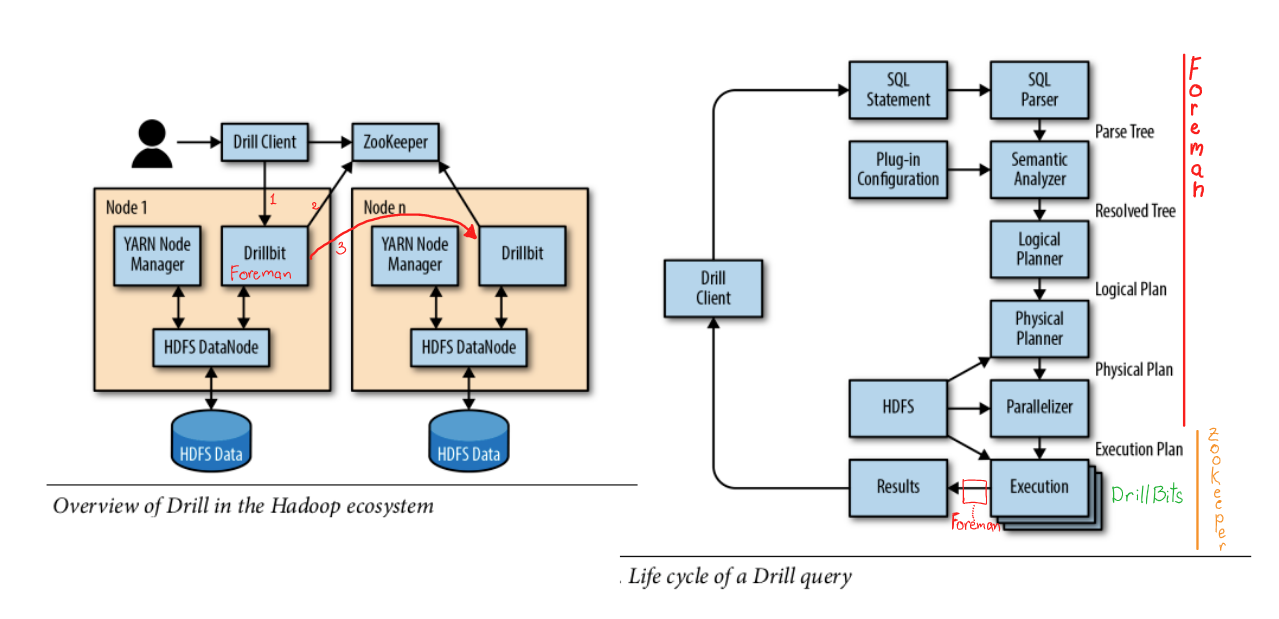
- Drill client ( connects to a Foreman, submits SQL statements, and receives results )
- Foreman ( DrillBit server selected to maintain your session )
- worker Drillbit servers ( do the actual work of running your query )
- ZooKeeper server ( which coordinates the Drillbits within the Drill cluster and keep configuration )
necessary to register of all Drillbit servers
- Parse the SQL statement into an internal parse tree ( Apache Calcite )
check sql query
- Perform semantic analysis on the parse tree by resolving names the selected data‐ base, against the schema (set of tables) in that database ( Apache Calcite )
check "database/table" names ( not columns, not columns types, schema-on-read system !!! )
- Convert the SQL parse tree into a logical plan, which can be thought of as a block diagram of the major operations needed to perform the given query. ( Apache Calcite )
- Convert the logical plan into a physical plan by performing a cost-based optimi‐ zation step that looks for the most efficient way to execute the logical plan.
Drill Web Console -> QueryProfile
- Convert the physical plan into an execution plan by determining how to distrib‐ ute work across the available worker Drillbits.
- Distribution
Major fragment - set of operators that can be done without exchange between DrillBits and grouped into a thread Minor fragment - slice of Major Fragment ( for instance reading one file from folder ), distribution unit Data affinity - place minor fragment to the same node where is data placed ( HDFS/MapR, where compute and storage are separate, like cloud - randomly )
- Collect all results (Minor fragments) on Foreman, provide results to client
# install drill
## https://drill.apache.org/download/
mkdir /home/projects/drill
cd /home/projects/drill
curl -L 'https://www.apache.org/dyn/closer.lua?filename=drill/drill-1.19.0/apache-drill-1.19.0.tar.gz&action=download' | tar -vxzf -
or
sudo apt-get install default-jdk
curl -o apache-drill-1.6.0.tar.gz http://apache.mesi.com.ar/drill/drill-1.6.0/apache-drill-1.6.0.tar.gz
tar xvfz apache-drill-1.6.0.tar.gz
cd apache-drill-1.6.0
# start drill locally
cd /home/projects/drill
# apache-drill-1.19.0/bin/sqlline -u jdbc:drill:zk=local
./apache-drill-1.19.0/bin/drill-embeddeddocker run -it --name drill-1.19.0 -p 8047:8047 -v /home/projects/temp/drill/conf:/opt/drill/conf --detach apache/drill:1.19.0 /bin/bash
# docker ps -a | awk '{print $1}' | xargs docker rm {}
x-www-browser http://localhost:8047
(skip for embedded ) create /home/projects/temp/drill-override.conf
drill.exec: {
cluster-id: "drillbits1",
zk.connect: "localhost:2181"
} "type": "file",
"connection": "file:///",
"workspaces": {
"json_files": {
"location": "/home/projects/dataset/test01",
"writable": false,
"defaultInputFormat": "json",
"allowAccessOutsideWorkspace": false
},
"tmp": {
"location": "/tmp",
"writable": true,
"defaultInputFormat": null,
"allowAccessOutsideWorkspace": false
},
"root": {
"location": "/",
"writable": false,
"defaultInputFormat": null,
"allowAccessOutsideWorkspace": false
}
},#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This file involves storage plugins configs, which can be updated on the Drill start-up.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md for more information.
"storage": {
dfs: {
type: "file",
connection: "file:///",
workspaces: {
"wondersign": {
"location": "/home/projects/wondersign",
"writable": false,
"defaultInputFormat": "json",
"allowAccessOutsideWorkspace": false
},
},
formats: {
"parquet": {
"type": "parquet"
},
"json": {
"type": "json"
extensions: [""],
}
},
enabled: true
}
}
SELECT filepath, filename, sku FROM dfs.json_files.`/*` where sku is not null;http://drill.apache.org/docs/s3-storage-plugin/ vim apache-drill-1.19.0/conf/core-site.xml
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>AKIA6L...</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>nqGApjHh....</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>us-east-1</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>s3.REGION.amazonaws.com</value>
</property>
</configuration> plugin configuration: https://drill.apache.org/docs/s3-storage-plugin/
http://localhost:8047/storage > s3 > Update (check below) > Enable
"connection": "s3a://bucket_name",
"config": {
"fs.s3a.secret.key": "nqGApjHh2i...",
"fs.s3a.access.key": "AKIA6LWYA...",
"fs.s3a.endpoint": "us-east-1"
},should appear in "Enabled Storage Plugins"
- activate dfs
- configure dfs
workspaces-> root -> location
> enter full path to filesystem
# login
maprlogin password
echo $CLUSTER_PASSWORD | maprlogin password -user $CLUSTER_USER
export MAPR_TICKETFILE_LOCATION=$(maprlogin print | grep "keyfile" | awk '{print $3}')
# open drill
/opt/mapr/drill/drill-1.14.0/bin/sqlline -u "jdbc:drill:drillbit=ubs000103.vantagedp.com:31010;auth=MAPRSASL"# start recording console to file, write output
!record out.txt
# stop recording
record-- execute it first
show databases; -- show schemas;
--------------------------------------------
select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/0171eabfceff/reprocessable/part-00000-63dbcc0d1bed-c000.snappy.parquet`;
-- or even
select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/*/*/part-00000-63dbcc0d1bed-c000.snappy.parquet`;
-- with functions
to_char(to_timestamp(my_column), 'yyyy-MM-dd HH:mm:ss')
to_number(concat('0', mycolumn),'#')
-- local filesystem
SELECT filepath, filename, sku FROM dfs.`/home/projects/dataset/kaggle-data-01` where sku is not null;
SELECT filepath, filename, sku FROM dfs.root.`/kaggle-data-01` where sku is not null
SELECT filepath, filename, t.version, t.car_info.boardnet_version catinfo FROM dfs.root.`/file_infos` t;
SELECT t.row_data.start_time start_time, t.row_data.end_time end_time FROM ( SELECT flatten(file_info) AS row_data from dfs.root.`/file_infos/765f3c13-6c57-4400-acee-0177ca43610b/Metadata/file_info.json` ) AS t;
-- local file system complex query with inner!!! join
SELECT hvl.startTime, hvl.endTime, hvl.labelValueDouble, hvl2.labelValueDouble
FROM dfs.`/vantage/data/store/95933/acfb-01747cefa4a9/single_labels/host_vehicle_latitude` hvl INNER JOIN dfs.`/vantage/data/store/95933/acfb-01747cefa4a9/single_labels/host_vehicle_longitude` hvl2
ON hvl.startTime = hvl2.startTime
WHERE hvl.startTime >= 1599823156000000000 AND hvl.startTime <= 1599824357080000000!!! important: you should avoid colon ':' symbol in path ( explicitly or implicitly with asterix )
# check status
curl --insecure -X GET https://mapr-web.vantage.zur:21103/status
# obtain cookie from server
curl -H "Content-Type: application/x-www-form-urlencoded" \
-k -c cookies.txt -s \
-d "j_username=$DRILL_USER" \
--data-urlencode "j_password=$DRILL_PASS" \
https://mapr-web.vantage.zur:21103/j_security_check
# obtain version
curl -k -b cookies.txt -X POST \
-H "Content-Type: application/json" \
-w "response-code: %{http_code}\n" \
-d '{"queryType":"SQL", "query": "select * from sys.version"}' \
https://mapr-web.vantage.zur:21103/query.json
# SQL request
curl -k -b cookies.txt -X POST \
-H "Content-Type: application/json" \
-w "response-code: %{http_code}\n" \
-d '{"queryType":"SQL", "query": "select loggerTimestamp, key, `value` from dfs.`/mapr/dp.zurich/some-file-on-cluster` limit 10"}' \
https://mapr-web.vantage.zur:21103/query.json!set outputformat 'csv'
!record '/user/user01/query_output.csv'
show databases
!record
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222/jre/bin/java \
-Ddrill.customAuthFactories=org.apache.drill.exec.rpc.security.maprsasl.MapRSaslFactory \
-Djava.security.auth.login.config=/opt/mapr/conf/mapr.login.conf \
-Dzookeeper.sasl.client=false \
-Dlog.path=/opt/mapr/drill/drill-1.14.0/logs/sqlline.log \
-Dlog.query.path=/opt/mapr/drill/drill-1.14.0/logs/sqlline_queries/data_api-s_sqlline_queries.json \
-cp /opt/mapr/drill/drill-1.14.0/conf:/opt/mapr/drill/drill-1.14.0/jars/*:/opt/mapr/drill/drill-1.14.0/jars/ext/*:/opt/mapr/drill/drill-1.14.0/jars/3rdparty/*:/opt/mapr/drill/drill-1.14.0/jars/classb/*:/opt/mapr/drill/drill-1.14.0/jars/3rdparty/linux/*:drill_jdbc-1.0-SNAPSHOT.jar \
DrillCollaborationCaused by: java.lang.IllegalStateException: No active Drillbit endpoint found from ZooKeeper. Check connection parameters?
[MapR][DrillJDBCDriver](500150) Error setting/closing connection:
# check your Zookeeper host & cluster ID
ZOOKEEPER_HOST=zurpmtjp03.ddp.com:5181,zurpmtjp04.ddp.com:5181
DRILL_CLUSTER_ID=dp_staging_zur-drillbits
/opt/mapr/drill/drill-1.16.0/bin/sqlline -u "jdbc:drill:zk=${ZOOKEEPER_HOST}/drill/${CLUSTER_ID};auth=MAPRSASL"increasing amount of parallel processing threads
set planner.width.max_per_node=10;show errors in log
ALTER SESSION SET `exec.errors.verbose`=true;select columns[0], columns[1] from s3.`sample.csv`