diff --git a/README.md b/README.md
index d738a80..a7389f4 100644
--- a/README.md
+++ b/README.md
@@ -2,6 +2,7 @@
This is a Keras implementation of a CNN for estimating age and gender from a face image [1, 2].
In training, [the IMDB-WIKI dataset](https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/) is used.
+- [Jul. 5, 2018] The UTKFace dataset became available for training.
- [Apr. 10, 2018] Evaluation result on the APPA-REAL dataset was added.
## Dependencies
@@ -28,18 +29,18 @@ python3 demo.py
The pretrained model for TensorFlow backend will be automatically downloaded to the `pretrained_models` directory.
-### Train a model using the IMDB-WIKI dataset
-
-#### Download the dataset
-The dataset is downloaded and extracted to the `data` directory.
+### Create training data from the IMDB-WIKI dataset
+First, download the dataset.
+The dataset is downloaded and extracted to the `data` directory by:
```sh
./download.sh
```
-#### Create training data
-Filter out noise data and serialize images and labels for training into `.mat` file.
+Secondly, filter out noise data and serialize images and labels for training into `.mat` file.
Please check [check_dataset.ipynb](check_dataset.ipynb) for the details of the dataset.
+The training data is created by:
+
```sh
python3 create_db.py --output data/imdb_db.mat --db imdb --img_size 64
```
@@ -57,7 +58,28 @@ optional arguments:
--min_score MIN_SCORE minimum face_score (default: 1.0)
```
-#### Train network
+### Create training data from the UTKFace dataset
+Firstly, download images from [the website of the UTKFace dataset](https://susanqq.github.io/UTKFace/).
+`UTKFace.tar.gz` can be downloaded from `Aligned&Cropped Faces` in Datasets section.
+Then, extract the archive.
+
+```sh
+tar zxf UTKFace.tar.gz UTKFace
+```
+
+Finally, run the following script to create the training data:
+
+```
+python3 create_db_utkface.py -i UTKFace -o UTKFace.mat
+```
+
+[NOTE]: Because the face images in the UTKFace dataset is tightly cropped (there is no margin around the face region),
+faces should be cropped in `demo.py`.
+As tight cropping is currently not supported, please modify the code.
+
+
+
+### Train network
Train the network using the training data created above.
```sh
@@ -89,7 +111,7 @@ optional arguments:
--aug use data augmentation if set true (default: False)
```
-#### Train network with recent data augmentation methods
+### Train network with recent data augmentation methods
Recent data augmentation methods, mixup [3] and Random Erasing [4],
can be used with standard data augmentation by `--aug` option in training:
@@ -103,7 +125,7 @@ I confirmed that data augmentation enables us to avoid overfitting
and improves validation loss.
-#### Use the trained network
+### Use the trained network
```sh
python3 demo.py
@@ -125,18 +147,18 @@ optional arguments:
Please use the best model among `checkpoints/weights.*.hdf5` for `WEIGHT_FILE` if you use your own trained models.
-#### Plot training curves from history file
+### Plot training curves from history file
```sh
python3 plot_history.py --input models/history_16_8.h5
```
-##### Results without data augmentation
+#### Results without data augmentation
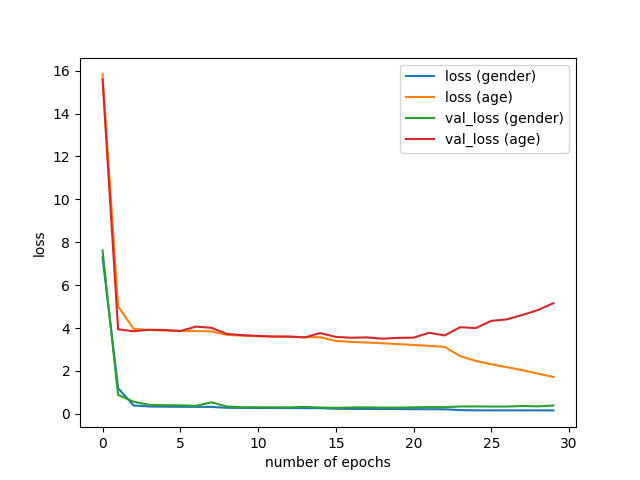
 -##### Results with data augmentation
+#### Results with data augmentation
The best val_loss was improved from 3.969 to 3.731:
- Without data augmentation: 3.969
- With standard data augmentation: 3.799
@@ -147,14 +169,14 @@ The best val_loss was improved from 3.969 to 3.731:
We can see that, with data augmentation,
overfitting did not occur even at very small learning rates (epoch > 15).
-#### Network architecture
+### Network architecture
In [the original paper](https://www.vision.ee.ethz.ch/en/publications/papers/articles/eth_biwi_01299.pdf) [1, 2], the pretrained VGG network is adopted.
Here the Wide Residual Network (WideResNet) is trained from scratch.
I modified the @asmith26's implementation of the WideResNet; two classification layers (for age and gender estimation) are added on the top of the WideResNet.
Note that while age and gender are independently estimated by different two CNNs in [1, 2], in my implementation, they are simultaneously estimated using a single CNN.
-#### Estimated results
+### Estimated results
Trained on imdb, tested on wiki.

diff --git a/create_db_utkface.py b/create_db_utkface.py
new file mode 100644
index 0000000..97de8d1
--- /dev/null
+++ b/create_db_utkface.py
@@ -0,0 +1,46 @@
+import argparse
+from pathlib import Path
+from tqdm import tqdm
+import numpy as np
+import scipy.io
+import cv2
+
+
+def get_args():
+ parser = argparse.ArgumentParser(description="This script creates database for training from the UTKFace dataset.",
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument("--input", "-i", type=str, required=True,
+ help="path to the UTKFace image directory")
+ parser.add_argument("--output", "-o", type=str, required=True,
+ help="path to output database mat file")
+ parser.add_argument("--img_size", type=int, default=64,
+ help="output image size")
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = get_args()
+ image_dir = Path(args.input)
+ output_path = args.output
+ img_size = args.img_size
+
+ out_genders = []
+ out_ages = []
+ out_imgs = []
+
+ for i, image_path in enumerate(tqdm(image_dir.glob("*.jpg"))):
+ image_name = image_path.name # [age]_[gender]_[race]_[date&time].jpg
+ age, gender = image_name.split("_")[:2]
+ out_genders.append(int(gender))
+ out_ages.append(min(int(age), 100))
+ img = cv2.imread(str(image_path))
+ out_imgs.append(cv2.resize(img, (img_size, img_size)))
+
+ output = {"image": np.array(out_imgs), "gender": np.array(out_genders), "age": np.array(out_ages),
+ "db": "utk", "img_size": img_size, "min_score": -1}
+ scipy.io.savemat(output_path, output)
+
+
+if __name__ == '__main__':
+ main()
-##### Results with data augmentation
+#### Results with data augmentation
The best val_loss was improved from 3.969 to 3.731:
- Without data augmentation: 3.969
- With standard data augmentation: 3.799
@@ -147,14 +169,14 @@ The best val_loss was improved from 3.969 to 3.731:
We can see that, with data augmentation,
overfitting did not occur even at very small learning rates (epoch > 15).
-#### Network architecture
+### Network architecture
In [the original paper](https://www.vision.ee.ethz.ch/en/publications/papers/articles/eth_biwi_01299.pdf) [1, 2], the pretrained VGG network is adopted.
Here the Wide Residual Network (WideResNet) is trained from scratch.
I modified the @asmith26's implementation of the WideResNet; two classification layers (for age and gender estimation) are added on the top of the WideResNet.
Note that while age and gender are independently estimated by different two CNNs in [1, 2], in my implementation, they are simultaneously estimated using a single CNN.
-#### Estimated results
+### Estimated results
Trained on imdb, tested on wiki.

diff --git a/create_db_utkface.py b/create_db_utkface.py
new file mode 100644
index 0000000..97de8d1
--- /dev/null
+++ b/create_db_utkface.py
@@ -0,0 +1,46 @@
+import argparse
+from pathlib import Path
+from tqdm import tqdm
+import numpy as np
+import scipy.io
+import cv2
+
+
+def get_args():
+ parser = argparse.ArgumentParser(description="This script creates database for training from the UTKFace dataset.",
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser.add_argument("--input", "-i", type=str, required=True,
+ help="path to the UTKFace image directory")
+ parser.add_argument("--output", "-o", type=str, required=True,
+ help="path to output database mat file")
+ parser.add_argument("--img_size", type=int, default=64,
+ help="output image size")
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = get_args()
+ image_dir = Path(args.input)
+ output_path = args.output
+ img_size = args.img_size
+
+ out_genders = []
+ out_ages = []
+ out_imgs = []
+
+ for i, image_path in enumerate(tqdm(image_dir.glob("*.jpg"))):
+ image_name = image_path.name # [age]_[gender]_[race]_[date&time].jpg
+ age, gender = image_name.split("_")[:2]
+ out_genders.append(int(gender))
+ out_ages.append(min(int(age), 100))
+ img = cv2.imread(str(image_path))
+ out_imgs.append(cv2.resize(img, (img_size, img_size)))
+
+ output = {"image": np.array(out_imgs), "gender": np.array(out_genders), "age": np.array(out_ages),
+ "db": "utk", "img_size": img_size, "min_score": -1}
+ scipy.io.savemat(output_path, output)
+
+
+if __name__ == '__main__':
+ main()