
Langchain/LlamaIndex provide easy to use abstractions that can be used for quick experimentation and prototyping on jupyter notebooks. But, when things move to production, there are constraints like the components should be modular, easily scalable and extendable. This is where Cognita comes in action. Cognita uses Langchain/Llamaindex under the hood and provides an organisation to your codebase, where each of the RAG component is modular, API driven and easily extendible. Cognita can be used easily in a local setup, at the same time, offers you a production ready environment along with no-code UI support. Cognita also supports incremental indexing by default.
You can try out Cognita at: https://cognita.truefoundry.com

- Cognita
- ✨ Getting Started
- 🐍 Installing Python and Setting Up a Virtual Environment
- 🚀 Quickstart: Running Cognita Locally
- 🛠️ Project Architecture
- 💡 Writing your Query Controller (QnA):
- 🐳 Quickstart: Deployment with Truefoundry:
- 💖 Open Source Contribution
- 🔮 Future developments
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are:
- Chunking and Embedding Job: The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be triggered via an event to keep the data updated.
- Query Service: The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic.
- LLM / Embedding Model Deployment: Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API.
- Vector DB deployment: Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way.
Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app.
- A central reusable repository of parsers, loaders, embedders and retrievers.
- Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team.
- Fully API driven - which allows integration with other systems.
If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries.
- Support for multiple document retrievers that use
Similarity Search,Query Decompostion,Document Reranking, etc - Support for SOTA OpenSource embeddings and reranking from
mixedbread-ai - Support for using LLMs using
Ollama - Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
You can play around with the code locally using the python script or using the UI component that ships with the code.
Before you can use Cognita, you'll need to ensure that Python >=3.10.0 is installed on your system and that you can create a virtual environment for a safer and cleaner project setup.
It's recommended to use a virtual environment to avoid conflicts with other projects or system-wide Python packages.
Navigate to your project's directory in the terminal. Run the following command to create a virtual environment named venv (you can name it anything you like):
python3 -m venv ./venv
- On Windows, activate the virtual environment by running:
venv\Scripts\activate.bat
- On macOS and Linux, activate it with:
source venv/bin/activate
Once your virtual environment is activated, you'll see its name in the terminal prompt. Now you're ready to install Cognita using the steps provided in the Quickstart sections.
Remember to deactivate the virtual environment when you're done working with Cognita by simply running deactivate in the terminal.
Following are the instructions for running Cognita locally without any additional Truefoundry dependencies
In the project root execute the following command:
pip install -r backend/requirements.txt
- Create a
.envfile by copying copy fromenv.local.exampleset up relavant fields.
- Now we index the data (
sample-data/creditcards) by executing the following command from project root:python -m local.ingest - To run the query execute the following command from project root:
python -m local.run
These commands make use of
local.metadata.yamlfile where you setup qdrant collection name, different data source path, and embedder configurations.
You can try out different retrievers and queries by importing them from
from backend.modules.query_controllers.example.payloadinrun.py
You can also start a FastAPI server:
uvicorn --host 0.0.0.0 --port 8000 backend.server.app:app --reloadThen, Swagger doc will be available at:http://localhost:8000/For local version you need not create data sources, collection or index them using API, as it is taken care bylocal.metadata.yamlandingest.pyfile. You can directly try out retrievers endpoint.
To use frontend UI for quering you can go to :
cd fronendand executeyarn devto start the UI and play around. Refer more at frontend README

Overall the architecture of Cognita is composed of several entities
-
Data Sources - These are the places that contain your documents to be indexed. Usually these are S3 buckets, databases, TrueFoundry Artifacts or even local disk
-
Metadata Store - This store contains metadata about the collection themselves. A collection refers to a set of documents from one or more data sources combined. For each collection, the collection metadata stores
- Name of the collection
- Name of the associated Vector DB collection
- Linked Data Sources
- Parsing Configuration for each data source
- Embedding Model and Configuration to be used
-
LLM Gateway - This is a central proxy that allows proxying requests to various Embedding and LLM models across many providers with a unified API format. This can be OpenAIChat, OllamaChat, or even TruefoundryChat that uses TF LLM Gateway.
-
Vector DB - This stores the embeddings and metadata for parsed files for the collection. It can be queried to get similar chunks or exact matches based on filters. We are currently supporting
QdrantandSingleStoreas our choice of vector database. -
Indexing Job - This is an asynchronous Job responsible for orchestrating the indexing flow. Indexing can be started manually or run regularly on a cron schedule. It will
- Scan the Data Sources to get list of documents
- Check the Vector DB state to filter out unchanged documents
- Downloads and parses files to create smaller chunks with associated metadata
- Embeds those chunks using the AI Gateway and puts them into Vector DB
The source code for this is in the
backend/indexer/
-
API Server - This component processes the user query to generate answers with references synchronously. Each application has full control over the retrieval and answer process. Broadly speaking, when a user sends a request
- The corresponsing Query Controller bootstraps retrievers or multi-step agents according to configuration.
- User's question is processed and embedded using the AI Gateway.
- One or more retrievers interact with the Vector DB to fetch relevant chunks and metadata.
- A final answer is formed by using a LLM via the AI Gateway.
- Metadata for relevant documents fetched during the process can be optionally enriched. E.g. adding presigned URLs.
The code for this component is in
backend/server/
- A Cron on some schedule will trigger the Indexing Job
- The data source associated with the collection are scanned for all data points (files)
- The job compares the VectorDB state with data source state to figure out newly added files, updated files and deleted files. The new and updated files are downloaded
- The newly added files and updated files are parsed and chunked into smaller pieces each with their own metadata
- The chunks are embedded using embedding models like
text-ada-002fromopenaiormxbai-embed-large-v1frommixedbread-ai - The embedded chunks are put into VectorDB with auto generated and provided metadata
-
Users sends a request with their query
-
It is routed to one of the app's query controller
-
One or more retrievers are constructed on top of the Vector DB
-
Then a Question Answering chain / agent is constructed. It embeds the user query and fetches similar chunks.
-
A single shot Question Answering chain just generates an answer given similar chunks. An agent can do multi step reasoning and use many tools before arriving at an answer. In both cases, the API server uses LLM models (like GPT 3.5, GPT 4, etc)
-
Before returning the answer, the metadata for relevant chunks can be updated with things like presigned urls, surrounding slides, external data source links.
-
The answer and relevant document chunks are returned in response.
Note: In case of agents the intermediate steps can also be streamed. It is up to the specific app to decide.
Entire codebase lives in backend/
.
|-- Dockerfile
|-- README.md
|-- __init__.py
|-- backend/
| |-- indexer/
| | |-- __init__.py
| | |-- indexer.py
| | |-- main.py
| | `-- types.py
| |-- modules/
| | |-- __init__.py
| | |-- dataloaders/
| | | |-- __init__.py
| | | |-- loader.py
| | | |-- localdirloader.py
| | | `-- ...
| | |-- embedder/
| | | |-- __init__.py
| | | |-- embedder.py
| | | -- mixbread_embedder.py
| | | `-- embedding.requirements.txt
| | |-- metadata_store/
| | | |-- base.py
| | | |-- client.py
| | | `-- truefoundry.py
| | |-- parsers/
| | | |-- __init__.py
| | | |-- parser.py
| | | |-- pdfparser_fast.py
| | | `-- ...
| | |-- query_controllers/
| | | |-- default/
| | | | |-- controller.py
| | | | `-- types.py
| | | |-- query_controller.py
| | |-- reranker/
| | | |-- mxbai_reranker.py
| | | |-- reranker.requirements.txt
| | | `-- ...
| | `-- vector_db/
| | |-- __init__.py
| | |-- base.py
| | |-- qdrant.py
| | `-- ...
| |-- requirements.txt
| |-- server/
| | |-- __init__.py
| | |-- app.py
| | |-- decorators.py
| | |-- routers/
| | `-- services/
| |-- settings.py
| |-- types.py
| `-- utils.py
Cognita goes by the tagline -
Everything is available and Everything is customizable.
Cognita makes it really easy to switch between parsers, loaders, models and retrievers.
-
You can write your own data loader by inherting the
BaseDataLoaderclass frombackend/modules/dataloaders/loader.py -
Finally, register the loader in
backend/modules/dataloaders/__init__.py -
Testing a dataloader on localdir, in root dir, copy the following code as
test.pyand execute it. We show how to test an existingLocalDirLoaderhere:from backend.modules.dataloaders import LocalDirLoader from backend.types import DataSource data_source = DataSource( type="local", uri="sample-data/creditcards", ) loader = LocalDirLoader() loaded_data_pts = loader.load_full_data( data_source=data_source, dest_dir="test/creditcards", ) for data_pt in loaded_data_pts: print(data_pt)
- The codebase currently uses
OpenAIEmbeddingsyou can registered asdefault. - You can register your custom embeddings in
backend/modules/embedder/__init__.py - You can also add your own embedder an example of which is given under
backend/modules/embedder/mixbread_embedder.py. It inherits langchain embedding class.
-
You can write your own parser by inherting the
BaseParserclass frombackend/modules/parsers/parser.py -
Finally, register the parser in
backend/modules/parsers/__init__.py -
Testing a Parser on a local file, in root dir, copy the following code as
test.pyand execute it. Here we show how we can test existingMarkdownParser:import asyncio from backend.modules.parsers import MarkdownParser parser = MarkdownParser() chunks = asyncio.run( parser.get_chunks( filepath="sample-data/creditcards/diners-club-black.md", ) ) print(chunks)
-
To add your own interface for a VectorDB you can inhertit
BaseVectorDBfrombackend/modules/vector_db/base.py -
Register the vectordb under
backend/modules/vector_db/__init__.py
- Rerankers are used to sort relavant documents such that top k docs can be used as context effectively reducing the context and prompt in general.
- Sample reranker is written under
backend/modules/reranker/mxbai_reranker.py
Code responsible for implementing the Query interface of RAG application. The methods defined in these query controllers are added routes to your FastAPI server.
-
Add your Query controller class in
backend/modules/query_controllers/ -
Add
query_controllerdecorator to your class and pass the name of your custom controller as argument
from backend.server.decorator import query_controller
@query_controller("/my-controller")
class MyCustomController():
...- Add methods to this controller as per your needs and use our http decorators like
post, get, deleteto make your methods an API
from backend.server.decorator import post
@query_controller("/my-controller")
class MyCustomController():
...
@post("/answer")
def answer(query: str):
# Write code to express your logic for answer
# This API will be exposed as POST /my-controller/answer
...- Import your custom controller class at
backend/modules/query_controllers/__init__.py
...
from backend.modules.query_controllers.sample_controller.controller import MyCustomControllerAs an example, we have implemented sample controller in
backend/modules/query_controllers/example. Please refer for better understanding
To be able to Query on your own documents, follow the steps below:
-
Register at TrueFoundry, follow here
- Fill up the form and register as an organization (let's say <org_name>)
- On
Submit, you will be redirected to your dashboard endpoint ie https://<org_name>.truefoundry.cloud - Complete your email verification
- Login to the platform at your dashboard endpoint ie. https://<org_name>.truefoundry.cloud
Note: Keep your dashboard endpoint handy, we will refer it as "TFY_HOST" and it should have structure like "https://<org_name>.truefoundry.cloud" -
Setup a cluster, use TrueFoundry managed for quick setup
- Give a unique name to your Cluster and click on Launch Cluster
- It will take few minutes to provision a cluster for you
- On Configure Host Domain section, click
Registerfor the pre-filled IP - Next,
Adda Docker Registry to push your docker images to. - Next, Deploy a Model, you can choose to
Skipthis step
-
Add a Storage Integration
-
Create a ML Repo
-
Navigate to ML Repo tab
-
Click on
+ New ML Repobutton on top-right -
Give a unique name to your ML Repo (say 'docs-qa-llm')
-
Select Storage Integration
-
On
Submit, your ML Repo will be createdFor more details: link
-
-
Create a Workspace
- Navigate to Workspace tab
- Click on
+ New Workspacebutton on top-right - Select your Cluster
- Give a name to your Workspace (say 'docs-qa-llm')
- Enable ML Repo Access and
Add ML Repo Access - Select your ML Repo and role as Project Admin
- On
Submit, a new Workspace will be created. You can copy the Workspace FQN by clicking on FQN.
For more details: link
-
Deploy RAG Application
- Navigate to Deployments tab
- Click on
+ New Deploymentbuttton on top-right - Select
Application Catalogue - Select your workspace
- Select RAG Application
- Fill up the deployment template
- Give your deployment a Name
- Add ML Repo
- You can either add an existing Qdrant DB or create a new one
- By default,
mainbranch is used for deployment (You will find this option inShow Advance fields). You can change the branch name and git repository if required.Make sure to re-select the main branch, as the SHA commit, does not get updated automatically.
- Click on
Submityour application will be deployed.
The following steps will showcase how to use the cognita UI to query documents:
-
Create Data Source
- Click on
Data Sourcestab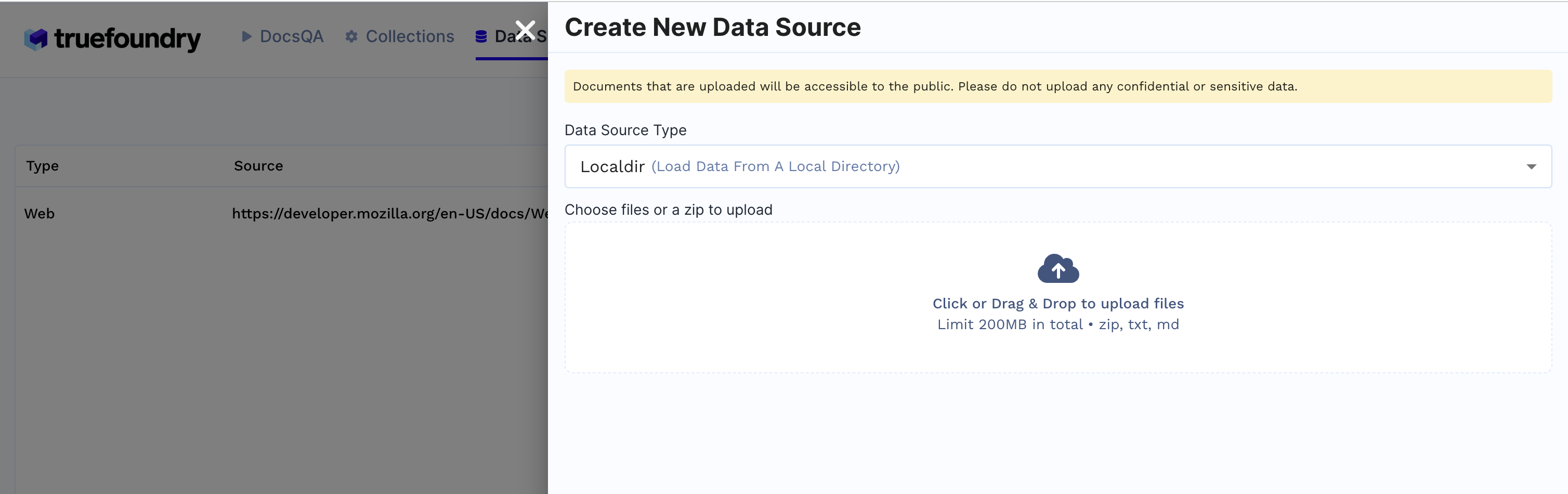
- Click
+ New Datasource - Data source type can be either files from local directory, web url, github url or providing Truefoundry artifact FQN.
- E.g: If
Localdiris selected upload files from your machine and clickSubmit.
- E.g: If
- Created Data sources list will be available in the Data Sources tab.

- Click on
-
Create Collection
- Click on
Collectionstab - Click
+ New Collection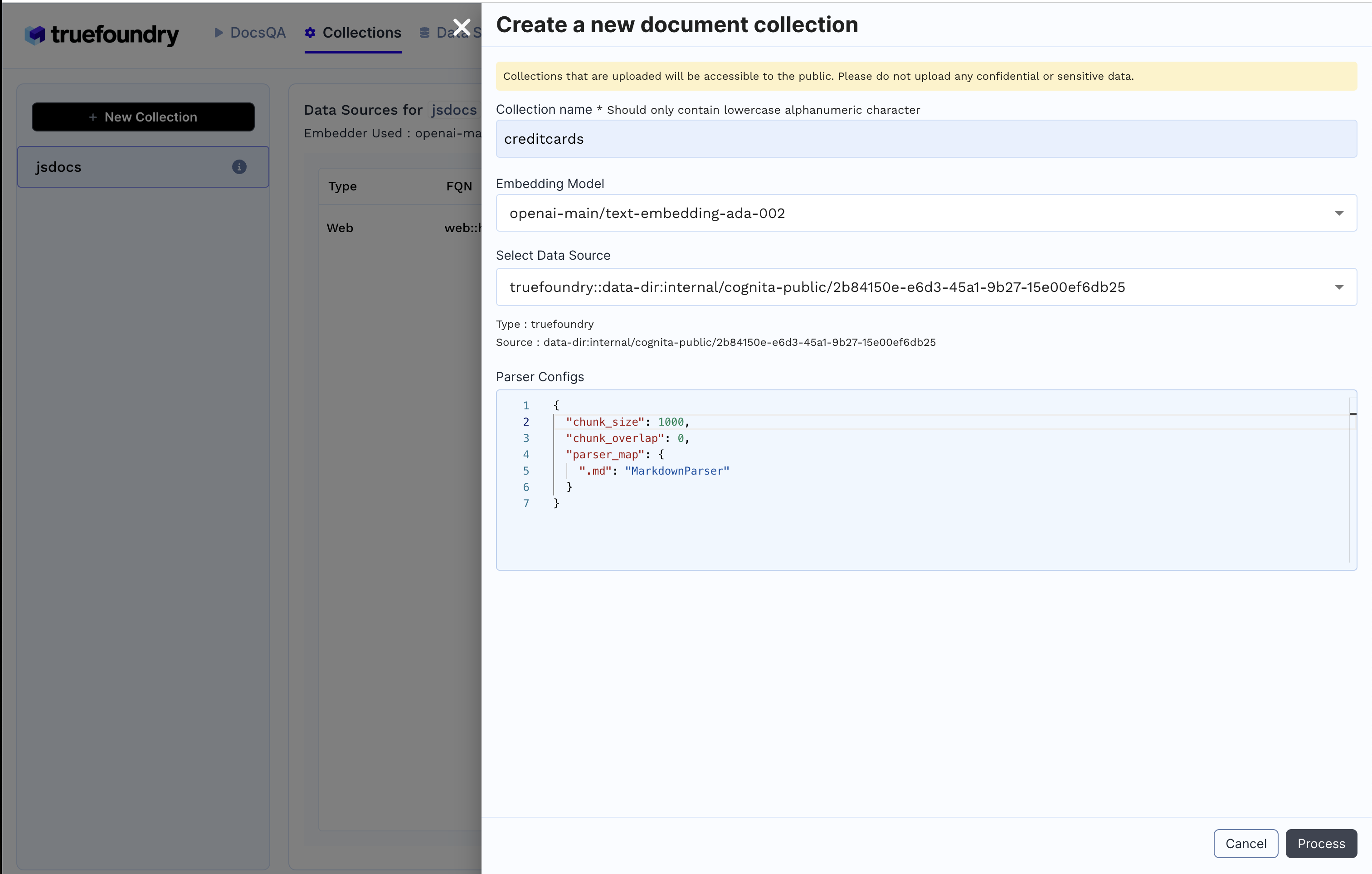
- Enter Collection Name
- Select Embedding Model
- Add earlier created data source and the necessary configuration
- Click
Processto create the collection and index the data.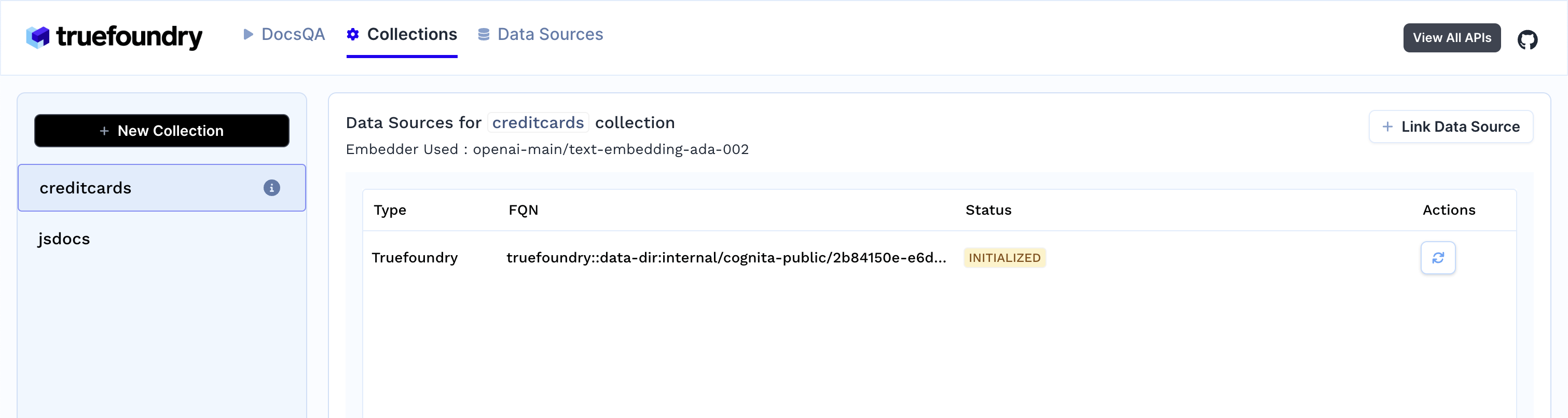
- Click on
-
As soon as you create the collection, data ingestion begins, you can view it's status by selecting your collection in collections tab. You can also add additional data sources later on and index them in the collection.
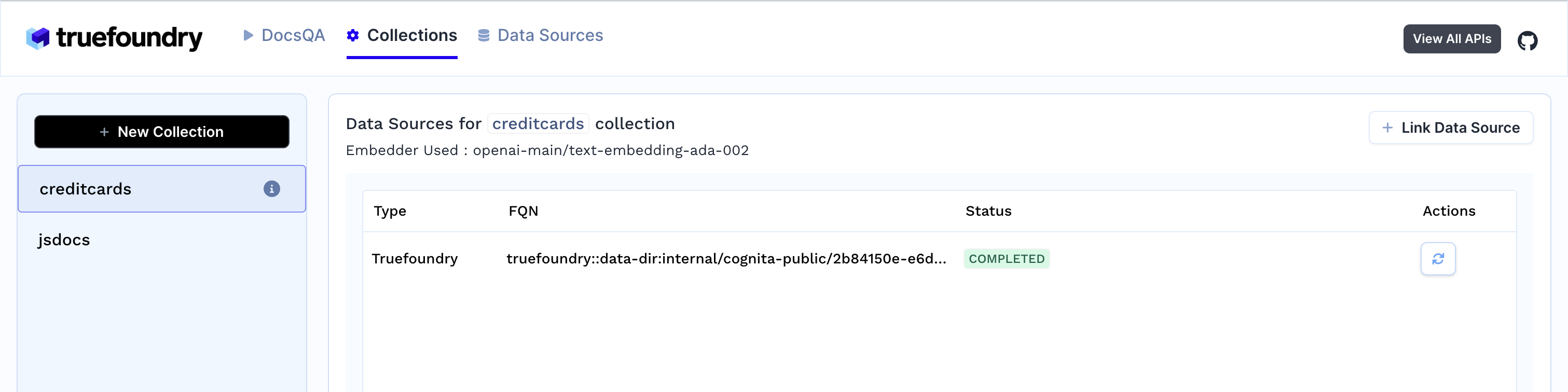
-
Response generation
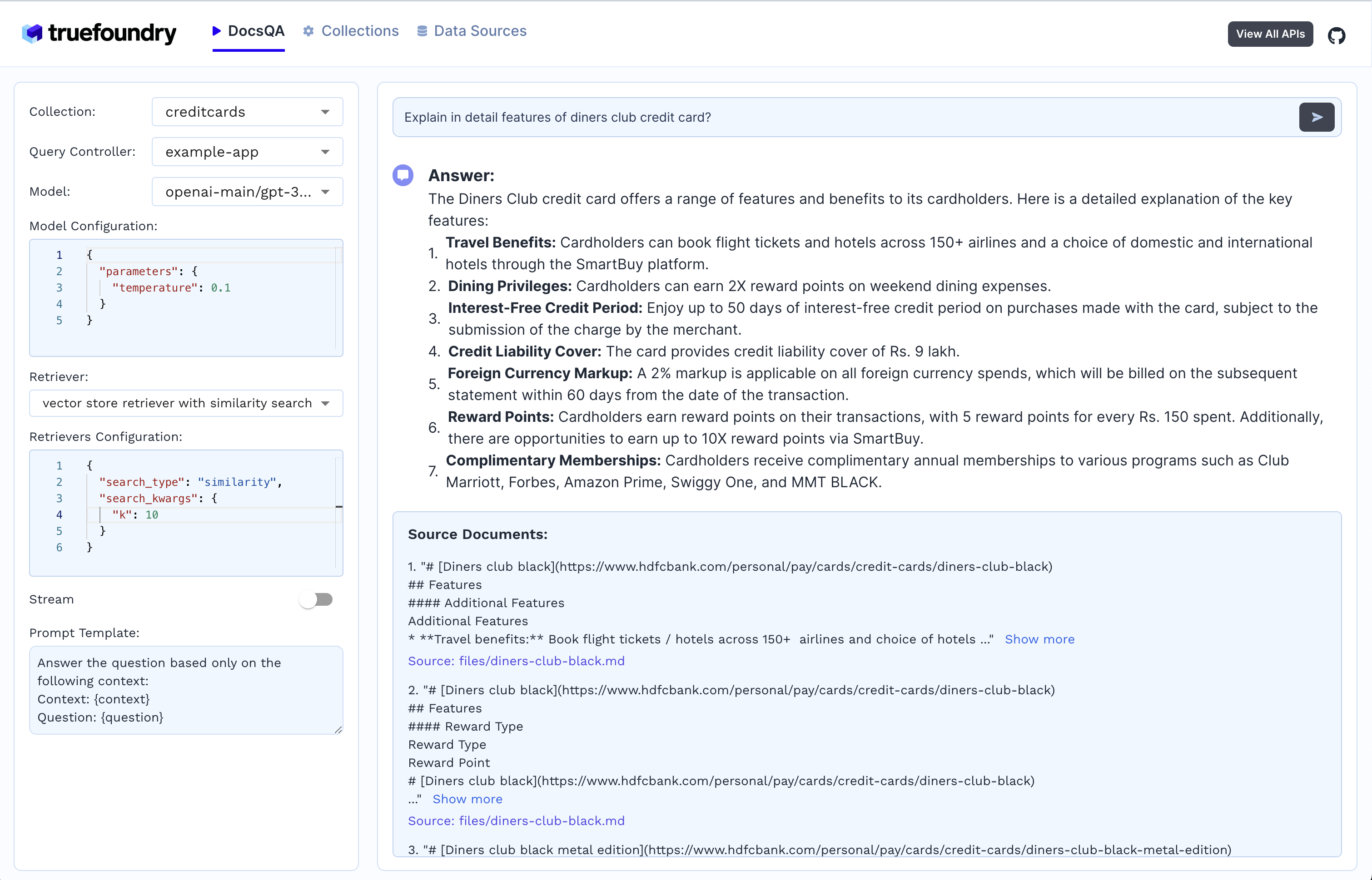
- Select the collection
- Select the LLM and it's configuration
- Select the document retriever
- Write the prompt or use the default prompt
- Ask the query






Your contributions are always welcome! Feel free to contribute ideas, feedback, or create issues and bug reports if you find any! Before contributing, please read the Contribution Guide.
Contributions are welcomed for the following upcoming developments:
- Support for other vector databases like
Chroma,Weaviate, etc - Support for
Scalar + Binary Quantizationembeddings. - Support for
RAG Evalutaionof different retrievers. - Support for
RAG Visualization. - Support for conversational chatbot with context
- Support for RAG optimized LLMs like
stable-lm-3b,dragon-yi-6b, etc - Support for
GraphDB