| title | description | author | ms.reviewer | ms.service | ms.custom | ms.topic | ms.date | ms.author |
|---|---|---|---|---|---|---|---|---|
Cluster capacity planning in Azure HDInsight |
How to specify an HDInsight cluster for capacity and performance. |
hrasheed-msft |
jasonh |
hdinsight |
hdinsightactive |
conceptual |
12/04/2018 |
hrasheed |
Before deploying an HDInsight cluster, plan for the desired cluster capacity by determining the needed performance and scale. This planning helps optimize both usability and costs. Some cluster capacity decisions cannot be changed after deployment. If the performance parameters change, a cluster can be dismantled and re-created without losing stored data.
The key questions to ask for capacity planning are:
- In which geographic region should you deploy your cluster?
- How much storage do you need?
- What cluster type should you deploy?
- What size and type of virtual machine (VM) should your cluster nodes use?
- How many worker nodes should your cluster have?
The Azure region determines where your cluster is physically provisioned. To minimize the latency of reads and writes, the cluster should be near your data.
HDInsight is available in many Azure regions. To find the closest region, see the HDInsight entry under Analytics in Products Available by Region.
The default storage, either an Azure Storage account or Azure Data Lake Storage, must be in the same location as your cluster. Azure Storage is available at all locations. Data Lake Storage Gen1 is available in some regions - see the current Data Lake Storage availability under Storage in Azure Products Available by Region.
If you already have a storage account or Data Lake Storage containing your data and want to use this storage as your cluster's default storage, then you must deploy your cluster at that same location.
After you have an HDInsight cluster deployed, you can attach additional Azure Storage accounts or access other Data Lake Storage. All your storage accounts must reside in the same location as your cluster. A Data Lake Storage can be in a different location, although this may introduce some data read/write latency.
Azure Storage has some capacity limits, while Data Lake Storage Gen1 is virtually unlimited.
A cluster can access a combination of different storage accounts. Typical examples include:
- When the amount of data is likely to exceed the storage capacity of a single blob storage container.
- When the rate of access to the blob container might exceed the threshold where throttling occurs.
- When you want to make data, you have already uploaded to a blob container available to the cluster.
- When you want to isolate different parts of the storage for reasons of security, or to simplify administration.
For a 48-node cluster, we recommend 4 to 8 storage accounts. Although there may already be sufficient total storage, each storage account provides additional networking bandwidth for the compute nodes. When you have multiple storage accounts, use a random name for each storage account, without a prefix. The purpose of random naming is reducing the chance of storage bottlenecks (throttling) or common-mode failures across all accounts. For better performance, use only one container per storage account.
The cluster type determines the workload your HDInsight cluster is configured to run, such as Apache Hadoop, Apache Storm, Apache Kafka, or Apache Spark. For a detailed description of the available cluster types, see Introduction to Azure HDInsight. Each cluster type has a specific deployment topology that includes requirements for the size and number of nodes.
Each cluster type has a set of node types, and each node type has specific options for their VM size and type.
To determine the optimal cluster size for your application, you can benchmark cluster capacity and increase the size as indicated. For example, you can use a simulated workload, or a canary query. With a simulated workload, you run your expected workloads on different size clusters, gradually increasing the size until the desired performance is reached. A canary query can be inserted periodically among the other production queries to show whether or not the cluster has enough resources.
The VM size and type is determined by CPU processing power, RAM size, and network latency:
-
CPU: The VM size dictates the number of cores. The more cores, the greater the degree of parallel computation each node can achieve. Also, some VM types have faster cores.
-
RAM: The VM size also dictates the amount of RAM available in the VM. For workloads that store data in memory for processing, rather than reading from disk, ensure your worker nodes have enough memory to fit the data.
-
Network: For most cluster types, the data processed by the cluster is not on local disk, but rather in an external storage service such as Data Lake Storage or Azure Storage. Consider the network bandwidth and throughput between the node VM and the storage service. The network bandwidth available to a VM typically increases with larger sizes. For details, see VM sizes overview.
A cluster's scale is determined by the quantity of its VM nodes. For all cluster types, there are node types that have a specific scale, and node types that support scale-out. For example, a cluster may require exactly three Apache ZooKeeper nodes or two Head nodes. Worker nodes that do data processing in a distributed fashion can benefit from scaling out, by adding additional worker nodes.
Depending on your cluster type, increasing the number of worker nodes adds additional computational capacity (such as more cores), but may also add to the total amount of memory required for the entire cluster to support in-memory storage of data being processed. As with the choice of VM size and type, selecting the right cluster scale is typically reached empirically, using simulated workloads or canary queries.
You can scale out your cluster to meet peak load demands, then scale it back down when those extra nodes are no longer needed. For more information, see Scale HDInsight clusters.
You are charged for a cluster's lifetime. If there are only specific times that you need your cluster up and running, you can create on-demand clusters using Azure Data Factory. You can also create PowerShell scripts that provision and delete your cluster, and then schedule those scripts using Azure Automation.
Note
When a cluster is deleted, its default Hive metastore is also deleted. To persist the metastore for the next cluster re-creation, use an external metadata store such as Azure Database or Apache Oozie.
Sometimes errors can occur due to the parallel execution of multiple maps and reduce components on a multi-node cluster. To help isolate the issue, try distributed testing by running concurrent multiple jobs on a single-node cluster, then expand this approach to run multiple jobs concurrently on clusters containing more than one node. To create a single-node HDInsight cluster in Azure, use the advanced option.
You can also install a single-node development environment on your local computer and test the solution there. Hortonworks provides a single-node local development environment for Hadoop-based solutions that is useful for initial development, proof of concept, and testing. For more information, see Hortonworks Sandbox.
To identify the issue on a single-node local cluster you can rerun failed jobs and adjust the input data, or use smaller datasets. How you run those jobs depends on the platform and type of application.
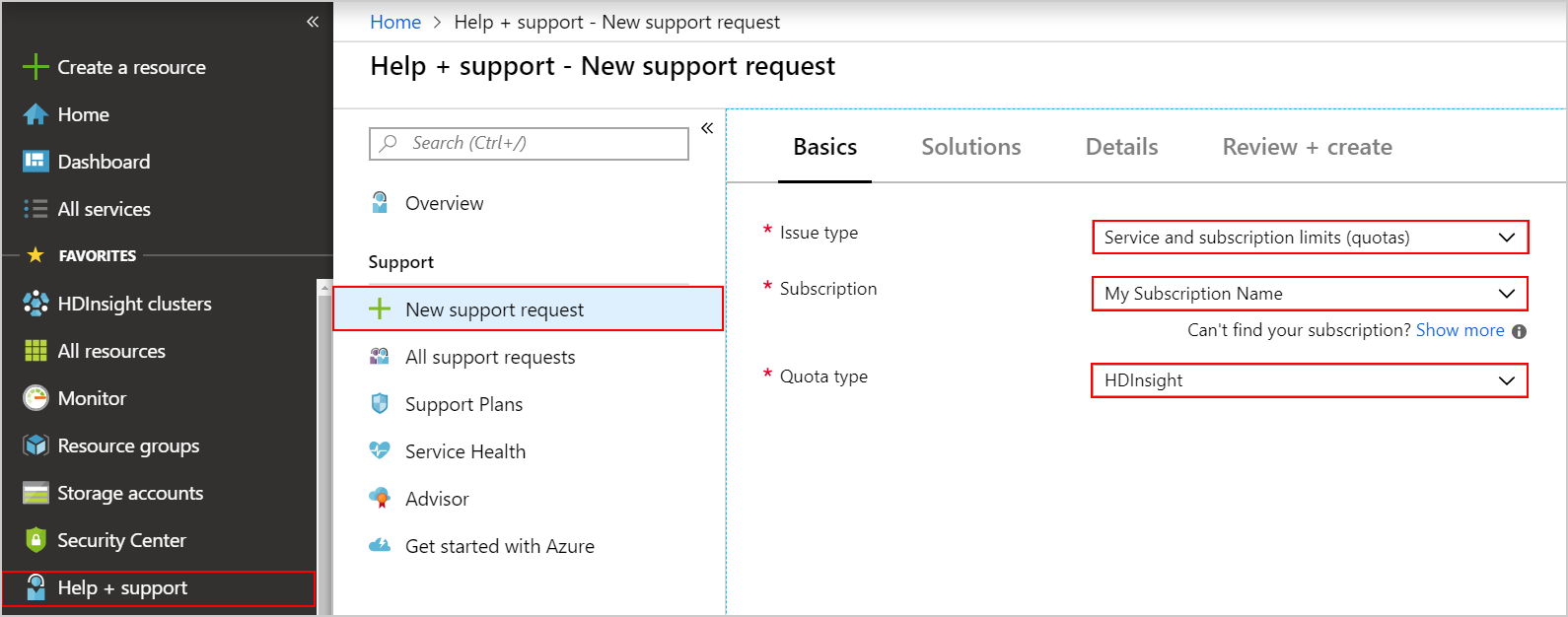
After determining your target cluster VM size, scale, and type, check the current quota capacity limits of your subscription. When you reach a quota limit, you may not be able to deploy new clusters, or scale out existing clusters by adding more worker nodes. The only quota limit is the CPU Cores quota that exists at the region level for each subscription. For example, your subscription may have 30 core limit in the East US region. If you need to request a quota increase, do the following steps:
-
Go to the Azure portal
-
Click on Help and Support on the bottom-left side of the page.
-
Click on New support request.
-
On the New support request page, under Basics tab, select the following options:
-
Issue type: Service and subscription limits (quotas)
-
Subscription: the subscription you want to modify
-
Quota type: HDInsight
-
-
Click Next.
-
On the Details page, enter a description of the issue, select the severity of the issue, and select your preferred contact method.
-
Click Next: Review + create.
-
On the Review + create tab, click Create.

Note
If you need to increase the HDInsight core quota in a private region, submit a whitelist request.
You can contact support to request a quota increase.
However, there are some fixed quota limits, for example a single Azure subscription can have at most 10,000 cores. For details on these limits, see Azure subscription and service limits, quotas, and constraints.
- Set up clusters in HDInsight with Apache Hadoop, Spark, Kafka, and more: Learn how to set up and configure clusters in HDInsight with Apache Hadoop, Spark, Kafka, Interactive Hive, HBase, ML Services, or Storm.
- Monitor cluster performance: Learn about key scenarios to monitor for your HDInsight cluster that might affect your cluster's capacity.