English| 简体中文
Alink is the Machine Learning algorithm platform based on Flink, developed by the PAI team of Alibaba computing platform. Welcome everyone to join the Alink open source user group to communicate.


- Make sure the version of python3 on your computer >=3.5
- Download the corresponding pyalink package according to the Python version:
- Install using
easy_install [path]/pyalink-0.0.1-py3.*.egg. have to be aware of is:- If you have previously installed pyalink, use pip uninstall pyalink to uninstall the previous version before install command.
- If you have multiple versions of Python, you may need to use a specific version of easy_install, such as easy_install-3.7.
- If Anaconda is used, you may need to install the package in Anaconda prompt.
We recommend using Jupyter Notebook to use PyAlink to provide a better experience.
Steps for usage:
-
Start Jupyter:
jupyter notebookin terminal , and create Python 3 notebook. -
Import the pyalink package:
from pyalink.alink import *. -
Use this command to create a local runtime environment:
useLocalEnv(parallism, flinkHome=None, config=None).Among them, the parameter
parallismindicates the degree of parallelism used for execution;flinkHomeis the full path of flink,and the default flink-1.9.0 path of PyAlink is used;configis the configuration parameter accepted by Flink. After running, the following output appears, indicating that the initialization of the running environment is successful.
JVM listening on ***
Python listening on ***
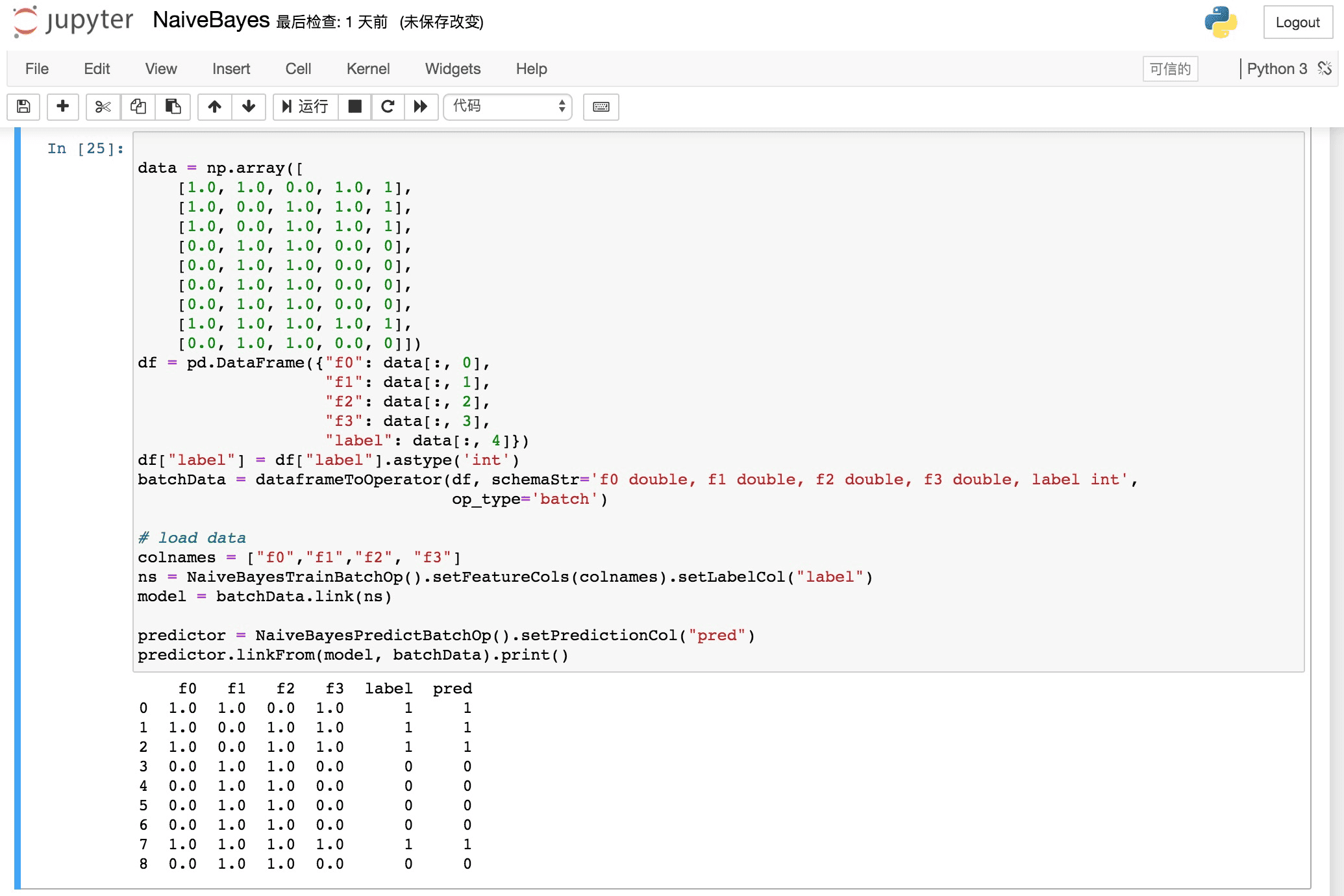
- Start writing PyAlink code, for example:
source = CsvSourceBatchOp()\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")\
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/iris.csv")
res = source.select("sepal_length", "sepal_width")
df = res.collectToDataframe()
print(df)
In PyAlink, the interface provided by the algorithm component is basically the same as the Java API, that is, an algorithm component is created through the default construction method, then the parameters are set through setXXX, and other components are connected through link / linkTo / linkFrom.
Here, Jupyter's auto-completion mechanism can be used to provide writing convenience.
For batch jobs, you can trigger execution through methods such as print / collectToDataframe / collectToDataframes of batch components or BatchOperator.execute (); for streaming jobs, start the job with StreamOperator.execute ().
Q: Can I connect to a remote Flink cluster for computation?
A: You can connect to a Flink cluster that has been started through the command: useRemoteEnv(host, port, parallelism, flinkHome=None, localIp="localhost", shipAlinkAlgoJar=True, config=None).
-
hostandportrepresent the address of the cluster; -
parallelismindicates the degree of parallelism of executing the job; -
flinkHomeis the full path of flink. By default, the flink-1.9.0 path that comes with PyAlink is used. -
localIpspecifies the local IP address required to implement the print preview function of FlinkDataStream, which needs to be accessible by the Flink cluster. The default islocalhost. -
shipAlinkAlgoJarWhether transmits the Alink algorithm package provided by PyAlink to the remote cluster. If the Alink algorithm package has been placed in the remote cluster, it can be set to False to reduce data transmission.
Q: How to stop long running Flink jobs?
A: When using the local execution environment, just use the Stop button provided by Notebook.
When using a remote cluster, you need to use the job stop function provided by the cluster.
Q: Can I run it directly using Python scripts instead of Notebook?
A: Yes. But you need to call resetEnv () at the end of the code, otherwise the script will not exit.
- Prepare a Flink Cluster:
wget https://archive.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.11.tgz
tar -xf flink-1.9.0-bin-scala_2.11.tgz && cd flink-1.9.0
./bin/start-cluster.sh
- Build Alink jar from the source:
git clone https://github.com/alibaba/Alink.git
cd Alink && mvn -Dmaven.test.skip=true clean package shade:shade
- Run Java examples:
./bin/flink run -p 1 -c com.alibaba.alink.ALSExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar
# ./bin/flink run -p 2 -c com.alibaba.alink.GBDTExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar
# ./bin/flink run -p 2 -c com.alibaba.alink.KMeansExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar