![]()
- a very simple framework for state-of-the-art NLP. Developed by Zalando Research.
Flair uses hyper-powerful word embeddings to achieve state-of-the-art accuracies on a range of natural language processing (NLP) tasks.
Flair is:
-
A word embedding library. There are many different types of word embeddings out there, with wildly different properties. Flair packages many of them behind a simple interface, so you can mix and match embeddings for your experiments. In particular, you can try out our proposed contextual string embeddings, to build your own state-of-the-art NLP methods.
-
A powerful syntactic / semantic tagger. Flair allows you to apply our state-of-the-art models for named entity recognition (NER), part-of-speech tagging (PoS) and chunking to your text.
Embedding your text for state-of-the-art NLP has never been easier.
Flair outperforms the previous best methods on a range of NLP tasks:
| Task | Dataset | Our Result | Previous best |
|---|---|---|---|
| Named Entity Recognition (English) | Conll-03 | 93.09 (F1) | 92.22 (Peters et al., 2018) |
| Named Entity Recognition (English) | Ontonotes | 89.71 (F1) | 86.28 (Chiu et al., 2016) |
| Named Entity Recognition (German) | Conll-03 | 88.32 (F1) | 78.76 (Lample et al., 2016) |
| Named Entity Recognition (German) | Germeval | 84.65 (F1) | 79.08 (Hänig et al, 2014) |
| Part-of-Speech tagging | WSJ | 97.85 | 97.64 (Choi, 2016) |
| Chunking | Conll-2000 | 96.72 (F1) | 96.36 (Peters et al., 2017) |
Here's how to reproduce these numbers using Flair. You can also find a detailed evaluation and discussion in our paper:
Contextual String Embeddings for Sequence Labeling. Alan Akbik, Duncan Blythe and Roland Vollgraf. 27th International Conference on Computational Linguistics, COLING 2018.
Let's look into some core functionality to understand the library better. For a more extensive introduction, please check out the tutorial!
First, you need to construct Sentence objects for your text.
# The sentence objects holds a sentence that we may want to embed
from flair.data import Sentence
# Make a sentence object by passing a whitespace tokenized string
sentence = Sentence('The grass is green .')
# Print the object to see what's in there
print(sentence)You can access the tokens of a sentence via their token id, or iterate through the tokens in a sentence.
print(sentence[4])
# The Sentence object has a list of Token objects (each token represents a word)
for token in sentence:
print(token) Tokens can also have tags, such as a named entity tag. In this example, we're adding an NER tag of type 'color' to the word 'green' in the example sentence.
# add a tag to a word in the sentence
sentence[4].add_tag('ner', 'color')
# print the sentence with all tags of this type
print(sentence.to_tag_string('ner'))Now, you can embed the words in a sentence. Instantiate an embedding class and call the method
embed() over a list of sentences. We start with a simple GloVe embedding.
# Init a simple GloVe embedding.
from flair.embeddings import WordEmbeddings
embedder = WordEmbeddings('glove')
# embed a sentence using GloVe.
from flair.data import Sentence
sentence = Sentence('The grass is green .')
embedder.embed(sentences=[sentence])If you want to check the embeddings of the words, just call the embedding property of any Token:
# now check out the embedded tokens.
for token in sentence:
print(token)
print(token.embedding)Switching to a different embedding is as simple as choosing a different embeddings class. Here, we use contextual string embeddings.
# the CharLMEmbedding also inherits from the TextEmbeddings class
from flair.embeddings import CharLMEmbeddings
embedder = CharLMEmbeddings('news-forward')
# embed a sentence using CharLM.
from flair.data import Sentence
sentence = Sentence('The grass is green .')
embedder.embed(sentences=[sentence])Some embeddings - such as character-features - are not pre-trained but rather trained on the downstream task. Normally this requires you to implement a hierarchical embedding architecture.
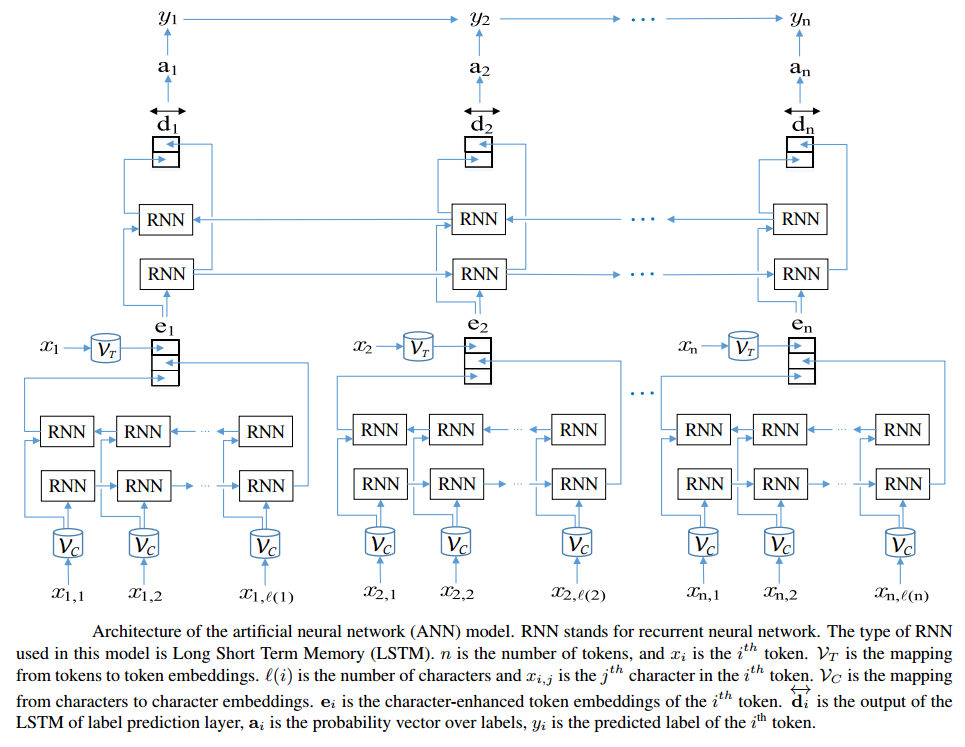{kind=link}
With Flair, you need not worry about such things. Just choose the appropriate embedding class and character features will then automatically train during downstream task training.
# the CharLMEmbedding also inherits from the TextEmbeddings class
from flair.embeddings import CharacterEmbeddings
embedder = CharacterEmbeddings()
# embed a sentence using CharLM.
from flair.data import Sentence
sentence = Sentence('The grass is green .')
embedder.embed(sentences=[sentence])This library runs on Python 3.6 - because methods signatures and type hints are beautiful. If you do not have Python 3.6, install it first. Here is how for Ubuntu 16.04.
The requirements.txt lists all libraries that we depend on. Install them first. For instance, if you
use pip and virtualenv, run these commands:
virtualenv --python=[path/to/python3.6] [path/to/this/virtualenv]
source [path/to/this/virtualenv]/bin/activate
pip install -r requirements.txtIn order to train your own models, you need training data. For instance, get the publicly available
CoNLL-03 data set for English and place train, test and dev data in /resources/tasks/conll_03/ as follows:
/resources/tasks/conll_03/eng.testa
/resources/tasks/conll_03/eng.testb
/resources/tasks/conll_03/eng.train
To set up more tasks, follow the guidelines here.
Once you have the data, go into the virtualenv and run the following command to train a small NER model:
python train.py Run this for a few epochs. Then test it on a sentence using the following command:
python predict.pyTo reproduce our state-of-the-art results using Flair, check out the experiments section.
Please cite the following paper when using Flair:
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {(forthcoming)},
year = {2018}
}
Thanks for your interest in contributing! There are many ways to get involved; start with our contributor guidelines and then check these open issues for specific tasks.
For contributors looking to get deeper into the API we suggest cloning the repository and checking out the unit tests for examples of how to call methods. Nearly all classes and methods are documented, so finding your way around the code should hopefully be easy.
The MIT License (MIT)
Flair is licensed under the following MIT license: The MIT License (MIT) Copyright © 2018 Zalando SE, https://tech.zalando.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.