- MapR
- Hortonworks
- Cloudera
docker run --hostname=quickstart.cloudera --privileged=true -t -i -p 7180 4239cd2958c6 /usr/bin/docker-quickstart
docker run -it --name bdu_spark2 -P -p 4040:4040 -p 4041:4041 -p 8080:8080 -p8081:8081 bigdatauniversity/spark2:latest
-- /etc/bootstrap.sh -bash



hdfs dfsadmin -report
hdfs getconf -namenodes
hdfs getconf -secondaryNameNodes
hdfs getconf -confKey dfs.namenode.name.dir
confKey:
- dfs.namenode.name.dir
- fs.defaultFS
- yarn.resourcemanager.address
- mapreduce.framework.name
- dfs.namenode.name.dir
- dfs.default.chunk.view.size
- dfs.namenode.fs-limits.max-blocks-per-file
- dfs.permissions.enabled
- dfs.namenode.acls.enabled
- dfs.replication
- dfs.replication.max
- dfs.namenode.replication.min
- dfs.blocksize
- dfs.client.block.write.retries
- dfs.hosts.exclude
- dfs.namenode.checkpoint.edits.dir
- dfs.image.compress
- dfs.image.compression.codec
- dfs.user.home.dir.prefix
- dfs.permissions.enabled
- io.file.buffer.size
- io.bytes-per-checksum
- io.seqfile.local.dir
hdfs dfs -help
hdfs dfs -help copyFromLocal
hdfs dfs -help ls
hdfs dfs -help cat
hdfs dfs -help setrep
hdfs dfs -ls /user/root/input
hdfs dfs -ls hdfs://hadoop-local:9000/data
output example:
-rw-r--r-- 1 root supergroup 5107 2017-10-27 12:57 hdfs://hadoop-local:9000/data/Iris.csv
^ factor of replication
hdfs dfs -count /user/root/input
where 1-st column - amount of folder ( +1 current ), where 2-nd column - amount of files into folder where 3-rd column - size of folder
hdfs dfs -test -d /user/root/some_folder
echo $?
0 - exists 1 - not exits
hdfs dfs -checksum <path to file>
java -jar HadoopChecksumForLocalfile-1.0.jar V717777_MDF4_20190201.MF4 0 512 CRC32C
locally only
hdfs dfs -cat <path to file> | md5sum
hadoop jar /opt/cloudera/parcels/CDH/jars/search-mr-1.0.0-cdh5.14.4-job.jar org.apache.solr.hadoop.HdfsFindTool -find hdfs:///data/ingest/ -type d -name "some-name-of-the-directory"
hadoop jar /opt/cloudera/parcels/CDH/jars/search-mr-1.0.0-cdh5.14.4-job.jar org.apache.solr.hadoop.HdfsFindTool -find hdfs:///data/ingest/ -type f -name "some-name-of-the-file"
hdfs dfs -setrep -w 4 /data/file.txt
hdfs dfs -mkdir /data
hdfs dfs -put /home/root/tmp/Iris.csv /data/
hdfs dfs -copyFromLocal /home/root/tmp/Iris.csv /data/
hdfs dfs -Ddfs.replication=2 -put /path/to/local/file /path/to/hdfs
copy ( small files only !!! ) from local to remote ( read from DataNodes and write to DataNodes !!!)
hdfs dfs -cp /home/root/tmp/Iris.csv /data/
hadoop distcp /home/root/tmp/Iris.csv /data/
hdfs get /path/to/hdfs /path/to/local/file
hdfs dfs -copyToLocal /path/to/hdfs /path/to/local/file
hdfs rm -r /path/to/hdfs-folder
hdfs rm -r -skipTrash /path/to/hdfs-folder
hdfs dfs -expunge
hdfs dfs -du -h /path/to/hdfs-folder
hdfs dfs -test /path/to/hdfs-folder
hdfs dfs -ls /
hdfs dfs -ls hdfs://192.168.1.10:8020/path/to/folder
the same as previous but with fs.defalut.name = hdfs://192.168.1.10:8020
hdfs dfs -ls /path/to/folder
hdfs dfs -ls file:///local/path == (ls /local/path)
show all sub-folders
hdfs dfs -ls -r
-touchz, -cat (-text), -tail, -mkdir, -chmod, -chown, -count ....
hadoop classpath
hadoop classpath glob
# javac -classpath `hadoop classpath` MyProducer.java
hdfs dfs -df -h
hdfs fsck /
hdfs balancer
hdfs dfsadmin -help
show statistic
hdfs dfsadmin -report
HDFS to "read-only" mode for external users
hdfs dfsadmin -safemode
hdfs dfsadmin -upgrade
hdfs dfsadmin -backup
- File permissions ( posix attributes )
- Hive ( grant revoke )
- Knox ( REST API for hadoop )
- Ranger
hadoop jar {path to jar} {classname}
jarn jar {path to jar} {classname}
yarn application --list
yarn application -list -appStates ALL
yarn application -status application_1555573258694_20981
yarn application -kill application_1540813402987_3657
yarn logs -applicationId application_1540813402987_3657 | less
tutorials ecosystem sandbox tutorial download install instruction getting started
localhost:4200
root/hadoop
ssh root@localhost -p 2222
- shell web client (aka shell-in-a-box): localhost:4200 root / hadoop
- ambari-admin-password-reset
- ambari-agent restart
- login into ambari: localhost:8080 admin/{your password}
http://localhost:9995 user: maria_dev pass: maria_dev
https://hortonworks.com/hadoop-tutorial/using-ipython-notebook-with-apache-spark/
PARK_MAJOR_VERSION is set to 2, using Spark2
Error in pyspark startup:
IPYTHON and IPYTHON_OPTS are removed in Spark 2.0+. Remove these from the environment and set PYSPARK_DRIVER_PYTHON and PYSPARK_DRIVER_PYTHON_OPTS instead.
just set variable to using Spart1 inside script: SPARK_MAJOR_VERSION=1
Import destinations:
- text files
- binary files
- HBase
- Hive
sqoop import --connect jdbc:mysql://127.0.0.1/crm --username myuser --password mypassword --table customers --target-dir /crm/users/michael.csv
additional parameter to leverage amount of mappers that working in parallel:
--split-by customer_id_pk
additional parameters:
--fields-terminated-by ','
--columns "name, age, address"
--where "age>30"
--query "select name, age, address from customers where age>30"
additional import parameters:
--as-textfile
--as-sequencefile
--as-avrodatafile
export modes:
- insert
sqoop export --connect jdbc:mysql://127.0.0.1/crm --username myuser --password mypassword --export-dir /crm/users/michael.csv --table customers
- update
sqoop export --connect jdbc:mysql://127.0.0.1/crm --username myuser --password mypassword --export-dir /crm/users/michael.csv --udpate_key user_id
- call ( store procedure will be executed )
sqoop export --connect jdbc:mysql://127.0.0.1/crm --username myuser --password mypassword --export-dir /crm/users/michael.csv --call customer_load
additional export parameters:
# row for a single insert
-Dsqoop.export.records.per.statement
# number of insert before commit
-Dexport.statements.per.transaction
mapr classpath
mapr classpath glob
javac -classpath `mapr classpath` MyProducer.java
java -classpath `mapr classpath`:. MyProducer
header = mdfreader.mdfinfo4.Info4("file.MF4")
header.keys()
header['AT'].keys()
header['AT'][768]['at_embedded_data']info=mdfreader.mdfinfo()
info.listChannels("file.MF4")from asammdf import MDF4 as MDF
mdf = MDF("file.MF4")hcat -e "describe school_explorer"
hcat -e "describe formatted school_explorer"
- Impala
- Phoenix ( HBase )
- Drill ( schema-less sql )
- BigSQL ( PostgreSQL + Hadoop )
- Spark
workflow scheduler
START -> ACTION -> OK | ERROR
TBD
TBD
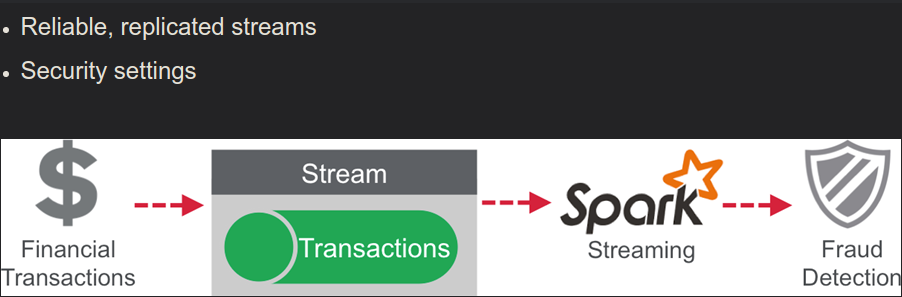
- Storm ( real time streaming solution )
- Spark ( near real time streaming, uses microbatching )
- Samza ( streaming on top of Kafka )
- Flink ( common approach to batch and stream code development )
TBD
TBD
- cloudera manager
download all slides from stepik - for repeating and creating xournals