In this lab you will use Azure Data Factory to download New York City images to your data lake. Then, as part of the same pipeline, you are going to use an Azure Databricks notebook to invoke Computer Vision Cognitive Service to generate metadata documents and save them in back in your data lake. The Azure Data Factory pipeline then finishes by saving all metadata information in a Cosmos DB collection. You will use Power BI to visualise NYC images and their AI-generated metadata.
IMPORTANT: The typical use case for Cosmos DB is to serve as the operational database layer for data-driven applications (e.g. real-time personalisation). This lab intends to illustrates how analytics data pipelines can be used to deliver insights to intelligent apps through Cosmos DB. For the sake of keeping this lab simple we will use Power BI to query Cosmos DB data instead of an App.
The estimated time to complete this lab is: 75 minutes.
The following Azure services will be used in this lab. If you need further training resources or access to technical documentation please find in the table below links to Microsoft Learn and to each service's Technical Documentation.
| Azure Service | Microsoft Learn | Technical Documentation |
|---|---|---|
| Azure Cognitive Vision Services | Process and classify images with the Azure Cognitive Vision Services | Azure Computer Vision Technical Documentation |
| Azure Cosmos DB | Work with NoSQL data in Azure Cosmos DB | Azure Cosmos DB Technical Documentation |
| Azure Databricks | Perform data engineering with Azure Databricks | Azure Databricks Technical Documentation |
| Azure Data Lake Gen2 | Large Scale Data Processing with Azure Data Lake Storage Gen2 | Azure Data Lake Gen2 Technical Documentation |

| Step | Description |
|---|---|
 |
Build an Azure Data Factory Pipeline to copy image files from shared Azure Storage |
 |
Save image files to your data lake |
 |
For each image in your data lake, invoke an Azure Databricks notebook that will take the image URL as parameter |
 |
For each image call the Azure Computer Vision Cognitive service to generate image metadata. Metadata files are saved back in your data lake |
 |
Copy metadata JSON documents into your Cosmos DB database |
 |
Visualize images and associated metadata using Power BI |
IMPORTANT: Some of the Azure services provisioned require globally unique name and a “-suffix” has been added to their names to ensure this uniqueness. Please take note of the suffix generated as you will need it for the following resources in this lab:
| Name | Type |
|---|---|
| adpcosmosdb-suffix | Cosmos DB account |
| SynapseDataFactory-suffix | Data Factory (V2) |
| synapsedatalakesuffix | Storage Account |
| ADPDatabricks-suffix | Databricks Workspace |
In this section you will create a container in your SynapseDataLake that will be used as a repository for the NYC image files. You will copy 30 files from the MDWResources Storage Account into your NYCTaxiData container.

| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
In the Azure Portal, go to the lab resource group and locate the Azure Storage account synapsedatalakesuffix.
-
On the Overview panel, click Containers.

-
On the synapsedatalakesuffix – Containers blade, click + Container. On the New container blade, enter the following details:
- Name: nycimages
- Public access level: Blob (anonymous read access for blobs only) -
Click OK to create the new container.

-
Repeat the process to create the NYCImageMetadata container. This container will be used to host the metadata files generated by Cognitive Services before they can be saved in Cosmos DB.
-
On the New container blade, enter the following details:
- Name: nycimagemetadata
- Public access level: Private (no anonymous access) -
Click OK to create the new container.




In this section you will create a CosmosDB database called NYC and a collection called ImageMetadata that will host New York image metadata information.

| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
In the Azure Portal, go to the lab resource group and locate the CosmosDB account ADPCosmosDB-suffix.
-
On the Overview panel, click + Add Container.

-
On the Add Container blade, enter the following details:
- Database id > Create new: NYC
- Container id: ImageMetadata
- Partition key: /requestId
- Throughput: 400
- Unique keys: /requestId -
Click OK to create the container.



In this section you will import a Databricks notebook to your workspace and fill out the missing details about your Computer Vision API and your Data Lake account. This notebook will be executed from an Azure Data Factory pipeline and it will invoke the Computer Vision API to generate metadata about the images and save the result back to your data lake.

| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
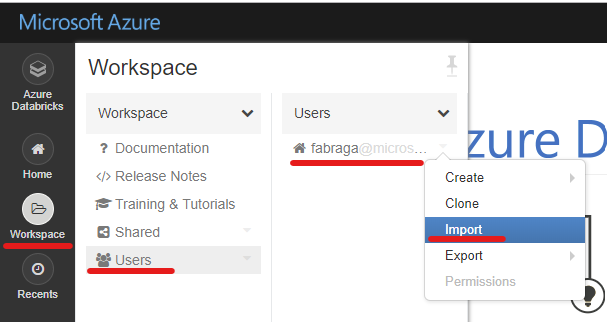
On the Azure Databricks portal, click the Workspace button on the left-hand side menu.
-
On the Workspace blade, click your username under the Users menu.
-
On the Users blade, click the arrow next to your user name and then Import.
-
On the Import Notebooks pop up window, select Import from: URL. Copy and paste the URL below in the box:

https://github.com/fabragaMS/ADPE2E/raw/master/Lab/Lab4/NYCImageMetadata-Lab.dbc-
Click Import.
-
On the NYCImageMetadata-Lab notebook, go to Cmd 2 cell Define function to invoke Computer Vision API. You will need to change the function code to include the Computer Vision API details.

-
From the Azure Portal, retrieve the MDWComputerVision subscription key and base endpoint URL.


-
Copy and paste the Key and Endpoint values back in the Databricks notebook.
-
On the NYCImageMetadata-Lab notebook, go to Cmd 3 cell Define function to mount NYC Image Metadata Container. You will need to change the function code to include your data lake storage account details.
-
In the dataLakeaccountName variable assignment replace <SynapseDataLake storage account name> with synapsedatalakesuffix.

-
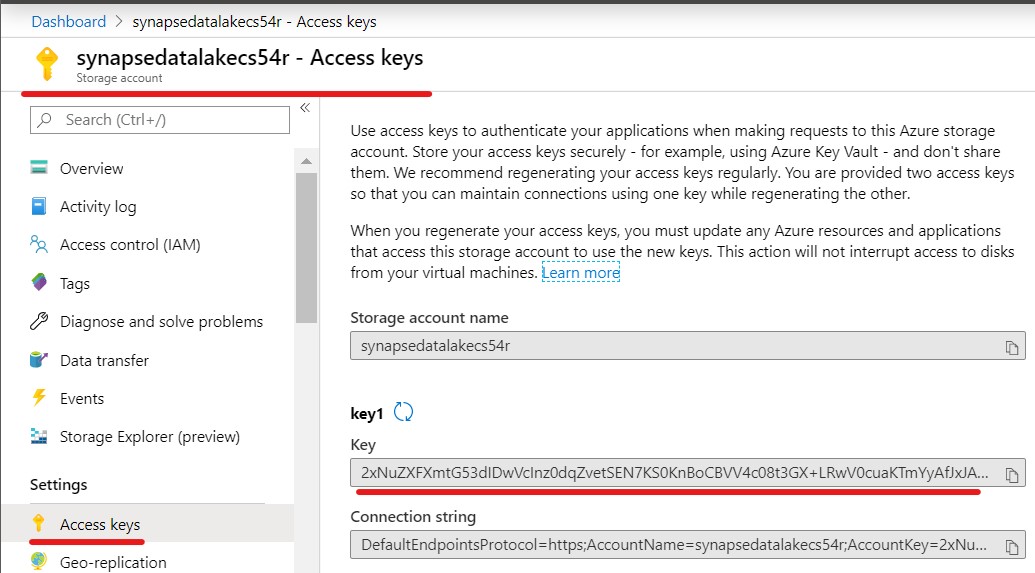
From the Azure Portal, retrieve the SynapseDataLakesuffix access key.
-
Copy and paste the Access Key Databricks notebook. Replace <SynapseDataLake storage account key> with the Access Key you got from the previous step.
-
Attach the notebook to your previously created ADPDatabricksCluster cluster.

-
Review the notebook code.
-
If you want to test it, you can copy any publicly available image URL and paste it in the Image URL notebook parameter. You can use any of the following image URLs in the list as examples:










-
Click Run All to execute the notebook.

-
After a successful execution you will notice that a new JSON file has been saved in the NYCImageMetadata container in your Data Lake.

-
Navigate to Azure Portal and check the contents of the nycimagemetadata container in your SynapseDataLakesuffix storage account.
-
Download the file generated to inspect its contents.
-
IMPORTANT: Delete this test file before moving to next steps of this exercise.




In this section you will create a Databricks linked service in Azure Data Factory. Through this linked service you will be able to create a data pipelines to copy NYC images to your data lake and integrate Databricks notebooks to its execution.

| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
On the Azure Databricks portal, click the User icon on the top right-hand corner of the screen.
-
Click on the User Settings menu item.

-
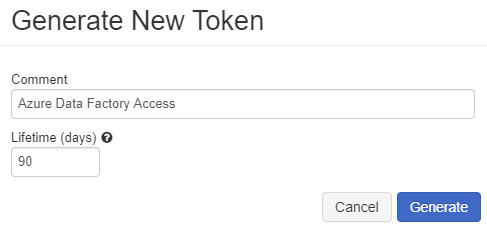
On the User Settings blade, under the Access Tokens tab, click Generate New Token.

-
On the Generate New Token pop-up window, enter “Azure Data Factory Access” in the Comment field. Leave Lifetime (days) with the default value of 90 days.
-
Click Generate.
-
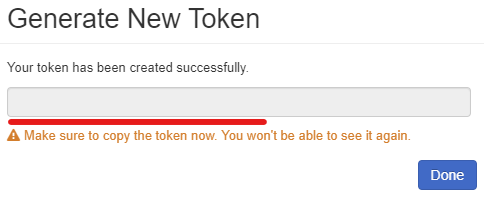
IMPORTANT: Copy the generated access token to Notepad and save it. You won’t be able to retrieve it once you close this window.
-
Open the Azure Data Factory portal and click the Author (pencil icon) option on the left-hand side panel. Under Connections tab, click Linked Services and then click + New to create a new linked service connection.

-
On the New Linked Service blade, click the Compute tab.
-
Type “Azure Databricks” in the search box to find the Azure Databricks linked service.
-
Click Continue.

-
On the New Linked Service (Azure Databricks) blade, enter the following details:
- Name: ADPDatabricks
- Connect via integration runtime: AutoResolveIntegrationRuntime
- Account selection method: From Azure subscription
- Azure subscription: [select your subscription]
- Databricks workspace: ADPDatabricks-suffix
- Select cluster: Existing interactive cluster
- Access token: [copy and paste previously generated access token here]
- Choose from existing clusters: ADPDatabricksCluster
-
Click Test connection to make sure you entered the correct connection details. You should see a “Connection successful” message above the button.
-
If the connection was successful, then click Finish. If you got an error message, please review the connection details above and try again.







In this section you will create a CosmosDB linked service in Azure Data Factory. CosmosDB will be used as the final repository of image metadata information generated by the Computer Vision API. Power BI will then be used to visualise the CosmosDB data.
| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
Open the Azure Data Factory portal and click the Author (pencil icon) option on the left-hand side panel. Under Connections tab, click Linked Services and then click + New to create a new linked service connection.
-
On the New Linked Service blade, click the Data Store tab.
-
Type “Cosmos DB” in the search box to find the Azure Cosmos DB (SQL API) linked service.
-
Click Continue.

-
On the New Linked Service (Azure Databricks) blade, enter the following details:
- Name: ADPCosmosDB
- Connect via integration runtime: AutoResolveIntegrationRuntime
- Account selection method: From Azure subscription
- Azure subscription: [select your subscription]
- Cosmos DB account name: adpcosmosdb-suffix
- Database name: NYC
-
Click Test connection to make sure you entered the correct connection details. You should see a “Connection successful” message above the button.
-
If the connection was successful, then click Finish. If you got an error message, please review the connection details above and try again.


In this section you will create 4 Azure Data Factory data sets that will be used in the data pipeline.
| Dataset | Role | Description |
|---|---|---|
| MDWResources_NYCImages_Binary | Source | References MDWResources shared storage account container that contains source image files. |
| SynapseDataLake_NYCImages_Binary | Destination | References your synapsedataLake-suffix storage account and it acts as the destination for the image files copied from MDWResources_NYCImages. |
| SynapseDataLake_NYCImageMetadata_JSON | Source | References your synapsedatalake-suffix storage account and it acts as the source of image metadata files (JSON) generated by Databricks and Computer Vision. |
| ADPCosmosDB_ImageMetadata | Destination | References ADPCosmosDB-suffix database that will save the metadata info for all images. |
| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
Open the Azure Data Factory portal and click the Author (pencil icon) option on the left-hand side panel. Under Factory Resources tab, click the ellipsis (…) next to Datasets and then click Add Dataset to create a new dataset.
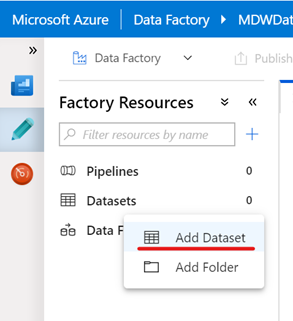
-
Type “Azure Blob Storage” in the search box and select Azure Blob Storage.

-
On the Select Format blade, select Binary and click Continue.

-
On the Set Properties blade, enter the following details:
- Name: MDWResources_NYCImages_Binary
- Linked Service: MDWResources
- File Path: Container: nycimages, Directory: [blank], File: [blank]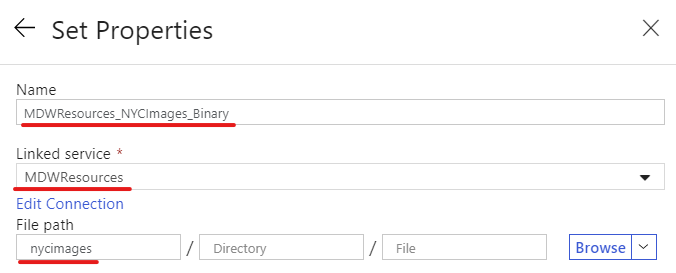
Click Continue.
-
Leave remaining fields with default values.
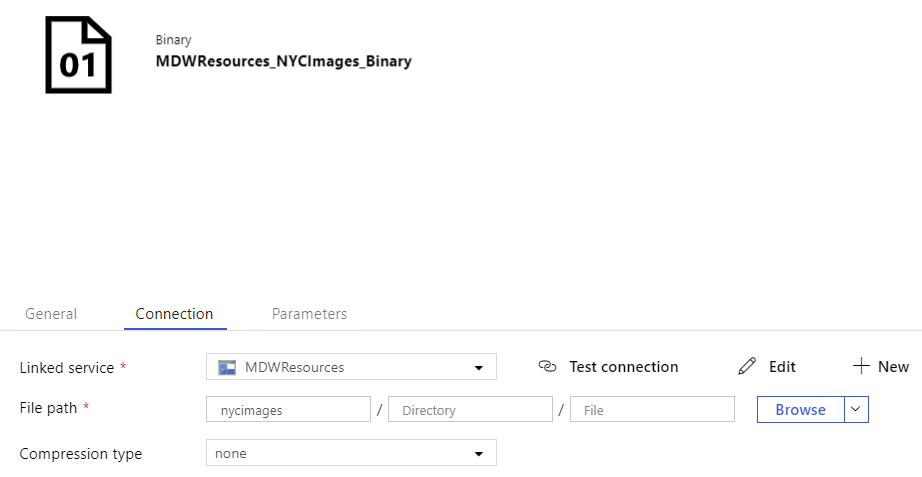
Alternatively you can copy and paste the dataset JSON definition below:
{ "name": "MDWResources_NYCImages_Binary", "properties": { "linkedServiceName": { "referenceName": "MDWResources", "type": "LinkedServiceReference" }, "folder": { "name": "Lab4" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "container": "nycimages" } } } } -
Repeat the process to create another dataset, this time referencing the NYCImages container in your synapsedatalake-suffix storage account.
-
Type “Azure Blob Storage” in the search box and click Azure Blob Storage.
-
On the Select Format blade, select Binary and click Continue.
-
On the Set Properties blade, enter the following details:
- Name: SynapseDataLake_NYCImages_Binary
- Linked Service: SynapseDataLake
- File Path: Container: nycimages, Directory: [blank], File: [blank]
Click Continue.
-
Leave remaining fields with default values.
 Alternatively you can copy and paste the dataset JSON definition below:
Alternatively you can copy and paste the dataset JSON definition below:{ "name": "SynapseDataLake_NYCImages_Binary", "properties": { "linkedServiceName": { "referenceName": "SynapseDataLake", "type": "LinkedServiceReference" }, "folder": { "name": "Lab4" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "container": "nycimages" } } } } -
Repeat the process to create another dataset, this time referencing the NYCImageMetadata container in your synapsedatalake-suffix storage account.
-
Type “Azure Blob Storage” in the search box and click Azure Blob Storage
-
On the Select Format blade, select JSON and click Continue.

-
On the Set properties blade, enter the following details:
- Name: SynapseDataLake_NYCImageMetadata_JSON
- Linked Service: SynapseDataLake
- File Path: Container: nycimagemetadata, Directory: [blank], File: [blank]
- Import Schema: None
Alternatively you can copy and paste the dataset JSON definition below:
{ "name": "SynapseDataLake_NYCImageMetadata_JSON", "properties": { "linkedServiceName": { "referenceName": "SynapseDataLake", "type": "LinkedServiceReference" }, "folder": { "name": "Lab4" }, "annotations": [], "type": "Json", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "container": "nycimagemetadata" } } } } -
Leave remaining fields with default values.










-
Repeat the process to create another dataset, this time referencing the ImageMetadata collection in your ADPCosmosDB database.
-
Type “Cosmos DB” in the search box and select Azure Cosmos DB (SQL API). Click Continue.

-
On the Set properties blade, enter the following details:
- Name: ADPCosmosDB_NYCImageMetadata
- Linked Service: ADPCosmosDB
- Collection: ImageMetadata
- Import schema: None
Alternatively you can copy and paste the dataset JSON definition below:
{ "name": "ADPCosmosDB_NYCImageMetadata", "properties": { "linkedServiceName": { "referenceName": "ADPCosmosDB", "type": "LinkedServiceReference" }, "folder": { "name": "Lab4" }, "annotations": [], "type": "CosmosDbSqlApiCollection", "typeProperties": { "collectionName": "ImageMetadata" } } } -
Leave remaining fields with default values.

-
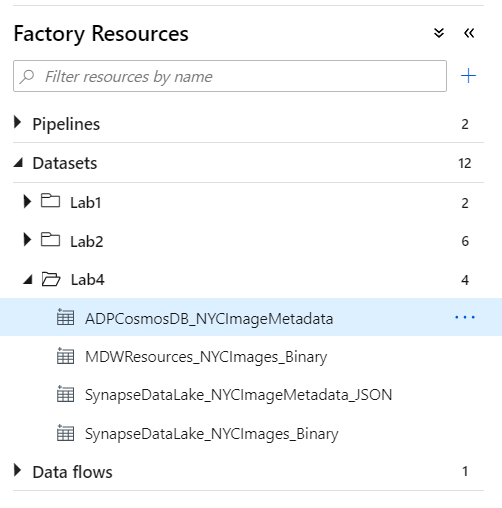
Under Factory Resources tab, click the ellipsis (…) next to Datasets and then click New folder to create a new Folder. Name it Lab4.
-
Drag the previously created datasets into the Lab4 folder you just created.
-
Publish your dataset changes by clicking the Publish all button.






In this section you will create an Azure Data Factory pipeline to copy New York images from MDWResources into your SynapseDataLakesuffix storage account. The pipeline will then execute a Databricks notebook for each image and generate a metadata file in the NYCImageMetadata container. The pipeline finishes by saving the image metadata content in a CosmosDB database.

| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
Open the Azure Data Factory portal and click the Author (pencil icon) option on the left-hand side panel. Under Factory Resources tab, click the ellipsis (…) next to Pipelines and then click Add Pipeline to create a new pipeline.

-
On the New Pipeline tab, enter the following details:
- General > Name: Lab4 - Generate NYC Image Metadata
- Variables > [click + New] >
- Name: ImageMetadataContainerUrl
- Default Value: https://synapsedatalake[suffix].blob.core.windows.net/nycimages/ IMPORTANT: Remember to replace the suffix for your SynapseDataLake account! -
Leave remaining fields with default values.

-
From the Activities panel, type “Copy Data” in the search box. Drag the Copy Data activity on to the design surface. This copy activity will copy image files from shared storage account MDWResources to your SynapseDataLake storage account.
-
Select the Copy Data activity and enter the following details:
- General > Name: CopyImageFiles
- Source > Source dataset: MDWResources_NYCImages_Binary
- Sink > Sink dataset: SynapseDataLake_NYCImages_Binary
- Sink > Copy Behavior: Preserve Hierarchy -
Leave remaining fields with default values.


-
From the Activities panel, type “Get Metadata” in the search box. Drag the Get Metadata activity on to the design surface. This activity will retrieve a list of image files saved in the NYCImages container by the previous CopyImageFiles activity.
-
Select the Get Metadata activity and enter the following details:
- General > Name: GetImageFileList
- Dataset: SynapseDataLake_NYCImages_Binary
- Source > Field list: Child Items -
Leave remaining fields with default values.

-
Create a Success (green) precedence constraint between CopyImageFiles and GetImageFileList activities. You can do it by dragging the green connector from CopyImageFiles and landing the arrow onto GetImageFileList.

-
From the Activities panel, type “ForEach” in the search box. Drag the ForEach activity on to the design surface. This ForEach activity will act as a container for other activities that will be executed in the context of each image files returned by the GetImageFileList activity.
-
Select the ForEach activity and enter the following details:
- General > Name: ForEachImage
- Settings > Items:@activity('GetImageFileList').output.childItems -
Leave remaining fields with default values.

-
Create a Success (green) precedence constraint between GetImageFileList and ForEachImage activities. You can do it by dragging the green connector from GetImageFileList and landing the arrow onto ForEachImage.

-
Double-click the ForEachImage activity to edit its contents.
IMPORTANT: Note the design context is displayed on the top left-hand side of the design canvas.

-
From the Activities panel, type “Notebook” in the search box. Drag the Notebook activity on to the design surface. This Notebook activity will pass the image URL as a parameter to the Databricks notebook we created previously.
-
Select the Notebook activity and enter the following details:
- General > Name: GetImageMetadata
- Azure Databricks > Databricks Linked Service: ADPDatabricks
- Settings > Notebook path: [Click Browse and navigate to /Users/your-user-name/NYCImageMetadata-Lab]
- Base Parameters: [Click + New]
- Name: nycImageUrl
- Value:@concat(variables('ImageMetadataContainerUrl'), item().name)IMPORTANT: Variable name is case sensitive!
-
Leave remaining fields with default values.


-
Navigate back to the “Copy NYC Images” pipeline canvas.
-
From the Activities panel, type “Copy Data” in the search box. Drag the Copy Data activity on to the design surface. This copy activity will copy image metadata from the JSON files sitting on the NYCImageMetadata container in SynapseDataLake to the ImageMetadata collection on CosmosDB.
-
Select the Copy Data activity and enter the following details:
- General > Name: ServeImageMetadata
- Source > Source dataset: SynapseDataLake_NYCImageMetadata_JSON
- Sink > Sink dataset: ADPCosmosDB_NYCImageMetadata -
Leave remaining fields with default values.

-
Create a Success (green) precedence constraint between ForEachImage and ServeImageMetadata activities. You can do it by dragging the green connector from ForEachImage and landing the arrow onto ServeImageMetadata.

-
Publish your pipeline changes by clicking the Publish all button.

-
To execute the pipeline, click on Add trigger menu and then Trigger Now.
-
On the Pipeline Run blade, click Finish.

-
To monitor the execution of your pipeline, click on the Monitor menu on the left-hand side panel.
-
You should be able to see the Status of your pipeline execution on the right-hand side panel.

-
Click the View Activity Runs button for detailed information about each activity execution in the pipeline. The whole execution should last between 7-8 minutes.



















In this section you will explore the image metadata records generated by the Azure Data Factory pipeline in CosmosDB. You will use the Cosmos DB’s SQL API to write SQL-like queries and retrieve data based on their criteria.
| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
In the Azure Portal, go to the lab resource group and locate the CosmosDB account ADPCosmosDB-suffix.
-
On the Data Explorer panel, click Open Full Screen button on the top right-hand side of the screen.
-
On the Open Full Screen pop-up window, click Open.

-
On the Azure Cosmos DB Data Explorer window, under NYC > ImageMetadata click the Items menu item to see the full list of documents in the collection.
-
Click any document in the list to see its contents.

-
Click the ellipsis (…) next to ImageMetadata collection.
-
On the pop-up menu, click New SQL Query to open a new query tab.

-
On the New Query 1 window, try the two different SQL Commands from the list. Click the Execute Selection button to execute your query.



SELECT m.id
, m.imageUrl
FROM ImageMetadata as mSELECT m.id
, m.imageUrl
, tags.name
FROM ImageMetadata as m
JOIN tags IN m.tags
WHERE tags.name = 'wedding'-
Check the results in the Results panel.


In this section you are going to use Power BI to visualize data from Cosmos DB. The Power BI report will use an Import connection to retrieve image metadata from Cosmos DB and visualise images sitting in your data lake.
| IMPORTANT |
|---|
| Execute these steps on your host computer |
-
Navigate to the Azure Portal and retrieve the adpcosmosdb-suffix access key.
-
Save it to notepad. You will need it in the next step.


| IMPORTANT |
|---|
| Execute these steps inside the ADPDesktop remote desktop connection |
-
On ADPDesktop, download the Power BI report from the link https://aka.ms/ADPLab4 and save it in the Desktop.
-
Open the file ADPLab4.pbit with Power BI Desktop.
-
When prompted to enter the value of the ADPCosmosDB parameter, type the full server URI: https://adpcosmosdb-*suffix*.documents.azure.com:443/
-
Click Load.

-
When prompted for an Account Key, paste the ADPCosmosDB account key you retrieved in the previous exercise.
-
Click Connect.

-
Once data finish loading, interact with the report by clicking on the different images displayed and check the accuracy of their associated metadata.
-
Save your work and close Power BI Desktop.



