#! https://zhuanlan.zhihu.com/p/448013208
分析改动 : https://github.com/sogou/workflow/commit/a6b8a2cde33a1319c0fa731c86e8849fd108fb5b
更加详细的源码注释可看 : https://github.com/chanchann/workflow_annotation
; perl calltree.pl 'message_out' '' 1 1 2
message_out
├── Communicator::handle_connect_result [vim src/kernel/Communicator.cc +930]
├── Communicator::request_idle_conn [vim src/kernel/Communicator.cc +1460]
├── Communicator::reply_idle_conn [vim src/kernel/Communicator.cc +1596]
├── ComplexHttpTask::message_out [vim src/factory/HttpTaskImpl.cc +77]
├── ComplexHttpProxyTask::message_out [vim src/factory/HttpTaskImpl.cc +510]
├── WFHttpServerTask::message_out [vim src/factory/HttpTaskImpl.cc +859]
├── ComplexMySQLTask::message_out [vim src/factory/MySQLTaskImpl.cc +198]
├── WFMySQLServerTask::message_out [vim src/factory/MySQLTaskImpl.cc +677]
├── ComplexDnsTask::message_out [vim src/factory/DnsTaskImpl.cc +64]
├── ComplexRedisTask::message_out [vim src/factory/RedisTaskImpl.cc +79]
└── __ComplexKafkaTask::message_out [vim src/factory/KafkaTaskImpl.cc +112]
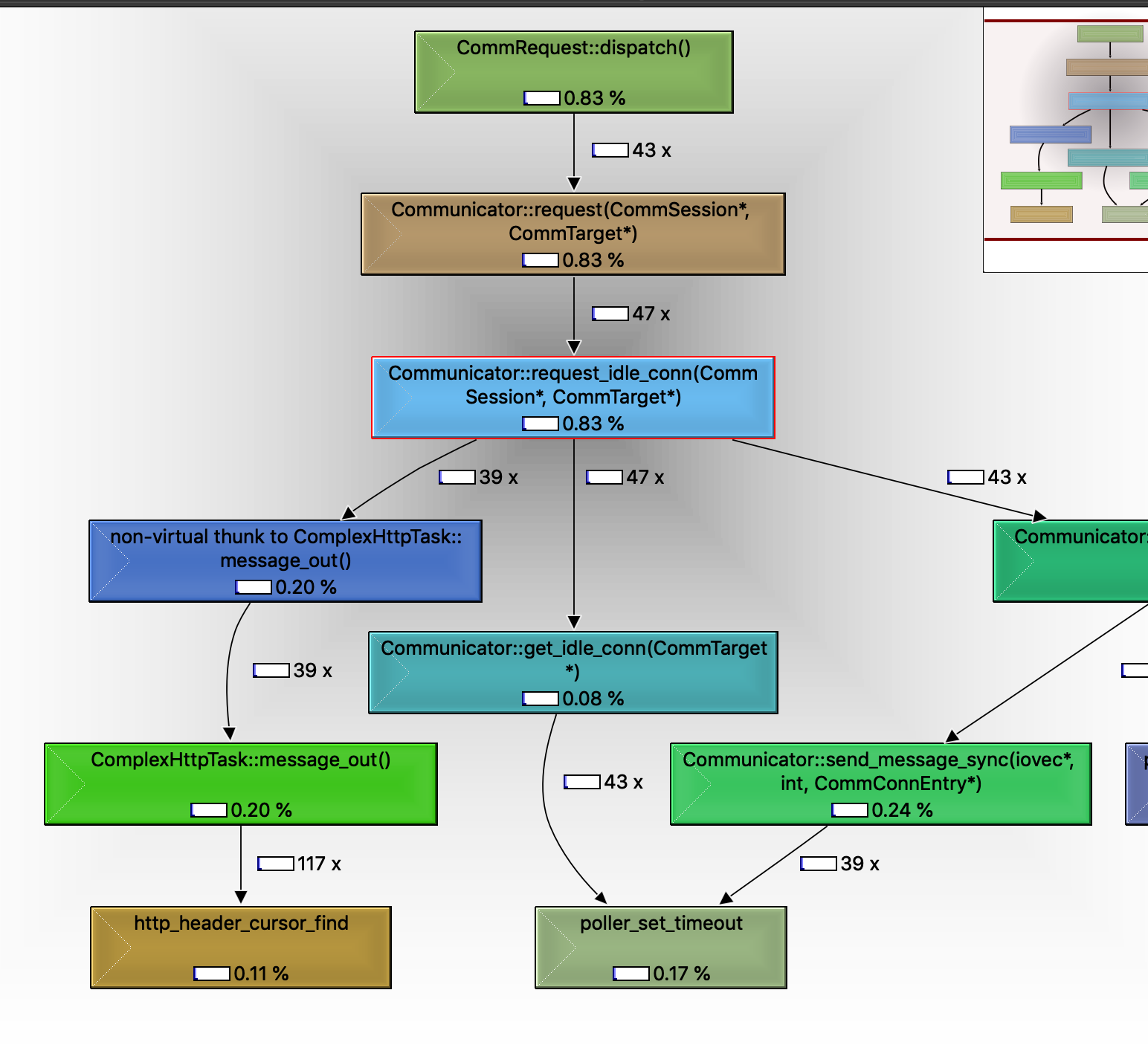
在我们简单的http request client中,我们的任务被调起,发送request(request优先复用,然后message_out发送)
旧版代码注释看此处的workflow文件message_out代码
用gdb查看
cgdb ./wget
(gdb) set args www.baidu.com
(gdb) b HttpTaskImpl.cc:ComplexHttpTask::message_out
分析代码可以看到,这里一共用了4次find header,分别是"Transfer-Encoding","Content-Length", "Connection","Keep-Alive",伴随了三次cursor的rewind
// 新版代码
CommMessageOut *ComplexHttpTask::message_out()
{
HttpRequest *req = this->get_req();
struct HttpMessageHeader header;
bool is_alive;
// 如果不为chunked 且req没有content_length 的 header
if (!req->is_chunked() && !req->has_content_length_header())
{
size_t body_size = req->get_output_body_size();
const char *method = req->get_method();
if (body_size != 0 || strcmp(method, "POST") == 0 ||
strcmp(method, "PUT") == 0)
{
// 同理,不为chunked的话,那我们给他添加上 "Content-Length" 这个header
char buf[32];
header.name = "Content-Length";
header.name_len = strlen("Content-Length");
header.value = buf;
header.value_len = sprintf(buf, "%zu", body_size);
req->add_header(&header);
}
}
// 如果req有connection_header
if (req->has_connection_header())
// 查看是否is_keep_alive
is_alive = req->is_keep_alive();
else
{
// 如果没有,我们帮用户添加
header.name = "Connection";
header.name_len = strlen("Connection");
is_alive = (this->keep_alive_timeo != 0); // 如果是time_out不为0,则是Keep-Alive
if (is_alive)
{
header.value = "Keep-Alive";
header.value_len = strlen("Keep-Alive");
}
else
{
header.value = "close";
header.value_len = strlen("close");
}
req->add_header(&header);
}
if (!is_alive)
this->keep_alive_timeo = 0;
else if (req->has_keep_alive_header())
{
// 这里因为不是简单的有没有的信息,而是要把这个字段取出切割,还是得用一次find
HttpHeaderCursor req_cursor(req);
//req---Connection: Keep-Alive
//req---Keep-Alive: timeout=0,max=100
header.name = "Keep-Alive";
header.name_len = strlen("Keep-Alive");
if (req_cursor.find(&header))
{
std::string keep_alive((const char *)header.value, header.value_len);
std::vector<std::string> params = StringUtil::split(keep_alive, ',');
for (const auto& kv : params)
{
std::vector<std::string> arr = StringUtil::split(kv, '=');
if (arr.size() < 2)
arr.emplace_back("0");
std::string key = StringUtil::strip(arr[0]);
std::string val = StringUtil::strip(arr[1]);
if (strcasecmp(key.c_str(), "timeout") == 0)
{
this->keep_alive_timeo = 1000 * atoi(val.c_str());
break;
}
}
}
if ((unsigned int)this->keep_alive_timeo > HTTP_KEEPALIVE_MAX)
this->keep_alive_timeo = HTTP_KEEPALIVE_MAX;
//if (this->keep_alive_timeo < 0 || this->keep_alive_timeo > HTTP_KEEPALIVE_MAX)
}
//req->set_header_pair("Accept", "*/*");
return this->WFComplexClientTask::message_out();
}
归根到底,之前的旧代码中,没有利用好http_parser中的一些记录信息, 比如说是否是chunked,是否有content_length_header等等,而是反复的rewind去find这些字段。
所以由之前的4次find+3次rewind ---> 变成了一次find,效率自然就增加了
typedef struct __http_parser
{
int header_state;
int chunk_state;
size_t header_offset;
size_t chunk_offset;
size_t content_length;
size_t transfer_length;
char *version;
char *method;
char *uri;
char *code;
char *phrase;
struct list_head header_list;
char namebuf[HTTP_HEADER_NAME_MAX];
void *msgbuf;
size_t msgsize;
size_t bufsize;
char has_connection;
char has_content_length;
char has_keep_alive;
char expect_continue;
char keep_alive;
char chunked;
char complete;
char is_resp;
} http_parser_t;