How to use better OOP in python.
Best practices programming python classes - a great lecture.
How to know pip packages size’ good for removal
Import click - command line interface
Concurrency vs Parallelism (great)
Async io
Clean code:
- Guide to pyenv & pyenv virtualenv
- Managing virtual env with pyenv
- Just use venv
- Summary on all the *envs
- A really good primer on virtual environments
- Introduction to venv complementary to the above
- Pipenv
- A great intro to pipenv
- A complementary to pipenv above
- Comparison between all *env
Pyenv tutorial and finding where it is ****
Pyenv override system python on mac
- Cloud GPUS cheap
- Importing a notebook as a module
- Important colaboratory commands for jupytr
- Timing and profiling in Jupyter
- (Debugging in Jupyter, how?) - put a one liner before the code and query the variables inside a function.
- 28 tips n tricks for jupyter
- Jupyter notebooks as a module
- Virtual environments in jupyter
- Enter your project directory
- $ python -m venv projectname
- $ source projectname/bin/activate
- (venv) $ pip install ipykernel
- (venv) $ ipython kernel install --user --name=projectname
- Run jupyter notebook * (not entirely sure how this works out when you have multiple notebook processes, can we just reuse the same server?)
- Connect to the new server at port 8889
- Virtual env with jupyter
(how does reshape work?) - a shape of (2,4,6) is like a tree of 2->4 and each one has more leaves 4->6.
As far as i can tell, reshape effectively flattens the tree and divide it again to a new tree, but the total amount of inputs needs to stay the same. 2*4*6 = 4*2*3*2 for example
code:
import numpy rng = numpy.random.RandomState(234) a = rng.randn(2,3,10) print(a.shape) print(a) b = numpy.reshape(a, (3,5,-1)) print(b.shape) print (b)
*** A tutorial for Google Colaboratory - free Tesla K80 with Jup-notebook
How to add extensions to jupyter: extensions
Connecting from COLAB to MS AZURE
Streamlit vs. Dash vs. Shiny vs. Voila vs. Flask vs. Jupyter
- Optimization problems, a nice tutorial to finding the minima
- Minima / maxima finding it in a 1d numpy array
Using numpy efficiently - explaining why vectors work faster.
Fast vector calculation, a benchmark between list, map, vectorize. Vectorize wins. The idea is to use vectorize and a function that does something that may involve if conditions on a vector, and do it as fast as possible.
- Great introductory tutorial about using pandas, loading, loading from zip, seeing the table’s features, accessing rows & columns, boolean operations, calculating on a whole row\column with a simple function and on two columns even, dealing with time\date parsing.
- Visualizing pandas pivoting and reshaping functions by Jay Alammar - pivot melt stack unstack
- How to beautify pandas dataframe using html display
- Speeding up pandas
- Pandas summary
- Pandas html profiling
- The fastest way to select rows by columns, by using masked values (benchmarked):
- def mask_with_values(df): mask = df['A'].values == 'foo' return df[mask]
- Parallelism, pools, threads, dask
- Accessing dataframe rows, columns and cells- by name, by index, by python methods.
- Looping through pandas
- How to inject headers into a headless CSV file -
- Dealing with time series in pandas,
- Create a new column based on a (boolean or not) column and calculation:
- Using python (map)
- Using numpy
- using a function (not as pretty)
- Given a DataFrame, the shift() function can be used to create copies of columns that are pushed forward (rows of NaN values added to the front) or pulled back (rows of NaN values added to the end).
- df['t'] = [x for x in range(10)]
- df['t-1'] = df['t'].shift(1)
- df['t-1'] = df['t'].shift(-1)
- Row and column sum in pandas and numpy
- Dataframe Validation In Python - A Practical Introduction - Yotam Perkal - PyCon Israel 2018
- In this talk, I will present the problem and give a practical overview (accompanied by Jupyter Notebook code examples) of three libraries that aim to address it: Voluptuous - Which uses Schema definitions in order to validate data [https://github.com/alecthomas/voluptuous] Engarde - A lightweight way to explicitly state your assumptions about the data and check that they're actually true [https://github.com/TomAugspurger/engarde] * TDDA - Test Driven Data Analysis [ https://github.com/tdda/tdda]. By the end of this talk, you will understand the Importance of data validation and get a sense of how to integrate data validation principles as part of the ML pipeline.
- Stop using itterows, use apply.
- (great) Group and Aggregate by One or More Columns in Pandas
- Pandas Groupby: Summarising, Aggregating, and Grouping data in Python
- Pipeline to json 1, 2
- cuML - Multi gpu, multi node-gpu alternative for SKLEARN algorithms
- Gpu TSNE ^
- Awesome code examples about using svm\knn\naive\log regression in sklearn in python, i.e., “fitting a model onto the data”
- Parallelism of numpy, pandas and sklearn using dask and clusters. Webpage, docs, example in jupyter.
Also Insanely fast, see here.
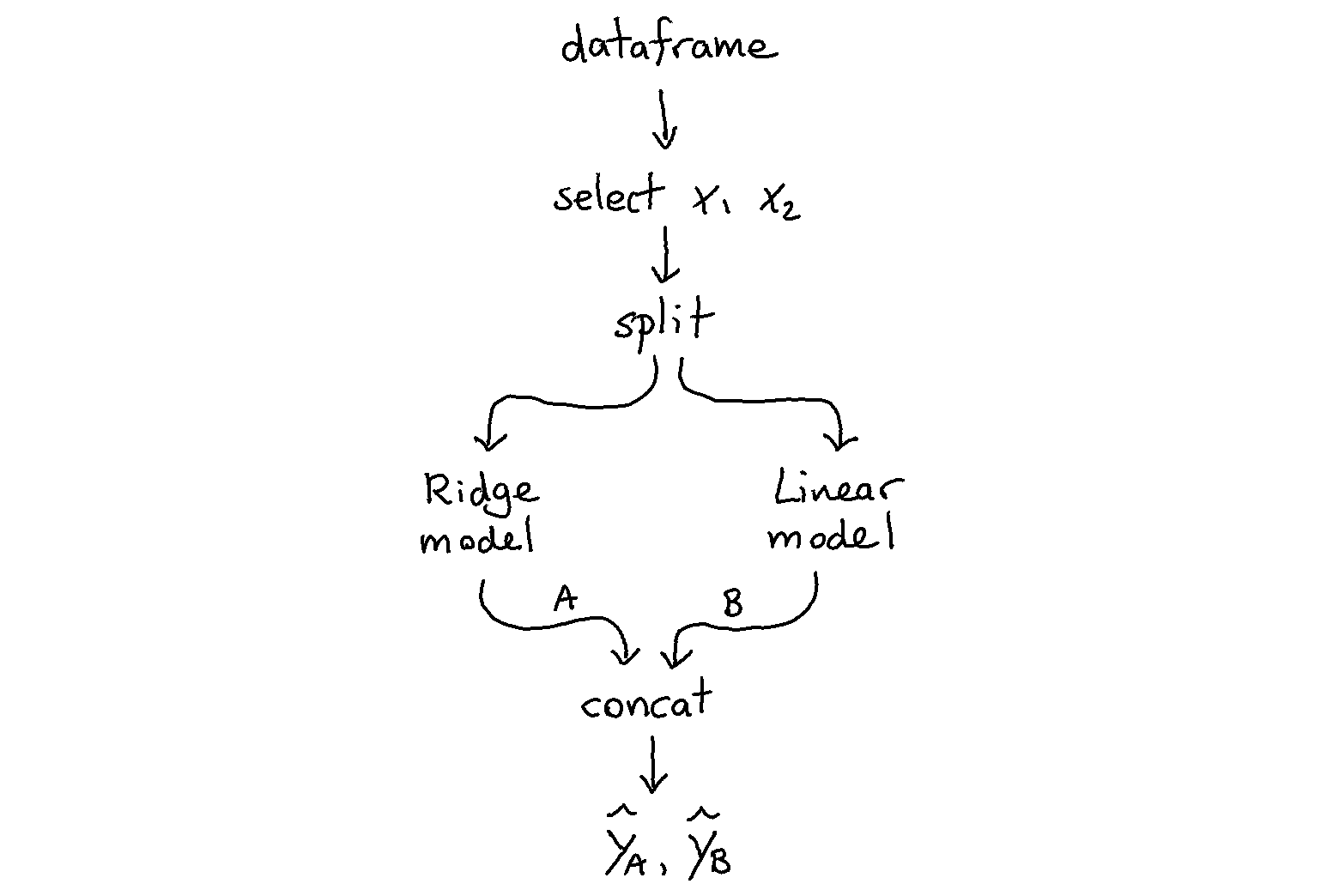
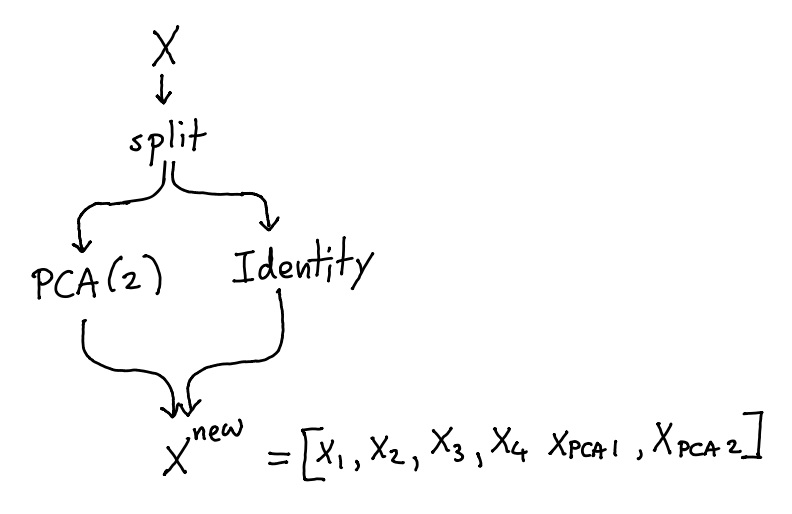
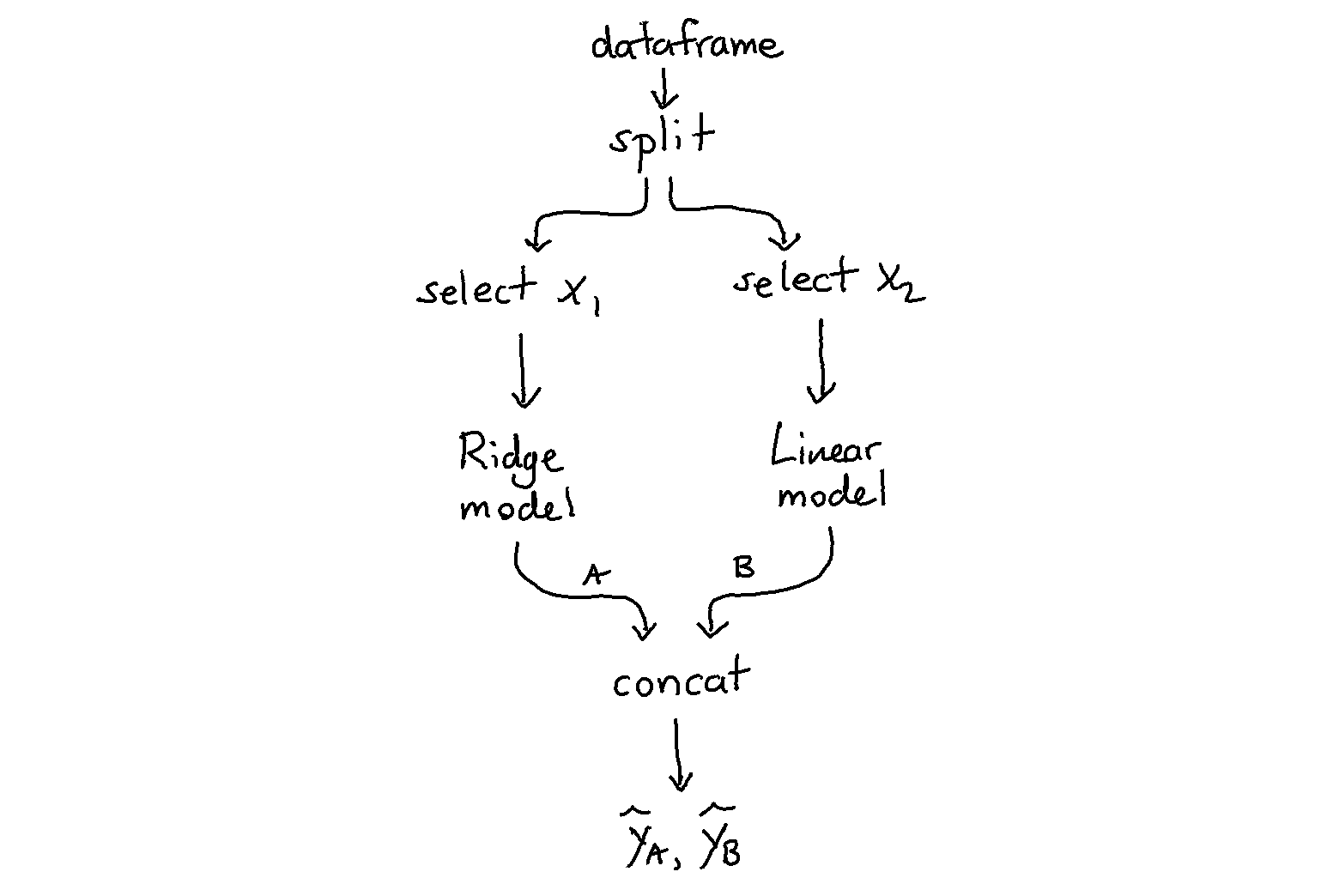
- Functional api for sk learn, using pipelines. thank you sk-lego.
- Medium on all fast.ai courses, 14 posts
1. What is? by vidhaya - PyCaret is an open-source, machine learning library in Python that helps you from data preparation to model deployment. It is easy to use and you can do almost every data science project task with just one line of code.
- Install TF
- Install cuda on ubuntu, official linux
- Replace cuda version ****
- Cuda 9 download
- Install cudnn
- Installing everything easily
- Failed to initialize NVML: Driver/library version mismatch
Resize google disk size, 1, ****2,