欢迎来到操作系统第一课。在真正打造操作系统前,有一条必经之路:你知道程序是如何运行的吗?一个熟练的编程老手只需肉眼看着代码,就能对其运行的过程了如指掌。
但对于初学者来说,这常常是很困难的事,这需要好几年的程序开发经验,和在长期的程序开发过程中对编程基本功的积累。
我记得自己最初学习操作系统的时候,面对逻辑稍微复杂的一些程序,在编写、调试代码时,就会陷入代码的迷宫,找不到东南西北。
不知道你现在处在什么阶段,是否曾有同样的感受?我常常说,扎实的基本功就像手里的指南针,你可以一步步强大到不依赖它,但是不能没有。
因此今天,我将带领你从“Hello World”起,扎实基本功,探索程序如何运行的所有细节和原理
#include "stdio.h"
int main(int argc, const char **argv) {
printf("Hello world\n");
return 0;
}计算机硬件是无法直接运行这个 C 语言文本程序代码的,需要 C 语言编译器,把这个代码编译成具体硬件平台的二进制代码。再由具体操作系统建立进程,把这个二进制文件装进其进程的内存空间中,才能运行。
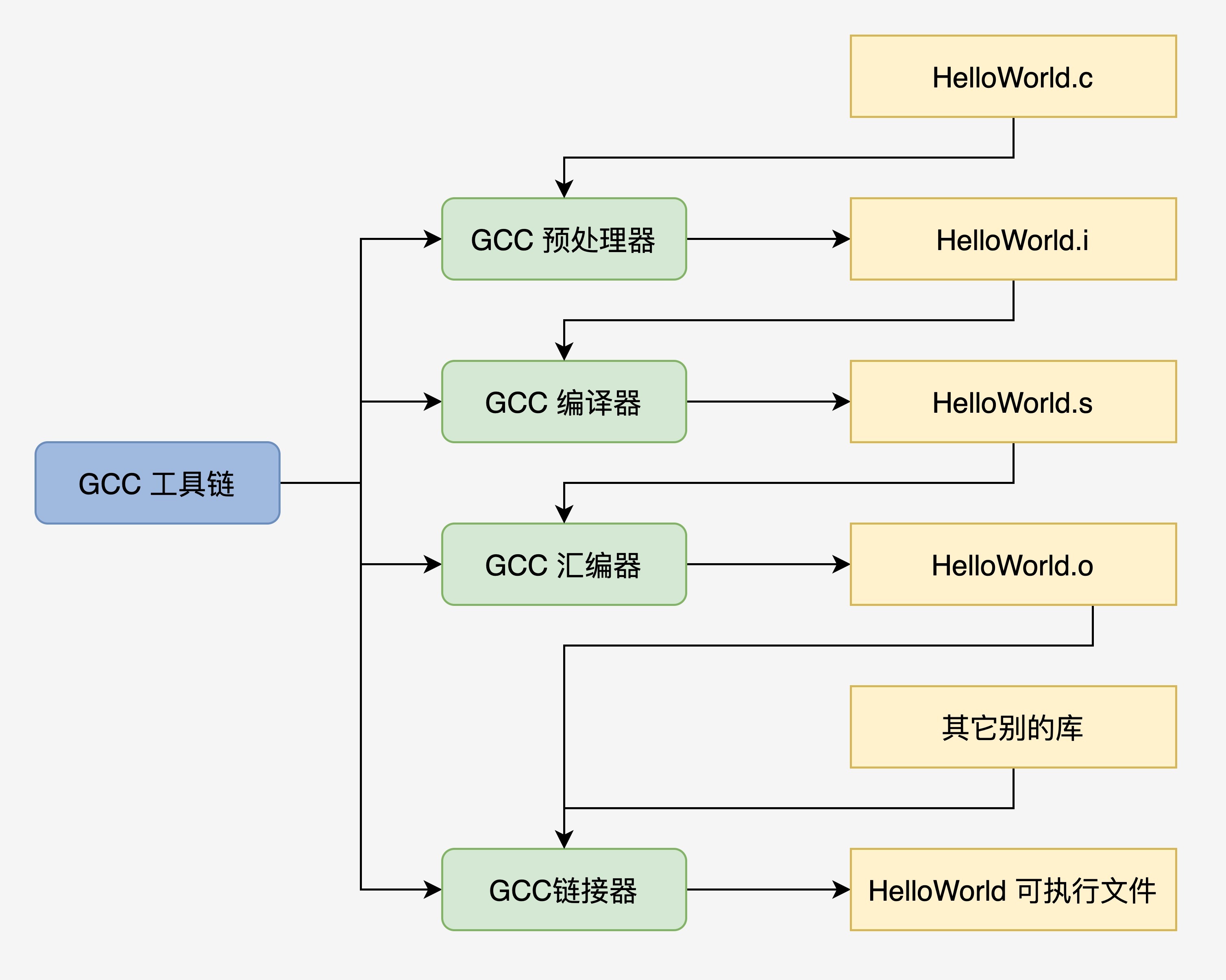
其实,我们也可以手动控制以上这个编译流程,从而留下中间文件方便研究:
- gcc HelloWorld.c -E -o HelloWorld.i 预处理:加入头文件,替换宏。
- gcc HelloWorld.c -S -c HelloWorld.s 编译:包含预处理,将 C 程序转换成汇编程序。
- gcc HelloWorld.c -c HelloWorld.o 汇编:包含预处理和编译,将汇编程序转换成可链接的二进制程序。
- gcc HelloWorld.c -o HelloWorld 链接:包含以上所有操作,将可链接的二进制程序和其它别的库链接在一起,形成可执行的程序文件。
图灵机是一个抽象的模型,它是这样的:有一条无限长的纸带,纸带上有无限个小格子,小格子中写有相关的信息,纸带上有一个读头,读头能根据纸带小格子里的信息做相关的操作并能来回移动。
根据冯诺依曼体系结构构成的计算机,必须具有如下功能:
- 把程序和数据装入到计算机中;
- 必须具有长期记住程序、数据的中间结果及最终运算结果;
- 完成各种算术、逻辑运算和数据传送等数据加工处理;
- 根据需要控制程序走向,并能根据指令控制机器的各部件协调操作;
- 能够按照要求将处理的数据结果显示给用户。
为了完成上述的功能,计算机必须具备五大基本组成部件:
- 装载数据和程序的输入设备;
- 记住程序和数据的存储器;
- 完成数据加工处理的运算器;
- 控制程序执行的控制器;
- 显示处理结果的输出设备
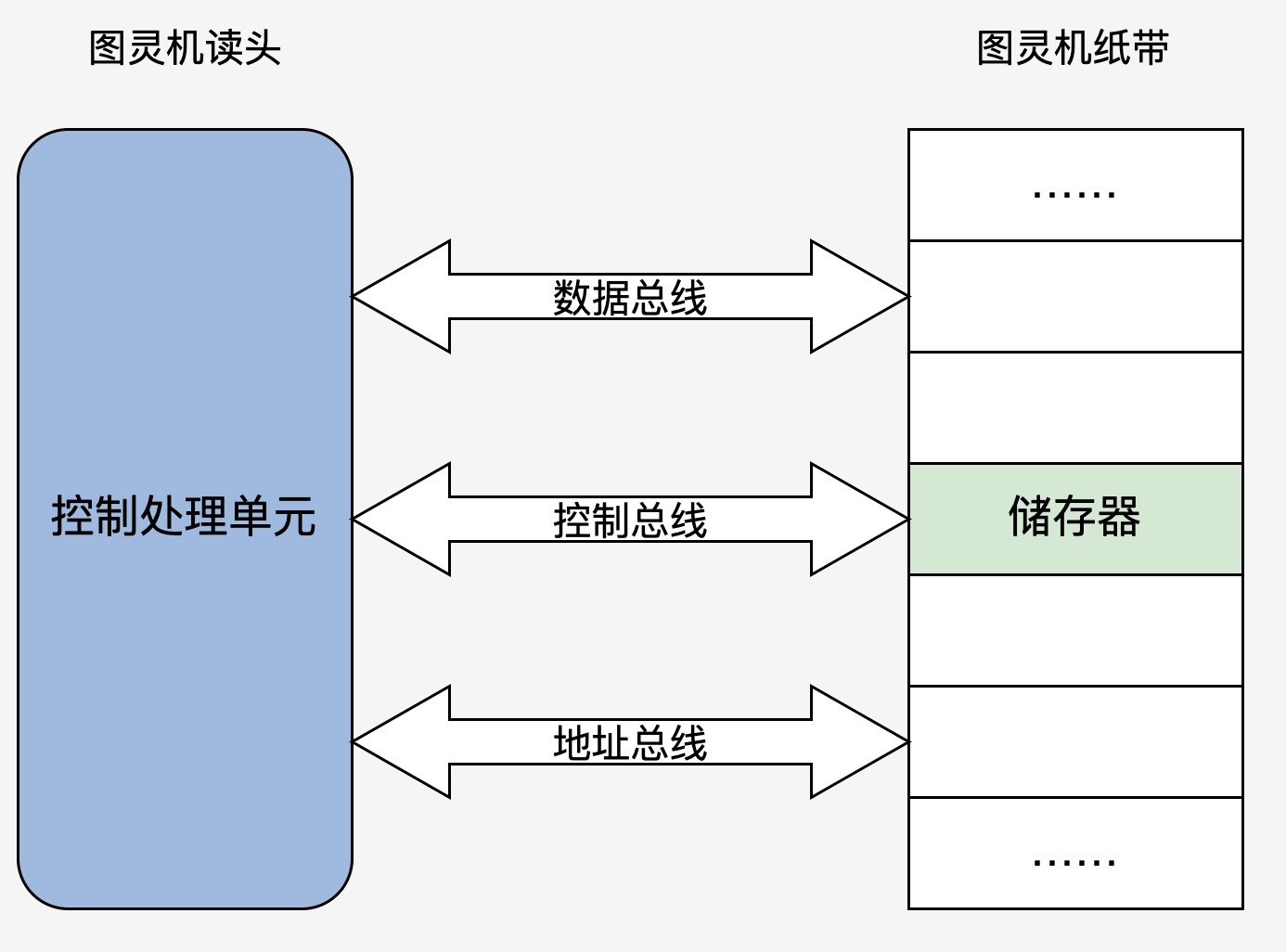
是不是非常简单?这次我们发现读头不再来回移动了,而是靠地址总线寻找对应的“纸带格子”。读取写入数据由数据总线完成,而动作的控制就是控制总线的职责了。


重点回顾以上,对应图中的伪代码你应该明白了:现代电子计算机正是通过内存中的信息(指令和数据)做出相应的操作,并通过内存地址的变化,达到程序读取数据,控制程序流程(顺序、跳转对应该图灵机的读头来回移动)的功能。 这和图灵机的核心思想相比,没有根本性的变化。只要配合一些 I/O 设备,让用户输入并显示计算结果给用户,就是一台现代意义的电子计算机。 到这里,我们理清了程序运行的所有细节和原理。还有一点,你可能有点疑惑,即 printf 对应的 puts 函数,到底做了什么?而这正是我们后面的课程要探索的!

简单解释一下,PC 机 BIOS 固件是固化在 PC 机主板上的 ROM 芯片中的,掉电也能保存,PC 机上电后的第一条指令就是 BIOS 固件中的,它负责检测和初始化 CPU、内存及主板平台,然后加载引导设备(大概率是硬盘)中的第一个扇区数据,到 0x7c00 地址开始的内存空间,再接着跳转到 0x7c00 处执行指令,在我们这里的情况下就是 GRUB 引导程序。
我们先来写一段汇编代码。这里我要特别说明一个问题:为什么不能直接用 C? C 作为通用的高级语言,不能直接操作特定的硬件,而且 C 语言的函数调用、函数传参,都需要用栈。 栈简单来说就是一块内存空间,其中数据满足后进先出的特性,它由 CPU 特定的栈寄存器指向,所以我们要先用汇编代码处理好这些 C 语言的工作环境。
;eintr
mbt_hdr_flags equ 0x00010003
mbt_hdr_magic equ 0x1badb002 ; 多协议引导头魔数
mbt_hdr2_magic equ 0xe85250d6 ; 第二版多协议引导头魔数
global _start ; 导出_start符号
extern main; 导出外部的main函数的符号
[section .start.text] ;定义.start.text代码段
[bits 32] ;汇编成32未代码
_start;
jmp _entry
align 8
mbt_hdr:
dd mbt_hdr_magic
dd mbt_hdr_flags
dd -(mbt_hdr_magic+mbt_hdr_flags)
dd mbt_hdr
dd _start
dd 0
dd 0
dd _entry
; 以上是grub所需要的头
align 8
mbt2_hdr:
dd mbt_hdr2_magic
dd 0
dd mbt2_hdr_end - mbt2_hdr
dd -(mbt_hdr2_magic + 0 + (mbt2_hdr_end - mbt2_hdr))
dw 2, 0
dd 24
dd mbt2_hdr
dd _start
dd 0
dd 0
dw 3, 0
dd 12
dd _entry
dd 0
dw 0, 0
dd 8
mbt2_hdr_end:
;以上是grub2所需要的头
align 8
_entry:
;关中断
cli
;关不可屏蔽中断
in al, 0x70
or al, 0x80
out 0x70,al
;重新加载gdt
lgdt [gdt_ptr]
jmp dword 0x8 :_32bits_mode
_32bits_mode:
;下面初始化c语言可能会用到的寄存器
mov ax, 0x10
mov ds, ax
mov ss, ax
mov es, ax
mov fs, ax
mov gs, ax
xor eax,eax
xor ebx,ebx
xor ecx,ecx
xor edx,edx
xor edi,edi
xor esi,esi
xor ebp,ebp
xor esp,esp
;初始化栈,c语言需要栈才能工作
mov esp,0x9000
;调用c语言函数main
call main
;让cpu停止执行指令
halt_step:
halt
jmp halt_step
gdt_start:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
k16cd_dsc: dq 0x00009e000000ffff
k16da_dsc: dq 0x000092000000ffff
gdt_end:
gdt_ptr:
gdtlen dw gdt_end-gdt_start-1
gdtbase dd gdt_start
以上的汇编代码(/lesson01/HelloOS/entry.asm)分为 4 个部分:
- 代码 1~40 行,用汇编定义的 GRUB 的多引导协议头,其实就是一定格式的数据,我们的 Hello OS 是用 GRUB 引导的,当然要遵循 GRUB 的多引导协议标准,让 GRUB 能识别我们的 Hello OS。之所以有两个引导头,是为了兼容 GRUB1 和 GRUB2。
- 代码 44~52 行,关掉中断,设定 CPU 的工作模式。你现在可能不懂,没事儿,后面 CPU 相关的课程我们会专门再研究它。
- 代码 54~73 行,初始化 CPU 的寄存器和 C 语言的运行环境。
- 代码 78~87 行,GDT_START 开始的,是 CPU 工作模式所需要的数据,同样,后面讲 CPU 时会专门介绍。
接着我们再看下显卡,这和我们接下来要写的代码有直接关联。
计算机屏幕显示往往是显卡的输出,显卡有很多形式:集成在主板的叫集显,做在 CPU 芯片内的叫核显,独立存在通过 PCIE 接口连接的叫独显,性能依次上升,价格也是。
独显的高性能是游戏玩家们所钟爱的,3D 图形显示往往要涉及顶点处理、多边形的生成和变换、纹理、着色、打光、栅格化等。而这些任务的计算量超级大,所以独显往往有自己的 RAM、多达几百个运算核心的处理器。因此独显不仅仅是可以显示图像,而且可以执行大规模并行计算,比如“挖矿”。
我们要在屏幕上显示字符,就要编程操作显卡。其实无论我们 PC 上是什么显卡,它们都支持一种叫 VESA 的标准,这种标准下有两种工作模式:字符模式和图形模式。显卡们为了兼容这种标准,不得不自己提供一种叫 VGABIOS 的固件程序。
下面,我们来看看显卡的字符模式的工作细节。
它把屏幕分成 24 行,每行 80 个字符,把这(24*80)个位置映射到以 0xb8000 地址开始的内存中,每两个字节对应一个字符,其中一个字节是字符的 ASCII 码,另一个字节为字符的颜色值。如下图所示:

#ifndef VGASTR_H_
#define VGASTR_H_
static inline void _strwrite(char* string) {
char *p_strdst = (char*)(0xb8000); // 指向显存的开始地址
while(*string) {
*p_strdst = *string++;
p_strdst += 2;
}
return;
}
inline void printf(char* fmt, ...) {
_strwrite(fmt);
return;
}
#endif // VGASTR_H_
#include "vgastr.h"
int main(int argc, char **argv) {
printf("Hello OS!");
return 0;
}
下面我们用一张图来描述我们 Hello OS 的编译过程,如下所示:

从用户和应用程序的角度来看,内核之中有什么并不重要,能提供什么服务才是重要的,所以内核在用户和上层应用眼里,就像一个大黑盒,至于黑盒里面有什么,怎么实现的,就不用管了。
不过,作为内核这个黑盒的开发者,我们要实现它,就必先设计它,而要设计它,就必先搞清楚内核中有什么。
从抽象角度来看,内核就是计算机资源的管理者,当然管理资源是为了让应用使用资源。既然内核是资源的管理者,我们先来看看计算机中有哪些资源,然后通过资源的归纳,就能推导出内核这个大黑盒中应该有什么。
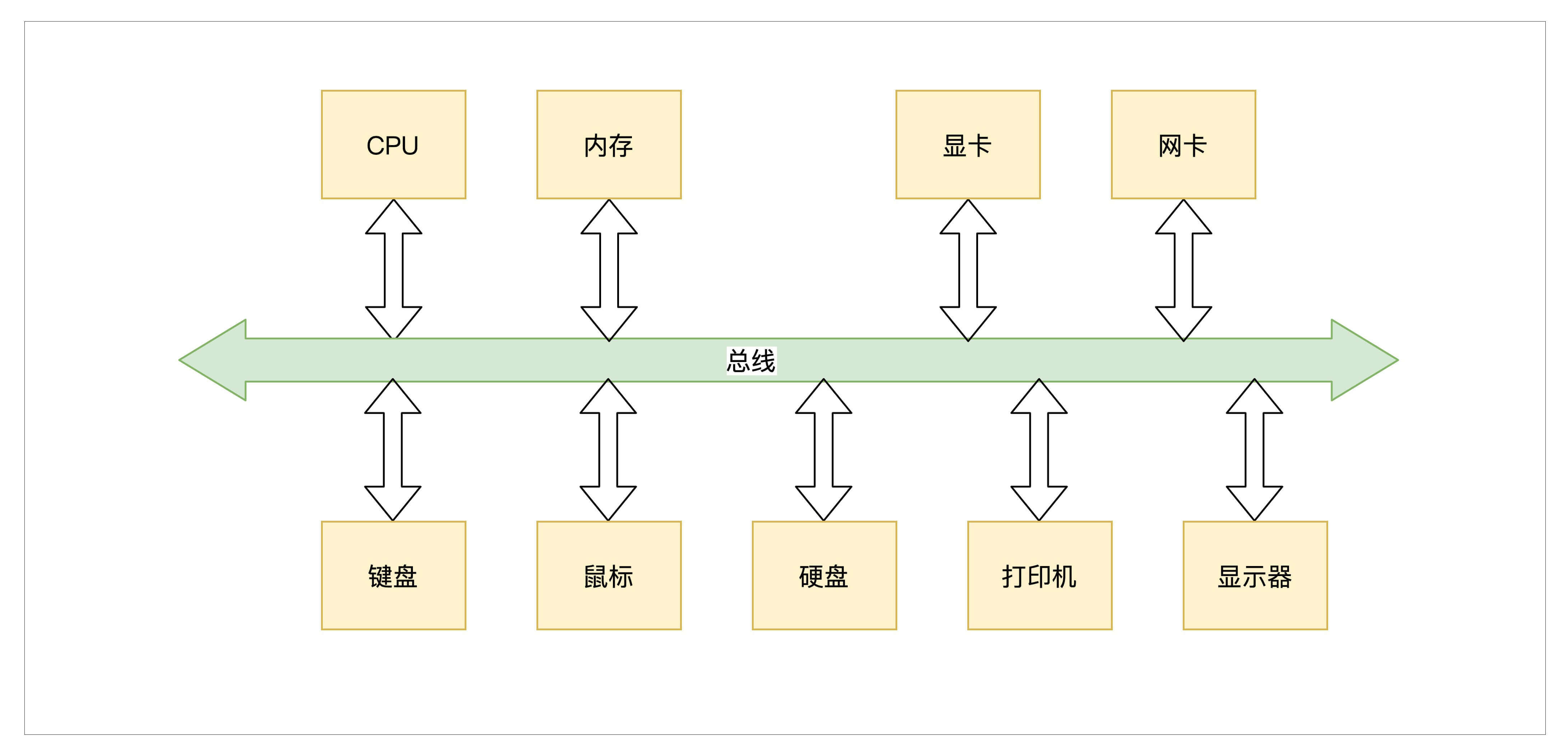
计算机中资源大致可以分为两类资源,一种是硬件资源,一种是软件资源。先来看看硬件资源有哪些,如下:
- 总线,负责连接各种其它设备,是其它设备工作的基础。
- CPU,即中央处理器,负责执行程序和处理数据运算。
- 内存,负责储存运行时的代码和数据。
- 硬盘,负责长久储存用户文件数据。
- 网卡,负责计算机与计算机之间的通信。
- 显卡,负责显示工作。
- 各种 I/O 设备,如显示器,打印机,键盘,鼠标等。
而计算机中的软件资源,则可表示为计算机中的各种形式的数据。如各种文件、软件程序等。
内核作为硬件资源和软件资源的管理者,其内部组成在逻辑上大致如下:
- 管理 CPU,由于 CPU 是执行程序的,而内核把运行时的程序抽象成进程,所以又称为进程管理。
- 管理内存,由于程序和数据都要占用内存,内存是非常宝贵的资源,所以内核要非常小心地分配、释放内存。
- 管理硬盘,而硬盘主要存放用户数据,而内核把用户数据抽象成文件,即管理文件,文件需要合理地组织,方便用户查找和读写,所以形成了文件系统。
- 管理显卡,负责显示信息,而现在操作系统都是支持 GUI(图形用户接口)的,管理显卡自然而然地就成了内核中的图形系统。
- 管理网卡,网卡主要完成网络通信,网络通信需要各种通信协议,最后在内核中就形成了网络协议栈,又称网络组件。
- 管理各种 I/O 设备,我们经常把键盘、鼠标、打印机、显示器等统称为 I/O(输入输出)设备,在内核中抽象成 I/O 管理器。
内核除了这些必要组件之外,根据功能不同还有安全组件等,最值得一提的是,各种计算机硬件的性能不同,硬件型号不同,硬件种类不同,硬件厂商不同,内核要想管理和控制这些硬件就要编写对应的代码,通常这样的代码我们称之为驱动程序。
硬件厂商就可以根据自己不同的硬件编写不同的驱动,加入到内核之中
以上我们已经大致知道了内核之中有哪些组件,但是另一个问题又出现了,即如何组织这些组件,让系统更加稳定和高效,这就需要我们从现有的一些经典内核结构里找灵感了。
其实看这名字,就已经能猜到了,宏即大也,这种最简单适用,也是最早的一种内核结构。
宏内核就是把以上诸如管理进程的代码、管理内存的代码、管理各种 I/O 设备的代码、文件系统的代码、图形系统代码以及其它功能模块的代码,把这些所有的代码经过编译,最后链接在一起,形成一个大的可执行程序。
这个大程序里有实现支持这些功能的所有代码,向用户应用软件提供一些接口,这些接口就是常说的系统 API 函数。而这个大程序会在处理器的特权模式下运行,这个模式通常被称为宏内核模式。结构如下图所示。

尽管图中一层一层的,这并不是它们有层次关系,仅仅表示它们链接在一起。
为了理解宏内核的工作原理,我们来看一个例子,宏内核提供内存分配功能的服务过程,具体如下:
- 应用程序调用内存分配的 API(应用程序接口)函数。
- 处理器切换到特权模式,开始运行内核代码。
- 内核里的内存管理代码按照特定的算法,分配一块内存。
- 把分配的内存块的首地址,返回给内存分配的 API 函数。
- 内存分配的 API 函数返回,处理器开始运行用户模式下的应用程序,应用程序就得到了一块内存的首地址,并且可以使用这块内存了。
上面这个过程和一个实际的操作系统中的运行过程,可能有差异,但大同小异。当然,系统 API 和应用程序之间可能还有库函数,也可能只是分配了一个虚拟地址空间,但是我们关注的只是这个过程。
上图的宏内核结构有明显的缺点,因为它没有模块化,没有扩展性、没有移植性,高度耦合在一起,一旦其中一个组件有漏洞,内核中所有的组件可能都会出问题。
开发一个新的功能也得重新编译、链接、安装内核。其实现在这种原始的宏内核结构已经没有人用了。这种宏内核唯一的优点是性能很好,因为在内核中,这些组件可以互相调用,性能极高。
为了方便我们了解不同内核架构间的优缺点,下面我们看一个和宏内核结构对应的反例。
微内核架构正好与宏内核架构相反,它提倡内核功能尽可能少:仅仅只有进程调度、处理中断、内存空间映射、进程间通信等功能(目前不懂没事,这是属于管理进程和管理内存的功能模块,后面课程里还会专门探讨的)。
这样的内核是不能完成什么实际功能的,开发者们把实际的进程管理、内存管理、设备管理、文件管理等服务功能,做成一个个服务进程。和用户应用进程一样,只是它们很特殊,宏内核提供的功能,在微内核架构里由这些服务进程专门负责完成。
微内核定义了一种良好的进程间通信的机制——消息。应用程序要请求相关服务,就向微内核发送一条与此服务对应的消息,微内核再把这条消息转发给相关的服务进程,接着服务进程会完成相关的服务。服务进程的编程模型就是循环处理来自其它进程的消息,完成相关的服务功能。其结构如下所示:
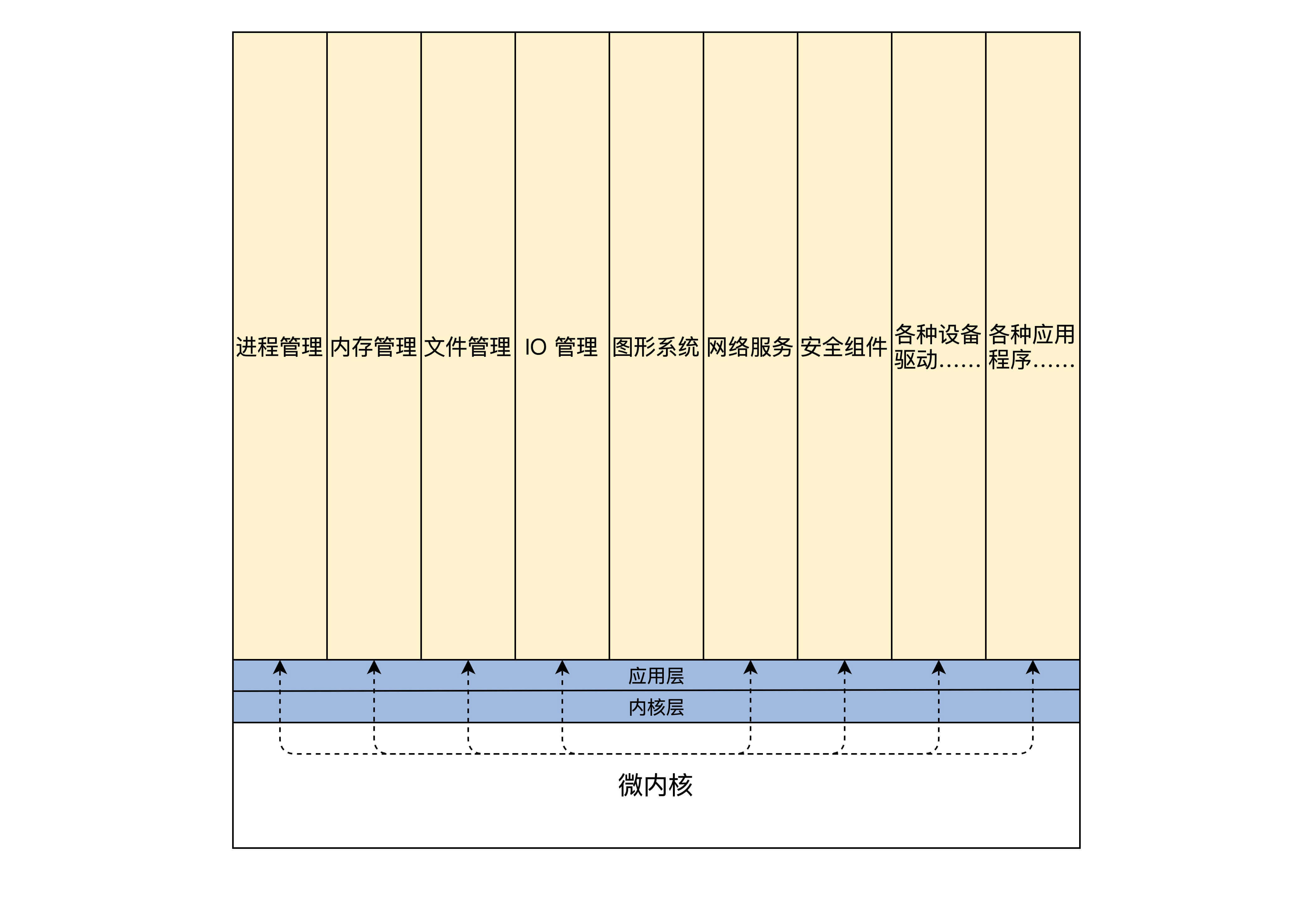
为了理解微内核的工程原理,我们来看看微内核提供内存分配功能的服务过程,具体如下:
- 应用程序发送内存分配的消息,这个发送消息的函数是微内核提供的,相当于系统 API,微内核的 API(应用程序接口)相当少,极端情况下仅需要两个,一个接收消息的 API 和一个发送消息的 API。
- 处理器切换到特权模式,开始运行内核代码。
- 微内核代码让当前进程停止运行,并根据消息包中的数据,确定消息发送给谁,分配内存的消息当然是发送给内存管理服务进程。
- 内存管理服务进程收到消息,分配一块内存。
- 内存管理服务进程,也会通过消息的形式返回分配内存块的地址给内核,然后继续等待下一条消息。
- 微内核把包含内存块地址的消息返回给发送内存分配消息的应用程序。
- 处理器开始运行用户模式下的应用程序,应用程序就得到了一块内存的首地址,并且可以使用这块内存了。
微内核的架构实现虽然不同,但是大致过程和上面一样。同样是分配内存,在微内核下拐了几个弯,一来一去的消息带来了非常大的开销,当然各个服务进程的切换开销也不小。这样系统性能就大打折扣。
但是微内核有很多优点,首先,系统结构相当清晰利于协作开发。其次,系统有良好的移植性,微内核代码量非常少,就算重写整个内核也不是难事。最后,微内核有相当好的伸缩性、扩展性,因为那些系统功能只是一个进程,可以随时拿掉一个服务进程以减少系统功能,或者增加几个服务进程以增强系统功能。
微内核的代表作有 MACH、MINIX、L4 系统,这些系统都是微内核,但是它们不是商业级的系统,商业级的系统不采用微内核主要还是因为性能差。
好了,粗略了解了宏内核和微内核两大系统内核架构的优、缺点,以后设计我们自己的系统内核时,心里也就有了底了,到时就可以扬长避短了,下面我们先学习一点其它的东西,即分离硬件相关性,为设计出我们自己的内核架构打下基础。
我们会经常听说,Windows 内核有什么 HAL 层、Linux 内核有什么 arch 层。这些 xx 层就是 Windows 和 Linux 内核设计者,给他们的系统内核分的第一个层。
今天如此庞杂的计算机,其实也是一层一层地构建起来的,从硬件层到操作系统层再到应用软件层这样构建。分层的主要目的和好处在于屏蔽底层细节,使上层开发更加简单。
计算机领域的一个基本方法是增加一个抽象层,从而使得抽象层的上下两层独立地发展,所以在内核内部再分若干层也不足为怪。分离硬件的相关性,就是要把操作硬件和处理硬件功能差异的代码抽离出来,形成一个独立的软件抽象层,对外提供相应的接口,方便上层开发。
为了让你更好理解,我们举进程管理中的一个模块实现细节的例子:进程调度模块。通过这个例子,来看看分层对系统内核的设计与开发有什么影响。
一般操作系统理论课程都会花大量篇幅去讲进程相关的概念,其实说到底,进程是操作系统开发者为了实现多任务而提出的,并让每个进程在 CPU 上运行一小段时间,这样就能实现多任务同时运行的假象。
当然,这种假象十分奏效。要实现这种假象,就要实现下面这两种机制:
- 进程调度,它的目的是要从众多进程中选择一个将要运行的进程,当然有各种选择的算法,例如,轮转算法、优先级算法等。
- 进程切换,它的目的是停止当前进程,运行新的进程,主要动作是保存当前进程的机器上下文,装载新进程的机器上下文。
我们不难发现,不管是在 ARM 硬件平台上还是在 x86 硬件平台上,选择一个进程的算法和代码是不容易发生改变的,需要改变的代码是进程切换的相关代码,因为不同的硬件平台的机器上下文是不同的。所以,这时最好是将进程切换的代码放在一个独立的层中实现,比如硬件平台相关层,当操作系统要运行在不同的硬件平台上时,就只是需要修改硬件平台相关层中的相关代码,这样操作系统的移植性就大大增强了。
如果把所有硬件平台相关的代码,都抽离出来,放在一个独立硬件相关层中实现并且定义好相关的调用接口,再在这个层之上开发内核的其它功能代码,就会方便得多,结构也会清晰很多。操作系统的移植性也会大大增强,移植到不同的硬件平台时,就构造开发一个与之对应的硬件相关层。这就是分离硬件相关性的好处。
从前面内容中,我们知道了内核必须要完成的功能,宏内核架构和微内核架构各自的优、缺点,最后还分析了分离硬件相关层的重要性,其实说了这么多,就是为了设计我们自己的操作系统内核。
虽然前面的内容,对操作系统设计这个领域还远远不够,但是对于我们自己从零开始的操作系统内核这已经够了。
首先大致将我们的操作系统内核分为三个大层,分别是:
- 内核接口层。
- 内核功能层。
- 内核硬件层。
内核接口层,定义了一系列接口,主要有两点内容,如下:
- 定义了一套 UNIX 接口的子集,我们出于学习和研究的目的,使用 UNIX 接口的子集,优点之一是接口少,只有几个,并且这几个接口又能大致定义出操作系统的功能。
- 这套接口的代码,就是检查其参数是否合法,如果参数有问题就返回相关的错误,接着调用下层完成功能的核心代码。
内核功能层,主要完成各种实际功能,这些功能按照其类别可以分成各种模块,当然这些功能模块最终会用具体的算法、数据结构、代码去实现它,内核功能层的模块如下:
- 进程管理,主要是实现进程的创建、销毁、调度进程,当然这要设计几套数据结构用于表示进程和组织进程,还要实现一个简单的进程调度算法。
- 内存管理,在内核功能层中只有内存池管理,分两种内存池:页面内存池和任意大小的内存池,你现在可能不明白什么是内存池,这里先有个印象就行,后面课程研究它的时候再详细介绍。
- 中断管理,这个在内核功能层中非常简单:就是把一个中断回调函数安插到相关的数据结构中,一旦发生相关的中断就会调用这个函数。
- 设备管理,这个是最难的,需要用一系列的数据结构表示驱动程序模块、驱动程序本身、驱动程序创建的设备,最后把它们组织在一起,还要实现创建设备、销毁设备、访问设备的代码,这些代码最终会调用设备驱动程序,达到操作设备的目的。
内核硬件层,主要包括一个具体硬件平台相关的代码,如下:
- 初始化,初始化代码是内核被加载到内存中最先需要运行的代码,例如初始化少量的设备、CPU、内存、中断的控制、内核用于管理的数据结构等。
- CPU 控制,提供 CPU 模式设定、开、关中断、读写 CPU 特定寄存器等功能的代码。
- 中断处理,保存中断时机器的上下文,调用中断回调函数,操作中断控制器等。
- 物理内存管理,提供分配、释放大块内存,内存空间映射,操作 MMU、Cache 等。
- 平台其它相关的功能,有些硬件平台上有些特殊的功能,需要额外处理一下。
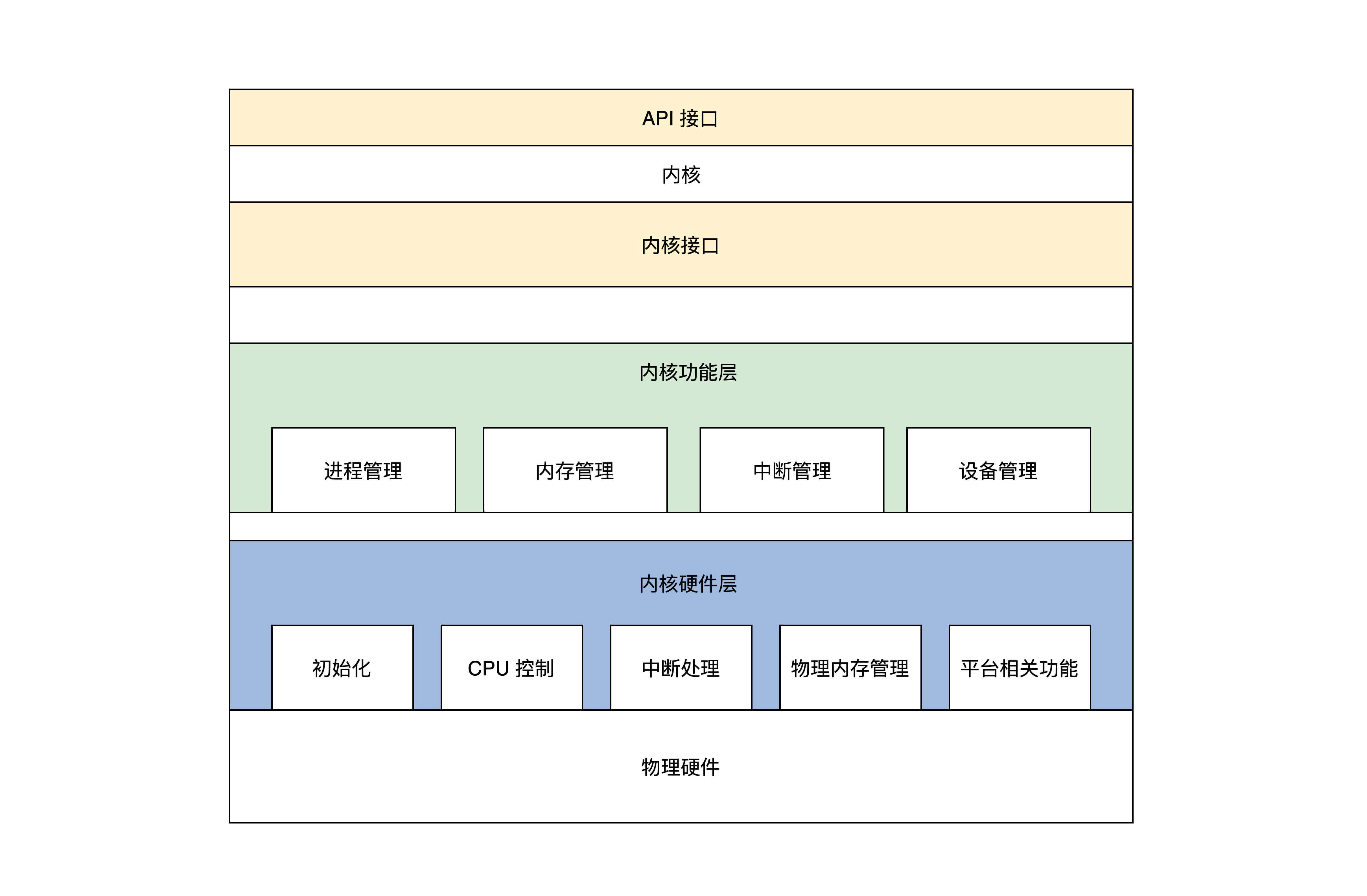
从上述文字和图示,可以发现,我们的操作系统内核没有任何设备驱动程序,甚至没有文件系统和网络组件,内核所实现的功能很少。这吸取了微内核的优势,内核小出问题的可能性就少,扩展性就越强。
同时,我们把文件系统、网络组件、其它功能组件作为虚拟设备交由设备管理,比如需要文件系统时就写一个文件系统虚拟设备的驱动,完成文件系统的功能,需要网络时就开发一个网络虚拟设备的驱动,完成网络功能。这些驱动一旦被装载,就是内核的一部分了,并不是像微内核一样作为服务进程运行。这又吸取了宏内核的优势,代码高度耦合,性能强劲。
这样的内核架构既不是宏内核架构也不是微内核架构,而是这两种架构综合的结果,可以说是混合内核架构,也可以说这是我们自己的内核架构……
好了,到这里为止,我们已经设计了内核,确定了内核的功能并且设计了一种内核架构用来组织这些功能,这离完成我们自己的操作系统内核又进了一步。
Linux 的基本思想是一切都是文件:每个文件都有确定的用途,包括用户数据、命令、配置参数、硬件设备等对于操作系统内核而言,都被视为各种类型的文件。Linux 支持多用户,各个用户对于自己的文件有自己特殊的权利,保证了各用户之间互不影响。
多任务则是现代操作系统最重要的一个特点,Linux 可以使多个程序同时并独立地运行。Linux 发展到今天,不是哪一个人能做到的,更不是一群计算机黑客能做到的,而是由很多世界级的顶尖科技公司联合开发,如 IBM、甲骨文、红帽、英特尔、微软,它们开发 Linux 并向 Linux 社区提供补丁,使 Linux 工作在它们的服务器上,向客户出售业务服务。
Linux 发展到今天其代码量近 2000 万行,可以用浩如烟海来形容,没人能在短时间内弄清楚。但是你也不用害怕,我们可以先看看 Linux 内部的全景图,从全局了解一下 Linux 的内部结构,如下图。

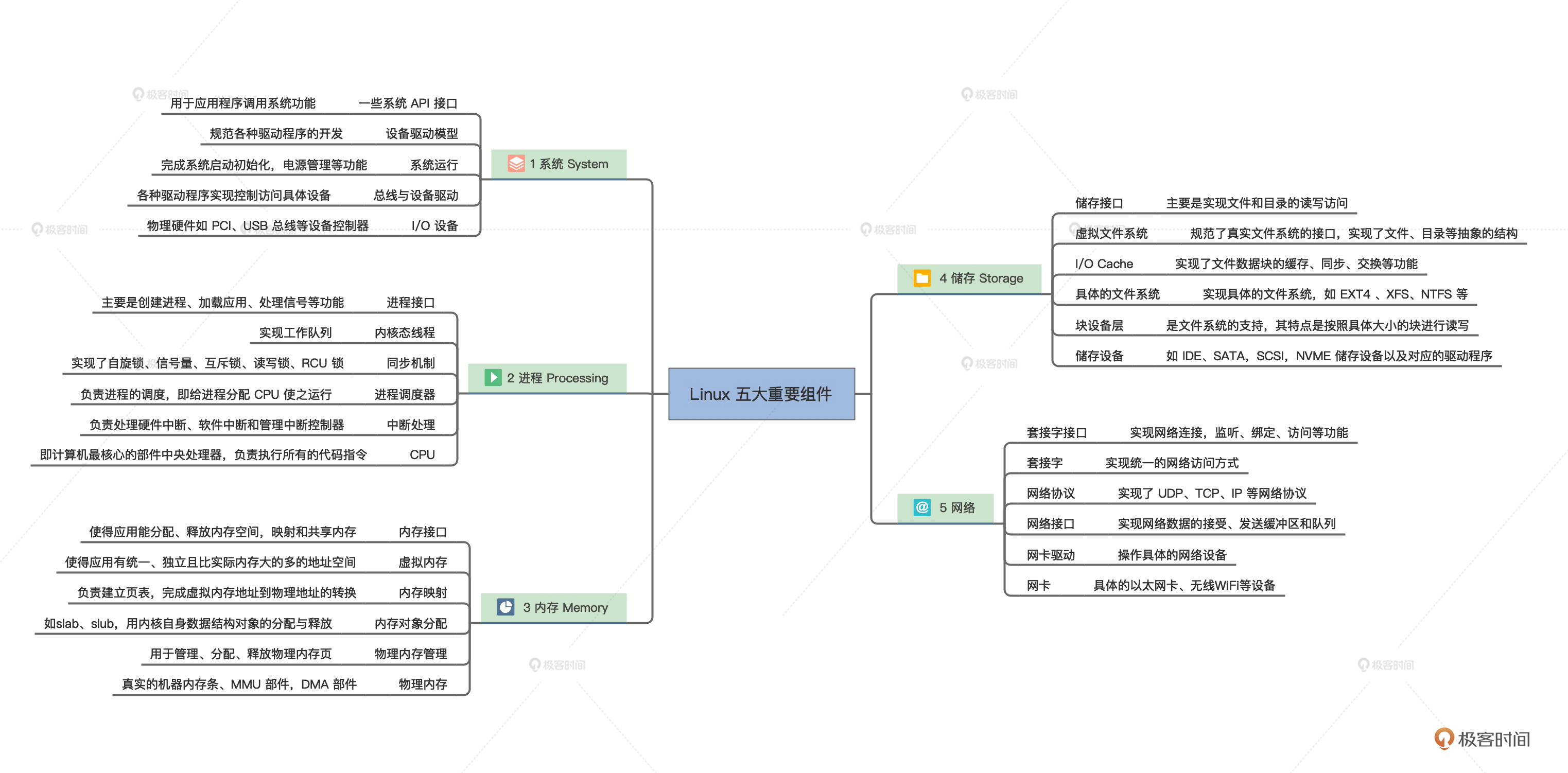
我们就能发现 Linux 这么多模块挤在一起,之间的通信主要是函数调用,而且函数间的调用没有一定的层次关系,更加没有左右边界的限定。函数的调用路径是纵横交错的,从图中的线条可以得到印证。继续深入思考你就会发现,这些纵横交错的路径上有一个函数出现了问题,就麻烦大了,它会波及到全部组件,导致整个系统崩溃。
当然调试解决这个问题,也是相当困难的。同样,模块之间没有隔离,安全隐患也是巨大的。当然,这种结构不是一无是处,它的性能极高,而性能是衡量操作系统的一个重要指标。
这种结构就是传统的内核结构,也称为宏内核架构。
我们先来看看 Darwin,Darwin 是由苹果公司在 2000 年开发的一个开放源代码的操作系统。
一个经久不衰的公司,必然有自己的核心竞争力,也许是商业策略,也许是技术产品,又或是这两者的结合。而作为苹果公司各种产品和强大的应用生态系统的支撑者——Darwin,更是公司核心竞争力中的核心。
苹果公司有台式计算机、笔记本、平板、手机,台式计算机、笔记本使用了 macOS 操作系统,平板和手机则使用了 iOS 操作系统。Darwin 作为 macOS 与 iOS 操作系统的核心,从技术实现角度说,它必然要支持 PowerPC、x86、ARM 架构的处理器。
Darwin 使用了一种微内核(Mach)和相应的固件来支持不同的处理器平台,并提供操作系统原始的基础服务,上层的功能性系统服务和工具则是整合了 BSD 系统所提供的。苹果公司还为其开发了大量的库、框架和服务,不过它们都工作在用户态且闭源。
下面我们先从整体看一下 Darwin 的架构。Darwin架构图什么?两套内核?惊不惊喜?由于我们是研究 Darwin 内核,所以上图中我们只需要关注内核 - 用户转换层以下的部分即可。显然它有两个内核层——Mach 层与 BSD 层。Mach 内核是卡耐基梅隆大学开发的经典微内核,意在提供最基本的操作系统服务,从而达到高性能、安全、可扩展的目的,而 BSD 则是伯克利大学开发的类 UNIX 操作系统,提供一整套操作系统服务。那为什么两套内核会同时存在呢?
MAC OS X(2011 年之前的称呼)的发展经过了不同时期,随着时代的进步,产品功能需求增加,单纯的 Mach 之上实现出现了性能瓶颈,但是为了兼容之前为 Mach 开发的应用和设备驱动,就保留了 Mach 内核,同时加入了 BSD 内核。Mach 内核仍然提供十分简单的进程、线程、IPC 通信、虚拟内存设备驱动相关的功能服务,BSD 则提供强大的安全特性,完善的网络服务,各种文件系统的支持,同时对 Mach 的进程、线程、IPC、虚拟内核组件进行细化、扩展延伸。
那么应用如何使用 Darwin 系统的服务呢?应用会通过用户层的框架和库来请求 Darwin 系统的服务,即调用 Darwin 系统 API。
在调用 Darwin 系统 API 时,会传入一个 API 号码,用这个号码去索引 Mach 陷入中断服务表中的函数。此时,API 号码如果小于 0,则表明请求的是 Mach 内核的服务,API 号码如果大于 0,则表明请求的是 BSD 内核的服务,它提供一整套标准的 POSIX 接口。
就这样,Mach 和 BSD 就同时存在了。Mach 中还有一个重要的组件 Libkern,它是一个库,提供了很多底层的操作函数,同时支持 C++ 运行环境。
依赖这个库的还有 IOKit,IOKit 管理所有的设备驱动和内核功能扩展模块。驱动程序开发人员则可以使用 C++ 面向对象的方式开发驱动,这个方式很优雅,你完全可以找一个成熟的驱动程序作为父类继承它,要特别实现某个功能就重载其中的函数,也可以同时继承其它驱动程序,这大大节省了内存,也大大降低了出现 BUG 的可能。
如果你要详细了解 Darwin 内核的话,可以自行阅读相应的代码。而在这里,你只要从全局认识一下它的结构就行了。
接下来我们再看下 NT 内核。现代 Windows 的内核就是 NT,我们不妨先看看 NT 的历史。
如果你是 90 后,大概没有接触过 MS-DOS,它的交互方式是你在键盘上输入相应的功能命令,它完成相应的功能后给用户返回相应的操作信息,没有图形界面。在 MS-DOS 内核的实现上,也没有应用现代硬件的保护机制,这导致后来微软基于它开发的图形界面的操作系统,如 Windows 3.1、Windows95/98/ME,极其不稳定,且容易死机。加上类 UNIX 操作系统在互联网领域大行其道,所以微软急需一款全新的操作系统来与之竞争。所以,Windows NT 诞生了。Windows NT 是微软于 1993 年推出的面向工作站、网络服务器和大型计算机的网络操作系统,也可做 PC 操作系统。
它是一款全新从零开始开发的新操作系统,并应用了现代硬件的所有特性,“NT”所指的便是“新技术”(New Technology)。而普通用户第一次接触基于 NT 内核的 Windows 是 Windows 2000,一开始用户其实是不愿意接受的,因为 Windows 2000 对用户的硬件和应用存在兼容性问题。随着硬件厂商和应用厂商对程序的升级,这个兼容性问题被缓解了,加之 Windows 2000 的高性能、高稳定性、高安全性,用户很快便接受了这个操作系统。这可以从 Windows 2000 的迭代者 Windows XP 的巨大成功,得到验证。
现在,NT 内核在设计上层次非常清晰明了,各组件之间界限耦合程度很低。下面我们就来看看 NT 内核架构图,了解一下 NT 内核是如何“庄严宏伟”。如下图:

这样看 NT 内核架构,是不是就清晰了很多?但这并不是我画图画得清晰,事实上的 NT 确实如此。
这里我要提示一下,上图中我们只关注内核模式下的东西,也就是传统意义上的内核。
当然微软自己在 HAL 层上是定义了一个小内核,小内核之下是硬件抽象层 HAL,这个 HAL 存在的好处是:不同的硬件平台只要提供对应的 HAL 就可以移植系统了。小内核之上是各种内核组件,微软称之为内核执行体,它们完成进程、内存、配置、I/O 文件缓存、电源与即插即用、安全等相关的服务。每个执行体互相独立,只对外提供相应的接口,其它执行体要通过内核模式可调用接口和其它执行体通信或者请求其完成相应的功能服务。所有的设备驱动和文件系统都由 I/O 管理器统一管理,驱动程序可以堆叠形成 I/O 驱动栈,功能请求被封装成 I/O 包,在栈中一层层流动处理。Windows 引以为傲的图形子系统也在内核中。
显而易见,NT 内核中各层次分明,各个执行体互相独立,这种“高内聚、低偶合”的特性,正是检验一个软件工程是否优秀的重要标准。而这些你都可以通过微软公开的 WRK 代码得到佐证,如果你觉得 WRK 代码量太少,也可以看一看REACT OS这个号称“开源版”的 NT。
到这里,我们了解了 Linux、Darwin-XNU 和 Windows 的发展历史,也清楚了它们内部的组件和结构,并对它们的架构进行了对比,对比后我们发现:Linux 性能良好,结构异常复杂,不利于问题的排查和功能的扩展,而 Darwin-XNU 和 Windows 结构良好,层面分明,利于功能扩展,不容易产生问题且性能稳定。
由于 OS 内核直接运行在硬件之上,所以我们要对运行我们代码的硬件平台有一定的了解。接下来,我会通过三节课,带你搞懂硬件平台的关键内容。
我们先来学习 CPU 的工作模式,硬件中最重要的就是 CPU,它就是执行程序的核心部件。而我们常用的电脑就是 x86 平台,所以我们要对 x86 CPU 有一些基本的了解。
按照 CPU 功能升级迭代的顺序,CPU 的工作模式有实模式、保护模式、长模式,这几种工作模式下 CPU 执行程序的方式截然不同,下面我们一起来探讨这几种工作模式
请思考一下,如果下面这段应用程序代码能够成功运行,会有什么后果?
int main() {
int *addr = (int*)0;
cli();// 关中断
while(1) {
*addr = 0;
addr++;
}
return 0;
}
上述代码首先关掉了 CPU 中断,让 CPU 停止响应中断信号,然后进入死循环,最后从内存 0 地址开始写入 0。你马上就会想到,这段代码只做了两件事:一是锁住了 CPU,二是清空了内存,你也许会觉得如果这样的代码能正常运行,那简直太可怕了。
不过如果是在实模式下,这样的代码确实是能正常运行。因为在很久以前,计算机资源太少,内存太小,都是单道程序执行,程序大多是由专业人员编写调试好了,才能预约到一个时间去上机运行,没有现代操作系统的概念。
实模式又称实地址模式,实,即真实,这个真实分为两个方面,一个方面是运行真实的指令,对指令的动作不作区分,直接执行指令的真实功能,另一方面是发往内存的地址是真实的,对任何地址不加限制地发往内存。
由于 CPU 是根据指令完成相应的功能,举个例子:ADD AX,CX;这条指令完成加法操作,AX、CX 为 ADD 指令的操作数,可以理解为 ADD 函数的两个参数,其功能就是把 AX、CX 中的数据相加。指令的操作数,可以是寄存器、内存地址、常数,其实通常情况下是寄存器,AX、CX 就是 x86 CPU 中的寄存器。
下面我们就去看看 x86 CPU 在实模式下的寄存器。表中每个寄存器都是 16 位的。

虽然有了寄存器,但是数据和指令都是存放在内存中的。通常情况下,需要把数据装载进寄存器中才能操作,还要有获取指令的动作,这些都要访问内存才行,而我们知道访问内存靠的是地址值。

结合上图可以发现,所有的内存地址都是由段寄存器左移 4 位,再加上一个通用寄存器中的值或者常数形成地址,然后由这个地址去访问内存。这就是大名鼎鼎的分段内存管理模型。
只不过这里要特别注意的是,代码段是由 CS 和 IP 确定的,而栈段是由 SS 和 SP 段确定的。
data SEGMENT ;定义一个数据段存放Hello World!
hello DB 'Hello World!$' ;注意要以$结束
data ENDS
code SEGMENT ;定义一个代码段存放程序指令
ASSUME CS:CODE,DS:DATA ;告诉汇编程序,DS指向数据段,CS指向代码段
start:
MOV AX,data ;将data段首地址赋值给AX
MOV DS,AX ;将AX赋值给DS,使DS指向data段
LEA DX,hello ;使DX指向hello首地址
MOV AH,09h ;给AH设置参数09H,AH是AX高8位,AL是AX低8位,其它类似
INT 21h ;执行DOS中断输出DS指向的DX指向的字符串hello
MOV AX,4C00h ;给AX设置参数4C00h
INT 21h ;调用4C00h号功能,结束程序
code ENDS
END start上述代码中的结构模型,也是符合 CPU 实模式下分段内存管理模式的,它们被汇编器转换成二进制数据后,也是以段的形式存在的。
代码中的注释已经很明确了,你应该很容易就能理解,大多数是操作寄存器,其中 LEA 是取地址指令,MOV 是数据传输指令,就是 INT 中断你可能还不太明白,下面我们就来研究它。
中断即中止执行当前程序,转而跳转到另一个特定的地址上,去运行特定的代码。在实模式下它的实现过程是先保存 CS 和 IP 寄存器,然后装载新的 CS 和 IP 寄存器,那么中断是如何产生的呢? 第一种情况是,中断控制器给 CPU 发送了一个电子信号,CPU 会对这个信号作出应答。随后中断控制器会将中断号发送给 CPU,这是硬件中断。 第二种情况就是 CPU 执行了 INT 指令,这个指令后面会跟随一个常数,这个常数即是软中断号。这种情况是软件中断。 无论是硬件中断还是软件中断,都是 CPU 响应外部事件的一种方式(信号)。 为了实现中断,就需要在内存中放一个中断向量表,这个表的地址和长度由 CPU 的特定寄存器 IDTR 指向。实模式下,表中的一个条目由代码段地址和段内偏移组成,如下图所示。

随着软件的规模不断增加,需要更高的计算量、更大的内存容量。
内存一大,首先要解决的问题是寻址问题,因为 16 位的寄存器最多只能表示 216 个地址,所以 CPU 的寄存器和运算单元都要扩展成 32 位的。
不过,虽然扩展 CPU 内部器件的位数解决了计算和寻址问题,但仍然没有解决前面那个实模式场景下的问题,导致前面场景出问题的原因有两点。
- CPU 对任何指令不加区分地执行;
- CPU 对访问内存的地址不加限制。
基于这些原因,CPU 实现了保护模式。保护模式是如何实现保护功能的呢?我们接着往下看。
保护模式相比于实模式,增加了一些控制寄存器和段寄存器,扩展通用寄存器的位宽,所有的通用寄存器都是 32 位的,还可以单独使用低 16 位,这个低 16 位又可以拆分成两个 8 位寄存器,如下表。

为了区分哪些指令(如 in、out、cli)和哪些资源(如寄存器、I/O 端口、内存地址)可以被访问,CPU 实现了特权级。
特权级分为 4 级,R0~R3,每个特权级执行指令的数量不同,R0 可以执行所有指令,R1、R2、R3 依次递减,它们只能执行上一级指令数量的子集。而内存的访问则是靠后面所说的段描述符和特权级相互配合去实现的。如下图.

上面的圆环图,从外到内,既能体现权力的大小,又能体现各特权级对资源控制访问的多少,还能体现各特权级之间的包含关系。R0 拥有最大权力,可以访问低特权级的资源,反之则不行。
目前为止,内存还是分段模型,要对内存进行保护,就可以转换成对段的保护。
由于 CPU 的扩展导致了 32 位的段基地址和段内偏移,还有一些其它信息,所以 16 位的段寄存器肯定放不下。放不下就要找内存借空间,然后把描述一个段的信息封装成特定格式的段描述符,放在内存中,其格式如下。

一个段描述符有 64 位 8 字节数据,里面包含了段基地址、段长度、段权限、段类型(可以是系统段、代码段、数据段)、段是否可读写,可执行等。虽然数据分布有点乱,这是由于历史原因造成的。
多个段描述符在内存中形成全局段描述符表,该表的基地址和长度由 CPU 和 GDTR 寄存器指示。如下图所示。

如果你认为 CS、DS、ES、SS、FS、GS 这些段寄存器,里面存放的就是一个内存段的描述符索引,那你可就草率了,其实它们是由影子寄存器、段描述符索引、描述符表索引、权限级别组成的。如下图所示。

上图中影子寄存器是靠硬件来操作的,对系统程序员不可见,是硬件为了减少性能损耗而设计的一个段描述符的高速缓存,不然每次内存访问都要去内存中查表,那性能损失是巨大的,影子寄存器也正好是 64 位,里面存放了 8 字节段描述符数据。
低三位之所以能放 TI 和 RPL,是因为段描述符 8 字节对齐,每个索引低 3 位都为 0,我们不用关注 LDT,只需要使用 GDT 全局描述符表,所以 TI 永远设为 0。
通常情况下,CS 和 SS 中 RPL 就组成了 CPL(当前权限级别),所以常常是 RPL=CPL,进而 CPL 就表示发起访问者要以什么权限去访问目标段,当 CPL 大于目标段 DPL 时,则 CPU 禁止访问,只有 CPL 小于等于目标段 DPL 时才能访问。
分段模型有很多缺陷,这在后面课程讲内存管理时有详细介绍,其实现代操作系统都会使用分页模型(这点在后面讲 MMU 那节课再探讨)。
但是 x86 CPU 并不能直接使用分页模型,而是要在分段模型的前提下,根据需要决定是否要开启分页。因为这是硬件的规定,程序员是无法改变的。但是我们可以简化设计,来使分段成为一种“虚设”,这就是保护模式的平坦模型。
根据前面的描述,我们发现 CPU 32 位的寄存器最多只能产生 4GB 大小的地址,而一个段长度也只能是 4GB,所以我们把所有段的基地址设为 0,段的长度设为 0xFFFFF,段长度的粒度设为 4KB(2^20 * 2^12),这样所有的段都指向同一个(0~4GB-1)字节大小的地址空间。
下面我们还是看一看前面 Hello OS 中段描述符表,如下所示。
gdt_start:
knull_dsc: dq 0 ; 第一个段描述符cpu硬件规定必须为0
kcode_dsc: dq 0x00cf9e000000ffff
; 段基地址=0 段长度=0xfffff
; G=1, D/B=1, L=0, AVL=0
; P=1, DPL=0, S=1
; T=1, C=0, R=1, A=0
kdata_dsc: dq 0x00cf92000000ffff
; 段基地址=0 段长度=0xfffff
; G=1, D/B=1, L=0, AVL=0
; P=1, DPL=0, S=1
; T=0, C=0, R=1, A=0
k16cd_dsc: dq 0x00009e000000ffff
k16da_dsc: dq 0x000092000000ffff
gdt_end:
gdt_ptr:
gdtlen dw gdt_end-gdt_start-1
gdtbase dd gdt_start
因为实模式下 CPU 不需要做权限检查,所以它可以直接通过中断向量表中的值装载 CS:IP 寄存器就好了。
而保护模式下的中断要权限检查,还有特权级的切换,所以就需要扩展中断向量表的信息,即每个中断用一个中断门描述符来表示,也可以简称为中断门,中断门描述符依然有自己的格式,如下图所示。

同样的,保护模式要实现中断,也必须在内存中有一个中断向量表,同样是由 IDTR 寄存器指向,只不过中断向量表中的条目变成了中断门描述符,如下图所示。

产生中断后,CPU 首先会检查中断号是否大于最后一个中断门描述符,x86 CPU 最大支持 256 个中断源(即中断号:0~255),然后检查描述符类型(是否是中断门或者陷阱门)、是否为系统描述符,是不是存在于内存中。
接着,检查中断门描述符中的段选择子指向的段描述符。
最后做权限检查,如果 CPL 小于等于中断门的 DPL 并且 CPL 大于等于中断门中的段选择子,就指向段描述符的 DPL。
进一步的,CPL 等于中断门中的段选择子指向段描述符的 DPL,则为同级权限不进行栈切换,否则进行栈切换。如果进行栈切换,还需要从 TSS 中加载具体权限的 SS、ESP,当然也要对 SS 中段选择子指向的段描述符进行检查。
做完这一系列检查之后,CPU 才会加载中断门描述符中目标代码段选择子到 CS 寄存器中,把目标代码段偏移加载到 EIP 寄存器中。
x86 CPU 在第一次加电和每次 reset 后,都会自动进入实模式,要想进入保护模式,就需要程序员写代码实现从实模式切换到保护模式。切换到保护模式的步骤如下。
GDT_START:
knull_dsc: dq 0
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1
GDTBASE dd GDT_STARTlgdt [GDT_PTR]; 开启PE
mov eax, cr0
bts eax, 0 ; CR0.PE = 1
mov cr0, eaxjmp dword 0x8 :_32bits_mode ;_32bits_mode为32位代码标号即段偏移你也许会有疑问,为什么要进行长跳转,这是因为我们无法直接或间接 mov 一个数据到 CS 寄存器中,因为刚刚开启保护模式时,CS 的影子寄存器还是实模式下的值,所以需要告诉 CPU 加载新的段信息。
接下来,CPU 发现了 CRO 寄存器第 0 位的值是 1,就会按 GDTR 的指示找到全局描述符表,然后根据索引值 8,把新的段描述符信息加载到 CS 影子寄存器,当然这里的前提是进行一系列合法的检查。
到此为止,CPU 真正进入了保护模式,CPU 也有了 32 位的处理能力。
长模式又名 AMD64,因为这个标准是 AMD 公司最早定义的,它使 CPU 在现有的基础上有了 64 位的处理能力,既能完成 64 位的数据运算,也能寻址 64 位的地址空间。这在大型计算机上犹为重要,因为它们的物理内存通常有几百 GB。
长模式相比于保护模式,增加了一些通用寄存器,并扩展通用寄存器的位宽,所有的通用寄存器都是 64 位,还可以单独使用低 32 位。
这个低 32 位可以拆分成一个低 16 位寄存器,低 16 位又可以拆分成两个 8 位寄存器,如下表。

长模式依然具备保护模式绝大多数特性,如特权级和权限检查。相同的部分就不再重述了,这里只会说明长模式和保护模式下的差异。下面我们来看看长模式下段描述的格式,如下图所示。

在长模式下,CPU 不再对段基址和段长度进行检查,只对 DPL 进行相关的检查,这个检查流程和保护模式下一样。
当描述符中的 L=1,D/B=0 时,就是 64 位代码段,DPL 还是 0~3 的特权级。然后有多个段描述在内存中形成一个全局段描述符表,同样由 CPU 的 GDTR 寄存器指向。
下面我们来写一个长模式下的段描述符表,加深一下理解,如下所示.
ex64_GDT;
null_dsc: dq 0
; 第一个段描述符cpu硬件规定必须为0
c64_dsc:dp 0x0020980000000000 ;64位代码段
; 无效位填0
; D/B=0,L=1,AVL=0
; P=1,DPL=0,S=1
; T=1,C=0,R=0,A=0
d64_dsc:dq 0x0000920000000000 ;64位数据段
; 无效位填0
; P=1,DPL=0,S=1
; T=0,C/E=0,R/W=1,A=0
eGdtLen equ $ - null_dsc ;GDT长度
eGdtPtr:dw eGdtLen - 1 ;GDT界限
dq ex64_GDT上面代码中注释已经很清楚了,段长度和段基址都是无效的填充为 0,CPU 不做检查。但是上面段描述符的 DPL=0,这说明需要最高权限即 CPL=0 才能访问。若是数据段的话,G、D/B、L 位都是无效的。
保护模式下为了实现对中断进行权限检查,实现了中断门描述符,在中断门描述符中存放了对应的段选择子和其段内偏移,还有 DPL 权限,如果权限检查通过,则用对应的段选择子和其段内偏移装载 CS:EIP 寄存器。
如果你还记得中断门描述符,就会发现其中的段内偏移只有 32 位,但是长模式支持 64 位内存寻址,所以要对中断门描述符进行修改和扩展,下面我们就来看看长模式下的中断门描述符的格式,如下图所示。

结合上图,我们可以看出长模式下中断门描述符的格式变化。
首先为了支持 64 位寻址中断门描述符在原有基础上增加 8 字节,用于存放目标段偏移的高 32 位值。其次,目标代码段选择子对应的代码段描述符必须是 64 位的代码段。最后其中的 IST 是 64 位 TSS 中的 IST 指针,因为我们不使用这个特性,所以不作详细介绍。
长模式也同样在内存中有一个中断门描述符表,只不过表中的条目(如上图所示)是 16 字节大小,最多支持 256 个中断源,对中断的响应和相关权限的检查和保护模式一样,这里不再赘述。
我们既可以从实模式直接切换到长模式,也可以从保护模式切换长模式。切换到长模式的步骤如下。
ex64_GDT:
null_dsc: dq 0
;第一个段描述符CPU硬件规定必须为0
c64_dsc:dq 0x0020980000000000 ;64位代码段
d64_dsc:dq 0x0000920000000000 ;64位数据段
eGdtLen equ $ - null_dsc ;GDT长度
eGdtPtr:dw eGdtLen - 1 ;GDT界限
dq ex64_GDT这个是为了开启分页模式,切换到长模式必须要开启分页,想想看,长模式下已经不对段基址和段长度进行检查了,那么内存地址空间就得不到保护了。
而长模式下内存地址空间的保护交给了 MMU,MMU 依赖页表对地址进行转换,页表有特定的格式存放在内存中,其地址由 CPU 的 CR3 寄存器指向,这在后面讲 MMU 的那节课会专门讲。
mov eax, cr4
bts eax, 5; CR4.PAE = 1
mov cr4, eax ; 开启PAE
mov eax, PAGE_TLB_BADR ; 页表物理地址
mov cr3, eaxlgdt [eGdtPtr]在实现长模式时定义了 MSR 寄存器,需要用专用的指令 rdmsr、wrmsr 进行读写,IA32_EFER 寄存器的地址为 0xC0000080,它的第 8 位决定了是否开启长模式。
; 开启 64位长模式
mov ecx, IA32_EFER
rdmsr
bts eax, 8 ;IA32_EFER.LME =1
wrmsr
; 开启 保护模式和分页模式
mov eax, cr0
bts eax, 0 ;CR0.PE =1
bts eax, 31
mov cr0, eax jmp 08:entry64 ;entry64为程序标号即64位偏移地址好,这节课的内容告一段落了,我来给你做个总结。
今天我们从一段死循环的代码开始思考,研究这类代码产生的问题和解决思路,然后一步步探索 CPU 为了处理这些问题而做出的改进和升级。这些功能上的改进和升级,渐渐演变成了 CPU 的工作模式,这也是系统开发人员需要了解的编程模型。
这三种模式梳理如下。
- 实模式,早期 CPU 是为了支持单道程序运行而实现的,单道程序能掌控计算机所有的资源,早期的软件规模不大,内存资源也很少,所以实模式极其简单,仅支持 16 位地址空间,分段的内存模型,对指令不加限制地运行,对内存没有保护隔离作用。
- 保护模式,随着多道程序的出现,就需要操作系统了。内存需求量不断增加,所以 CPU 实现了保护模式以支持这些需求。保护模式包含特权级,对指令及其访问的资源进行控制,对内存段与段之间的访问进行严格检查,没有权限的绝不放行,对中断的响应也要进行严格的权限检查,扩展了 CPU 寄存器位宽,使之能够寻址 32 位的内存地址空间和处理 32 位的数据,从而 CPU 的性能大大提高。
- 长模式,又名 AMD64 模式,最早由 AMD 公司制定。由于软件对 CPU 性能需求永无止境,所以长模式在保护模式的基础上,把寄存器扩展到 64 位同时增加了一些寄存器,使 CPU 具有了能处理 64 位数据和寻址 64 位的内存地址空间的能力。 长模式弱化段模式管理,只保留了权限级别的检查,忽略了段基址和段长度,而地址的检查则交给了 MMU。
从前面的课程我们得知,CPU 执行程序、处理数据都要和内存打交道,这个打交道的方式就是内存地址。
读取指令、读写数据都需要首先告诉内存芯片:hi,内存老哥请你把 0x10000 地址处的数据交给我……hi,内存老哥,我已经计算完成,请让我把结果写回 0x200000 地址的空间。这些地址存在于代码指令字段后的常数,或者存在于某个寄存器中。
今天,我们就来专门研究一下程序中的地址。说起程序中的地址,不知道你是否好奇过,为啥系统设计者要引入虚拟地址呢?
我会先带你从一个多程序并发的场景热身,一起思考这会导致哪些问题,为什么能用虚拟地址解决这些问题。
搞懂原理之后,我还会带你一起探索虚拟地址和物理地址的关系和转换机制。在后面的课里,你会发现,我们最宝贵的内存资源正是通过这些机制来管理的。
设想一下,如果一台计算机的内存中只运行一个程序 A,这种方式正好用前面 CPU 的实模式来运行,因为程序 A 的地址在链接时就可以确定,例如从内存地址 0x8000 开始,每次运行程序 A 都装入内存 0x8000 地址处开始运行,没有其它程序干扰
现在改变一下,内存中又放一道程序 B,程序 A 和程序 B 各自运行一秒钟,如此循环,直到其中之一结束。这个新场景下就会产生一些问题,当然这里我们只关心内存相关的这几个核心问题。
- 谁来保证程序 A 跟程序 B 没有内存地址的冲突?换句话说,就是程序 A、B 各自放在什么内存地址,这个问题是由 A、B 程序协商,还是由操作系统决定。
- 怎样保证程序 A 跟程序 B 不会互相读写各自的内存空间?这个问题相对简单,用保护模式就能解决。
- 如何解决内存容量问题?程序 A 和程序 B,在不断开发迭代中程序代码占用的空间会越来越大,导致内存装不下。
- 还要考虑一个扩展后的复杂情况,如果不只程序 A、B,还可能有程序 C、D、E、F、G……它们分别由不同的公司开发,而每台计算机的内存容量不同。这时候,又对我们的内存方案有怎样的影响呢?
要想完美地解决以上最核心的 4 个问题,一个较好的方案是:让所有的程序都各自享有一个从 0 开始到最大地址的空间,这个地址空间是独立的,是该程序私有的,其它程序既看不到,也不能访问该地址空间,这个地址空间和其它程序无关,和具体的计算机也无关。
事实上,计算机科学家们早就这么做了,这个方案就是虚拟地址,下面我们就来看看它。
正如其名,这个地址是虚拟的,自然而然地和具体环境进行了解耦,这个环境包括系统软件环境和硬件环境。
虚拟地址是逻辑上存在的一个数据值,比如 0100 就有 101 个整数值,这个 0100 的区间就可以说是一个虚拟地址空间,该虚拟地址空间有 101 个地址。
我们再来看看最开始 Hello World 的例子,我们用 objdump 工具反汇编一下 Hello World 二进制文件,就会得到如下的代码片段:
00000000000004e8 <_init>:
4e8: 48 83 ec 08 sub $0x8,%rsp
4ec: 48 8b 05 f5 0a 20 00 mov 0x200af5(%rip),%rax # 200fe8 <__gmon_start__>
4f3: 48 85 c0 test %rax,%rax
4f6: 74 02 je 4fa <_init+0x12>
4f8: ff d0 callq *%rax
4fa: 48 83 c4 08 add $0x8,%rsp
4fe: c3 retq 上述代码中,左边第一列数据就是虚拟地址,第三列中是程序指令,如:“mov 0x200af5(%rip),%rax,je 4fa,callq *%rax”指令中的数据都是虚拟地址。
事实上,所有的应用程序开始的部分都是这样的。这正是因为每个应用程序的虚拟地址空间都是相同且独立的。
那么这个地址是由谁产生的呢?
答案是链接器,其实我们开发软件经过编译步骤后,就需要链接成可执行文件才可以运行,而链接器的主要工作就是把多个代码模块组装在一起,并解决模块之间的引用,即处理程序代码间的地址引用,形成程序运行的静态内存空间视图。
只不过这个地址是虚拟而统一的,而根据操作系统的不同,这个虚拟地址空间的定义也许不同,应用软件开发人员无需关心,由开发工具链给自动处理了。由于这虚拟地址是独立且统一的,所以各个公司开发的各个应用完全不用担心自己的内存空间被占用和改写。
虽然虚拟地址解决了很多问题,但是虚拟地址只是逻辑上存在的地址,无法作用于硬件电路的,程序装进内存中想要执行,就需要和内存打交道,从内存中取得指令和数据。而内存只认一种地址,那就是物理地址。
什么是物理地址呢?物理地址在逻辑上也是一个数据,只不过这个数据会被地址译码器等电子器件变成电子信号,放在地址总线上,地址总线电子信号的各种组合就可以选择到内存的储存单元了。
但是地址总线上的信号(即物理地址),也可以选择到别的设备中的储存单元,如显卡中的显存、I/O 设备中的寄存器、网卡上的网络帧缓存器。不过如果不做特别说明,我们说的物理地址就是指选择内存单元的地址。
明白了虚拟地址和物理地址之后,我们发现虚拟地址必须转换成物理地址,这样程序才能正常执行。要转换就必须要转换机构,它相当于一个函数:p=f(v),输入虚拟地址 v,输出物理地址 p。
那么要怎么实现这个函数呢?
用软件方式实现太低效,用硬件实现没有灵活性,最终就用了软硬件结合的方式实现,它就是 MMU(内存管理单元)。MMU 可以接受软件给出的地址对应关系数据,进行地址转换。
我们先来看看逻辑上的 MMU 工作原理框架图。如下图所示:
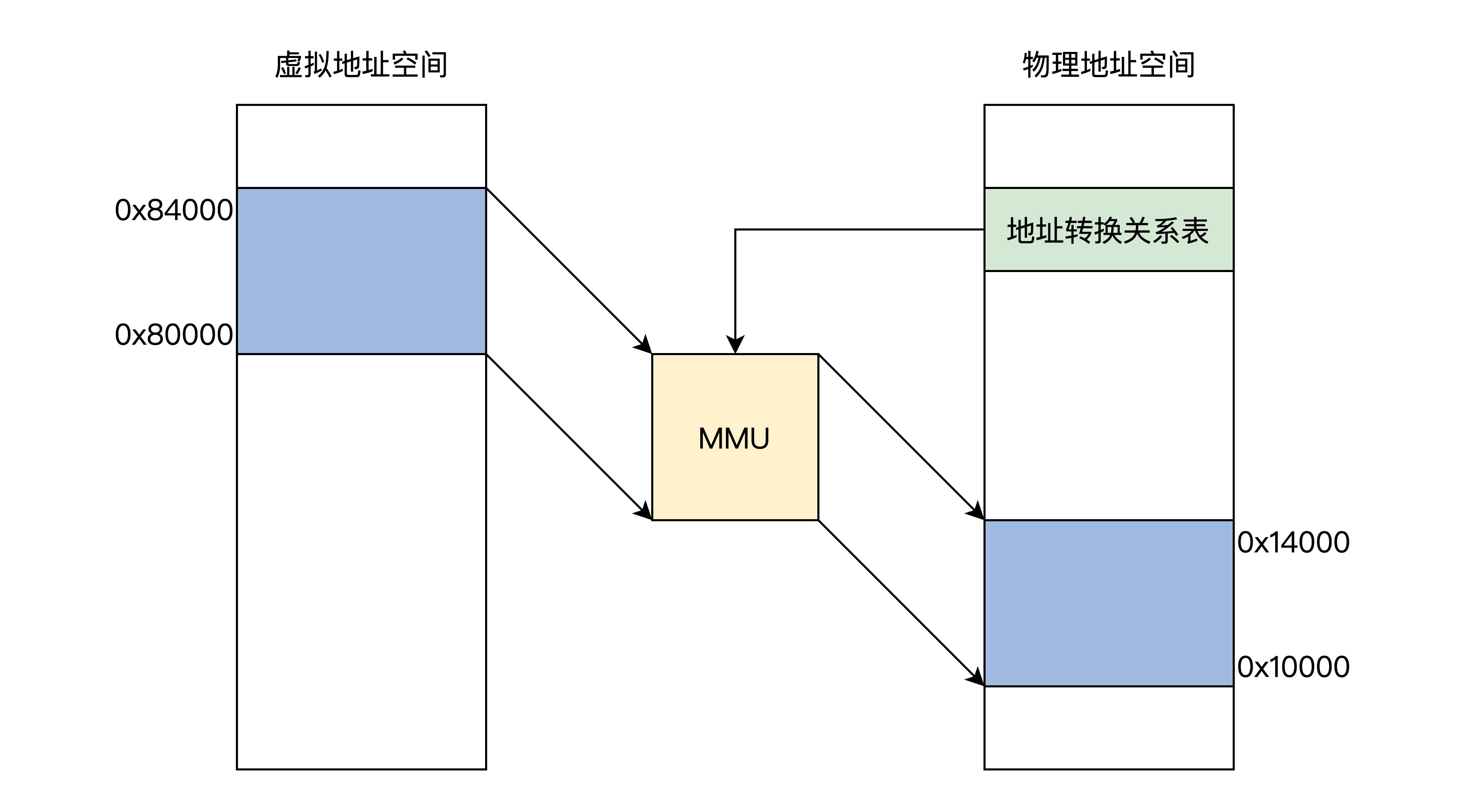
上图中展示了 MMU 通过地址关系转换表,将 0x800000x84000 的虚拟地址空间转换成 0x100000x14000 的物理地址空间,而地址关系转换表本身则是放物理内存中的。
下面我们不妨想一想地址关系转换表的实现. 如果在地址关系转换表中,这样来存放:一个虚拟地址对应一个物理地址。
那么问题来了,32 位地址空间下,4GB 虚拟地址的地址关系转换表就会把整个 32 位物理地址空间用完,这显然不行。
要是结合前面的保护模式下分段方式呢,地址关系转换表中存放:一个虚拟段基址对应一个物理段基址,这样看似可以,但是因为段长度各不相同,所以依然不可取。
综合刚才的分析,系统设计者最后采用一个折中的方案,即把虚拟地址空间和物理地址空间都分成同等大小的块,也称为页,按照虚拟页和物理页进行转换。根据软件配置不同,这个页的大小可以设置为 4KB、2MB、4MB、1GB,这样就进入了现代内存管理模式——分页模型。
下面来看看分页模型框架,如下图所示:
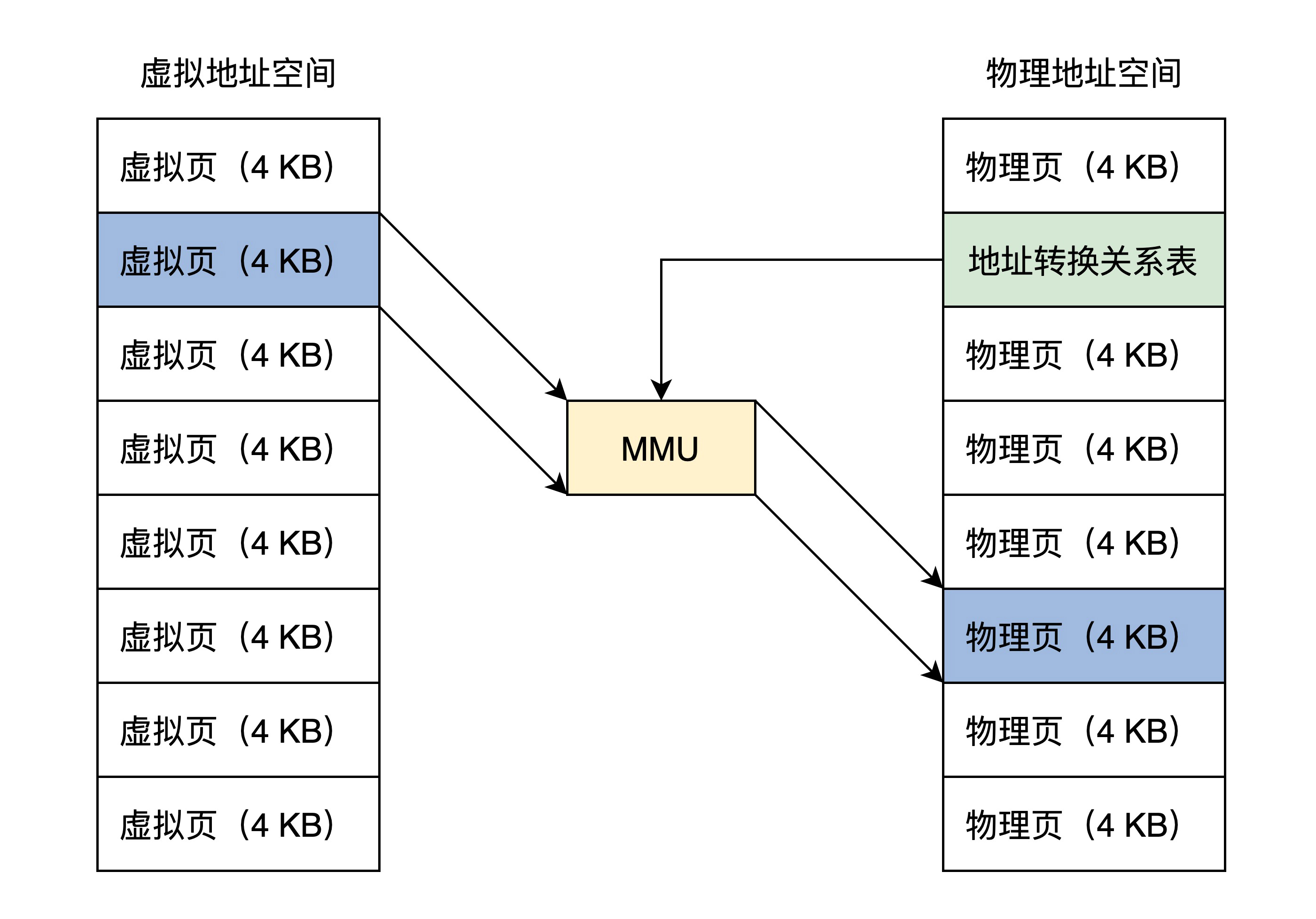
结合图片可以看出,一个虚拟页可以对应到一个物理页,由于页大小一经配置就是固定的,所以在地址关系转换表中,只要存放虚拟页地址对应的物理页地址就行了。
我知道,说到这里,也许你仍然没搞清楚 MMU 和地址关系转换表的细节,别急,我们现在已经具备了研究它们的基础,下面我们就去探索它们。
MMU 即内存管理单元,是用硬件电路逻辑实现的一个地址转换器件,它负责接受虚拟地址和地址关系转换表,以及输出物理地址。
根据实现方式的不同,MMU 可以是独立的芯片,也可以是集成在其它芯片内部的,比如集成在 CPU 内部,x86、ARM 系列的 CPU 就是将 MMU 集成在 CPU 核心中的。
SUN 公司的 CPU 是将独立的 MMU 芯片卡在总线上的,有一夫当关的架势。下面我们只研究 x86 CPU 中的 MMU。x86 CPU 要想开启 MMU,就必须先开启保护模式或者长模式,实模式下是不能开启 MMU 的。
由于保护模式的内存模型是分段模型,它并不适合于 MMU 的分页模型,所以我们要使用保护模式的平坦模式,这样就绕过了分段模型。这个平坦模型和长模式下忽略段基址和段长度是异曲同工的。地址产生的过程如下所示。
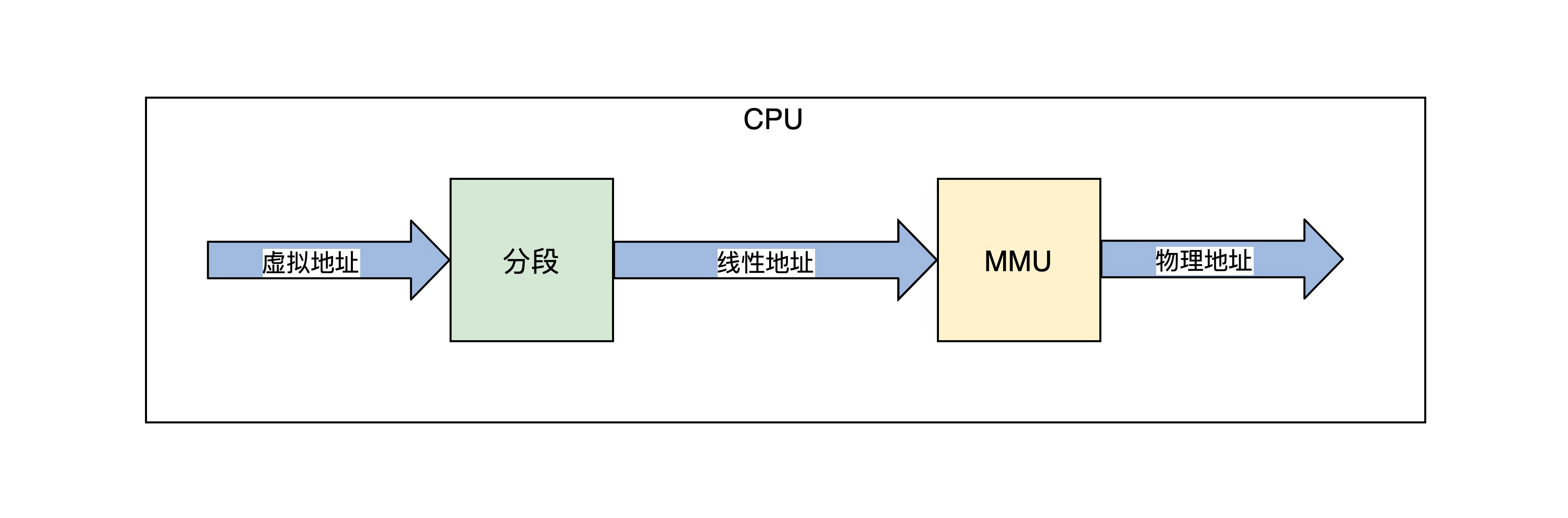
上图中,程序代码中的虚拟地址,经过 CPU 的分段机制产生了线性地址,平坦模式和长模式下线性地址和虚拟地址是相等的。
如果不开启 MMU,在保护模式下可以关闭 MMU,这个线性地址就是物理地址。因为长模式下的分段弱化了地址空间的隔离,所以开启 MMU 是必须要做的,开启 MMU 才能访问内存地址空间。
现在我们开始研究地址关系转换表,其实它有个更加专业的名字——页表。它描述了虚拟地址到物理地址的转换关系,也可以说是虚拟页到物理页的映射关系,所以称为页表。
为了增加灵活性和节约物理内存空间(因为页表是放在物理内存中的),所以页表中并不存放虚拟地址和物理地址的对应关系,只存放物理页面的地址,MMU 以虚拟地址为索引去查表返回物理页面地址,而且页表是分级的,总体分为三个部分:一个顶级页目录,多个中级页目录,最后才是页表,逻辑结构图如下.
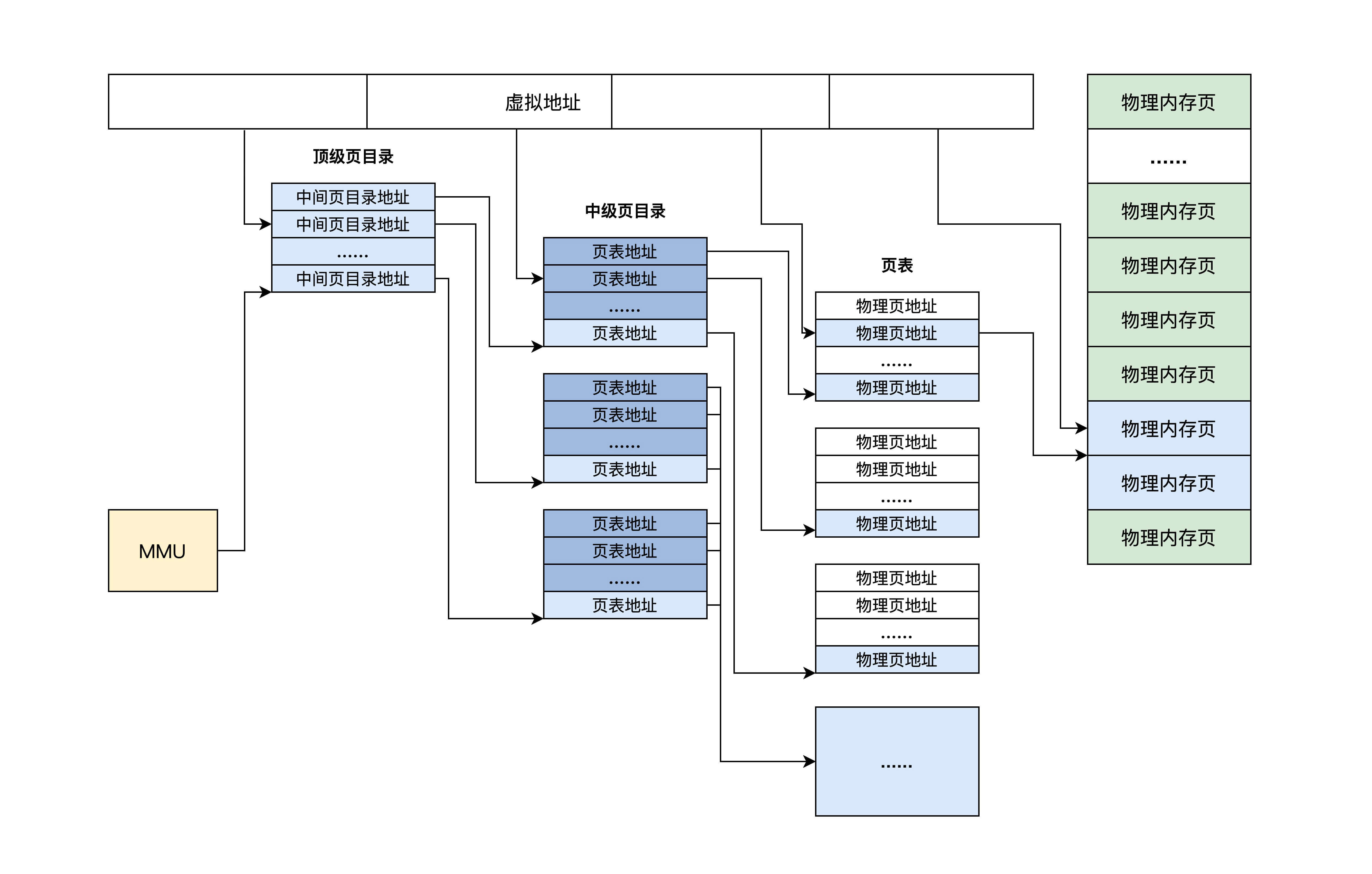
从上面可以看出,一个虚拟地址被分成从左至右四个位段
第一个位段索引顶级页目录中一个项,该项指向一个中级页目录,然后用第二个位段去索引中级页目录中的一个项,该项指向一个页目录,再用第三个位段去索引页目录中的项,该项指向一个物理页地址,最后用第四个位段作该物理页内的偏移去访问物理内存。这就是 MMU 的工作流程。
前面的内容都是理论上帮助我们了解分页模式原理的,分页模式的灵活性、通用性、安全性,是现代操作系统内存管理的基石,更是事实上的标准内存管理模型,现代商用操作系统都必须以此为基础实现虚拟内存功能模块。
因为我们的主要任务是开发操作系统,而开发操作系统就落实到真实的硬件平台上去的,下面我们就来研究 x86 CPU 上的分页模式。
首先来看看保护模式下的分页,保护模式下只有 32 位地址空间,最多 4GB-1 大小的空间。
根据前面得知 32 位虚拟地址经过分段机制之后得到线性地址,又因为通常使用平坦模式,所以线性地址和虚拟地址是相同的。
保护模式下的分页大小通常有两种,一种是 4KB 大小的页,一种是 4MB 大小的页。分页大小的不同,会导致虚拟地址位段的分隔和页目录的层级不同,但虚拟页和物理页的大小始终是等同的。
该分页方式下,32 位虚拟地址被分为三个位段:页目录索引、页表索引、页内偏移,只有一级页目录,其中包含 1024 个条目 ,每个条目指向一个页表,每个页表中有 1024 个条目。其中一个条目就指向一个物理页,每个物理页 4KB。这正好是 4GB 地址空间。如下图所示。
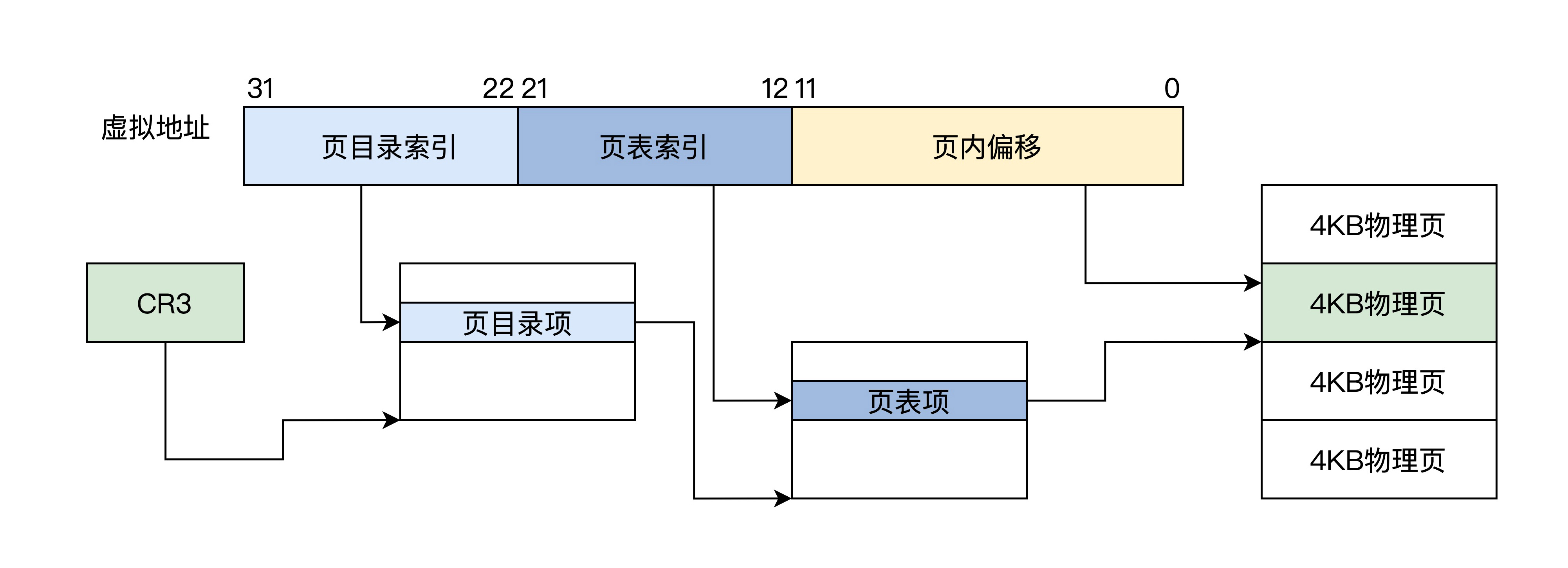
上图中 CR3 就是 CPU 的一个 32 位的寄存器,MMU 就是根据这个寄存器找到页目录的。下面,我们看看当前分页模式下的 CR3、页目录项、页表项的格式。
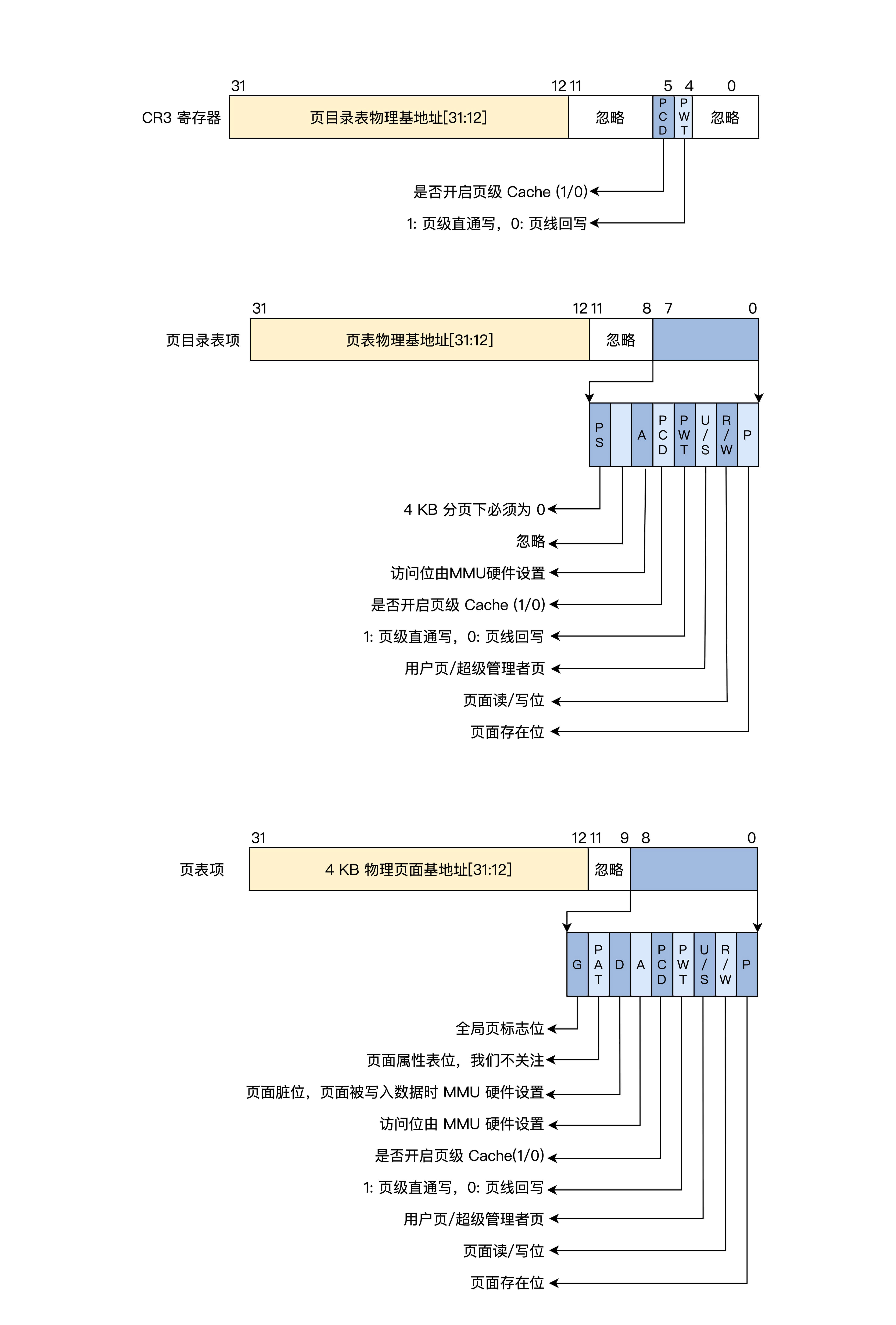
可以看到,页目录项、页表项都是 4 字节 32 位,1024 个项正好是 4KB(一个页),因此它们的地址始终是 4KB 对齐的,所以低 12 位才可以另作它用,形成了页面的相关属性,如是否存在、是否可读可写、是用户页还是内核页、是否已写入、是否已访问等
该分页方式下,32 位虚拟地址被分为两个位段:页表索引、页内偏移,只有一级页目录,其中包含 1024 个条目。其中一个条目指向一个物理页,每个物理页 4MB,正好为 4GB 地址空间,如下图所示。
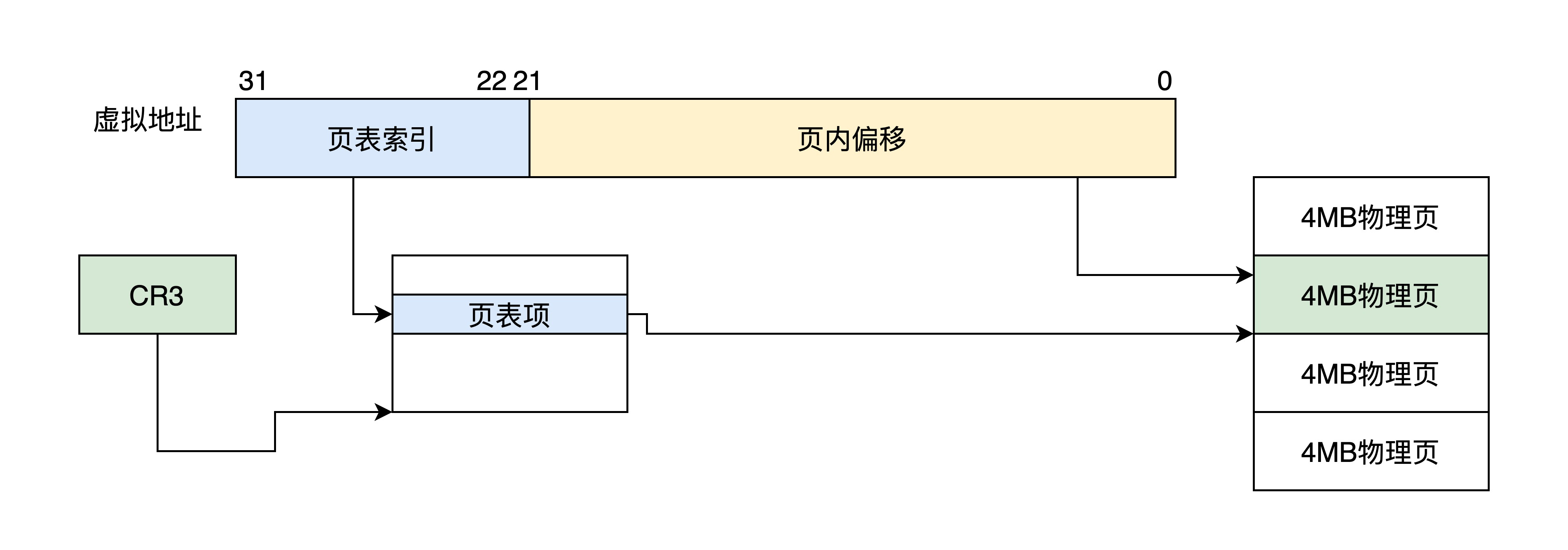
CR3 还是 32 位的寄存器,只不过不再指向顶级页目录了,而是指向一个 4KB 大小的页表,这个页表依然要 4KB 地址对齐,其中包含 1024 个页表项,格式如下图。
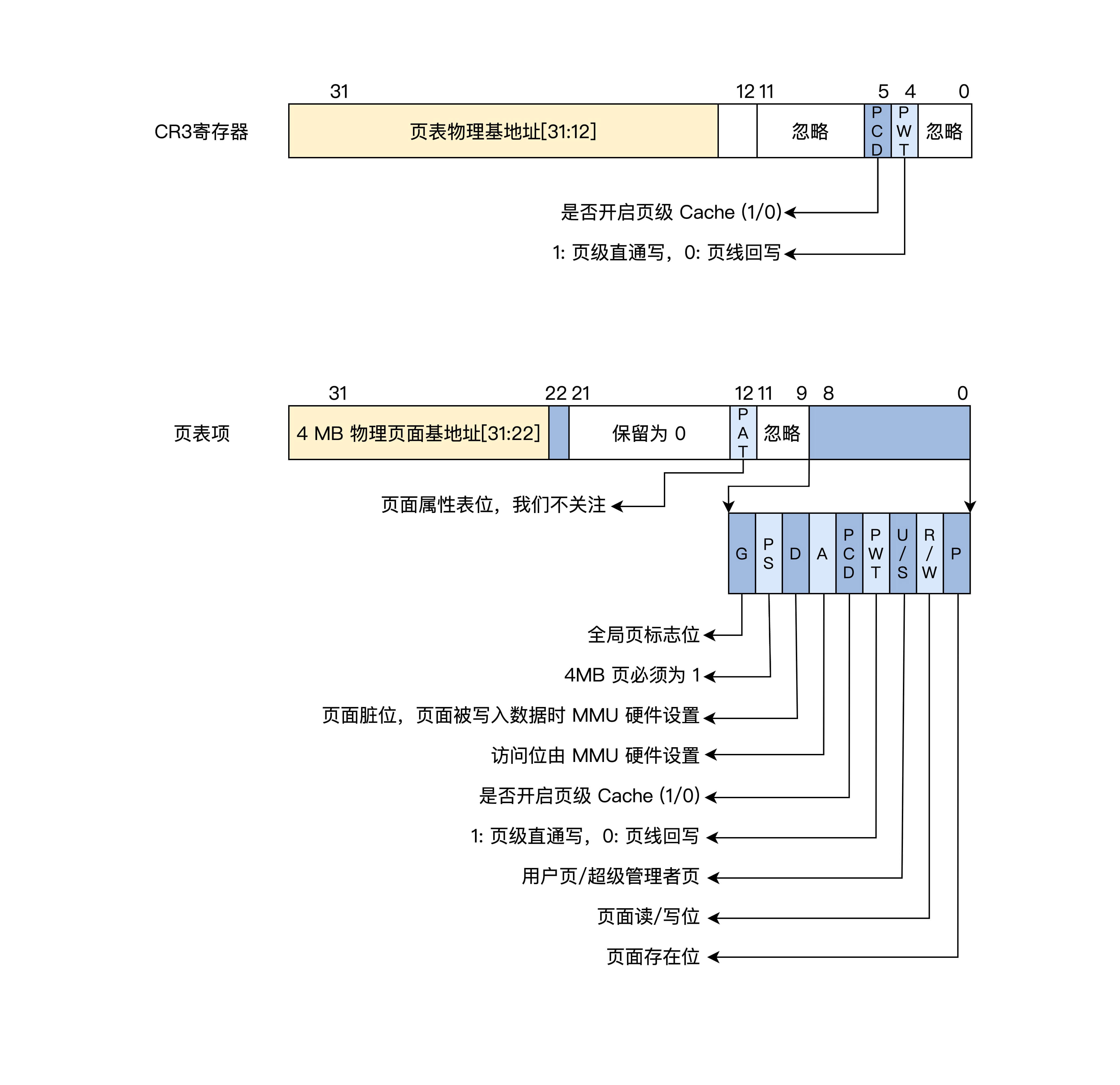
可以发现,4MB 大小的页面下,页表项还是 4 字节 32 位,但只需要用高 10 位来保存物理页面的基地址就可以。因为每个物理页面都是 4MB,所以低 22 位始终为 0,为了兼容 4MB 页表项低 8 位和 4KB 页表项一样,只不过第 7 位变成了 PS 位,且必须为 1,而 PAT 位移到了 12 位。
如果开启了长模式,则必须同时开启分页模式,因为长模式弱化了分段模型,而分段模型也确实有很多不足,不适应现在操作系统和应用软件的发展。
同时,长模式也扩展了 CPU 的位宽,使得 CPU 能使用 64 位的超大内存地址空间。所以,长模式下的虚拟地址必须等于线性地址且为 64 位。
长模式下的分页大小通常也有两种,4KB 大小的页和 2MB 大小的页。
该分页方式下,64 位虚拟地址被分为 6 个位段,分别是:保留位段,顶级页目录索引、页目录指针索引、页目录索引、页表索引、页内偏移,顶级页目录、页目录指针、页目录、页表各占有 4KB 大小,其中各有 512 个条目,每个条目 8 字节 64 位大小,如下图所示。
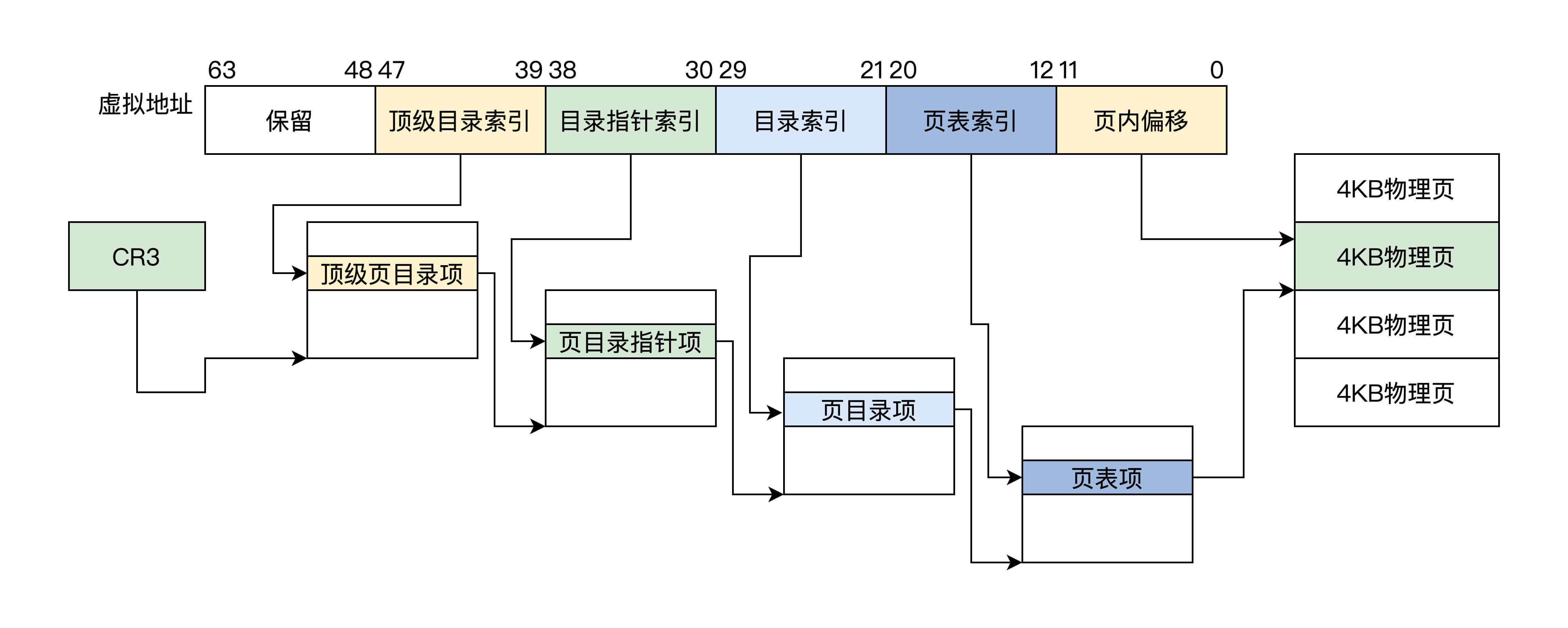
上面图中 CR3 已经变成 64 位的 CPU 的寄存器,它指向一个顶级页目录,里面的顶级页目项指向页目录指针,依次类推。
需要注意的是,虚拟地址 48 到 63 这 16 位是根据第 47 位来决定的,47 位为 1,它们就为 1,反之为 0,这是因为 x86 CPU 并没有实现全 64 位的地址总线,而是只实现了 48 位,但是 CPU 的寄存器却是 64 位的。
这种最高有效位填充的方式,即使后面扩展 CPU 的地址总线也不会有任何影响,下面我们去看看当前分页模式下的 CR3、顶级页目录项、页目录指针项、页目录项、页表项的格式,我画了一张图帮你理解。
由上图可知,长模式下的 4KB 分页下,由一个顶层目录、二级中间层目录和一层页表组成了 64 位地址翻译过程。
顶级页目录项指向页目录指针页,页目录指针项指向页目录页,页目录项指向页表页,页表项指向一个 4KB 大小的物理页,各级页目录项中和页表项中依然存在各种属性位,这在图中已经说明。其中的 XD 位,可以控制代码页面是否能够运行。
在这种分页方式下,64 位虚拟地址被分为 5 个位段 :保留位段、顶级页目录索引、页目录指针索引、页目录索引,页内偏移,顶级页目录、页目录指针、页目录各占有 4KB 大小,其中各有 512 个条目,每个条目 8 字节 64 位大小
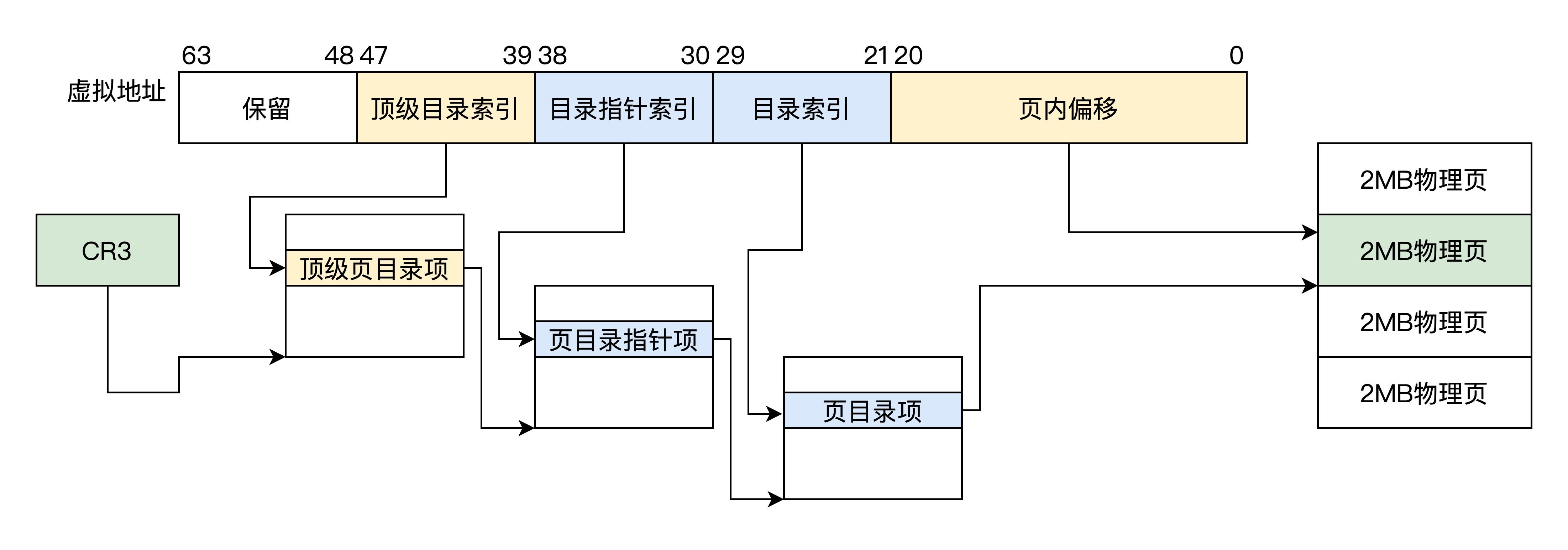
可以发现,长模式下 2MB 和 4KB 分页的区别是,2MB 分页下是页目录项直接指向了 2MB 大小的物理页面,放弃了页表项,然后把虚拟地址的低 21 位作为页内偏移,21 位正好索引 2MB 大小的地址空间。
下面我们还是要去看看 2MB 分页模式下的 CR3、顶级页目录项、页目录指针项、页目录项的格式,格式如下图
上图中没有了页表项,取而代之的是,页目录项中直接存放了 2MB 物理页基地址。由于物理页始终 2MB 对齐,所以其地址的低 21 位为 0,用于存放页面属性位。
要使用分页模式就必先开启 MMU,但是开启 MMU 的前提是 CPU 进入保护模式或者长模式,开启 CPU 这两种模式的方法,我们在前面第五节课已经讲过了,下面我们就来开启 MMU,步骤如下:
- 使 CPU 进入保护模式或者长模式。
- 准备好页表数据,这包含顶级页目录,中间层页目录,页表,假定我们已经编写了代码,在物理内存中生成了这些数据。
- 把顶级页目录的物理内存地址赋值给 CR3 寄存器。
mov eax, PAGE_TLB_BADR ;页表物理地址
mov cr3, eax- 设置 CPU 的 CR0 的 PE 位为 1,这样就开启了 MMU。
;开启 保护模式和分页模式
mov eax, cr0
bts eax, 0 ;CR0.PE =1
bts eax, 31 ;CR0.P = 1
mov cr0, eax MMU 的主要功能是根据页表数据把虚拟地址转换成物理地址,但有没有可能转换失败?
绝对有可能,例如,页表项中的数据为空,用户程序访问了超级管理者的页面,向只读页面中写入数据。
这些都会导致 MMU 地址转换失败。MMU 地址转换失败了怎么办呢?失败了既不能放行,也不是 reset,MMU 执行的操作如下。
- MMU 停止转换地址。
- MMU 把转换失败的虚拟地址写入 CPU 的 CR2 寄存器。
- MMU 触发 CPU 的 14 号中断,使 CPU 停止执行当前指令。
- CPU 开始执行 14 号中断的处理代码,代码会检查原因,处理好页表数据返回。
- CPU 中断返回继续执行 MMU 地址转换失败时的指令。
这里你只要先明白这个流程就好了,后面课程讲到内存管理的时候我们继续探讨。
又到了课程的尾声,把心情放松下来,我们一起来回顾这节课的重点。
首先,我们从一个场景开始热身,发现多道程序同时运行有很多问题,都是内存相关的问题,内存需要隔离和保护。从而提出了虚拟地址与物理地址分离,让应用程序从实际的物理内存中解耦出来。
虽然虚拟地址是个非常不错的方案,但是虚拟地址必须转换成物理地址,才能在硬件上执行。为了执行这个转换过程,才开发出了 MMU(内存管理单元),MMU增加了转换的灵活性,它的实现方式是硬件执行转换过程,但又依赖于软件提供的地址转换表。
最后,我们下落到具体的硬件平台,研究了 x86 CPU 上的 MMU。x86 CPU 上的 MMU 在其保护模式和长模式下提供 4KB、2MB、4MB 等页面转换方案,我们详细分析了它们的页表格式。同时,也搞清楚了如何开启 MMU,以及 MMU 地址转换失败后执行的操作。
在前面的课程里,我们已经知道了 CPU 是如何执行程序的,也研究了程序的地址空间,这里我们终于到了程序的存放地点——内存。
你知道什么是 Cache 吗?在你心中,真实的内存又是什么样子呢?今天我们就来重新认识一下 Cache 和内存,这对我们利用 Cache 写出高性能的程序代码和实现操作系统管理内存,有着巨大的帮助。
通过这节课的内容,我们一起来看看内存到底是啥,它有什么特性。有了这个认识,你就能更加深入地理解我们看似熟悉的局部性原理,从而搞清楚,为啥 Cache 是解决内存瓶颈的神来之笔。最后,我还会带你分析 x86 平台上的 Cache,规避 Cache 引发的一致性问题,并让你掌握获取内存视图的方法。
#include <stdio.h>
int main() {
int, i, j;
for(i = 1; i <= 9;i++) {
for(j = 1;j <= i;j++) {
printf("%d*%d=%2d ", i, j, i*j);
}
printf("\n");
}
return 0;
}我们当然不是为了研究代码本身,这个代码非常简单,这里我们主要是观察这个结构,代码的结构主要是顺序、分支、循环,这三种结构可以写出现存所有算法的程序。
我们常规情况下写的代码是顺序和循环结构居多。上面的代码中有两重循环,内层循环的次数受到外层循环变量的影响。就是这么简单,但是越简单的东西越容易看到本质。
可以看到,这个代码大数时间在执行一个乘法计算和调用一个 printf 函数,而程序一旦编译装载进内存中,它的地址就确定了。也就是说,CPU 大多数时间在访问相同或者与此相邻的地址,换句话说就是:CPU 大多数时间在执行相同的指令或者与此相邻的指令。这就是大名鼎鼎的程序局部性原理。
明白了程序的局部性原理之后,我们再来看看内存。你或许感觉这跨越有点大,但是只有明白了内存的结构和特性,你才能明白程序局部性原理的应用场景和它的重要性。
内存也可称为主存,不管硬盘多大、里面存放了多少程序和数据,只要程序运行或者数据要进行计算处理,就必须先将它们装入内存。我们先来看看内存长什么样(你也可以上网自行搜索),如下图所示。

从上图可以看到在 PCB 板上有内存颗粒芯片,主要是用来存放数据的。SPD 芯片用于存放内存自身的容量、频率、厂商等信息。还有最显眼的金手指,用于连接数据总线和地址总线,电源等。
其实从专业角度讲,内存应该叫 DRAM,即动态随机存储器。内存储存颗粒芯片中的存储单元是由电容和相关元件做成的,电容存储电荷的多、少代表数字信号 0 和 1。
而随着时间的流逝,电容存在漏电现象,这导致电荷不足,就会让存储单元的数据出错,所以 DRAM 需要周期性刷新,以保持电荷状态。DRAM 结构较简单且集成度很高,通常用于制造内存条中的储存颗粒芯片。
虽然内存技术标准不断更新,但是储存颗粒的内部结构没有本质改变,还是电容存放电荷,标准看似更多,实际上只是提升了位宽、工作频率,以及传输时预取的数据位数。
比如 DDR SDRAM,即双倍速率同步动态随机存储器,它使用 2.5V 的工作电压,数据位宽为 64 位,核心频率最高为 166MHz。下面简称 DDR 内存,它表示每一个时钟脉冲传输两次数据,分别在时钟脉冲的上升沿和下降沿各传输一次数据,因此称为双倍速率的 SDRAM。
后来的 DDR2、DDR3、DDR4 也都在核心频率和预取位数上做了提升。最新的 DDR4 采用 1.2V 工作电压,数据位宽为 64 位,预取 16 位数据。DDR4 取消了双通道机制,一条内存即为一条通道,工作频率最高可达 4266MHz,单根 DDR4 内存的数据传输带宽最高为 34GB/s
其实我们无需过多关注内存硬件层面的技术规格标准,重点需要关注的是,内存的速度还有逻辑上内存和系统的连接方式和结构,这样你就能意识到内存有多慢,还有是什么原因导致内存慢的。
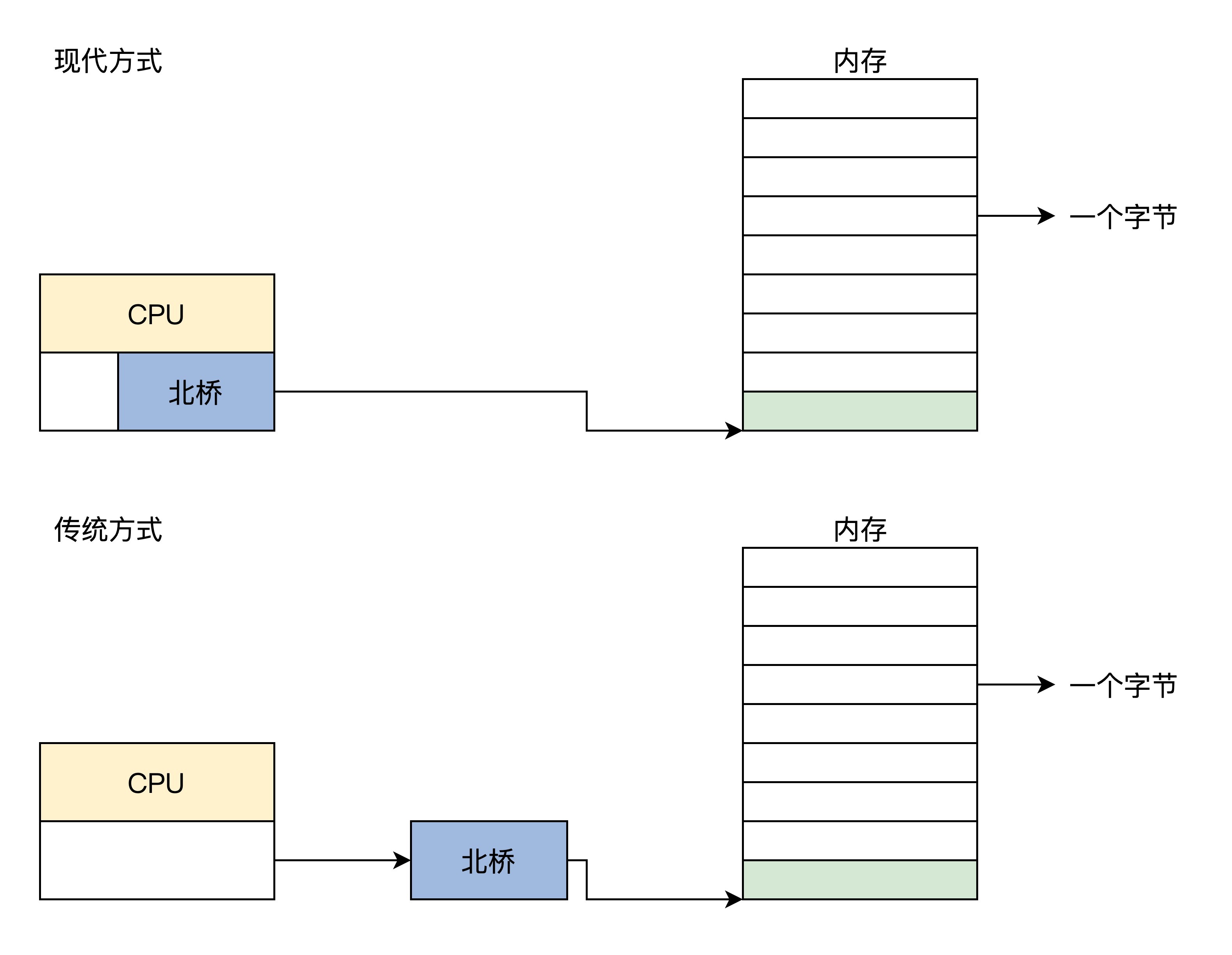
结合图片我们看到,控制内存刷新和内存读写的是内存控制器,而内存控制器集成在北桥芯片中。传统方式下,北桥芯片存在于系统主板上,而现在由于芯片制造工艺的升级,芯片集成度越来越高,所以北桥芯片被就集成到 CPU 芯片中了,同时这也大大提升了 CPU 访问内存的性能。
而作为软件开发人员,从逻辑上我们只需要把内存看成一个巨大的字节数组就可以,而内存地址就是这个数组的下标。
尽管 CPU 和内存是同时代发展的,但 CPU 所使用技术工艺的材料和内存是不同的,侧重点也不同,价格也不同。如果内存使用 CPU 的工艺和材料制造,那内存条的昂贵程度会超乎想象,没有多少人能买得起。
由于这些不同,导致了 CPU 和内存条的数据吞吐量天差地别。尽管最新的 DDR4 内存条带宽高达 34GB/s,然而这相比 CPU 的数据吞吐量要慢上几个数量级。再加上多核心 CPU 同时访问内存,会导致总线争用问题,数据吞吐量会进一步下降。
CPU 要数据,内存一时给不了怎么办?CPU 就得等,通常 CPU 会让总线插入等待时钟周期,直到内存准备好,到这里你就会发现,无论 CPU 的性能多高都没用,而内存才是决定系统整体性能的关键。显然依靠目前的理论直接提升内存性能,达到 CPU 的同等水平,这是不可行的,得想其它的办法。