Open source code for the paper: "AutoML-Zero: Evolving Machine Learning Algorithms From Scratch"
| Introduction | Quick Demo | Reproducing Search Baselines | Citation |
|---|
AutoML-Zero aims to automatically discover computer programs that can solve machine learning tasks, starting from empty or random programs and using only basic math operations. The goal is to simultaneously search for all aspects of an ML algorithm—including the model structure and the learning strategy—while employing minimal human bias.

Despite AutoML-Zero's challenging search space, evolutionary search shows promising results by discovering linear regression with gradient descent, 2-layer neural networks with backpropagation, and even algorithms that surpass hand designed baselines of comparable complexity. The figure above shows an example sequence of discoveries from one of our experiments, evolving algorithms to solve binary classification tasks. Notably, the evolved algorithms can be interpreted. Below is an analysis of the best evolved algorithm: the search process "invented" techniques like bilinear interactions, weight averaging, normalized gradient, and data augmentation (by adding noise to the inputs).
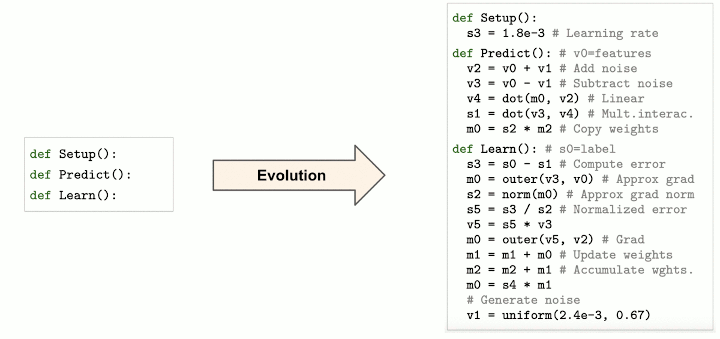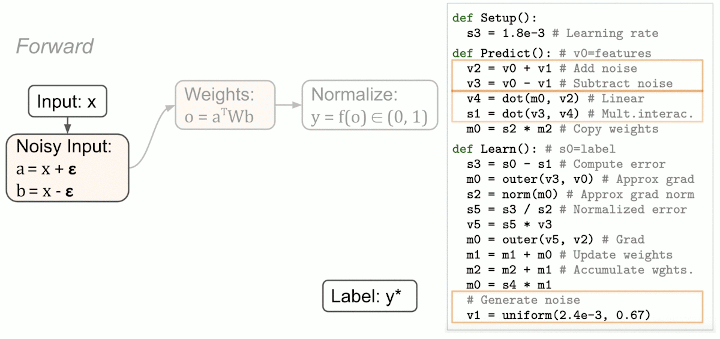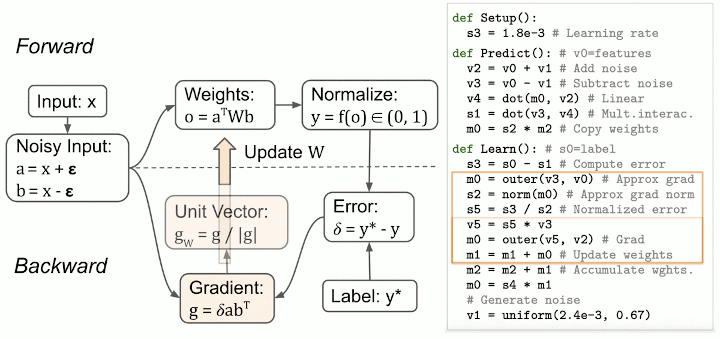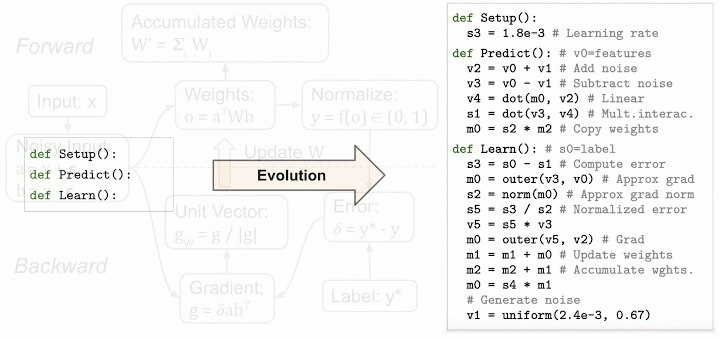
{kind=link}
{kind=link}
More examples, analysis, and details can be found in the paper.
As a miniature "AutoML-Zero" experiment, let's try to automatically discover programs to solve linear regression tasks.
To get started, first install bazel following instructions here (bazel>=2.2.0 and g++>=9 are required), then run the demo with:
git clone https://github.com/google-research/google-research.git
cd google-research/automl_zero
./run_demo.sh
This script runs evolutionary search on 10 linear tasks (Tsearch in the paper). After each experiment, it evaluates the best algorithm discovered on 100 new linear tasks (Tselect in the paper). Once an algorithm attains a fitness (1 - RMS error) greater than 0.9999, it is selected for a final evaluation on 100 unseen tasks. To conclude, the demo prints the results of the final evaluation and shows the code for the automatically discovered algorithm.
To make this demo quick, we use a much smaller search space than in the paper: only the math operations necessary to implement linear regression are allowed and the programs are constrained to a short, fixed length. Even with these limitations, the search space is quite sparse, as random search experiments show that only ~1 in 108 algorithms in the space can solve the tasks with the required accuracy. Nevertheless, this demo typically discovers programs similar to linear regression by gradient descent in under 5 minutes using 1 CPU (Note that the runtime may vary due to random seeds and hardware). We have seen similar and more interesting discoveries in the unconstrained search space (see more details in the paper).
You can compare the automatically discovered algorithm with the solution from a human ML researcher (one of the authors):
def Setup():
s2 = 0.001 # Init learning rate.
def Predict(): # v0 = features
s1 = dot(v0, v1) # Apply weights
def Learn(): # v0 = features; s0 = label
s3 = s0 - s1 # Compute error.
s4 = s3 * s2 # Apply learning rate.
v2 = v0 * s4 # Compute gradient.
v1 = v1 + v2 # Update weights.
In this human designed program, the Setup function establishes a learning rate, the Predict function applies a set of weights to the inputs, and the Learn function corrects the weights in the opposite direction to the gradient; in other words, a linear regressor trained with gradient descent. The evolved programs may look different even if they have the same functionality due to redundant instructions and different ordering, which can make them challenging to interpret. See more details about how we address these problems in the paper.
First install bazel, following the instructions here (bazel>=2.2.0 and g++>=9 are required), then follow the instructions below to reproduce the results in Supplementary
Section 9 ("Baselines") with the "Basic" method on 1 process (1 CPU).
First, generate the projected binary CIFAR10 datasets by running
python generate_datasets.py --data_dir=binary_cifar10_data
It takes ~1 hrs to download and preprocess all the data.
Then, start the baseline experiment by running
./run_baseline.sh
It takes 12-18 hrs to finish, depending on the hardware. You can vary the random seed in run_baseline.sh to produce a different result for each run.
If you want to use more than 1 process, you will need to create your own implementation to parallelize the computation based on your particular distributed-computing platform. A platform-agnostic description of what we did is given in our paper.
Note we left out of this directory upgrades for the "Full" method that are pre-existing (hurdles) but included those introduced in this paper (e.g. FEC for ML algorithms).
If you use the code in your research, please cite:
@article{real2020automl,
title={AutoML-Zero: Evolving Machine Learning Algorithms From Scratch},
author={Real, Esteban and Liang, Chen and So, David R and Le, Quoc V},
journal={arXiv preprint arXiv:2003.03384},
year={2020}
}
Search keywords: machine learning, neural networks, evolution, evolutionary algorithms, regularized evolution, program synthesis, architecture search, NAS, neural architecture search, neuro-architecture search, AutoML, AutoML-Zero, algorithm search, meta-learning, genetic algorithms, genetic programming, neuroevolution, neuro-evolution.