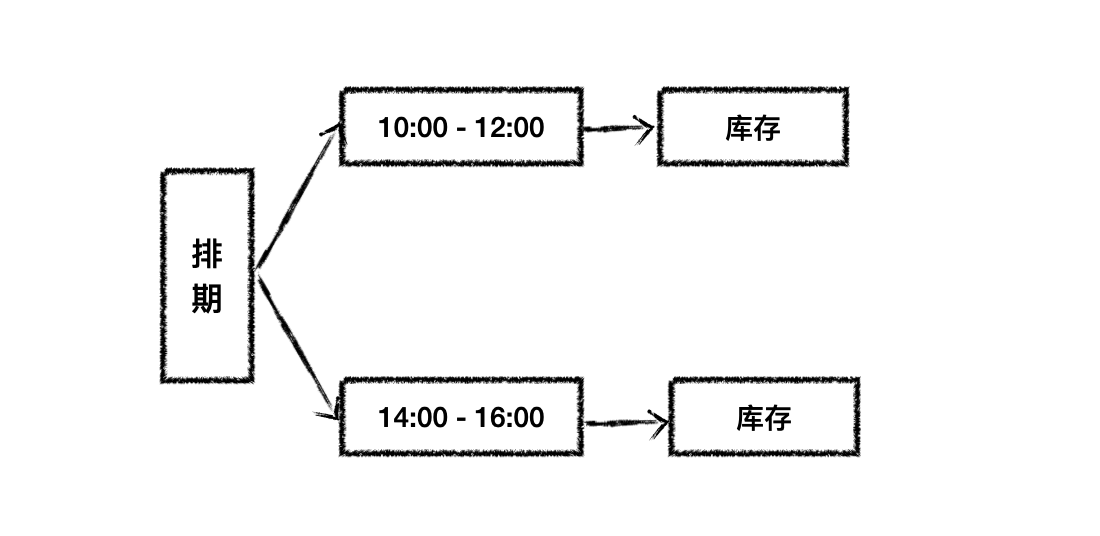
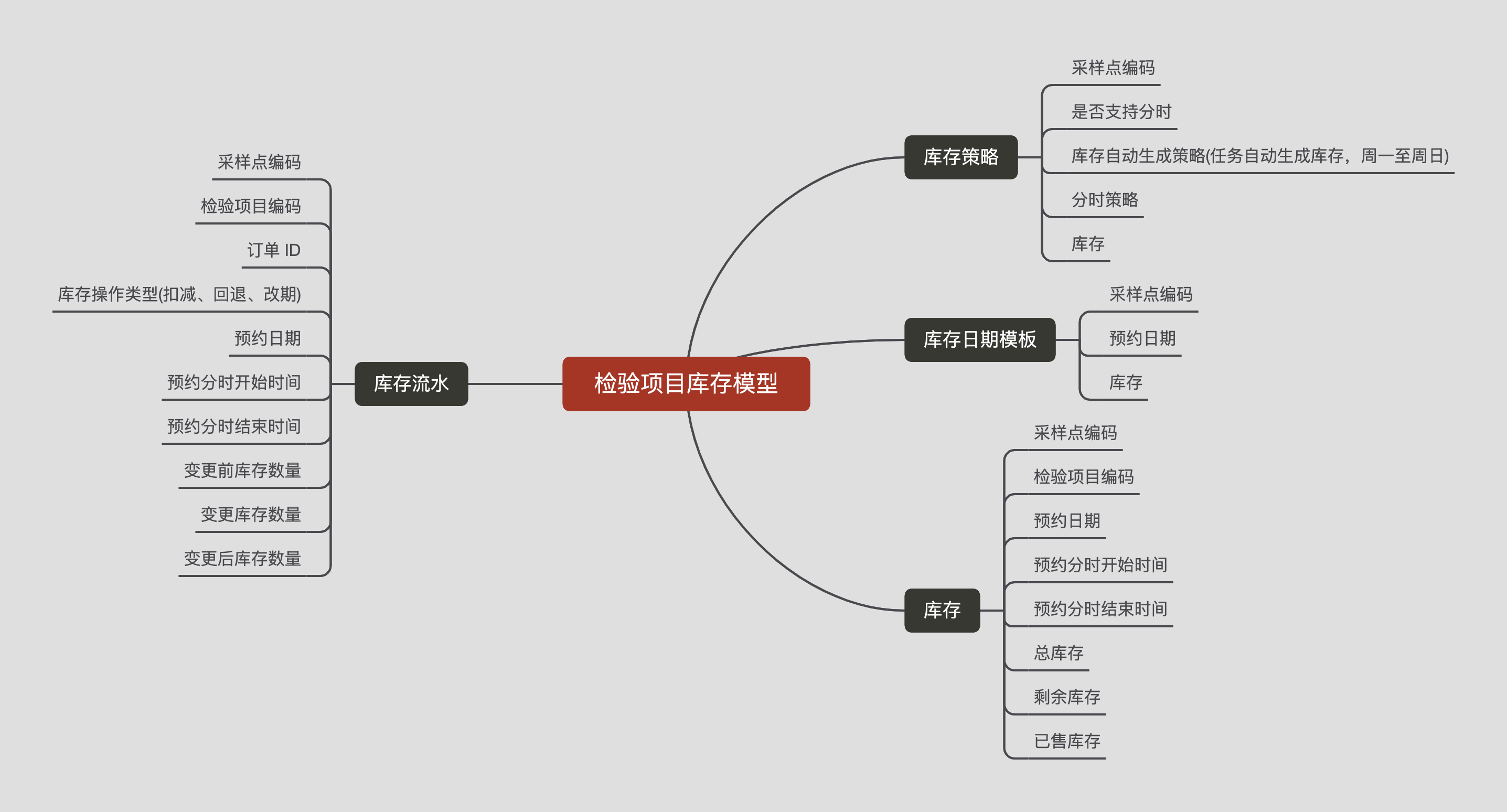
- 库存策略:分时与不分时是两种策略,支持来回切换
- 库存日期模板:库存未生成时,需要根据库存日期模板信息与分时策略构造库存信息
- 库存:库存实体
- 库存流水:记录库存变更,便于排查问题与库存核对
沟通与表达至关重要,保持良好的沟通往往能节约大量的开发成本并减少线上问题。
设计库存模型时由于时间紧迫,没有具体讨论相关设计方案,目前库存相关表设计不够扁平化,当后期处理延迟改造与分时项目时,有的细节实现起来比较复杂,需要冗余一些信息,导致代码复杂度高,可读性下降,因此需要在代码中批注相关注释。
库存变更存在并发问题,延迟生成时通过分布式锁进行控制,库存扣减与回退时有以下处理方案。应该综合考虑并发程度与用户体验,选择适中的方案。
- 利用分布式锁,代码层面对库存进行计算,更新 DB
- 对库存变更流程进行事务控制,利用数据库拍他锁通过 DB 计算扣减与回退库存
- 库存放到 Redis,Redis 扣减成功后再操作 DB
- 利用数据库乐观锁,进行版本号对比
库存核对,可以开发自动化库存核对脚本,以任务的形式自动核对。