TrWebOCR,基于开源项目Tr构建。
在其基础上提供了http调用的接口,便于你在其他的项目中调用。
并且提供了易于使用的web页面,便于调试或日常使用。
-
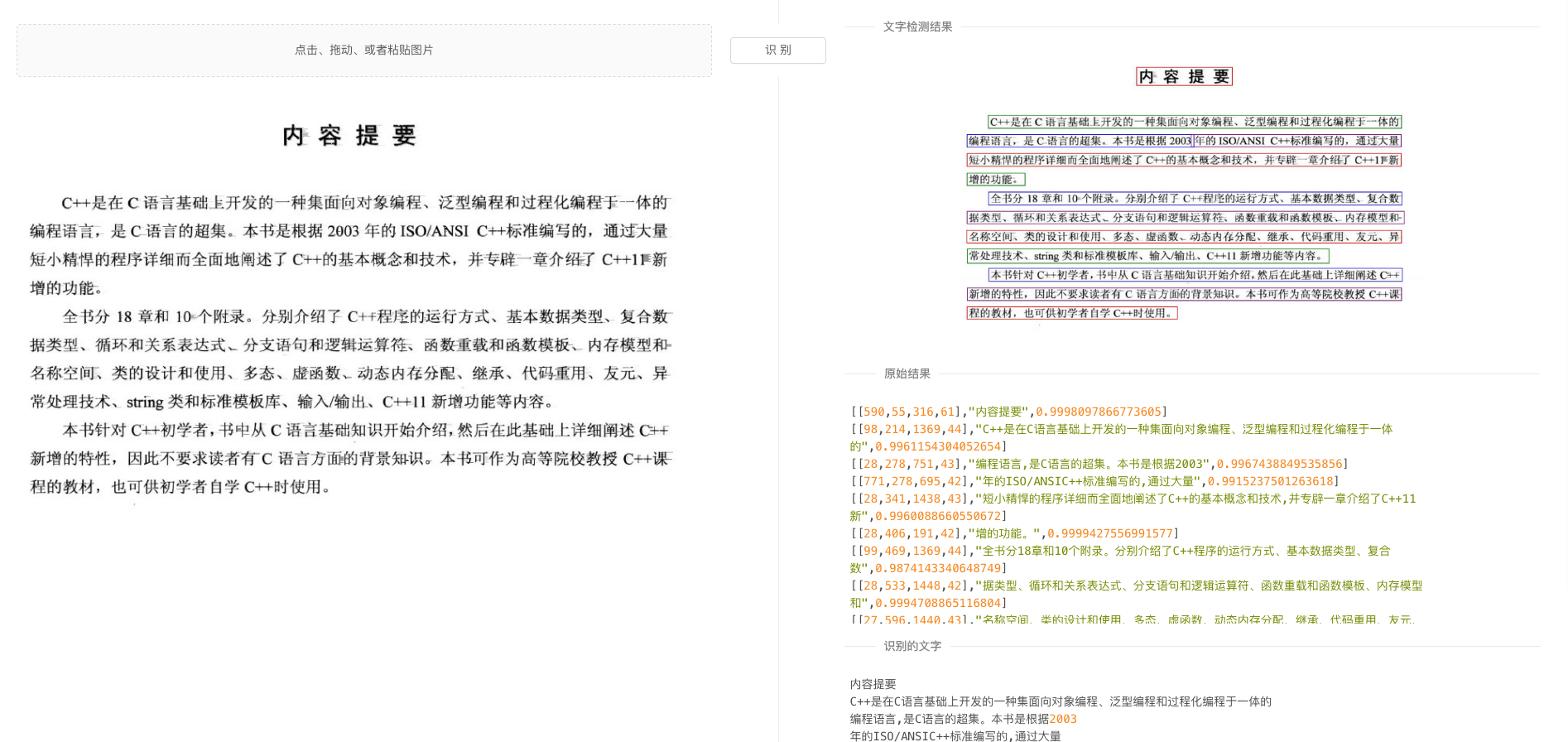
中文识别
快速高识别率 -
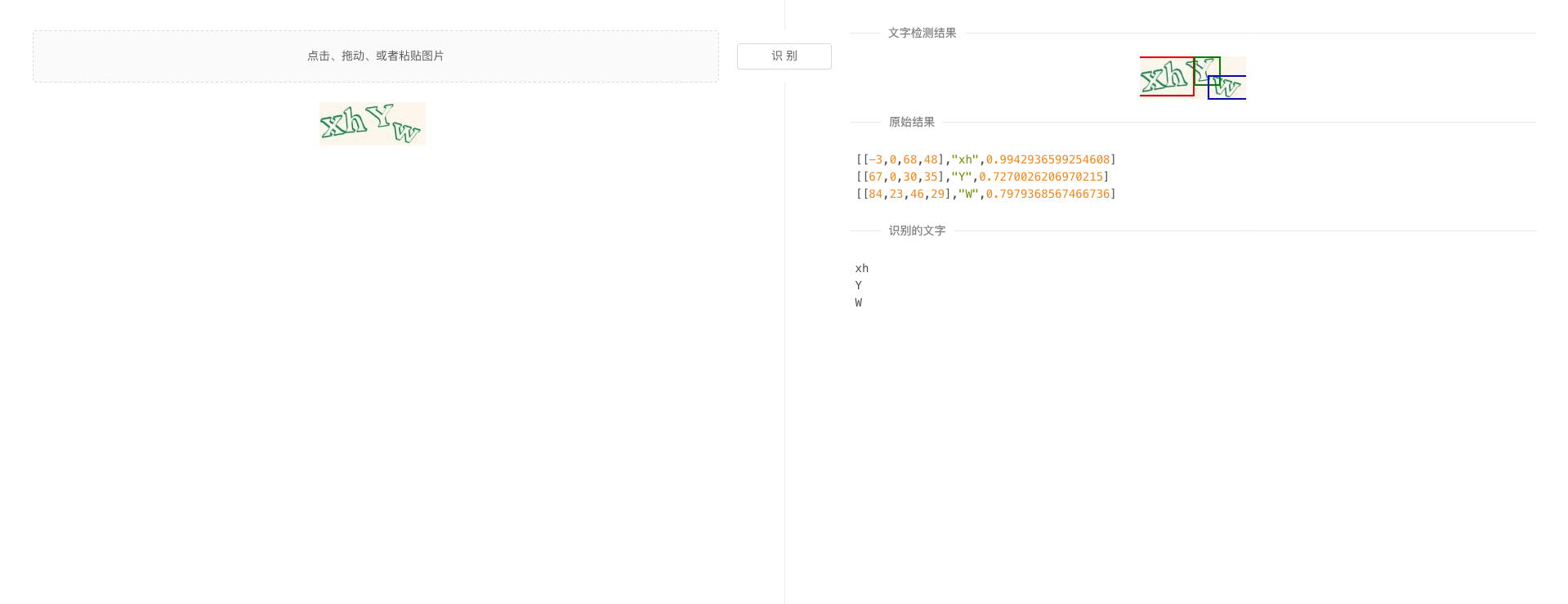
文字检测
支持一定角度的旋转 -
并发请求
由于模型本身不支持并发,但通过tornado多进程的方式,能支持一定数量的并发请求。具体并发数取决于机器的配置。
- ✔ Python 3.6+
- ✔ Ubuntu 16.04
- ✔ ️Ubuntu 18.04
- ✔ CentOS 7
- ❌
Windows - ❌
MacOS
暂时不支持Windows和MacOS的部署,后续会提供docker部署的镜像。
其他Linux平台暂未测试,可自行安装测试
- CPU: 1核
- 内存: 2G
- SWAP: 2G
-
安装python3.7
推荐使用miniconda -
执行install.py
python install.py
- 安装依赖包
pip install -r requirements.txt- 运行
python backend/main.py项目默认运行在8089端口,看到以下输出则代表运行成功:
# tr 1.5.0 https://github.com/myhub/tr
server is running: 0.0.0.0:8089- 编译 Dockerfile
docker build -t TrWebOCR:latest .- Docker run
docker run -itd -p 8089:8089 --name trweb trweb-ocr:latest /bin/bash这里把容器的8089端口映射到了物理机的8089上,但如果你不喜欢映射,去掉run后面的-p 8089:8089 也可以使用docker的IP加8089来访问
Apache 2.0
- 感谢 myhub 和它的开源项目Tr
如果你也喜欢这个项目,不妨给个star (^.^)✨