REmote DIctionary Server
- purposes (use cases)
- Primary data storage (key:value, fast data ingestion, geo-based search, leaderboards, ...)
- In-memory cache (http session storage, rate-limits - decrease amount of request to expensive API with fixing/sliding window ...)
- Services decoupling (glue between microservices - pub/sub, streams)
- (extensions)[https://redislabs.com/community/oss-projects/]
- (RediSearch)[https://oss.redislabs.com/redisearch/]
- (RedisGraph)[https://oss.redislabs.com/redisgraph/]
- (RedisTimeSeries)[https://oss.redislabs.com/redistimeseries/]
- (RedisJSON)[https://oss.redislabs.com/rejson/]
- (RedisAI)[https://oss.redislabs.com/redisai/]
- (RedisBloom)[https://oss.redislabs.com/rebloom/]
- (Benchmarking)[https://github.com/RedisLabs/memtier_benchmark]
- simple nodejs app
- commands
- data types
string is underpinning data for all data structures
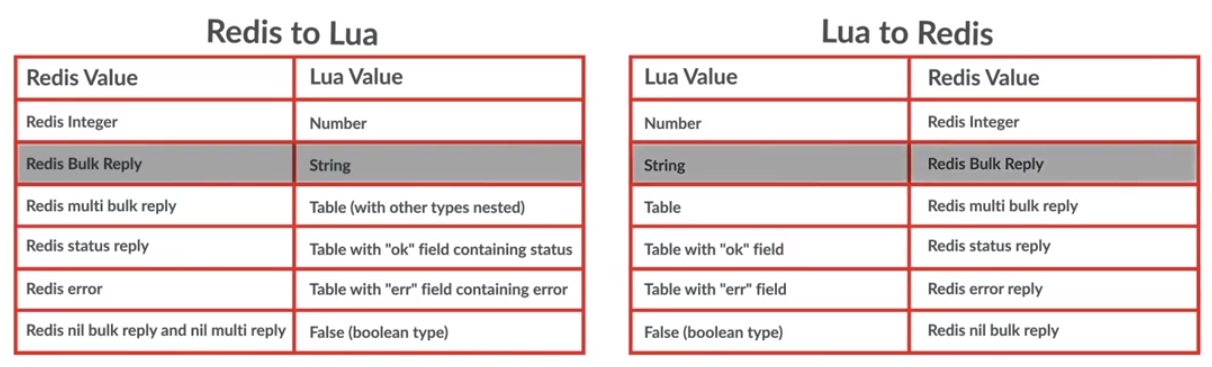
- REdis Serialization Protocol - RESP
- pipeline
pipeline == batch commands, will return result ONLY when ALL commands will be finished commands
- PIPELINED - start batching
- EXEC - execute all commands at once
PIPELINED SET my-value 200 INCR my-value SYNC - transactions
- commands:
- Within a transaction, changes are made by a command visible to subsequent commands in the same transaction
- MULTI - start transaction
- EXEC ( OK - successfully applied, nil - discard) / DISCARD - execute or discard transaction
- no rollback ( single operation )
- no nested transactions
- don't check validity of command during queueing
- wrong operation on datatype (increase string) just skipping the step, don't throw exception
- WATCH/UNWATCH - optimistic lock ( DISCARD transaction when someone will change key )
- should be executed !!before!! MULTI
- EXEC will execute UNWATCH for all transactions
- full example
SET my-value 200 WATCH my-value MULTI INCR my-value EXEC - terminate server
SHUTDOWN NOSAVE
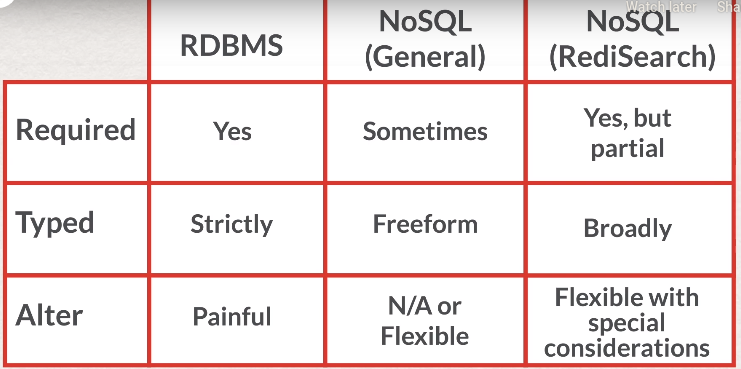
- no native indexes
- use "secondary index" - build "inverted index"
- use "faceted search" - build intersection of "inverted indexes" to find target search criteria
- use "hashed search" - build set with hash-key ( long name of relations between data cardinality )
- reject all types of 'write' operations in case of "Out of Memory"
- redis built in C, all modules (Shared Objects) should be written in C or interoperate with it ( Foreign Function Interface )
- module loading
- redis.conf
- command line: --loadmodule /usr/lib/redis/modules/redistimeseries.so
- MODULE LOAD
- through Redis Enterpirse GUI
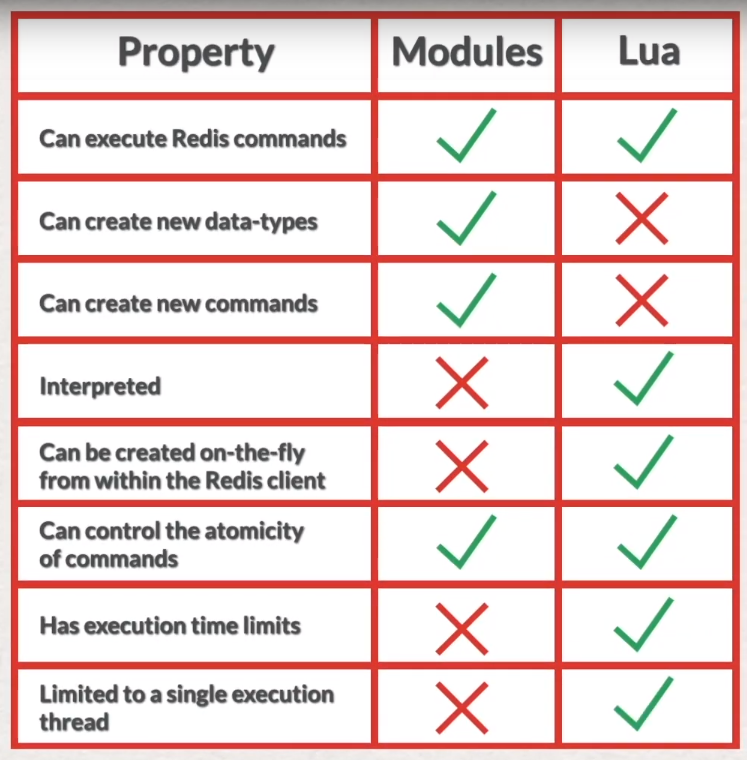
- module vs lua scripting
- LUA scripting in Redis, lua playground
Redis Lua script debugger
like transaction will execute script atomically
types
if execution timeout exceed limit - all other clients will receive "BUSY" answer
# EVAL script numkeys key [key ...] arg [arg ...]
# !!! KEYS and ARGV - 1-based arrays
HSET hash-key field1 hello field2 world
EVAL "return redis.call('HGET', 'hash-key', 'field1')" 0
EVAL "return redis.call('HGET', KEYS[1], ARGV[1])" 1 hash-key field2
EVAL "return redis.call('HMGET', KEYS[1], ARGV[1], ARGV[2])" 1 hash-key field2 field1
EVAL "return redis.call('HSCAN', KEYS[1], ARGV[1])" 1 hash-key 0
EVAL "local var1='hello world' return var1" 0
EVAL "local current_year=2019 return current_year+4" 0
SET current_year 2019
GET current_year
EVAL "local current_year=redis.call('GET', 'current_year') return current_year+4" 0
load scripts, cache script
# EVAL "return redis.call('HGET', KEYS[1], ARGV[1])" 1 hash-key field2
SCRIPT LOAD "return redis.call('HGET', KEYS[1], ARGV[1])"
EVALSHA 4688a0f6e1e971a14e2d596031751f0590d37a92 1 hash-key field2
ticket purchasing example
local customer_hold_key = 'hold:' .. ARGV[1] .. ':' .. KEYS[1]
local requested_tickets = tonumber(ARGV[2])
local purchase_state = redis.call('HGET', KEYS[2], 'state')
local hold_qty = redis.call('HGET', customer_hold_key, 'qty')
if (hold_qty == nil) then
return 0
elseif requested_tickets == tonumber(hold_qty) and
purchase_state == 'AUTHORIZE' then
-- Decrement the number of available tickets
redis.call('HINCRBY', KEYS[1], "available:General", -requested_tickets)
-- Delete the customer hold key
redis.call('DEL', customer_hold_key)
-- Set the purchase to 'COMPLETE'
redis.call('HMSET', KEYS[2], 'state', 'COMPLETE', 'ts', ARGV[3])
return 1
else
return 0
end
state machine example
local current_state = redis.call('HGET', KEYS[1], 'state')
local requested_state = ARGV[1]
if ((requested_state == 'AUTHORIZE' and current_state == 'RESERVE') or
(requested_state == 'FAIL' and current_state == 'RESERVE') or
(requested_state == 'FAIL' and current_state == 'AUTHORIZE') or
(requested_state == 'COMPLETE' and current_state == 'AUTHORIZE')) then
redis.call('HMSET', KEYS[1], 'state', requested_state, 'ts', ARGV[2])
return 1
else
return 0
end
managing scripts
# remove all scripts
SCRIPT FLUSH
# terminal current script
SCRIPT KILL
# debug command
SCRIPT DEBUG YES|SYNC|NO
- MODULE LIST - print all modules
- MODULE LOAD /usr/lib/redis/modules/redistimeseries.so
- MONITOR - show all executed commands ( for debugging purposes only !!! )
- debugging via linux shell, collaboration between client and server
sudo ngrep -W byline -d lo -t '' 'port 6379' sudo ngrep -W byline -d docker0 -t '' 'port 6379'
- DBSIZE - print current DB size
- MEMORY USAGE
- MEMORY STATS
- SLOWLOG GET 2 - investigating slow operations
- CLIENT LIST
- FLUSHALL [async] # remove all keys
- Flat key space
- No automatic namespacing
- Logical Databases ( Database zero )
- Naming conventions ( case sensitive, example user:{unique id of user}:followers
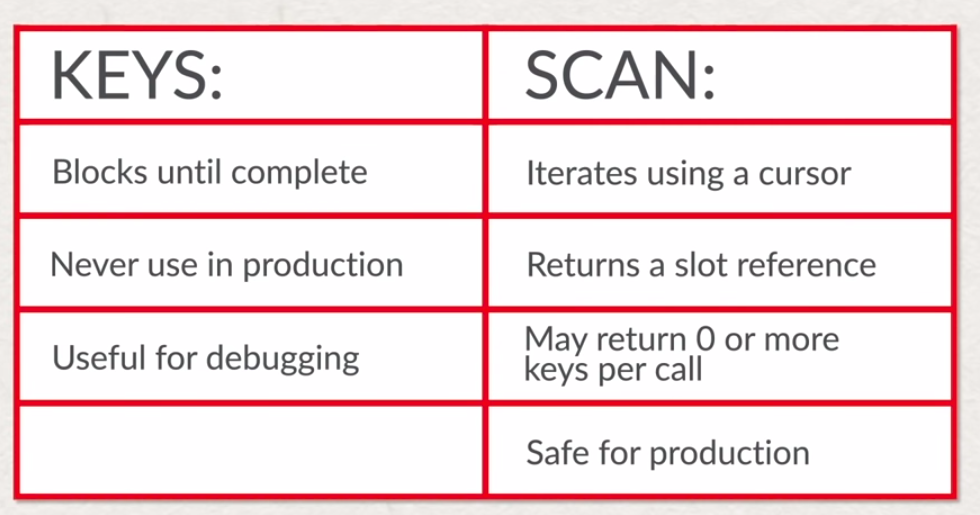
- keys
KEYS customer:15*
KEYS cus:15*
KEYS *
- scan
SCAN 0 MATCH customer*
SCAN 0
# return None if value is empty
TYPE <key>
OBJECT ENCODING <key>
- if value is of type string -> GET
- if value is of type hash -> HGETALL
- if value is of type lists ->
- LRANGE ( hgetall )
- if value is of type sets ->
- SMEMBERS
- if value is of type sorted sets ->
- ZRANGEBYSCORE
- existence of keys
EXIST {key}
# EXIST customer:1500
- set value
# insert only if the record still Not eXists
SET customer:3000 Vitalii NX
# insert only if the record EXXists
SET customer:3000 cherkavi XX
- LLEN
- LRANGE ( hgetall )
LRANGE my-list 0 -1 - LINDEX ( get from specific position )
- LPUSH ( left push )
- RPUSH ( right push )
- LSET
- LINSERT ( insert after certain element )
- LPOP ( left pop )
- RPOP ( right pop )
- LREM ( remove element by value )
- LTRIM ( remove to certain length,
LTRIM mylist -5 -1- retain only last 5 elements )rpush mylist 1 2 3 4 5 lstrim mylist 0 3 lrange mylist 0 -1 # 1 2 3
- SADD
- SMEMBERS
- SISMEMBER ( check if value present into set )
- SCARD # amount of elements, CARDinality
- SSCAN MATCH
SSCAN myset 0 MATCH *o* - SREM ( remove by value )
- SPOP ( pop random!!! element )
- SUNION (sql:union)
- SINTER (sql:inner join)
sadd myset1 one two three four sadd myset2 three four five six sinter myset1 myset2 - SDIFF ( not in )
sadd set-three A b C sadd set-four a b C sdiff set-three set-four # A
- ZRANGE <rank/index start> <rank/index stop> # inclusive
- ZRANGEBYSCORE # inclusive
- ZRANGEBYLEX
# ZADD <key> <score> <member> ZADD zset 10 aaa ZADD zset 20 bbb ZADD zset 30 ccc ZADD zset 30 ddd ZRANGEBYLEX zset "[aaa" "[ddd" ZRANGEBYLEX zset "[aaa" "(ddd" - ZADD
- ZREM
- ZREMRANGEBYSCORE
- ZREMRANGEBYRANK < position end>
redis:6379>zrange zset 0 -1 1) "aaa" 2) "bbb" 3) "ccc" 4) "ddd" 5) "eee" redis:6379> ZREMRANGEBYRANK zset 4 5 # (not-inclusive inclusive] (integer) 1 redis:6379> zrange zset 0 -1 # 1) "aaa" 2) "bbb" 3) "ccc" 4) "ddd" - ZRANK
- ZSCORE
- ZCOUNT # inclusive ZCOUNT -inf +inf ZCOUNT (-inf +inf) # exclusive
- ZINTERSTORE <key1, key2.... [number of keys]> WEIGHTS AGGREGATE <SUM|MIN|MAX> # intersection of sets (WEIGHT can be specified for all elements) and ordered-sets with multiplication factor WEIGHTS and way of AGGREGATion
- ZUNIONSTORE <key1, key2.... [number of keys]> WEIGHTS AGGREGATE <SUM|MIN|MAX> # union of sets (WEIGHT can be specified for all elements) and ordered-sets with multiplication factor WEIGHTS and way of AGGREGATion
hash has only one level, can't be embeddable individual field cannot be expired
# HEXISTS <key> <field>
HEXISTS myhash three
# HSET <key> <field1> <value1> <field2> <value2>
HSET myhash one 1 two 2 three 3
# HSETNX <key> <field> <value> # set only if not exists
HSETNX myhash one 2
HSETNX myhash four 4
# HDEL <key> <field>
HDEL myhash one
# HGET <key> <field>
HGET myhash one
# HMGET <key> <field1> ... <field.> # return multiply values
HMGET myhash one two
# HGETALL <key>
HGETALL myhash
# HLEN <key> # return amount of all fields
HLEN myhash
# HKEYS <key> # return only names of fields
HKEYS myhash
# HSCAN <key> <number> MATCH <pattern>
HSCAN myhash 0 MATCH *o*
HSCAN myhash 0 MATCH *ou*
# HINCRBY <key> <field> <value>
HINCRBY myhash four 3
HINCRBYFLOAT myhash four 3.2
INCR <key> # for integer
# SET my-personal-key 10
# SET my-personal-key "10"
# INCR my-personal-key
# INCRBY my-personal-key 3
# INCRBYFLOAT my-personal-key 2.5
under the hood - SortedSet,
where Score is 52bit GeoHash == Long+Lat
geohash online retrieving can be fulfilled by Distance, by Radius
geospatial standards:
- https://epsg.io/900913
- https://spatialreference.org/ref/epsg/popular-visualisation-crs-mercator/
UseCases:- finding points nearby
- find points in special region
GEOADD key longitude latitude member
Longitude: -180..180
Latitude: -85.05112878..85.05112878
GEOADD sites:geo -122.147019 37.670738 56
GEOADD sites:geo -122.007419 37.5506959 101
nature of the data under the hood
GEOADD test:geopoints 139.75 35.69333 "Budokan"
GEOADD test:geopoints 139.76632 35.666 "Olympic"
GEOADD test:geopoints 139.64007 35.4433 "Yokohama"
ZRANGE test:geopoints 0 -1 WITHSCORES
GEOHASH test:geopoints "Budokan" "Olympic" "Yokohama"
GEOPOS test:geopoints "Budokan" "Olympic" "Yokohama"
querying goedata
measurements: m, km, mi, ft
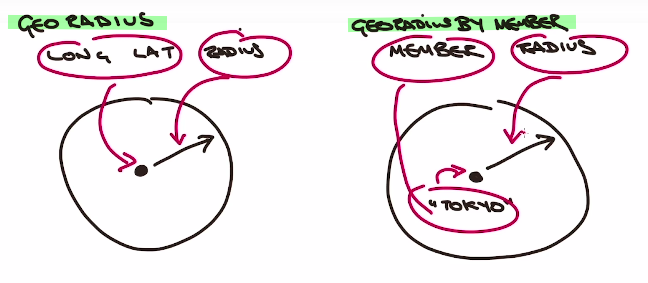
#GEODIST key member1 member2 [unit]
GEODIST test:geopoints "Budokan" "Olympic" km
# GEORADIUSBYMEMBER key member value unit
GEORADIUSBYMEMBER test:geopoints "Budokan" 3.5 km
GEORADIUSBYMEMBER test:geopoints "Budokan" 3.5 km WITHCOORD
GEORADIUS sites:geo -122.007419 37.5506959 5 km
GEORADIUS sites:geo -122.007419 37.5506959 5 km WITHDIST WITHCOORD
GEORADIUSBYMEMBER test:geopoints "Budokan" 5 km WITHHASH
GEORADIUSBYMEMBER test:geopoints "Budokan" 5 km WITHHASH WITHDIST STORE search_result
# saving search results into new key
GEORADIUSBYMEMBER test:geopoints "Budokan" 5 km STORE search_result
ZRANGE search_result 0 -1 WITHSCORES
GEOPOS search_result "Budokan" "Olympic" "Yokohama"
# intersection between two keysets
ZINTERSTORE
# union for two keysets
ZUNIONSTORE
# removing data
ZREM key member
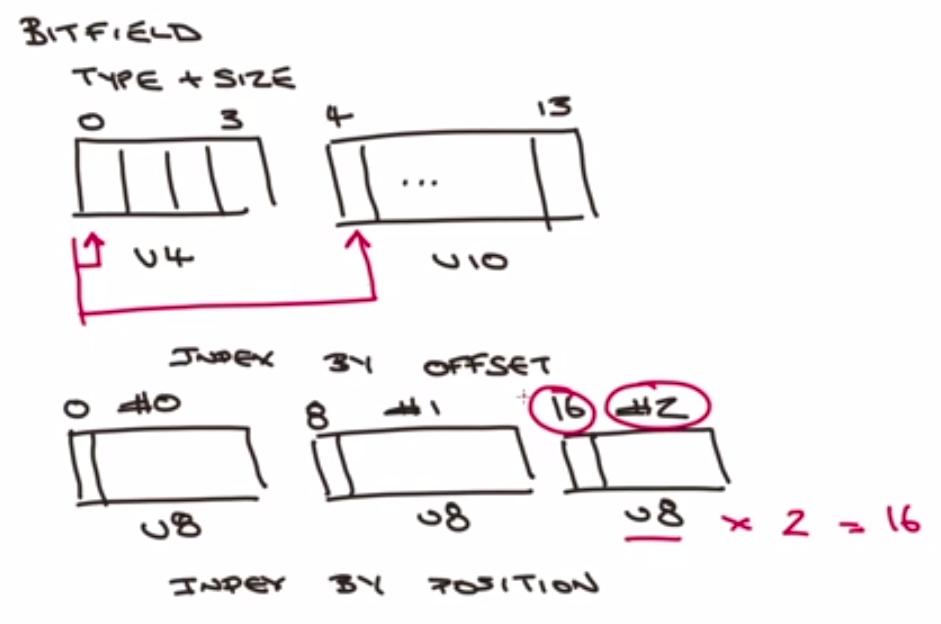
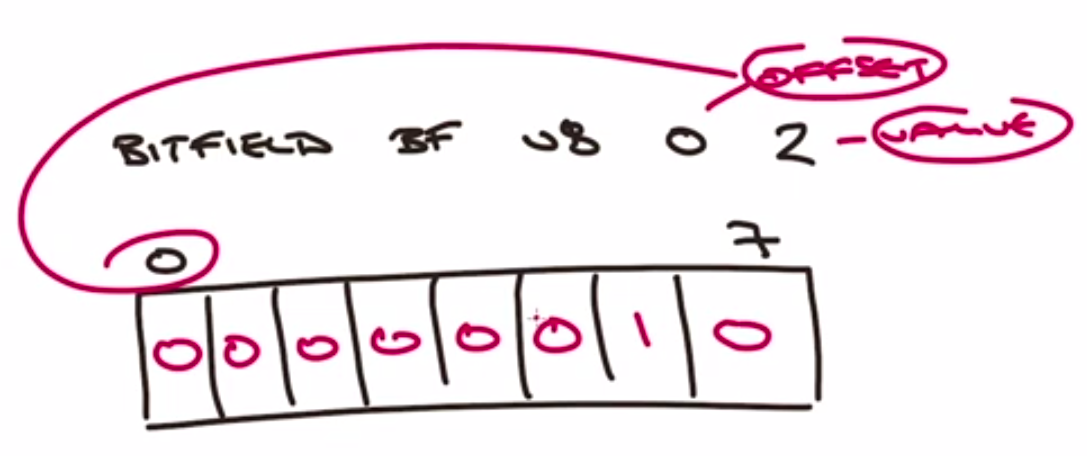
bitfield represenation
bitfield setvalue
set using histogram symbol
limit - i64 or u63
# sign - i
# unsign - u
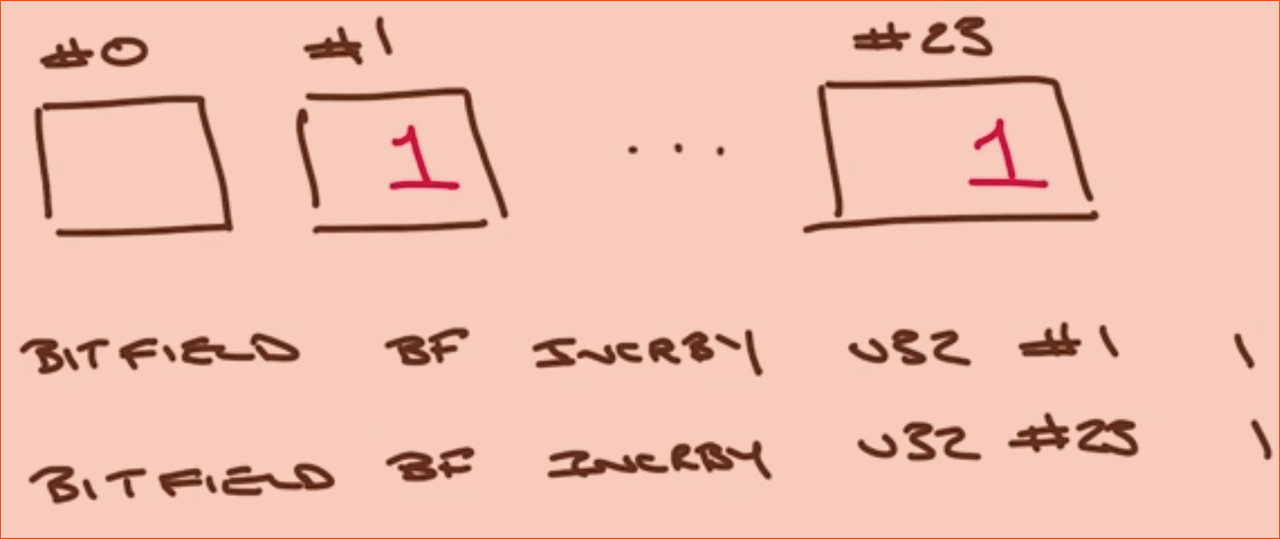
BITFIELD mybit SET u8 0 42
BITFIELD mybit SET u8 #0 0
BITFIELD mybit GET u8 0
BITFIELD mybit INCRBY u8 0 3
BITFIELD mybit INCRBY u8 #0 0
GET mybit
GETBIT mybit #0
SETBIT mybit #0 1
# total amount of bit with value 1
BITCOUNT mybit
# total amount of bit with value 1 with byte!!! offset
BITCOUNT mybit 1
# perform OR (AND, XOR, NOT) opertion with bitfields
BITOP OR mybit mybit
EXPIRE {key} {seconds}
PEXPIRE {key} {miliseconds}
EXPIREAT {key} {timestamp}
PEXPIREAT {key} {miliseconds-timestamp}
check expiration, check TimeToLive, how many seconds will live
TTL {key}
check living time
OBJECT IDLETIME <key>
remove expiration
PERSIST {key]
set with TTL
# miliseconds
SET customer:3000 warior PX 60000
# seconds
SET customer:3000 warior EX 60
SMOVE "source set" "destination set" "member name"
# delete key and value with blocking until removing associated memory block
DEL {key}
# delete key without blocking
UNLINK {key}


- subscribers listening only for new messages
- published message will not be saved/stored ( if no subscribers are listening - lost forever ) - fire and forget
- message is just a string ( unstructured )
- no unique id for message

SUBSCRIBE <channel name>
UNSUBSCRIBE <channel name>
PUBLISH <channel name> <value>
if channel is not exists but you are subscribed already - you will get all messages patterns
# subscribe for all channels
PSUBSCRIBE *
# subscribe for channel with any letter (ch-1, ch-2) at the end
PSUBSCRIBE ch-?
administration of pub/subscribe
PUBSUB <subcommand>
# list of active channels to subscribe
PUBSUB CHANNELS
# number of subscribers for a channel
PUBSUB NUMSUB <channel name>
# number of patterned subscribers ( how many psubscribe commands are active right now)
PUBSUB NUMPAT <channel name>
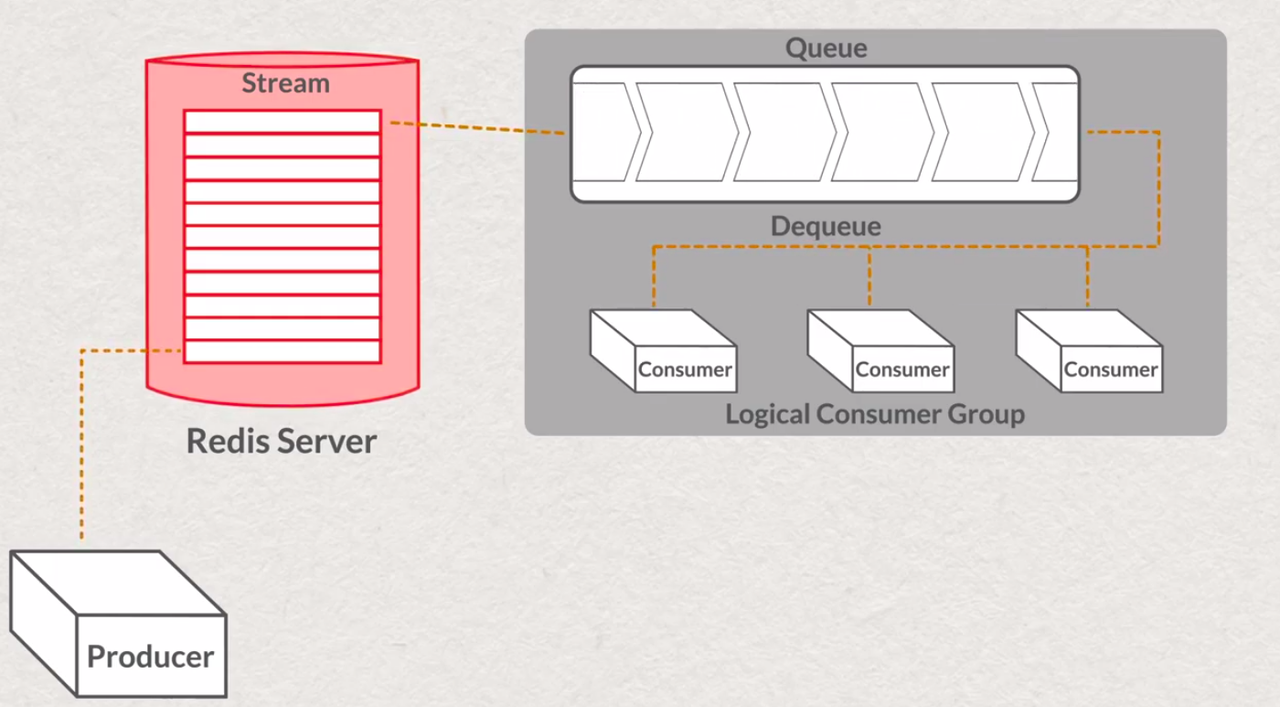
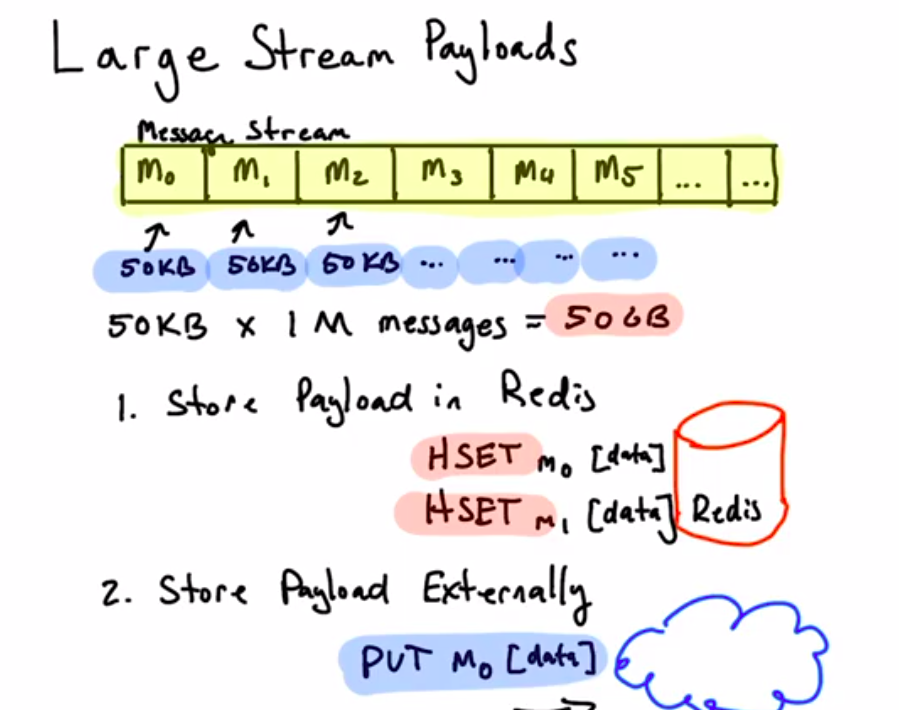
logically infinite, but server doesn't have infinite memory removing old messages ( XTRIM ) should be performed manually ( all messages are saving in memory permanently )
- stream patterns
- large message payloads external payload storage
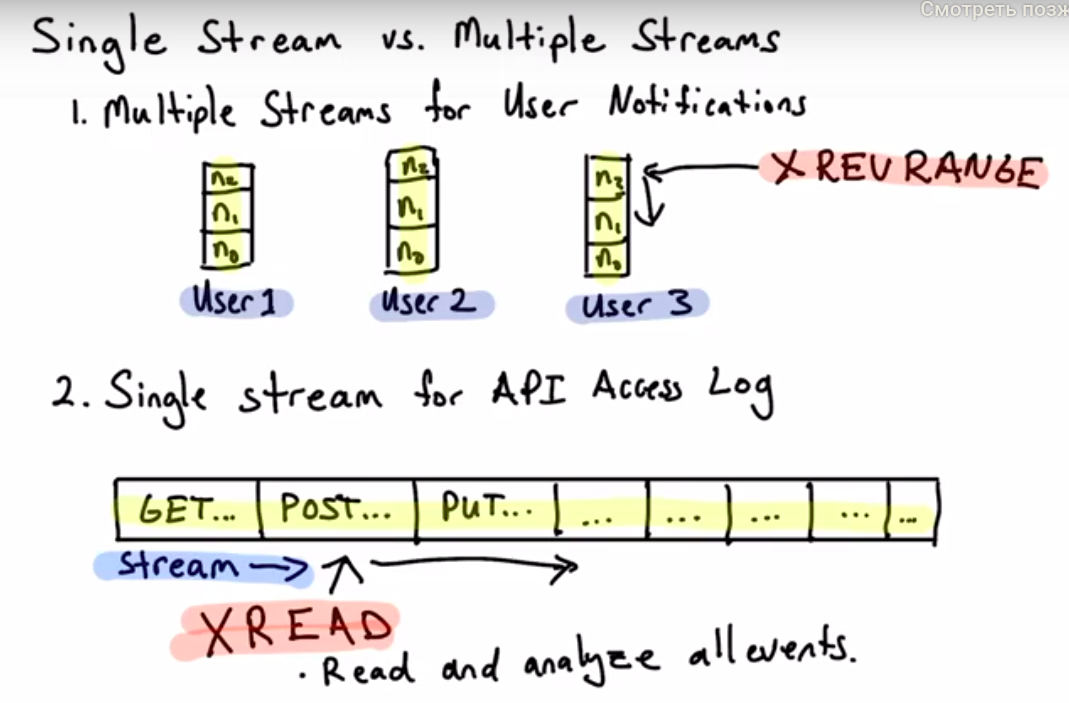
- one stream vs multiple stream one/multiple stream approach
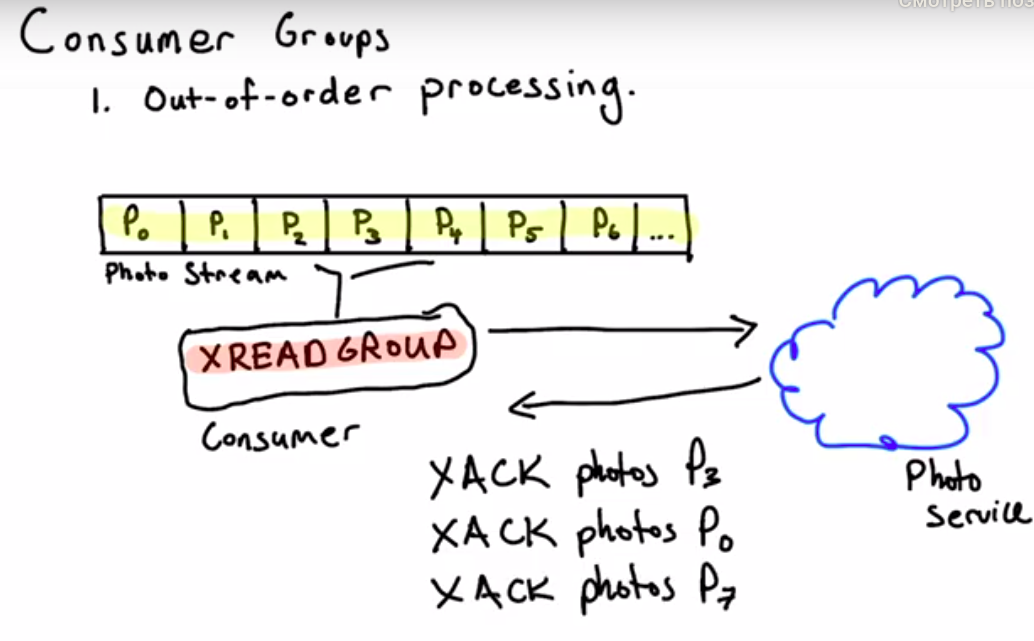
- single consumer vs consumer group
- consume jobs from queue (order is not important, resource-consuming processing )
consume jobs from queue - chain of responsibilities
chain of responsibilities
- consume jobs from queue (order is not important, resource-consuming processing )
- stream information
# XINFO GROUPS <name of stream >
XINFO GROUPS numbers
# XINFO STREAM <key == stream name>
XINFO STREAM numbers
# XINFO CONSUMERS <key == stream name> < name of consumer group >
XINFO CONSUMERS numbers numbers-group
# print all clients, print consumers
CLIENT LIST
# consumer set name, nameconvention: hostname-applicationName-processId
CLIENT SETNAME <name>
# get user name
CLIENT GETNAME
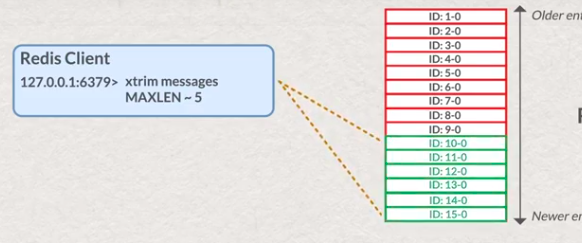
- control stream length ( removing redundant messages )
- by size of stream: during adding new element
# strict number of elements ( not recommended ) XADD <stream name> MAXLEN <max elements size> <name of current key or *> <field name> <field value> # more efficient by resources consumption XADD <stream name> MAXLEN ~ <max elements size> <name of current key or *> <field name> <field value>- by size of stream: background process
# certain number of elements XTRIM <stream name> MAXLEN <max elements size> # recommended ( approximate amount of elements ) XTRIM <stream name> MAXLEN ~ <max elements size>- by using EXPIRE with special name of STREAM based on date/time


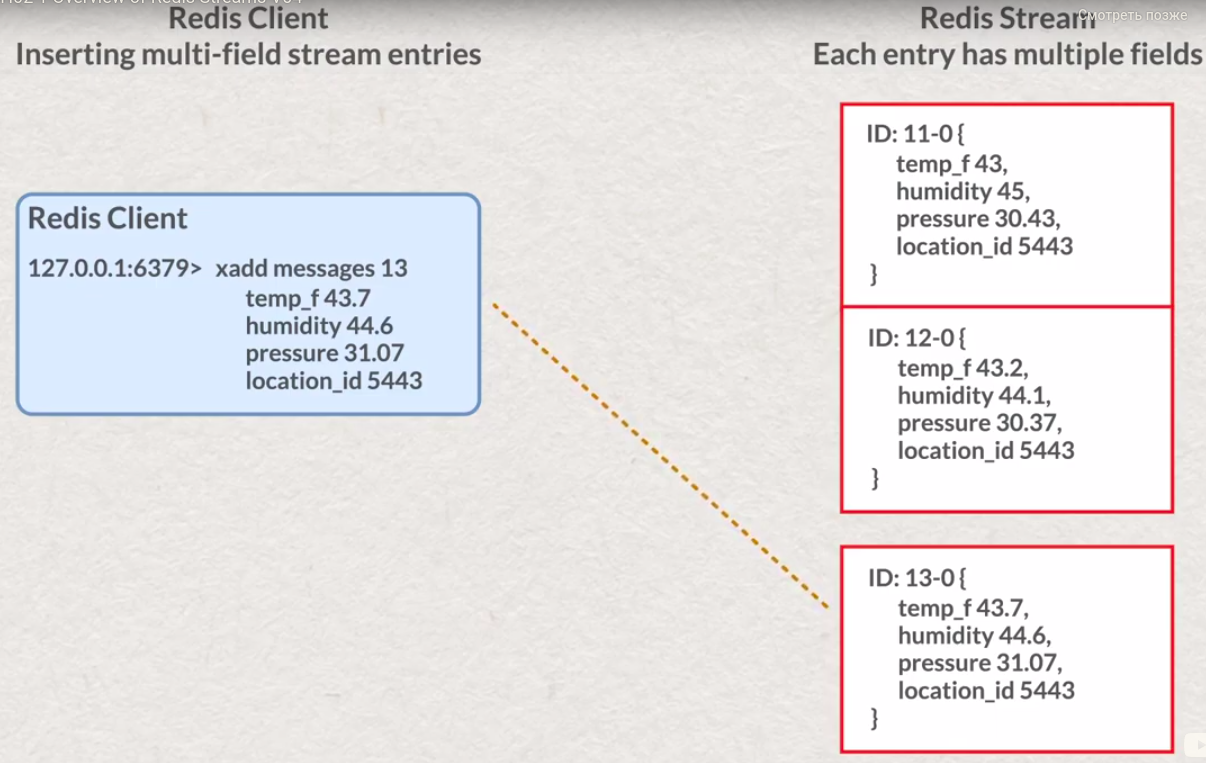
- add stream entry https://redis.io/commands/xadd
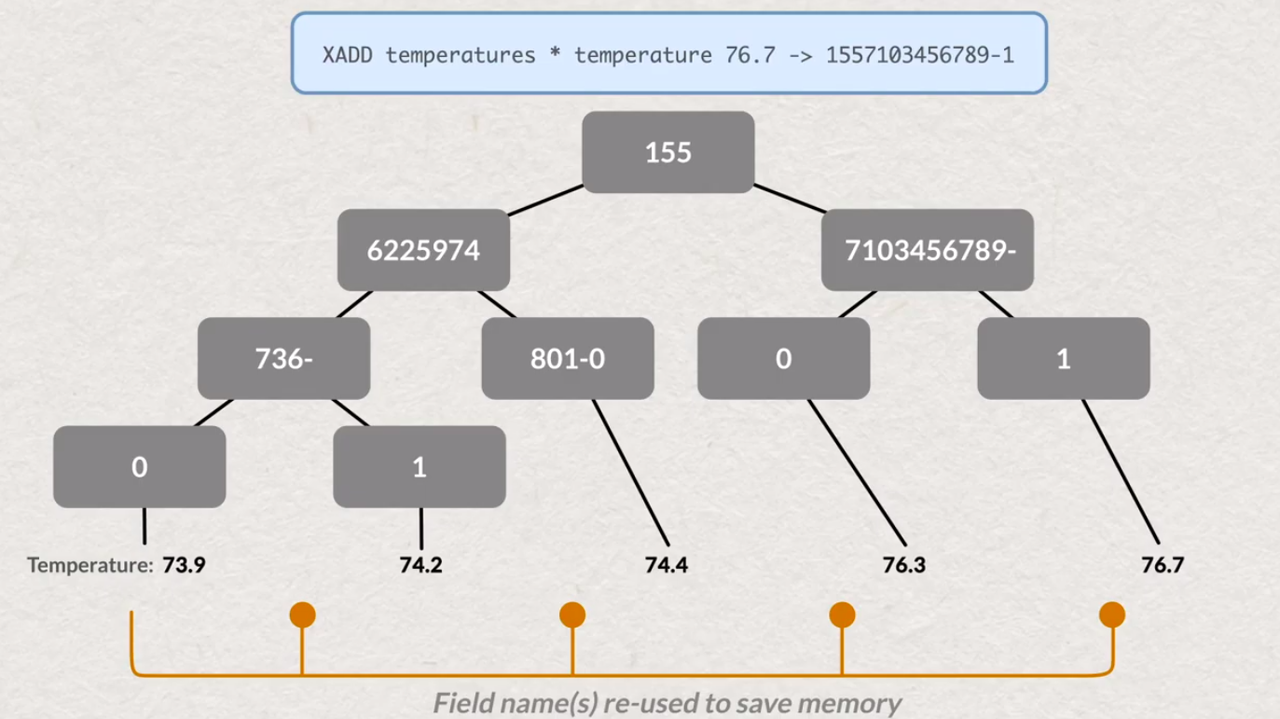
# XADD <name of stream> <unique ID, or *> <field-name> <field-value>
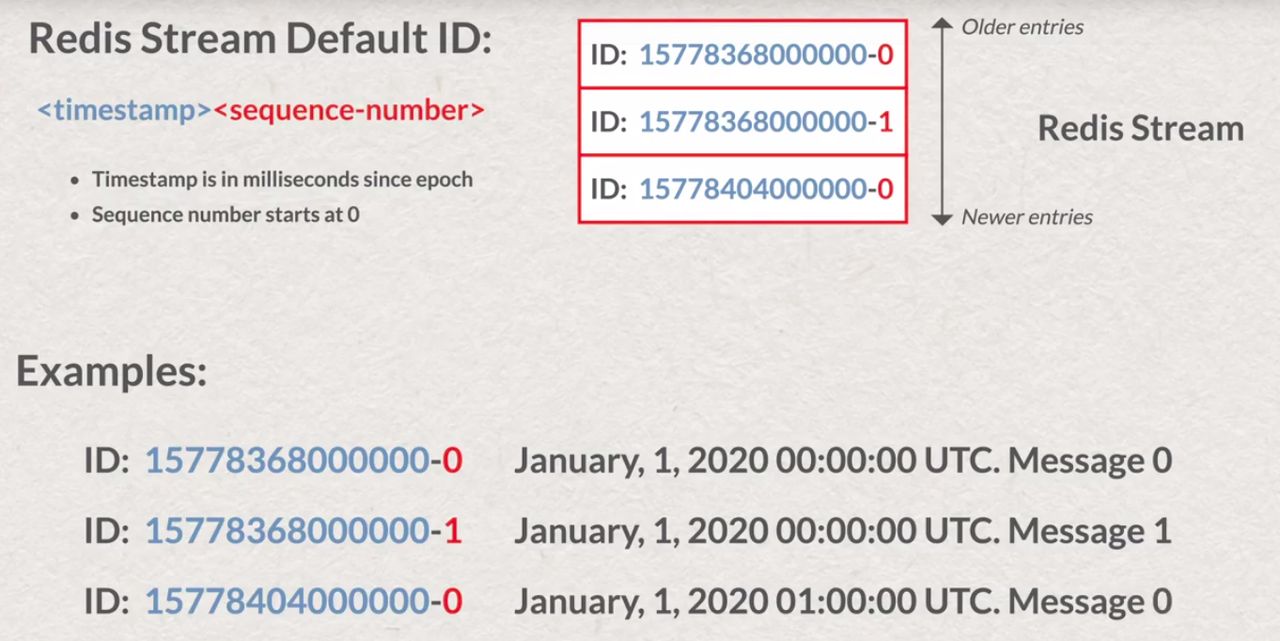
# return generated ID ( in case of * ) like "<miliseconds>-<add digit>" or specified by user ID
# XADD my-stream * my-field 0
XADD numbers * n 6
XADD numbers * n 7
# approximate size: XADD <key> MAXLEN ~ <maxlen of stream > <unique ID, or *> <field-name> <field-value>
XADD numbers MAXLEN ~ 10 * n 9
# certain size: XADD <key> MAXLEN <maxlen of stream > <unique ID, or *> <field-name> <field-value>
XADD numbers MAXLEN 10 * n 9
# XDEL <stream name> ID ID...
-
STREAMS are using path compression for keys ( fieldname compression ) - less memory consumption in comparing with SET path compression
-
calculate amount of messages
# XLEN <stream name>
XLEN numbers
- print all messages
# XRANGE <stream name> - +
XRANGE numbers - +
# XREVRANGE <stream name> + -
XREVRANGE numbers + -
- read specific messages
# XREAD COUNT <count of values or -1 > STREAMS <stream-name stream-name2> <start id or 0>
# xread is waiting for last known client id, not inclusive; multistream
XREAD COUNT 1 STREAMS numbers 1570976182071-0
# XREAD BLOCK <milisec> STREAMS <stream-name> <last message id or '$' for last message> # waiting milisec (0-forever) for first new message
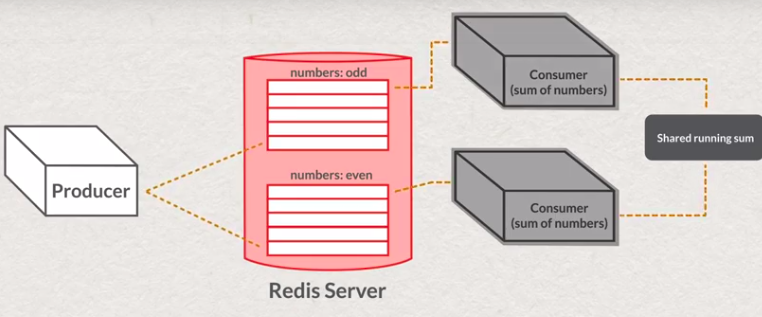


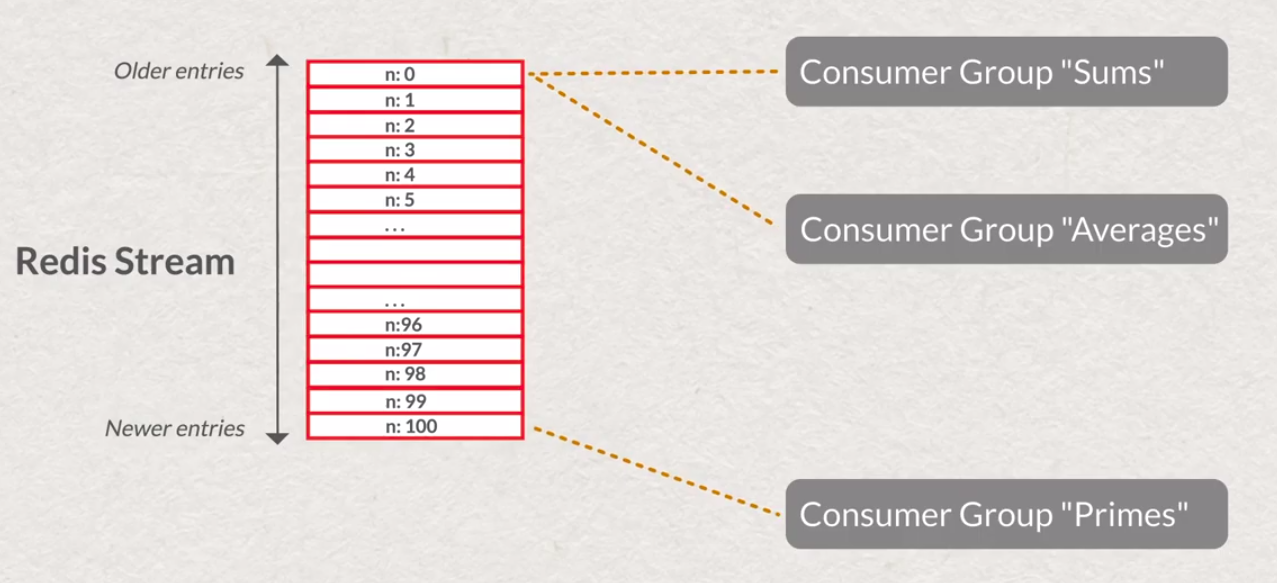
# create stream if it is not exist
XGROUP CREATE <name of stream> <name of group> <message id>
XGROUP CREATE <name of stream> <name of group> <message id> MKSTREAM
# create group, start from first message
# XGROUP CREATE my-stream my-group0 0
# create group, start from next new message
# XGROUP CREATE my-stream my-group0 $
# remove group and delete all consumers associated with group
XGROUP DESTROY <stream> <name of group>
# XGROUP DELCONSUMER <stream> <group> <user name>
XGROUP DELCONSUMER numbers numbers-group terminal-upper
# Use XPENDING and XCLAIM to identify messages that may need to be processed by other consumers and reassign them
# XREADGROUP
# read all messages from Pending Entries List ( not acknowledged )
XREADGROUP GROUP numbers-group terminal-lower STREAMS numbers 0
# read new messages ( acknowledgement is not considering )
XREADGROUP GROUP numbers-group terminal-lower STREAMS numbers >
# read new messages ( switch off acknowledgement )
# The message delivery semantics will change from at-least-once to at-most-once.
# Redis will consider all messages returned by XREADGROUP to be acknowledged.
XREADGROUP GROUP numbers-group NOACK terminal-lower STREAMS numbers >
# read messages from stream <numbers> with group <numbers-group> with consumerA and after messageID ( non inclusive ) 1570997593499-0
XREADGROUP GROUP numbers-group consumerA STREAMS numbers 1570997593499-0
# read with waiting for new
XREADGROUP GROUP numbers-group terminal-lower COUNT 1 BLOCK 1000 STREAMS numbers 1570976183500
# read new messages with waiting for 1000 miliseconds ( acknowledgement is not considering )
XREADGROUP GROUP numbers-group terminal-lower COUNT 1 BLOCK 1000 STREAMS numbers >
- Pending Entries List
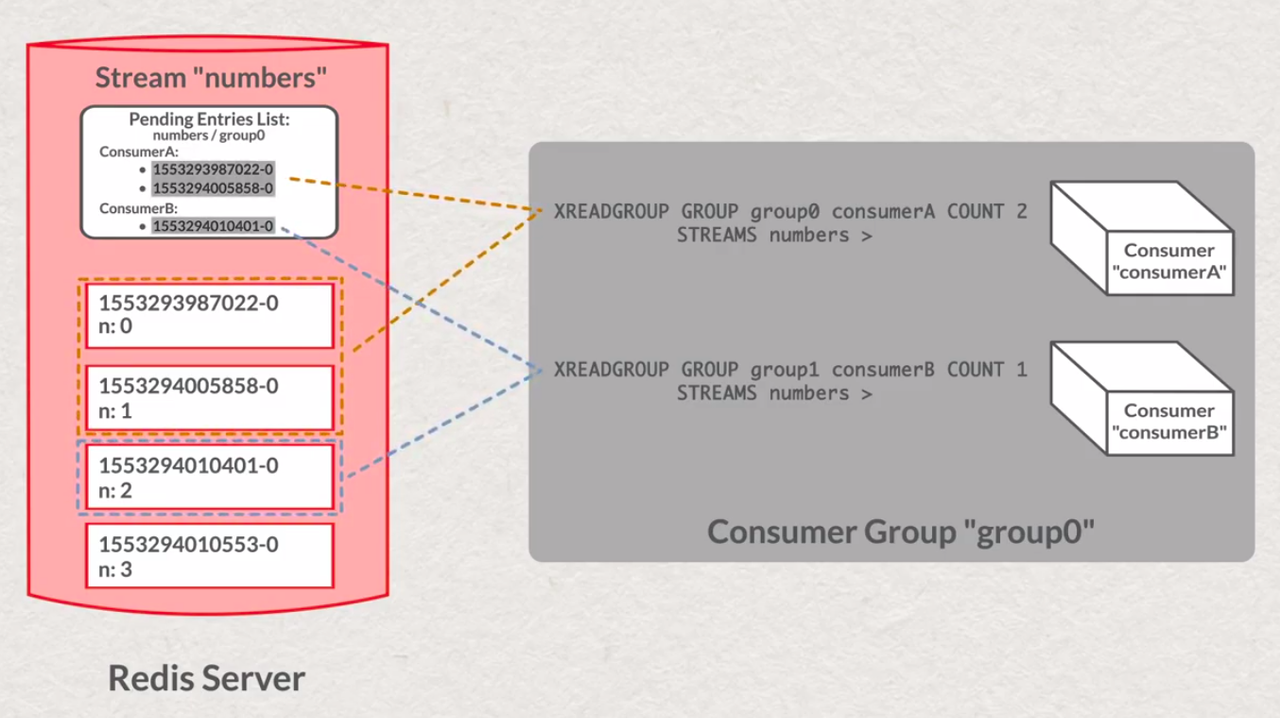
for adding consumer to ConsumerGroup (create consumer) - just read message via XREADGROUP, automatically will be created Pending Entries List ( if NOACK not applied )
for removing consumer ( also Pending Entries List will be removed)
- review pending messages
- list of consumers with pending messages
# XPENDING <stream name> <group name>
XPENDING numbers numbers-group
- list of messages that pending by consumer
# XPENDING <stream name> <group name> <begin> <end> <count>
XPENDING numbers numbers-group - + 3
# XPENDING <stream name> <group name> <begin> <end> <count> <consumer>
XPENDING numbers numbers-group - + 3 terminal-lower
- re-assign message to another consumer
XPENDING numbers numbers-group
1) (integer) 9
2) "1570976179060-0"
3) "1571005063764-0"
4) 1) 1) "consumerC"
1) "1"
1) 1) "terminal-lower"
1) "8"
XPENDING numbers numbers-group - + 3
1) 1) "1570976179060-0"
2) "terminal-lower"
3) (integer) 451374622
4) (integer) 1
2) 1) "1570976182075-0"
2) "terminal-lower"
3) (integer) 451372154
4) (integer) 1
3) 1) "1570976183508-0"
2) "terminal-lower"
3) (integer) 451371190
4) (integer) 1
# re-assing one of the message that belong to <consumer-1> to <consumer-2>
XCLAIM numbers numbers-group consumerC 1000 1570976182075-0
XPENDING numbers numbers-group
1) (integer) 9
2) "1570976179060-0"
3) "1571005063764-0"
4) 1) 1) "consumerC"
2) "2"
2) 1) "terminal-lower"
2) "7"
- message acknowledges, removing from entry from Pending Entries List by certain customer
# XACK <key of stream> <name of the group> <messageID>
XACK numbers numbers-group 1570976179060-0
- change last-delivered-id for group
# XGROUP SETID <stream name> <group name> <message id>
XGROUP SETID numbers numbers-group 0
XGROUP SETID numbers numbers-group $
# XTRIM <stream name> MAXLEN <length of latest messages in stream >
# more memory efficiency optimization
# XTRIM <stream name> MAXLEN ~ <length of latest messages in stream >
# trimming after adding value
# XTRIM <stream name> MAXLEN ~ <length of latest messages in stream > <ID or *> <field-name> <field-value>
- data structure ( reading can be blocked and non-blocking )
- acts like append-only list ( immutable, order cannot be changed)
- each entries are hashes ( immutable )
- entries have unique ID - time entries
- supports ID-based range queries
- fan-out



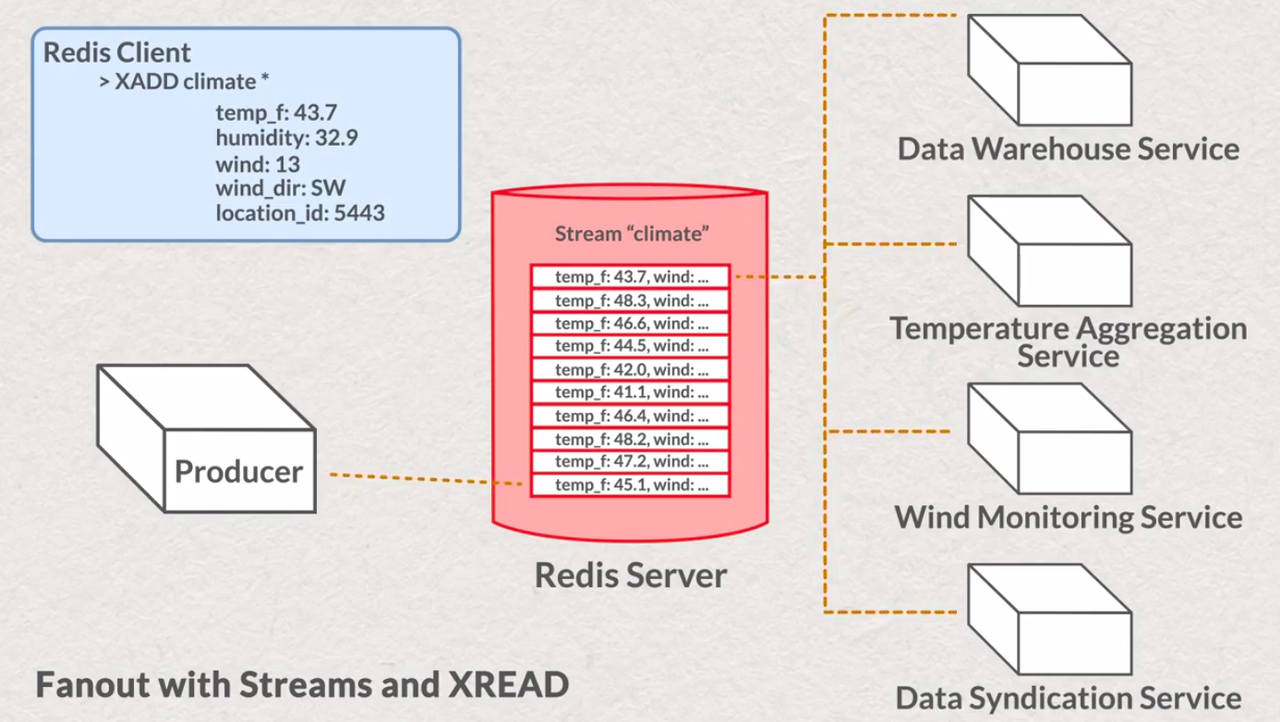
# add TimeSeries values
TS.ADD sites:ts:1:tempC 1562707932573 18.0
TS.ADD sites:ts:1:tempC 1562707992573 18.5
TS.ADD sites:ts:1:tempC 1562708052573 19.0
TS.ADD sites:ts:1:tempC 1562708152573 19.5
# retrieve values by timerange
TS.RANGE sites:ts:1:tempC 1562707932573 1562708152573
# retrieve values by timerange with aggregation
TS.RANGE sites:ts:1:tempC 1562707932573 1562708152573 AGGREGATION AVG 120000
MODULE LOAD ./redisearch.so
module list # ft- creating index
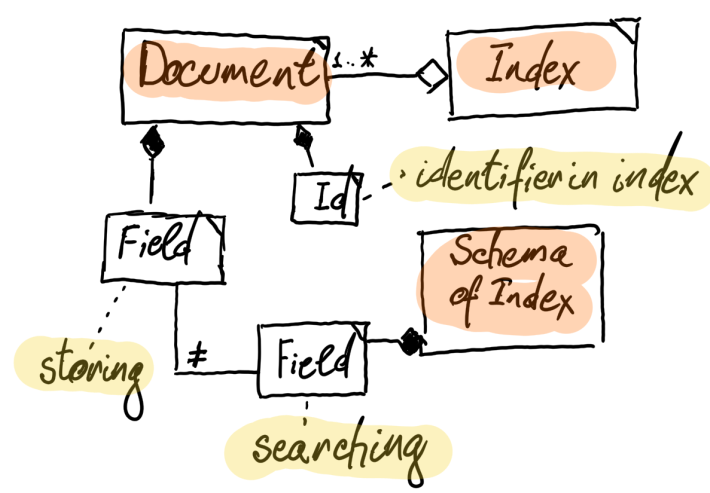
FT.CREATE <index-name> [index level arguments] SCHEMA <name type options> <name type options> <...>
criterias:
- Indexed field == queryable
- All or Some fields
- Duplicate values across fields
- Value vs Ambiguity
- Space vs Flexibility limits:
- up to 1024 fields
- up to 128 text fields
- find fields in index, get field types
# keys ft:<name of index>/<field prefix>*
keys ft:permits/neig*
type ft:permits/neighbourhood # ft_invidx - textual index or tag
-
creating index arguments, creating index options
- STOPWORDS
# FT.CREATE <index name> STOPWORDS 2 <stop-word1> <stop-word2> SCHEMA <index field name> text FT.CREATE my-fields STOPWORDS 4 and or xor not SCHEMA field-names text - NOFIELDS - will search through all text fields, not only for specific one
# FT.CREATE <index name> NOFIELDS SCHEMA <field name> <type> <field name> <type> FT.CREATE my-index NOFIELDS SCHEMA fname TEXT lname TEXT age NUMERIC # will return "my-search-value" from all text fields, not only from fname FT.SEARCH my-index "@fname:my-search-value" - SORTABLE - additional argument SORTBY ASC|DESC can be applied to search query can be used for: text, tag, numeric
- SORTABLE NOINDEX - can be used only for sorting, not for querying
FT.CREATE my-index SCHEMA my-field NUMERIC SORTABLE NOINDEX my-field2 TEXT # next query will always return empty results - field is not searchable FT.SEARCH my-index "@my-field:[-inf +inf]" # next query can return some results FT.SEARCH my-index "@my-field2:some-value" SORTBY my-field ASC - WEIGHT ( for text only ) for increasing weight in return result
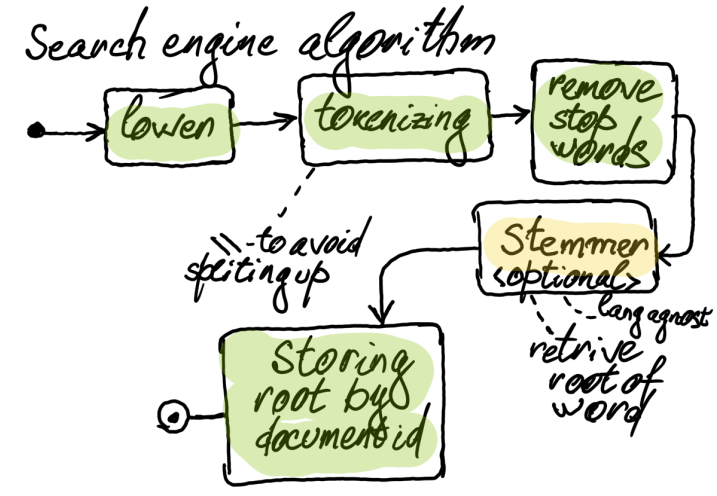
... SCHEMA my-field TEXT WEIGHT 3.0- NOSTEM ( for text only ) not using root-word diversity ( only matching by exact value )
... SCHEMA my-field TEXT NOSTEM- TAG SEPARATOR - separator between tags
... FT.CREATE <index name> SCHEMA <field name> TAG {SORTABLE} - STOPWORDS
-
changing existing
FT.ALTER all already have added documents will not be changed -
drop index, remove index, delete index
FT.DROP <index name> -
add value to index, adding value to index
# FT.ADD <index name> <document id> <score> FIELDS <field name> <field value> <field name> <field value> # FT.ADD <index name> <document id> <score> <options> FIELDS <field name> <field value> <field name> <field value> FT.ADD my-fields math-expressions 1 FIELDS field_names "ln 10 and sin 2.5 and cos 1" # re-index document FT.ADD my-fields math-expressions 1 FIELDS REPLACE field_names "ln 10 and sin 2.5 and cos 1" # if a field is not a part of the schema (NOINDEX) - no re-index; if field is SORTABLE - sort will be updated FT.ADD my-fields math-expressions 1 FIELDS REPLACE PARTIAL field_names "ln 10 and sin 2.5 and cos 1" # index document with force without saving fields FT.ADD my-fields math-expressions 1 FIELDS NOSAVE field_names "ln 10 and sin 2.5 and cos 1" # specify a language FT.ADD my-fields math-expressions 1 FIELDS LANGUAGE Russian field_names "ln 10 and sin 2.5 and cos 1" -
read element from index
# retrieve all fields, synonym is HGETALL FT.GET <index name> <document id> # retrieve ManyDocuments FT.MGET <index name> <document id> < document id > -
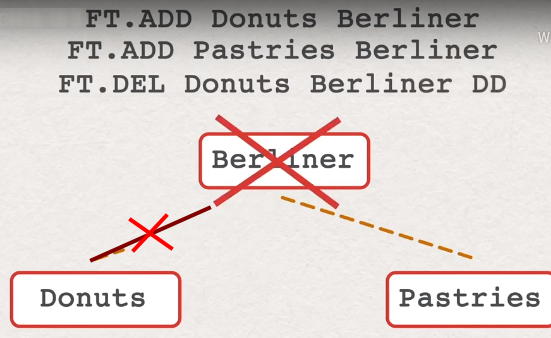
remove value from index
- problem of deletion
- document is marking for deletion, not removing immediately
- removing is executing in separate thread
# delete document from index but underlying hash is not FT.DEL <index> <document ID> # delete also related hash map FT.DEL <index> <document ID> DD- one document can belonds to two indexes one document two indexes
-
sysnonyms https://oss.redislabs.com/redisearch/Commands/#ftsynadd
# add synonyms, return value - id of group, index should be updated afterwards ( FT.ADD ... REPLACE ) # be aware, one synonym can belong to different groups FT.SYNADD <index name> <synonym 1> <synonym 2> <synonym 3> <synonym ...> # explaing cli will return group id for sysnonym - it starts with tilda FT.EXPLAINCLI <index name> <search request> # print all synonyms in all groups FT.SYNDUMP <index name> # update ( append )some of the group with new values FT.SYNUPDATE <index name> <group id> <additional synonym 1> < additional synonym 2> # synonym cannot be removed !!! -
advantages of using secondary indexing
- optimizing memory usage
- deals with large documents
- optimizing for high scale and speed
- flexibility by docoupling storage from index
- unify multiply data storages
-
UNLINK, DEL, TTL not affected index
-
only RedisEnterprise can cluster RediSearch ( not compatible with Redis Cluster )
-
RediSearch - one index per database ( documents are living there with document ID - unique in one DB)
-
field types for indexing:
- text ( human language )
- numeric ( numbers, timestamps )
- tag ( collection of flags/words, no stemming; flags or enums )
- geo ( location )
-
-
TF-IDF - TermFrequency - Inverse Document Frequency ( default scoring mechanism )

TF-IDF = 1 + ln( number of documents / ( 1 + documents with term ) )
Document Score = "amount of words" * TF-IDF
- explain query cli
# FT.EXPLAINCLI <index> <query>
- search examples
- simple search ( INTERSECT by default - boolean and )
# FT.SEARCH <index> <query> LIMIT <offset> <count> # use explanation to understand what is going on under the hood # FT.EXPLAINCLI permits garage LIMIT 0 0 # number of documents, without results FT.SEARCH permits garage LIMIT 0 0 # OR condition ( UNION ) FT.SEARCH permits garage|carport LIMIT 0 0 # AND condition ( INTERSECT ) FT.SEARCH permits "garage carport" LIMIT 0 0- AND condition with NOT ( INTERSECT NOT)
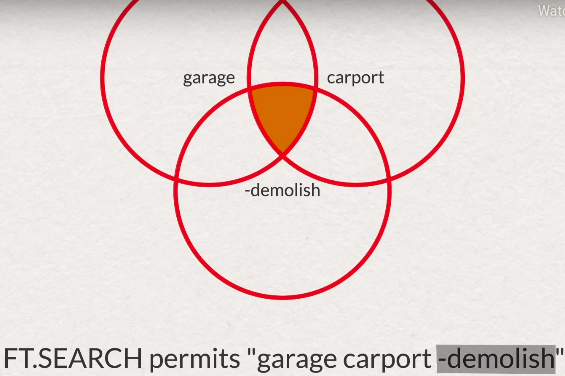
# AND condition with NOT FT.SEARCH permits "garage carport -government" LIMIT 0 0- wildchar
FT.SEARCH permits car*- optional search ( OPTIONAL ), increase score of document ( boost up document weights in return result )
FT.SEARCH permits "garage ~kiosk"- certain search, multi word search ( EXACT )
FT.SEARCH permits "\"big yellow garage\""- levenstein search with distance 1
FT.SEARCH permits "%lock%"- parens
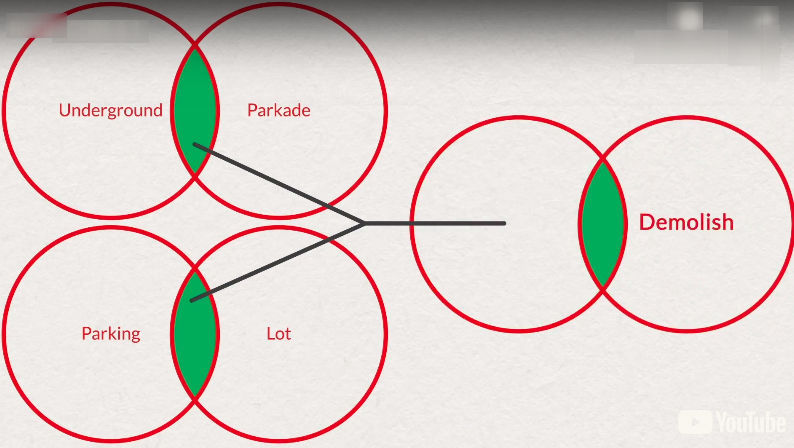
FT.SEARCH permits "(underground parkade)|(parking lot)"# image above FT.SEARCH permits "(underground parkade)|(parking lot) demolish" # or with not FT.SEARCH permits "(underground parkade)|(parking lot) -demolish" FT.SEARCH permits "(underground parkade)|(parking lot) -(demolish|remove)"- field search, specify field name for search ( not across all fields )
FT.SEARCH permits "@building_type:new @description:construction"- AND
FT.SEARCH permits "@building_type:new @description:construction" - OR
FT.SEARCH permits "@building_type:new @description:construction|done" FT.SEARCH permits "(@building_type:new @description:construction) | (@building_type:new @description:fdone)" - SLOP
- text only
- limit to field ( otherwise all fields will be considered like one text line )
FT.SEARCH slop-fox "@phrase: (brown lazy john)" SLOP 5 # more strict - order should be the same FT.SEARCH permits "retail construction" SLOP 5 INORDER - search with numeric fields
FT.SEARCH permits "@construction_value:[1 300]" LIMIT 0 0 FT.SEARCH permits "@construction_value:[1 (300]" LIMIT 0 0 FT.SEARCH permits "@construction_value:[1 300]|@description:in_process" LIMIT 0 0 FT.SEARCH permits "@construction_value:[10 300]|@description:in_process" LIMIT 0 0 # find certain numeric number - low/high ranges are equals FT.SEARCH permits "@construction_value:[1000 1000] demolish garage" LIMIT 0 0- TAG
# example of querying by tag FT.SEARCH permits @zoning:{rf1} # print all available tags FT.TAGVALS permits zoning- AND
FT.SEARCH permits "@zoning:{rf1} @zoning:{rf1}"- OR
FT.SEARCH permits @zoning:{rf1|rf6}- NOT
FT.SEARCH permits "@zoning:{AGU} @zoning:{DC2} -@zoning:{PU|CSC|US}"- GEO
value in field: [longitude latitude radius m|km|mi|ft ]
FT.SEARCH permits "@location:[-113.477 53.558 1 km]" LIMIT 0 0 FT.SEARCH permits "@location:[-113.50125915402455, 53.57593507222605 1 km] @neighbourhood:{Westwood|Eastwood}" LIMIT 0 0- SORTBY ( field must be marked as SORTABLE )
FT.SEARCH permits "retail construction" HIGHLIGHTS SORTBY my-sortable-field ASC LIMIT 0 1- SUMMARIZE
- LEN - amount of words to be output
- FRAGS - amount of fragments
- SEPARATOR - sepearator for fragments
- RETURN - list of fields to be returned
- HIGHLIGHT - wrap results with markers
FT.SEARCH permits "work" RETURN 1 description FT.SEARCH permits "work" RETURN 2 description location FT.SEARCH permits "work" RETURN 1 description SUMMARIZE FIELDS 1 description FRAGS 1 LEN 5 SEPARATOR , FT.SEARCH permits "work" RETURN 1 description SUMMARIZE FIELDS 1 description FRAGS 1 LEN 5 SEPARATOR , HIGHLIGHT TAGS <strong> </strong> FT.SEARCH permits "work" RETURN 1 description SUMMARIZE FIELDS 1 description FRAGS 1 LEN 5 SEPARATOR , HIGHLIGHT TAGS <strong> </strong> LIMIT 100 5 - HIGHLIGHTS
FT.SEARCH permits "retail construction" HIGHLIGHTS FT.SEARCH permits "retail construction" HIGHLIGHTS LIMIT 0 1 FT.SEARCH permits "retail construction" HIGHLIGHTS FIELDS description FT.SEARCH permits "retail construction" HIGHLIGHTS FIELDS description TAGS <strong> </strong> FT.SEARCH permits "retail construction" HIGHLIGHTS FIELDS 1 description TAGS "<strong>" "</strong>" FT.SEARCH permits "retail construction" HIGHLIGHTS FIELDS 1 description TAGS "<strong>" "</strong>" RETURN 1 description- autocomplete, suggestion - special dictionary, separate type not belong to index
# add suggestion, return amount of elements that already inside FT.SUGADD <key> <typed query, case insensitive> <score> # update score (summarize with existing) of suggestion, if exists; remove PAYLOAD without specifying - UseCase: feedback from user that it is searchable query FT.SUGADD <key> <typed query, icase> <score> INCR # save additional information with specific case ( WITHPAYLOADS will return it ) FT.SUGADD <key> <typed query, icase> <score> PAYLOAD <return value for query># return up to 5 suggestions FT.SUGGET <key> <query> # specify amount of return values - up to 10 return values FT.SUGGET <key> <query> MAX 10 # add Levenshtein distance 1 FT.SUGGET <key> <query> FUZZY # return also saved payload ( if was ) FT.SUGGET <key> <query> WITHPAYLOADSFT.SUGLEN <key>FT.SUGDEL <key> <query> UNLINK <key>




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}