Primary contact: Yitian Zhang

Motivation: Vision foundation models are renowned for their generalization ability due to massive training data. Nevertheless, they demand tremendous training resources, and the training data is often inaccessible, e.g., CLIP, DINOv2.Solution: We offer a very simple and general solution, named Proteus, to distill foundation models into smaller equivalents on ImageNet-1K without access to the original training data.Strength:- (1) Small Training Costs (similar to DeiT distillation on ImageNet-1K)
- (2) Strong Performance (similar to foundation models trained with tons of data)
- (3) Generalization Ability (validated across DINOv2, CLIP, SynCLR)

Proteus is a simple and general distillation framework which has two distinct features compared to conventional knowledge distillation:
-
Combating Dataset Bias: We find the introduction of one-hot labels and the projection head will lead to dataset bias. Consequently, we perform distillation on the intermediate features and discard the labels.
-
Multi-level Training Objectives: We construct the proxy task by combining the token-level, patch-level, and feature-level learning objectives to learn the general-purpose visual representations, ensuring the performance of Proteus across various tasks.
Proteus can easily generalize to existing vision foundation models to access them at much smaller costs. Currently, Proteus supports the training of DINOv2, CLIP, SynCLR. Please feel free to contact us if you want to contribute the implementation of other methods.
-
Accessing DINOv2
DINOv2 is trained on private large-scale dataset LVD-142M and we utilize the pre-trained DINOv2 as the teacher to train a randomly initialized network on ImageNet-1K. We validate Proteus across ImageNet-1K, 12 fine-grained classification datasets, semantic segmentation dataset ADE20K and depth estimation dataset NYU-Depth V2 following DINOv2.
- Target Model: ViT-S

- Target Model: ViT-B and ViT-L

- Comparison with Distillation in Supervised Learning

Proteus outperforms traditional supervised training across various dimensions with similar costs, offering a novel training scheme enhanced by foundation models.



We provide the pretrained Proteus distilled from DINOv2:
| Model | Backbone Weight | ImageNet | Fine-grained | ADE20K | NYU-Depth V2 |
|---|---|---|---|---|---|
| ViT-Ti | download | 75.2% | 80.2% | 40.7%, weight | 0.423, weight |
| ViT-S | download | 81.8% | 85.8% | 50.0%, weight | 0.350, weight |
| ViT-B | download | 84.9% | 88.6% | 54.4%, weight | 0.303, weight |
| ViT-L | download | 86.2% | 91.0% | 57.7%, weight | 0.240, weight |
-
Accessing SynCLR and CLIP
We test the generalization ability of Proteus by leveraging other foundation models SynCLR and CLIP as the teacher networks. SynCLR is trained with the contrastive learning objective on the undisclosed 600M synthetic dataset, while CLIP is obtained by aligning images and corresponding text descriptions through contrastive learning on the private dataset WIT-400M.

We provide the pretrained Proteus distilled from SynCLR:
| Model | Backbone Weight | ImageNet | Fine-grained |
|---|---|---|---|
| ViT-B | download | 81.4% | 87.4% |
and CLIP:
| Model | Backbone Weight | ImageNet | Fine-grained |
|---|---|---|---|
| ViT-B | download | 81.2% | 85.7% |
-
Ablation on Proxy Dataset
- Dataset Diversity
The generalization ability of Proteus can be improved if we increase the diversity of the proxy dataset and Proteus is robust even under the extreme scenario when we only have a single image to represent the proxy dataset.

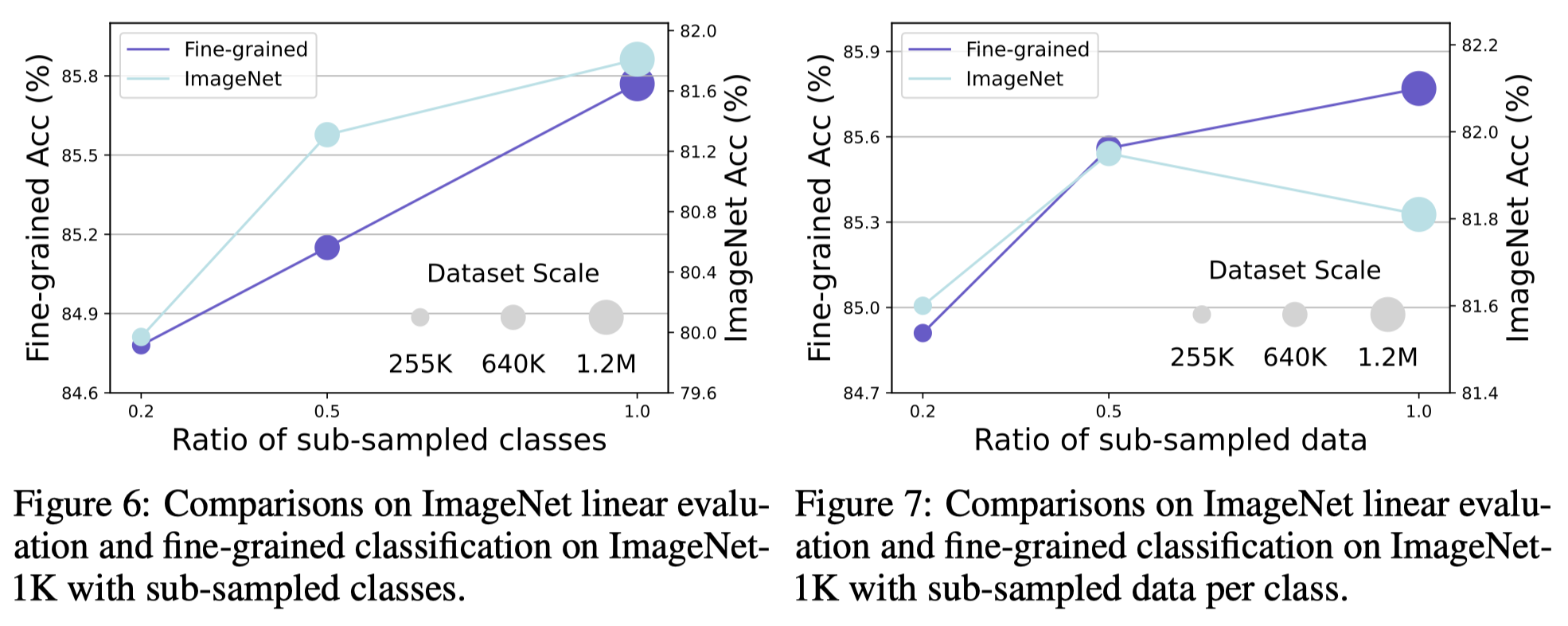
- Scaling Behavior
Proteus is robust when we either sub-sample a portion of data at each class or sub-sample a portion of classes from the total 1000 classes. It suggests that it is feasible to access foundation models with even smaller data scales.


We provide a comprehensive codebase which contains the implementation of Pre-training on ImageNet-1K, ImageNet-1K Linear Evaluation, Fine-grained Classification and Semantic Segmentation and Depth Estimation. Please go to the folders for specific docs.
Our codebase is heavily build upon DeiT, DINOv2, SynCLR and mmsegmentation. We gratefully thank the authors for their wonderful works.