pip install supervenn
Python 2.7 or 3.6+, numpy,matplotlib
The main entry point is the eponymous supervenn function, that takes a list of python sets as its first and only
required argument:
from supervenn import supervenn
sets = [{1, 2, 3, 4}, {3, 4, 5}, {1, 6, 7, 8}]
supervenn(sets, side_plots=False)
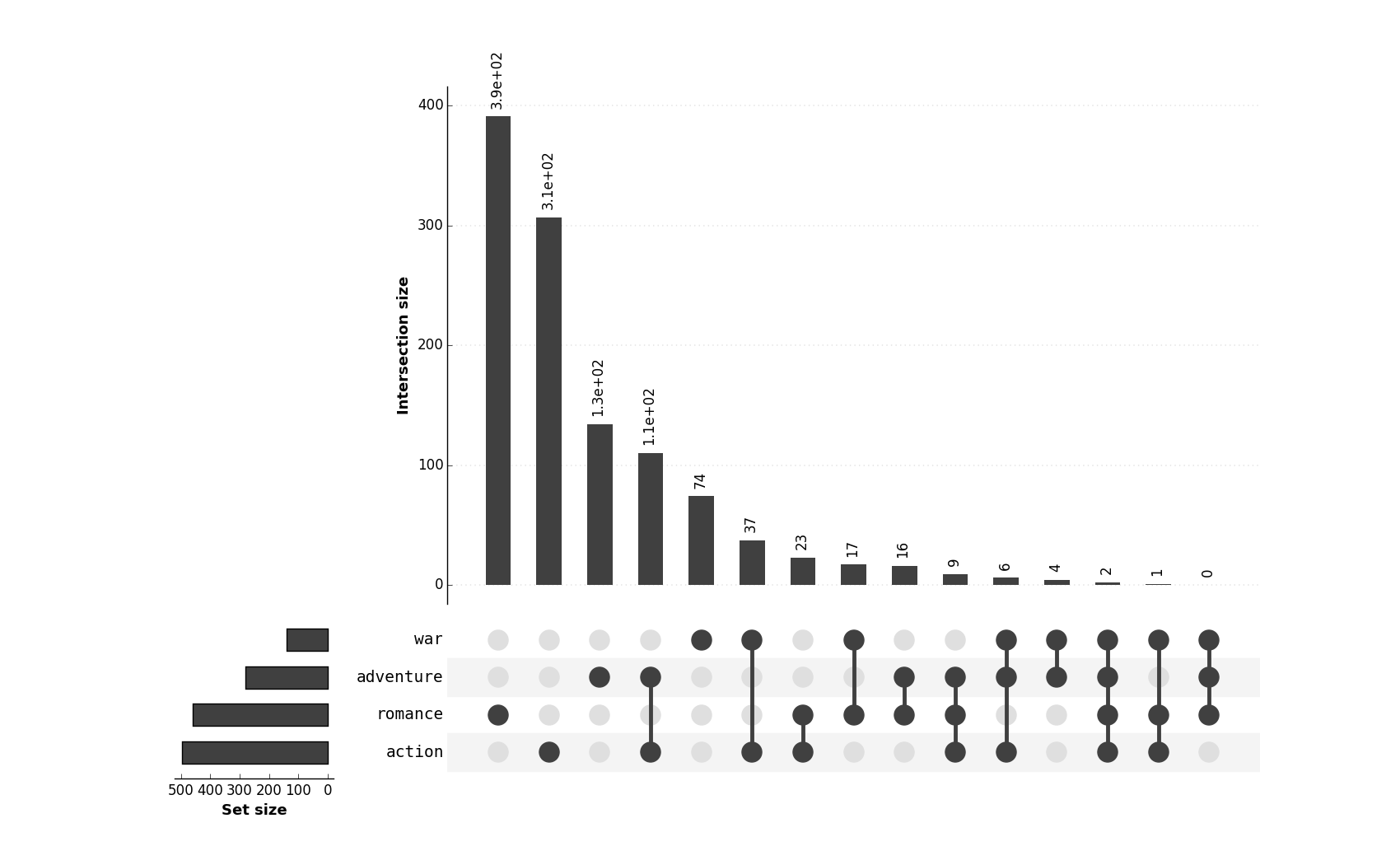
Each row is a set, the order from bottom to top is the same as in the sets list. Overlapping parts correspond to set intersections.
The numbers at the bottom show the sizes (cardinalities) of all intersections, aka chunks. The sizes of sets and
their intersections (chunks) are up to proportion, but the order of elements is not preserved, e.g. the leftmost chunk of size 3 is {6, 7, 8}.
A combinatorial optimization algorithms is applied that automatically chooses an order of the chunks (the columns of the array plotted) to minimize the number of parts, the sets are broken into. In the example above there are no gaps in the rows at all, but it is not always possible even for three sets.
By default, additional side plots are also displayed:
supervenn(sets)
set_annotations: names to be displayed in each row instead ofSet_0,Set_1etc.figsize: the figure size in inches; callingplt.figure(figsize=(16, 10))andsupervennafterwards will not work, because the function makes its own figure. TODO: dpiside_plots:True(default) orFalse, as shown above.chunks_ordering:'minimize gaps'(default, use an quasi-greedy algorithm to to find an order of columns with fewer gaps in each row),'size'(bigger chunks go first),'occurence'(chunks that are in more sets go first),'random'( randomly shuffle the columns).sets_ordering:None(default - keep the order of sets as passed into function),'minimize gaps'(use same quasi-greedy algorithm to group similar sets closer together),'size'(bigger sets go first),'chunk count'(sets that contain most chunks go first),'random'.widths_minmax_ratio:None(default) or a number0 < r <= 1. Useful in case the chunks (intersections) are very different in sizes. Will map the chunk sizes according tow -> a * w + bso that the minimal to maximal chunk width ratio is no smaller thanwidths_minmax_ratio. The exact proportionality is lost in this case. Settingwidths_minmax_ratio=1will result in all chunks being displayed as same size (no proportionalty at all.)col_annotations_ys_count: 1 (default), 2, or 3 - also helps to reduce clutter in column annotations area.min_width_for_annotation: integer (default 1), another argument to reduce clutter, allows to hide annotations for chunks smaller than this value.
Other arguments can be found in the docstring to the function.
letters = {'a', 'r', 'c', 'i', 'z'}
programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
green_things = {'python', 'grass'}
sets = [letters, programming_languages, animals, geographic_places, names, green_things]
labels = ['letters', 'programming languages', 'animals', 'geographic places',
'human names', 'green things']
supervenn(sets, labels, figsize=(10, 6), sets_ordering='minimize gaps')
And this is how the figure would look without the smart column reordering algorithm:

Data courtesy of Jake R Conway, Alexander Lex, Nils Gehlenborg - creators of UpSet
Figure from original article (note that it is by no means proportional!):

Figure made with UpSetR

Figure made with supervenn (using the widths_minmax_ratio argument)
supervenn(sets_list, species_names, figsize=(20, 10), widths_minmax_ratio=0.1,
sets_ordering='minimize gaps', rotate_col_annotations=True, col_annotations_area_height=1.2)
It must be noted that supervenn produces best results when there is some inherent structure to the sets in question.
This typically means that the number of non-empty intersections is significantly lower than the maximum possible
(which is 2^n_sets - 1). This is not the case in the present example, as 62 of the 63 intersections are non-empty,
hence the results are not that pretty.
This was actually my motivation in creating this package. The team I'm currently working in provides an API that solves a variation of the Multiple Vehicles Routing Problem. The API solves tasks of the form "Given 1000 delivery orders each with lat, lon, time window and weight, and 50 vehicles each with capacity and work shift, distribute the orders between the vehicles and build an optimal route for each vehicle".
A given client can send tens of such requests per day and sometimes it is usefult to look at their requests and understand how they are related to each other in terms of what orders are included in each of the request. Are they sending the same task over and over again - a sign that they are not satisfied with routes they get and they might need our help in using the API? Are they manually editing the routes (a process that results in more requests to our API, with only the orders from affected routes included)? Or are they solving for several independent order sets and are happy with each individual result?
Here's an example of a client who is not that happy:

Rows from bottom to top are requests to our API from earlier to later, represented by their sets of order IDs. With the
help of some custom annotations (set_annotations argument), the situation is immediately made clear. The client solved
a big task at 10:54, they were not happy about the result, and tried some manual edits until 11:11. Then in the evening
they re-sent the whole task twice over, probably with some change in parameters.
Another unhappy customer:

This guy here spend almost two hours, 17:40 to 19:30 solving the same full task over and over again, with some manual edits in between. Looks like they might be doing something wrong and our help is needed.
And finally, a happy one:

The description of the algorithm can be found in the docstring to supervenn._algorithms module.
This tool plots proper area-propriotional Venn diagrams with circles for two or three sets. But the problem with circles is that they are pretty useless even in the case of three sets. For example, if one set is symmetrical difference of the other two:
from matplotlib_venn import venn3
set_1 = {1, 2, 3, 4}
set_2 = {3, 4, 5}
set_3 = set_1 ^ set_2
venn3([set_1, set_2, set_3], set_colors=['steelblue', 'orange', 'green'], alpha=0.8)
See all that zeros? This image makes little sense. The supervenn's approach to this problem is to allow the sets to be
broken into separate parts, while trying to minimize the number of such breaks and guaranteeing exact proportionality of
all parts:

This package is created and maintained by Fedor Indukaev. This is my first attempt at making a full Python package,
so code and structure of the package might be not up to best practices sometimes. Any bug reports, questions, comments, recommendations, feature requests, pull requests, code reviews etc are most welcome. You can reach me at my github username at mail by g0ogIe.