导读: 该部分介绍预训练模型微调 想提升预训练模型在指定任务上的性能?让我们选择合适的预训练模型,在特定任务上进行微调,并将微调后的模型部署成方便使用的Demo!
- 熟悉使用Transformers工具包
- 掌握预训练模型的微调、推理(解耦可定制版本 & 默认集成版本)
- 掌握利用Gradio Spaces进行Demo部署
- 了解不同类型的预训练模型的选型和应用场景
https://github.com/huggingface/transformers
🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。这些模型支持不同模态中的常见任务,比如: 📝 自然语言处理:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。 🖼️ 机器视觉:图像分类、目标检测和语义分割。 🗣️ 音频:自动语音识别和音频分类。 🐙 多模态:表格问答、光学字符识别、从扫描文档提取信息、视频分类和视觉问答。
详细中文文档:https://huggingface.co/docs/transformers/main/zh/index

- 我们进入到文本分类的案例库,参考readme了解关键参数,下载requirements.txt和run_classification.py
https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification
- 安装环境:
-
- (可选)通过conda创建新的环境:conda create -n llm python=3.9
-
- (可选)进入虚拟环境:conda activate llm
-
- pip install transformers
-
- pip install -r requirements.txt
*Note:安装速度网速慢?使用国内源:pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
- 准备数据:我们以Kaggle上的虚假推文数据集为例:https://www.kaggle.com/c/nlp-getting-started/data
(1)解耦可定制版本(关键模块解耦,方便理解,可自定义数据加载、模型结构、评价指标等)
(2)默认集成版本(代码较 为丰富、复杂,一般直接超参数调用,略有开发门槛)
共三个主要文件:main.py主程序,utils_data.py数据加载和处理文件,modeling_bert.py模型结构文件

-
加载和处理数据(utils_data.py)
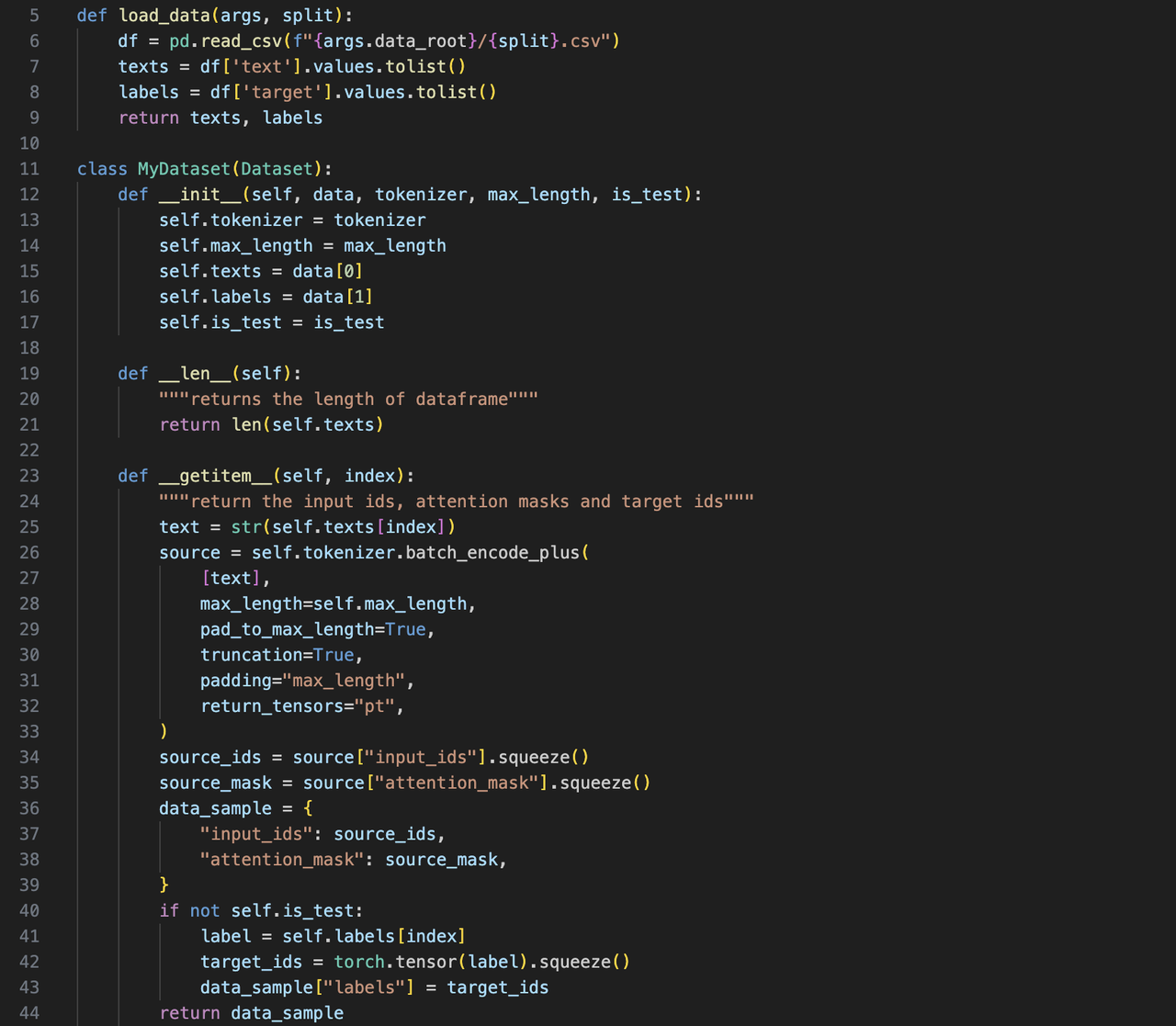
-
加载模型(modeling_bert.py)



- 训练/验证/预测(main.py)

python main.py-
加载数据(csv或json格式)
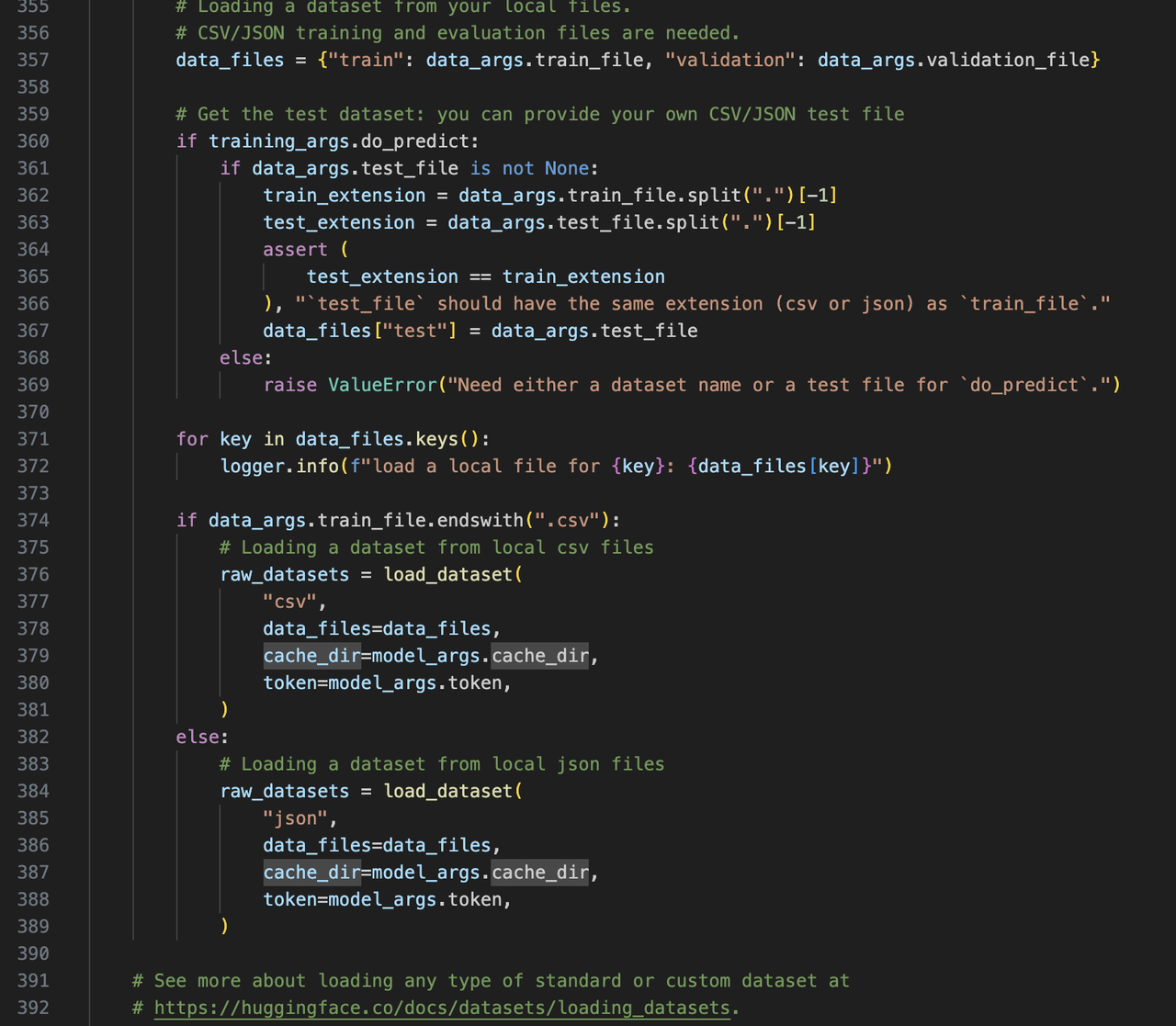
-
处理数据
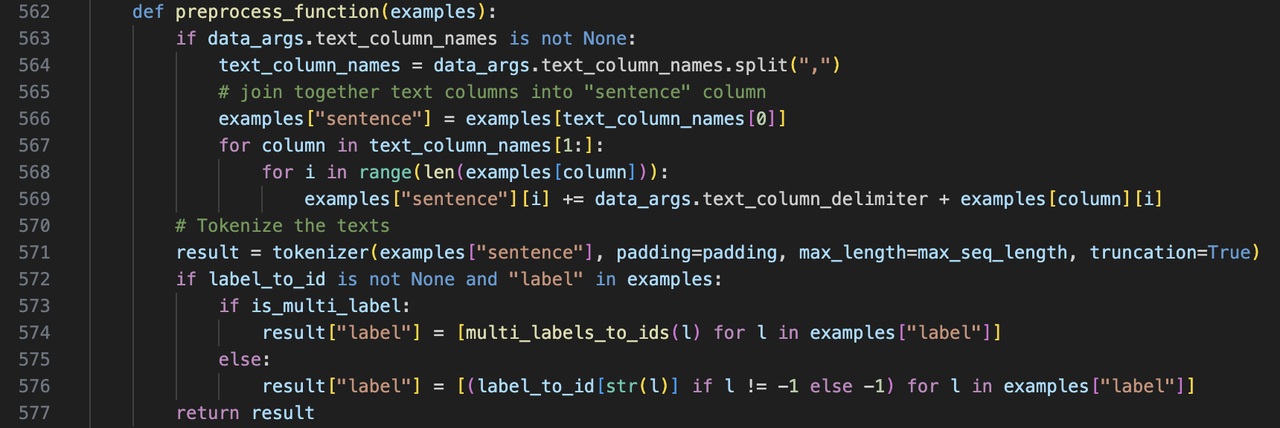
-
加载模型
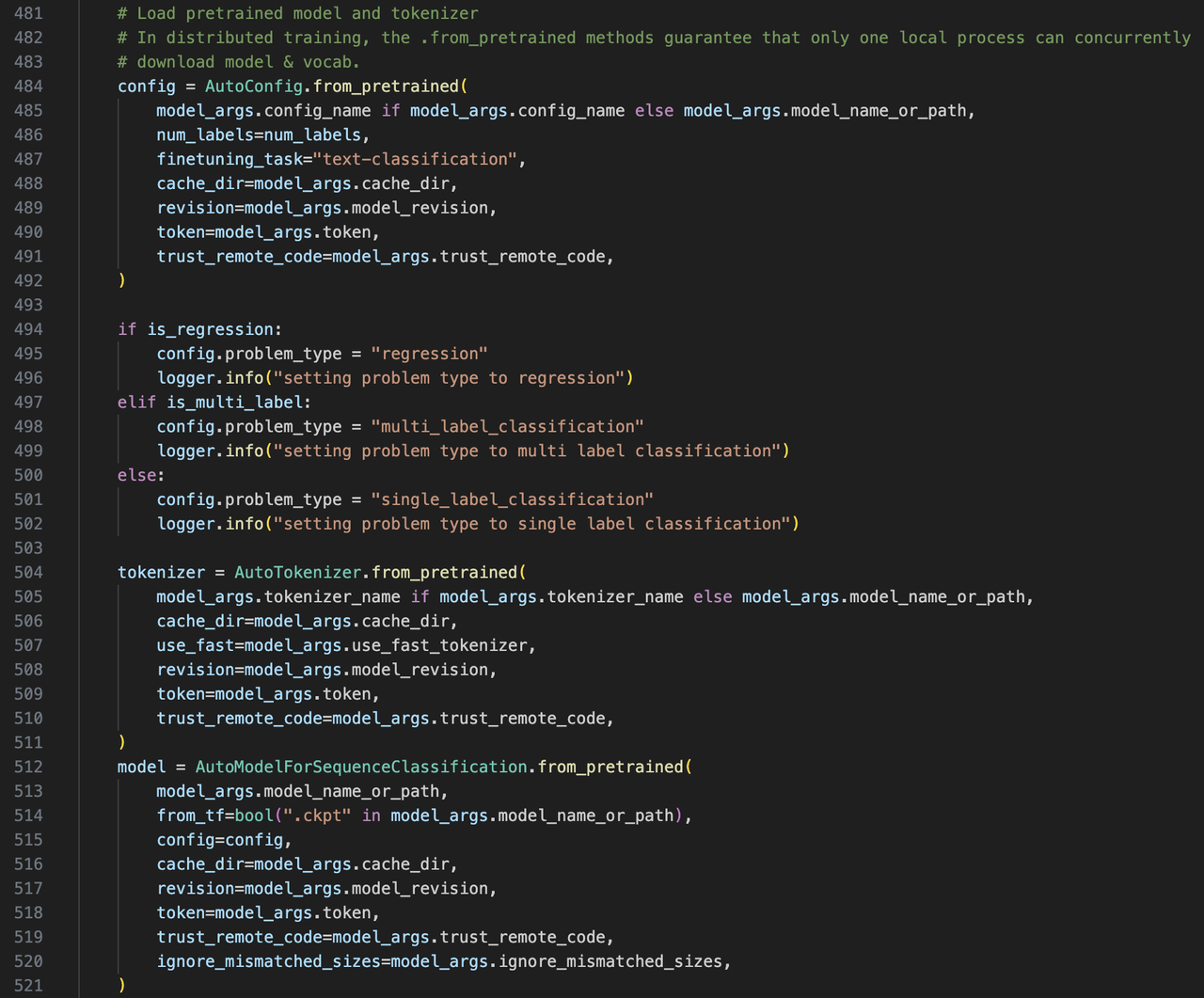
-
训练/验证/预测




同时在开发集上验证,在测试集上预测,执行下述脚本:
python run_classification.py \
--model_name_or_path bert-base-uncased \
--train_file data/train.csv \
--validation_file data/val.csv \
--test_file data/test.csv \
--shuffle_train_dataset \
--metric_name accuracy \
--text_column_name "text" \
--text_column_delimiter "\n" \
--label_column_name "target" \
--do_train \
--do_eval \
--do_predict \
--max_seq_length 512 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 1 \
--output_dir experiments/若出现报错或卡住,通常是网络问题:
- 下载模型时显示“Network is unreachable”,手动下载模型到本地:https://huggingface.co/google-bert/bert-base-uncased
- 若加完数据后卡住不动,CTRL+C终止后显示卡在“connection”,则是evaluate包加载评价指标时网络连接失败所致。

此时,可去evaluate的GitHub下载整个包:https://github.com/huggingface/evaluate/tree/main,并在超参数中将--metric_name路径改成本地的指标路径,即:
python run_classification.py \
--model_name_or_path bert-base-uncased \
--train_file data/train.csv \
--validation_file data/val.csv \
--test_file data/test.csv \
--shuffle_train_dataset \
--metric_name evaluate/metrics/accuracy/accuracy.py \
--text_column_name "text" \
--text_column_delimiter "\n" \
--label_column_name "target" \
--do_train \
--do_eval \
--do_predict \
--max_seq_length 512 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 1 \
--output_dir experiments/
https://huggingface.co/docs/hub/en/spaces-sdks-gradio
- https://huggingface.co/new-space?sdk=gradio
- Note:打不开的话请尝试科学上网

具体见工程包中的app.py

- 配置文件(requirements.txt)
transformers==4.30.2
torch==2.0.0
- 文件概览

- Demo效果 成功部署的案例供参考:https://huggingface.co/spaces/cooelf/text-classification 其中在右上角“Files”栏目可以看到源码。

- 彩蛋:在Spaces平台可以看到每周的热点Demo,且可以搜索感兴趣的大模型、Demo进行尝试

- 试试其他分类/回归任务,例如情感分类、新闻分类、漏洞分类等
- 试试其他类型的模型,例如T5、ELECTRA等
- 问答模型:https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering
- 文本摘要:https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization
- 调用Llama2进行推理:https://huggingface.co/docs/transformers/en/model_doc/llama2
- 对Llama2进行轻量化微调(LoRA): https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/5-Fine%20Tuning/LoRA_Tuning_PEFT.ipynb
-
一篇对大语言模型(LLMs)进行全面、深入分析的43页综述(Word2Vec作者出品)
论文题目:Large Language Models: A Survey