

A C++ Implementation of YoloV8 using TensorRT
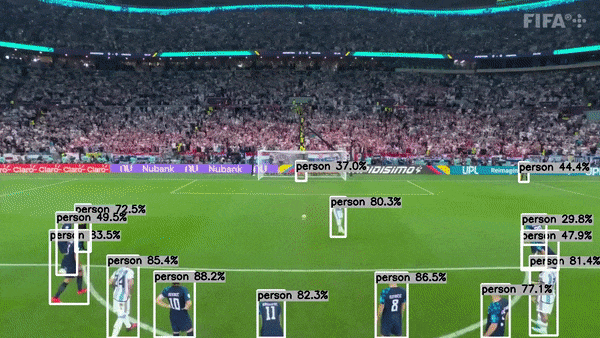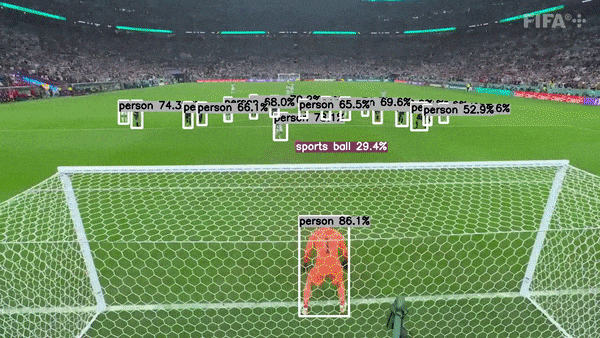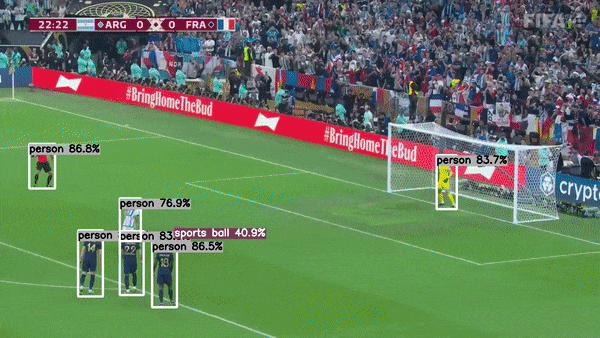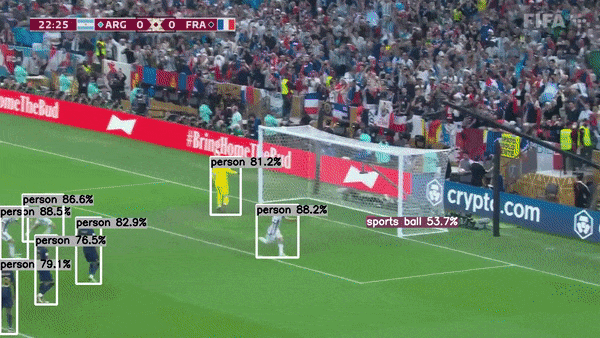

This project demonstrates how to use the TensorRT C++ API to run GPU inference for YoloV8. It makes use of my other project tensorrt-cpp-api to run inference behind the scene, so make sure you are familiar with that project.
New: Now supports YoloV8 Semantic Segmentation models.
- Tested and working on Ubuntu 20.04
- Install CUDA, instructions here.
- Recommended >= 11.8
- Install cudnn, instructions here.
- Recommended >= 8
sudo apt install build-essentialsudo apt install python3-pippip3 install cmake- Install OpenCV with cuda support. To compile OpenCV from source, run the
build_opencv.shscript provided in./scripts/- Recommended >= 4.8
- Download TensorRT 8 from here.
- Recommended >= 8.6
- Required >= 8.0
- Extract, and then navigate to the
CMakeLists.txtfile and replace theTODOwith the path to your TensorRT installation.
git clone https://github.com/cyrusbehr/YOLOv8-TensorRT-CPP --recursive- Note: Be sure to use the
--recursiveflag as this repo makes use of git submodules.
- Navigate to the official YoloV8 repository and download your desired version of the model (ex. YOLOv8m).
- The code also supports semantic segmentation models out of the box (ex. YOLOv8x-seg)
pip3 install ultralytics- Navigate to the
scripts/directory and modify this line so that it points to your downloaded model:model = YOLO("../models/yolov8m.pt"). python3 pytorch2onnx.py- After running this command, you should successfully have converted from PyTorch to ONNX.
mkdir buildcd buildcmake ..make -j
- Note: the first time you run any of the scripts, it may take quite a long time (5 mins+) as TensorRT must generate an optimized TensorRT engine file from the onnx model. This is then saved to disk and loaded on subsequent runs.
- To run the benchmarking script, run:
./benchmark /path/to/your/onnx/model.onnx - To run inference on an image and save the annotated image to disk run:
./detect_object_image /path/to/your/onnx/model.onnx /path/to/your/image.jpg- You can use the images in the
images/directory for testing
- You can use the images in the
- To run inference using your webcam and display the results in real time, run:
./detect_object_video /path/to/your/onnx/model.onnx- To change the video source, navigate to
src/object_detection_video_streaming.cppand change this line to your specific video source:cap.open(0);. - The video source can be an int or a string (ex. "/dev/video4" or an RTSP url).
- To change the video source, navigate to
- If you have issues creating the TensorRT engine file from the onnx model, navigate to
libs/tensorrt-cpp-api/src/engine.cppand change the log level by changing the severity level tokVERBOSEand rebuild and rerun. This should give you more information on where exactly the build process is failing.
If this project was helpful to you, I would appreicate if you could give it a star. That will encourage me to ensure it's up to date and solve issues quickly.