If interested, join the slack workspace where the paper is discussed, issues are worked through, and more! Click this link to join.
PyTorch implementation for this paper.
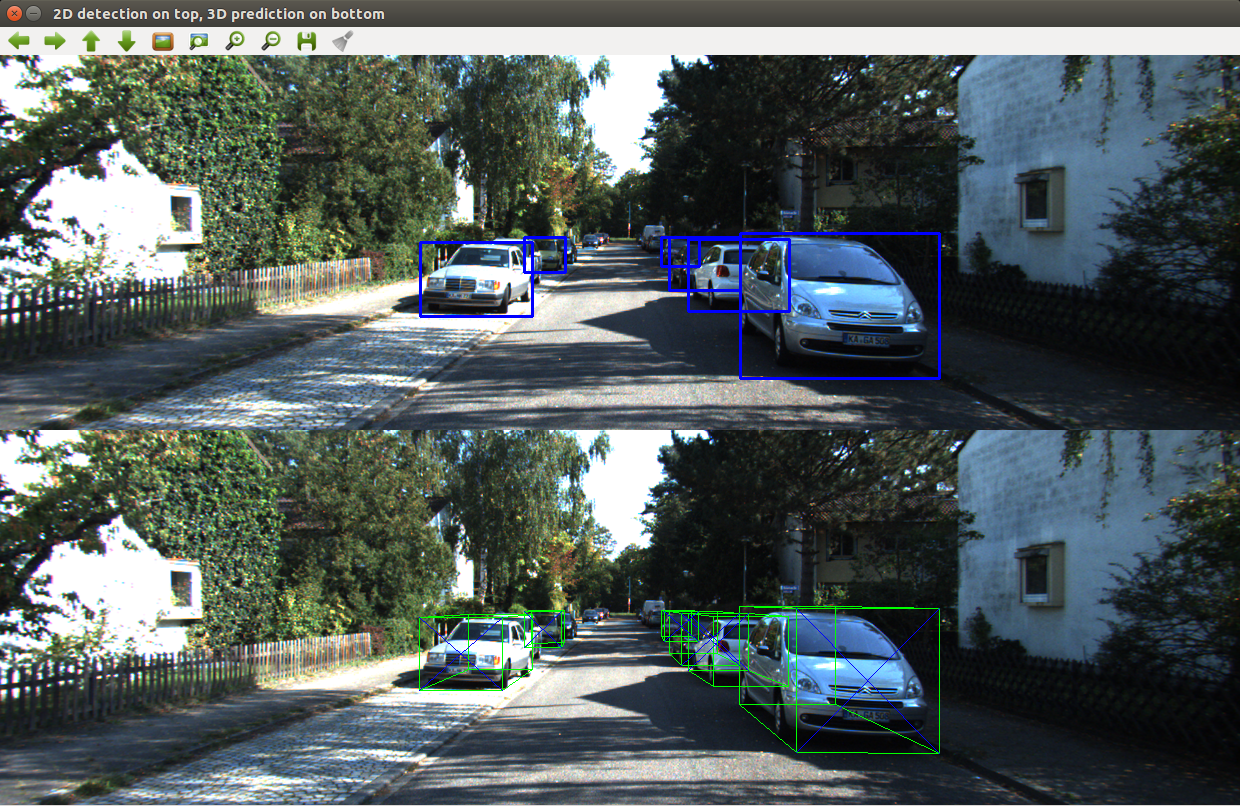
At the moment, it takes approximately 0.4s per frame, depending on the number of objects
detected. An improvement will be speed upgrades soon. Here is the current fastest possible:

- PyTorch
- OpenCV >= 3.4.3
Download the weights:
cd weights/
./get_weights.sh
This will download the weights I have trained and also the YOLOv3 weights from the official yolo site.
To see options:
python Run.py --help
Run through all images in default directory (eval/image_2/):
python Run.py [--show-yolo]
Run through default video:
python Run.py --video [--hide-debug]
Note: This script expects images in
./Kitti/testing/image_2/and corresponding projection matricies in./Kitti/testing/calib/. See training for where to download data from.
Press SPACE to process next image, and any other key to exit. This will visualize the 3d bounding box for all the images in Kitti/testing/. The image is passed through YOLOv3 pre-trained on the COCO dataset to make 2D bounding box detections, which is then used to crop the image and pass portions through the PyTorch neural net. The obtained location is used to project a 3D box onto the image. Camera projection matrices are also needed for every image (given by Kitti).
python Run_no_yolo.py
Will process all the images in eval/, using the label to get 2D box instead of YOLO.
First, you must download the data from Kitti. You will need the left color images, the training labels, and the camera calibration matrices. Total is ~13GB. Put these folders into the Kitti/ directory.
python Train.py
By default, the model is saved every 10 epochs in weights/. The loss is printed every 10 batches. The loss should not converge to 0! The loss function for the orientation is driven to -1, so a negative loss is expected. The hyper-parameters to tune are alpha and w (see paper). I obtained good results after just 10 epochs, but the training script will run until 100.
The PyTorch neural net takes in images of size 224x224 and predicts the orientation and relative dimension of that object to the class average. Thus, another neural net must give the 2D bounding box and object class, this repo uses YOLOv3 to do this using OpenCV. Using the orientation, dimension, and 2D bounding box, the 3D location is calculated. (more in depth math explanation coming soon...)
There are 2 key assumptions made:
- The 2D bounding box fits very tightly around the object
- The object has ~0 pitch and ~0 roll (valid for cars on the road)
- Train custom YOLO net on the Kitti dataset
- Cuda optimization to run frame by frame on video feed
- ROS node to publish positions
I originally started from a fork of this repo, and some of the original code still exists in the training script.