




Highlights • Overview • Install • Getting Started • Documentation • Tutorial • Contributing • Release Notes
GNES [jee-nes] is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form.
| GNES is all-in-microservice! Encoder, indexer, preprocessor and router are all running in their own containers. They communicate via versioned APIs and collaborate under the orchestration of Docker Swarm/Kubernetes etc. Scaling, load-balancing, automated recovering, they come off-the-shelf in GNES. | How long would it take to deploy a change that involves just switching a layer in VGG? In GNES, this is just one line change in a YAML file. We abstract the encoding and indexing logic to a YAML config, so that you can change or stack encoders and indexers without even touching the codebase. | Taking advantage of fast-evolving AI/ML/NLP/CV communities, we learn from best-of-breed deep learning models and plug them into GNES, making sure you always enjoy the state-of-the-art performance. |
| Searching for texts, image or even short-videos? Using Python/C/Java/Go/HTTP as the client? Doesn't matter which content form you have or which language do you use, GNES can handle them all. | When built-in models do not meet your requirments, simply build your own with one Python file and one YAML file. No need to rebuilt GNES framework, as your models will be loaded as plugins and directly rollout online. | We love to learn the best practice from the community, helping our GNES to achieve the next level of availability, resiliency, performance, and durability. If you have any ideas or suggestions, feel free to contribute. |

There are two ways to get GNES, either as a Docker image or as a PyPi package.
✅ For cloud users, we highly recommend using GNES via Docker image.
We provide GNES as a Docker image to simplify the installation. The Docker image is built with GNES full dependencies, so you can run GNES out-of-the-box.
via Docker cloud
docker run gnes/gnes:latestThis command downloads the latest GNES image and runs it in a container. When the container runs, it prints an informational message and exits.
We also provide a public mirror hosted on Tencent Cloud, from which Chinese mainland users can pull the image faster.
docker login --username=xxx ccr.ccs.tencentyun.com # login to Tencent Cloud so that we can pull from it
docker run ccr.ccs.tencentyun.com/gnes/gnes:latest💡 Please note that version
latestrefers to the latest master of this repository, which is mutable and may not always be a stable. Therefore, we recommend you to use an official release by changing thelatestto a version tag, sayv0.0.24.
You can also install GNES as a Python package via:
pip install gnesNote that this will only install a "barebone" version of GNES, consists of the minimal dependencies for running GNES, i.e. no third-party pretrained models, deep learning/NLP/CV packages are installed. We make this setup as the default installation behavior as in GNES models serve as plugins, and a model interested to NLP engineers may not be interested to CV engineers.
To enable the full functionalities and dependencies, you may install GNES via:
pip install gnes[all]🍒 Or cherry-picking the dependencies according to the table below:
List of cherry-picked dependencies (click to expand...)
pip install gnes[bert] | bert-serving-server>=1.8.6, bert-serving-client>=1.8.6 |
pip install gnes[flair] | flair>=0.4.1 |
pip install gnes[annoy] | annoy==1.15.2 |
pip install gnes[chinese] | jieba |
pip install gnes[vision] | opencv-python>=4.0.0, torchvision==0.3.0, imagehash>=4.0 |
pip install gnes[leveldb] | plyvel>=1.0.5 |
pip install gnes[test] | pylint, memory_profiler>=0.55.0, psutil>=5.6.1, gputil>=1.4.0 |
pip install gnes[http] | flask, flask-compress, flask-cors, flask-json, aiohttp==3.5.4 |
pip install gnes[nlp] | flair>=0.4.1, bert-serving-client>=1.8.6, bert-serving-server>=1.8.6 |
pip install gnes[cn_nlp] | bert-serving-server>=1.8.6, bert-serving-client>=1.8.6, jieba, flair>=0.4.1 |
pip install gnes[all] | bert-serving-client>=1.8.6, bert-serving-server>=1.8.6, imagehash>=4.0, gputil>=1.4.0, flask, flask-cors, flask-compress, jieba, flair>=0.4.1, opencv-python>=4.0.0, torchvision==0.3.0, pylint, aiohttp==3.5.4, psutil>=5.6.1, flask-json, plyvel>=1.0.5, annoy==1.15.2, memory_profiler>=0.55.0 |
🚸 Tensorflow, Pytorch and torchvision are not part of GNES installation. Depending on your model, you may have to install them in advance.
Either way, if you end up reading the following message after $ gnes or $ docker run gnes/gnes, then you are ready to go!

- 🐣 Preliminaries
- Build your first GNES app on local machine
- Scale your GNES app to the cloud
- Customize GNES on your need
- Take-home messages
Before we start, let me first introduce two important concepts serving as the backbone of GNES: microservice and runtime.
For machine learning engineers and data scientists who are not familiar with the concept of cloud-native and microservice, one can picture a microservice as an app (on your smartphone). Each app runs independently, and an app may cooperate with other apps to accomplish a task. In GNES, we have four fundamental apps, aka. microservices, they are:
- Preprocessor: transforming a real-world object to a list of workable semantic units;
- Encoder: representing a semantic unit with vector representation;
- Indexer: storing the vectors into memory/disk that allows fast-access;
- Router: forwarding messages between microservices: e.g. batching, mapping, reducing.
In GNES, we have implemented dozens of preprocessor, encoder, indexer to process different content forms, such as image, text, video. It is also super easy to plug in your own implementation, which we shall see an example in the sequel.
Okay, now that we have a bunch of apps, what are we expecting them to do? In a typical search system, there are two fundamental tasks: indexing and querying. Indexing is storing the documents, querying is searching the documents, pretty straightforward. In a neural search system, one may also face another task: training, where one fine-tunes an encoder/preprocessor according to the data distribution in order to achieve better search relevance. These three tasks: indexing, querying and training are what we call three runtimes in GNES.
💡 The key to understand GNES is to know which runtime requires what microservices, and each microservice does what.
Let's start with a typical indexing procedure by writing a YAML config (see the left column of the table):
| YAML config | GNES workflow (generated by GNES board) |
|---|---|
port: 5566
services:
- name: Preprocessor
yaml_path: text-prep.yml
- name: Encoder
yaml_path: gpt2.yml
- name: Indexer
yaml_path: b-indexer.yml
|

|
Now let's see what the YAML config says. First impression, it is pretty intuitive. It defines a pipeline workflow consists of preprocessing, encoding and indexing, where the output of the former component is the input of the next. This pipeline is a typical workflow of index or query runtime. Under each component, we also associate it with a YAML config specifying how it should work. Right now they are not important for understanding the big picture, nonetheless curious readers can checkout how each YAML looks like by expanding the items below.
Preprocessor config: text-prep.yml (click to expand...)
!TextPreprocessor
parameter:
start_doc_id: 0
random_doc_id: True
deliminator: "[.!?]+"
gnes_config:
is_trained: trueEncoder config: gpt2.yml (click to expand...)
!PipelineEncoder
component:
- !GPT2Encoder
parameter:
model_dir: $GPT2_CI_MODEL
pooling_stragy: REDUCE_MEAN
gnes_config:
is_trained: true
- !PCALocalEncoder
parameter:
output_dim: 32
num_locals: 8
gnes_config:
batch_size: 2048
- !PQEncoder
parameter:
cluster_per_byte: 8
num_bytes: 8
gnes_config:
work_dir: ./
name: gpt2bin-pipeIndexer config: b-indexer.yml (click to expand...)
!BIndexer
parameter:
num_bytes: 8
data_path: /out_data/idx.binary
gnes_config:
work_dir: ./
name: bindexerOn the right side of the above table, you can see how the actual data flow looks like. There is an additional component gRPCFrontend automatically added to the workflow, it allows you to feed the data and fetch the result via gRPC protocol through port 5566.
Now it's time to run! GNES board can automatically generate a starting script/config based on the YAML config you give, saving troubles of writing them on your own.
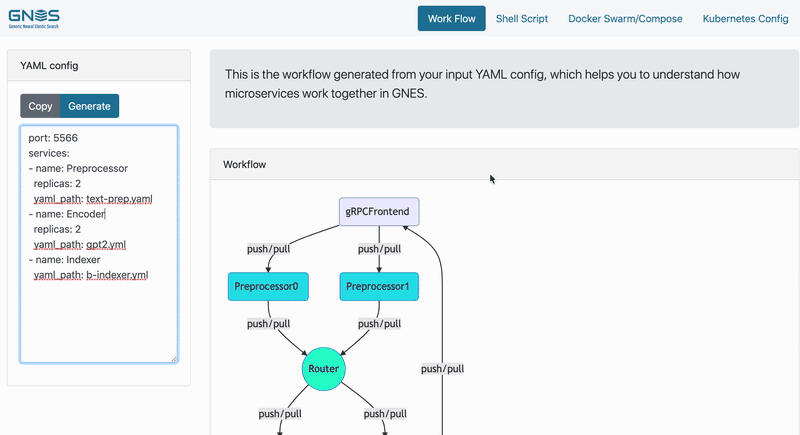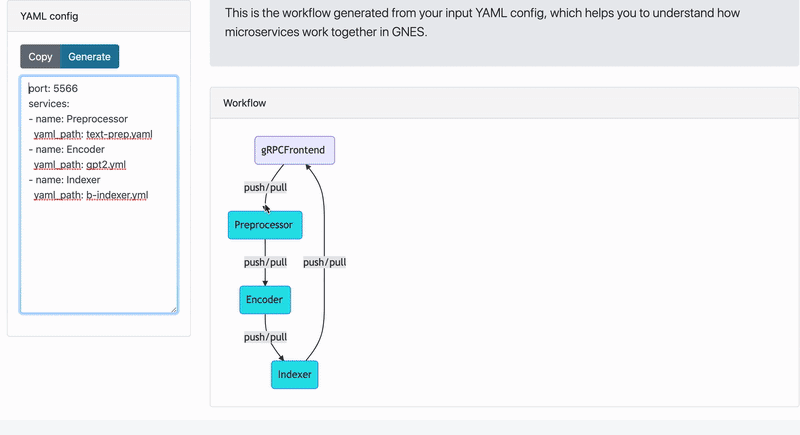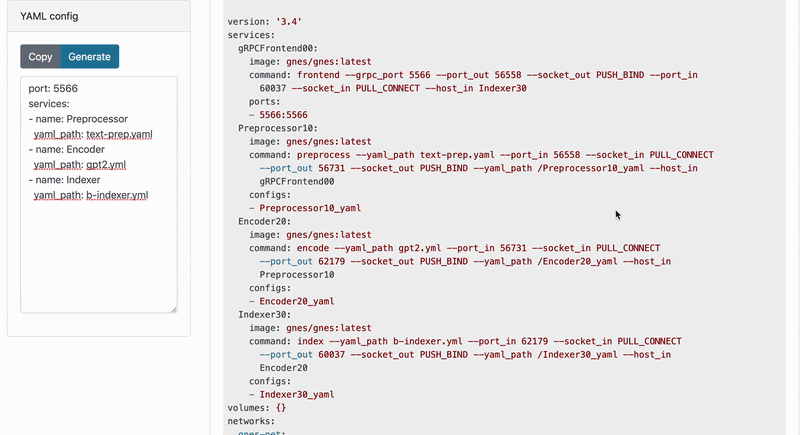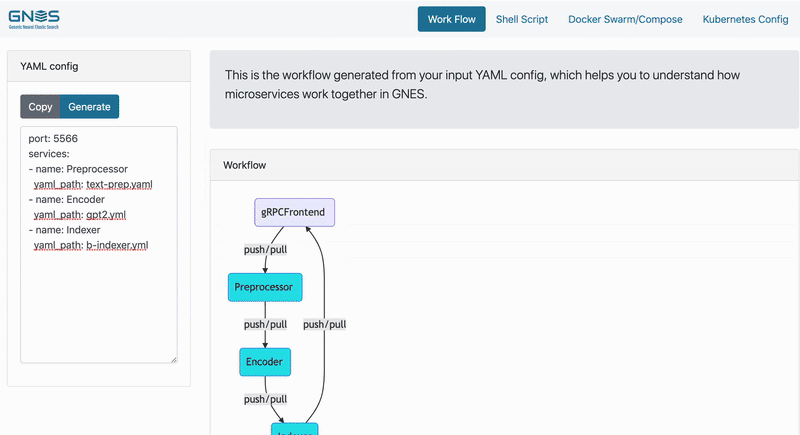
💡 You can also start a GNES board locally. Simply run
docker run -d -p 0.0.0.0:80:8080/tcp gnes/gnes compose --flask
As a cloud-native application, GNES requires an orchestration engine to coordinate all micro-services. We support Kubernetes, Docker Swarm and shell-based multi-process. Let's see what the generated script looks like in this case.
Shell-based starting script (click to expand...)
#!/usr/bin/env bash
set -e
trap 'kill $(jobs -p)' EXIT
printf "starting service gRPCFrontend with 0 replicas...\n"
gnes frontend --grpc_port 5566 --port_out 49668 --socket_out PUSH_BIND --port_in 60654 --socket_in PULL_CONNECT &
printf "starting service Preprocessor with 0 replicas...\n"
gnes preprocess --yaml_path text-prep.yml --port_in 49668 --socket_in PULL_CONNECT --port_out 61911 --socket_out PUSH_BIND &
printf "starting service Encoder with 0 replicas...\n"
gnes encode --yaml_path gpt2.yml --port_in 61911 --socket_in PULL_CONNECT --port_out 49947 --socket_out PUSH_BIND &
printf "starting service Indexer with 0 replicas...\n"
gnes index --yaml_path b-indexer.yml --port_in 49947 --socket_in PULL_CONNECT --port_out 60654 --socket_out PUSH_BIND &
waitDockerSwarm compose file (click to expand...)
version: '3.4'
services:
gRPCFrontend00:
image: gnes/gnes:latest
command: frontend --grpc_port 5566 --port_out 49668 --socket_out PUSH_BIND --port_in
60654 --socket_in PULL_CONNECT --host_in Indexer30
ports:
- 5566:5566
Preprocessor10:
image: gnes/gnes:latest
command: preprocess --port_in 49668 --socket_in PULL_CONNECT
--port_out 61911 --socket_out PUSH_BIND --yaml_path /Preprocessor10_yaml --host_in
gRPCFrontend00
configs:
- Preprocessor10_yaml
Encoder20:
image: gnes/gnes:latest
command: encode --port_in 61911 --socket_in PULL_CONNECT
--port_out 49947 --socket_out PUSH_BIND --yaml_path /Encoder20_yaml --host_in
Preprocessor10
configs:
- Encoder20_yaml
Indexer30:
image: gnes/gnes:latest
command: index --port_in 49947 --socket_in PULL_CONNECT
--port_out 60654 --socket_out PUSH_BIND --yaml_path /Indexer30_yaml --host_in
Encoder20
configs:
- Indexer30_yaml
volumes: {}
networks:
gnes-net:
driver: overlay
attachable: true
configs:
Preprocessor10_yaml:
file: text-prep.yml
Encoder20_yaml:
file: gpt2.yml
Indexer30_yaml:
file: b-indexer.yml For the sake of simplicity, we will just use the generated shell-script to start GNES. Create a new file say run.sh, copy the content to it and run it via $ bash ./run.sh. You should see the output as follows:

This suggests the GNES app is ready and waiting for the incoming data. You may now feed data to it through the gRPCFrontend. Depending on your language (Python, C, Java, Go, HTTP, Shell, etc.) and the content form (image, video, text, etc), the data feeding part can be slightly different.
To stop a running GNES, you can simply do control + c.
Now let's juice it up a bit. To be honest, building a single-machine process-based pipeline is not impressive anyway. The true power of GNES is that you can scale any component at any time you want. Encoding is slow? Adding more machines. Preprocessing takes too long? More machines. Index file is too large? Adding shards, aka. more machines!
In this example, we compose a more complicated GNES workflow for images. This workflow consists of multiple preprocessors, encoders and two types of indexers. In particular, we introduce two types of indexers: one for storing the encoded binary vectors, the other for storing the original images, i.e. full-text index. These two types of indexers work in parallel. Check out the YAML file on the left side of table for more details, note how replicas is defined for each component.
| YAML config | GNES workflow (generated by GNES board) |
|---|---|
port: 5566
services:
- name: Preprocessor
replicas: 2
yaml_path: image-prep.yml
- name: Encoder
replicas: 3
yaml_path: incep-v3.yml
- - name: Indexer
yaml_path: faiss.yml
replicas: 4
- name: Indexer
yaml_path: fulltext.yml
replicas: 3
|

|
You may realize that besides the gRPCFrontend, multiple Router have been added to the workflow. Routers serve as a message broker between microservices, determining how and where the message is received and sent. In the last pipeline example, the data flow is too simple so there is no need for adding any router. In this example routers are necessary for connecting multiple preprocessors and encoders, otherwise preprocessors wouldn't know where to send the message. GNES Board automatically adds router to the workflow when necessary based on the type of two consecutive layers. It may also add stacked routers, as you can see between encoder and indexer in the right graph.
Again, the detailed YAML config of each component is not important for understanding the big picture, hence we omit it for now.
This time we will run GNES via DockerSwarm. To do that simply copy the generated DockerSwarm YAML config to a file say my-gnes.yml, and then do
docker stack deploy --compose-file my-gnes.yml gnes-531Note that gnes-531 is your GNES stack name, keep that name in mind. If you forget about that name, you can always use docker stack ls to find out. To tell whether the whole stack is running successfully or not, you can use docker service ls -f name=gnes-531. The number of replicas 1/1 or 4/4 suggests everything is fine.
Generally, a complete and successful Docker Swarm starting process should look like the following:

When the GNES stack is ready and waiting for the incoming data, you may now feed data to it through the gRPCFrontend. Depending on your language (Python, C, Java, Go, HTTP, Shell, etc.) and the content form (image, video, text, etc), the data feeding part can be slightly different.
To stop a running GNES stack, you can use docker stack rm gnes-531.
With the help of GNES Board, you can easily compose a GNES app for different purposes. The table below summarizes some common compositions with the corresponding workflow visualizations. Note, we hide the component-wise YAML config (i.e. yaml_path) for the sake of clarity.
| YAML config | GNES workflow (generated by GNES board) |
|---|---|
Parallel preprocessing only
port: 5566
services:
- name: Preprocessor
replicas: 2
|

|
Training an encoder
port: 5566
services:
- name: Preprocessor
replicas: 3
- name: Encoder
|

|
Index-time with 3 vector-index shards
port: 5566
services:
- name: Preprocessor
- name: Encoder
- name: Indexer
replicas: 3
|

|
Query-time with 2 vector-index shards followed by 3 full-text-index shards
port: 5566
services:
- name: Preprocessor
- name: Encoder
- name: Indexer
income: sub
replicas: 2
- name: Indexer
income: sub
replicas: 3
|

|
Now that you know how to compose and run a GNES app, let's make a short recap of what we have learned.
- GNES is all-in-microservice, there are four fundamental components: preprocessor, encoder, indexer and router.
- GNES has three runtimes: training, indexing, and querying. The key to compose a GNES app is to clarify which runtime requires what microservices (defined in the YAML config), and each microservice does what (defined in the component-wise YAML config).
- GNES requires an orchestration engine to coordinate all microservices. It supports Kubernetes, Docker Swarm and a shell-based multi-process solution.
- GNES Board is a convenient tool for visualizing the workflow, generating starting script or cloud configuration.
- The real power of GNES is elasticity on every level. Router is automatically added between microservices for connecting the pieces together.
The next step is feeding data to GNES for training, indexing and querying. Checkout the tutorials and documentations for more details.
The official documentation of GNES is hosted on doc.gnes.ai. It is automatically built, updated and archived on every new release.
🚧 Tutorial is still under construction. Stay tuned! Meanwhile, we sincerely welcome you to contribute your own learning experience / case study with GNES!
- How to write your GNES YAML config
- How to write a component-wise YAML config
- Understanding preprocessor, encoder, indexer and router
- Index and query text data with GNES
- Index and query image data with GNES
- Index and query video data with GNES
- Using GNES with Kubernetes
- Using GNES in other language (besides Python)
- Serves HTTP-request with GNES in an end-to-end way
- Model-as-plugin: write your own component
- Migrating from
bert-as-service
Thanks for your interest in contributing! GNES always welcome the contribution from the open-source community, individual committers and other partners. Without you, GNES can't be successful.
Currently there are three major directions of contribution:
- Porting state-of-the-art models to GNES. This includes new preprocessing algorithms, new DNN networks for encoding, and new high-performance index. Believe me, it is super easy to wrap an algorithm and use it in GNES. Checkout this example.
- Adding tutorial and learning experience. What is good and what can be improved? If you apply GNES in your domain, whether it's about NLP or CV, whether it's a blog post or a Reddit/Twitter thread, we are always eager to hear your thoughts.
- Completing the user experience of other programming languages. GNES offers a generic interface with gRPC and protobuf, therefore it is easy to add an interface for other languages, e.g. Java, C, Go.
Make sure to read the contributor guidelines before your first commit.
For contributors looking to get deeper into the API we suggest cloning the repository and checking out the unit tests for examples of how to call methods.
If you use GNES in an academic paper, you are more than welcome to make a citation. Here are the two ways of citing GNES:
-
\footnote{https://github.com/gnes-ai/gnes} -
@misc{tencent2019GNES, title={GNES: Generic Neural Elastic Search}, author={Xiao, Han and Yan, Jianfeng and Wang, Feng and Fu, Jie}, howpublished={\url{https://github.com/gnes-ai}}, year={2019} }
If you have downloaded a copy of the GNES binary or source code, please note that the GNES binary and source code are both licensed under the Apache License, Version 2.0.
Tencent is pleased to support the open source community by making GNES available.Copyright (C) 2019 THL A29 Limited, a Tencent company. All rights reserved.