




##English | 中文
Make Flink|Spark easier!!!
一个神奇的框架,让 Flink|Spark 开发更简单
大数据技术如今发展的如火如荼,已经呈现百花齐放欣欣向荣的景象,实时处理流域 Apache Spark 和 Apache Flink
更是一个伟大的进步,尤其是 Apache Flink 被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力终于诞生了今天的框架
—— StreamX, 项目的初衷是 —— 让 Flink 开发更简单, 使用 StreamX 开发,可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务, StreamX
规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的 Connectors ,标准化了配置、开发、测试、部署、监控、运维的整个过程, 提供 Scala 和 Java 两套api,
其最终目的是打造一个一站式大数据平台,流批一体,湖仓一体的解决方案



- 开发脚手架
- 一系列开箱即用的connectors
- 支持项目编译功能(maven 编译)
- 在线参数配置
- 多版本flink支持(1.12.x,1.13.x,1.14.x)
- on Kubernetes部署模式支持(
K8s-Native-Application/K8s-Native-Session) - on YARN部署模式支持(
YARN-Application/YARN-Pre-Job) - 快捷的日常操作(任务
启动、停止、savepoint,从savepoint恢复) - 支持火焰图
- 支持
notebook(在线任务开发) - 项目配置和依赖版本化管理
- 支持任务备份、回滚(配置回滚)
- 在线管理依赖(maven pom)和自定义jar
- 自定义 udf、连接器等支持
- Flink SQL WebIDE
- 支持 Catalog、Hive
- 从任务
开发阶段到部署管理全链路支持 - ...
Streamx 由三部分组成,分别是 streamx-core,streamx-pump 和 streamx-console
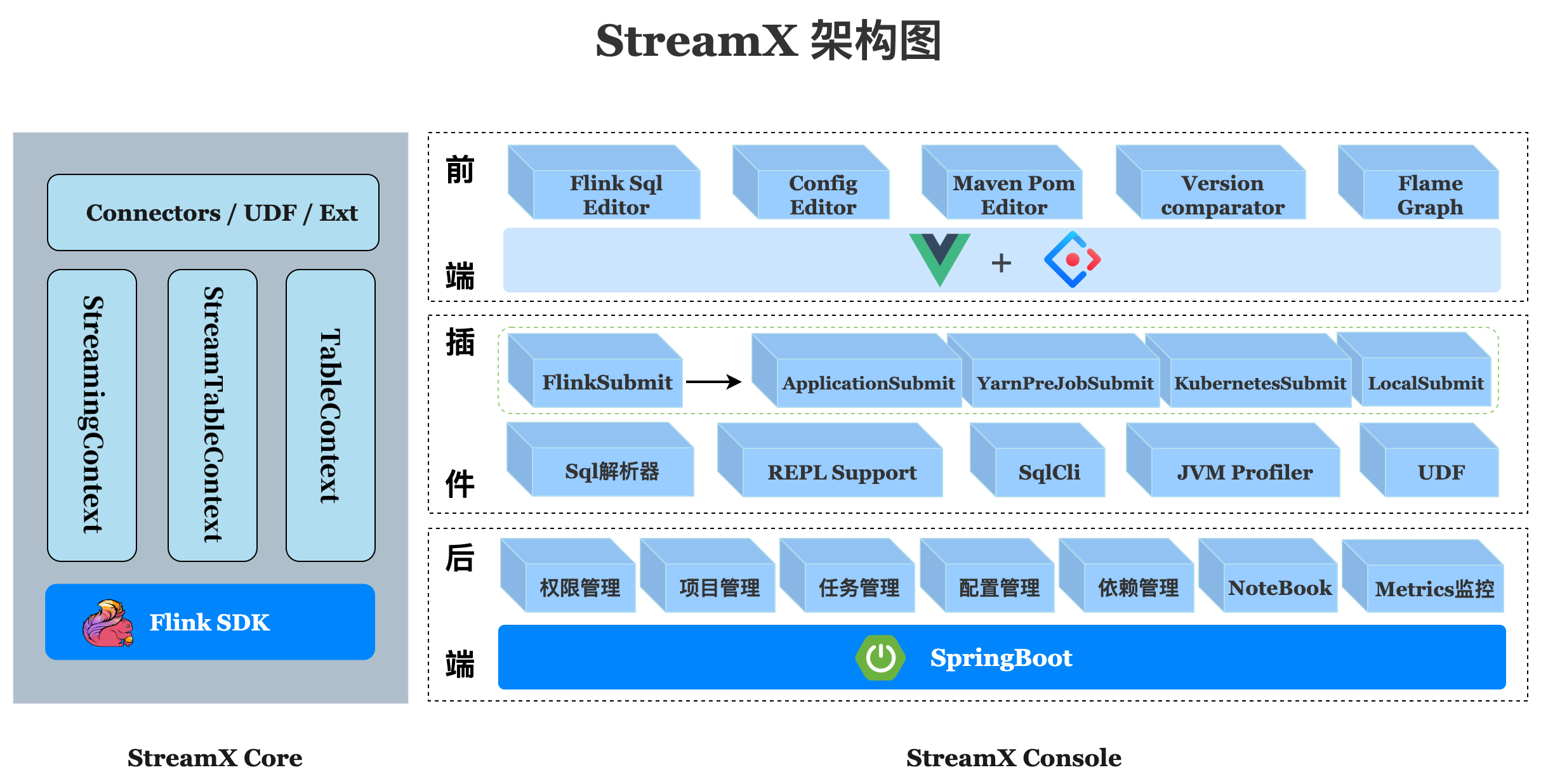
streamx-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发时 RunTime Content 和一系列开箱即用的 Connector
,扩展了 DataStream 相关的方法,融合了DataStream 和 Flink sql api,简化繁琐的操作,聚焦业务本身,提高开发效率和开发体验
pump 是抽水机,水泵的意思,streamx-pump 的定位是一个数据抽取的组件,类似于 flinkx,基于streamx-core 中提供的各种 connector
开发,目的是打造一个方便快捷,开箱即用的大数据实时数据抽取和迁移组件,并且集成到 streamx-console 中,解决实时数据源获取问题,目前在规划中
streamx-console 是一个综合实时数据平台,低代码(Low Code)平台,可以较好的管理Flink任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图(flame graph)
,Flink SQL, 监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人可以使用,
其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案,该平台使用但不仅限以下技术:
- Apache Flink
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Flame Graph
- JVM-Profiler
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
感谢以上优秀的开源项目和很多未提到的优秀开源项目,致以最崇高的敬意,特别感谢Apache Zeppelin ,IntelliJ IDEA, 感谢 fire-spark 项目,早期给予的灵感和帮助, 感谢我老婆在项目开发时给予的支持,悉心照顾我的生活和日常,给予我足够的时间开发这个项目
git clone https://github.com/streamxhub/streamx.git
cd streamx
mvn clean install -DskipTests -Denv=prod
更多请查看官网文档
Apache Zeppelin是一个非常优秀的开源项目👏 对 Flink 做了很好的支持,Zeppelin 创新型的 notebook
功能,让开发者非常方便的 On-line 编程,快捷的提交任务,语言层面同时支持Java,Scala,Python,国内阿里的章剑峰大佬也在积极推动该项目,向剑峰大佬致以崇高的敬意🙏🙏🙏,
但该项目目前貌似没有解决项目的管理和运维方面的痛点,针对比较复杂的项目和大量的作业管理就有些力不从心了,一般来讲不论是 DataStream 作业还是 Flink SQL 作业,大概都会经历作业的开发阶段,测试阶段
,打包阶段,上传服务器阶段,启动任务阶段等这些步骤,这是一个链路很长的步骤,且整个过程耗时比较长,体验不好,
即使修改了一个符号,项目改完上线都得走上面的流程,我们期望这些步骤能够动动鼠标一键式解决,还希望至少能有一个任务列表的功能,能够方便的管理任务,可以清楚的看到哪些任务正在运行,哪些停止了,任务的资源消耗情况,可以在任务列表页面一键启动
或停止任务,并且自动管理 savePoint,这些问题也是开发者实际开发中会遇到了问题,
streamx-console 很好的解决了这些痛点,定位是一个一站式实时数据平台,并且开发了更多令人激动的功能(诸如Flink SQL WebIDE,依赖隔离,任务回滚,火焰图等)
FlinkX
是基于flink的分布式数据同步工具,实现了多种异构数据源之间高效的数据迁移,定位比较明确,专门用来做数据抽取和迁移,可以作为一个服务组件来使用,StreamX 关注开发阶段和任务后期的管理,定位有所不同,streamx-pump
模块也在规划中, 致力于解决数据源抽取和迁移,最终会集成到 streamx-console 中
如果你希望参与贡献 欢迎 Pull Request,或给我们 报告 Bug。
强烈推荐阅读 《提问的智慧》(本指南不提供此项目的实际支持服务!)、《如何有效地报告 Bug》、《如何向开源项目提交无法解答的问题》,更好的问题更容易获得帮助。
感谢 JetBrains 提供的免费开源 License 赞助

Are you enjoying this project ? 👋
StreamX 采用 Apache LICENSE 2.0 许可的开源项目,使用完全免费, 旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人都可以使用,流批一体,湖仓一体,数据湖是大数据领域的趋势, StreamX现在离这个目标还有一段距离,还需持续投入,相应的资金支持能更好的持续项目的维护和开发。你可以通过下列的方法来赞助 StreamX 的开发, 欢迎捐助,一起来帮我们做的更好! ☀️ 👊
| 微信支付 | 支付宝 |
|---|---|
 |
 |
所有赞助人将在赞助人名单中显示。
虚席以待,欢迎个人和企业前来赞助,您的支持会帮助我们更好的发展项目







Streamx 已正式开源,现已经进入高速发展模式,如果您觉得还不错请在右上角点一下 star,帮忙转发,谢谢 🙏🙏🙏 大家的支持是开源最大动力,
你可以扫下面的二维码加入官方微信群,更多相关信息请访问官网


扫微信二维码加群讨论(验证信息:"StreamX")