This sample is a Video Archive Q&A that uses the Retrieval Augmented Generation (RAG) pattern with your own Azure AI Video Indexer indexed data. It uses Azure OpenAI Service to access the ChatGPT model, and Azure AI Search or ChromaDB for data indexing and retrieval.
The repo includes sample data so it's ready to try end-to-end. The sample we use is an Azure AI Video Indexer introduction video, so you can actually use it to learn more about the product.

- Q&A interface
- Explores various options to help users evaluate the trustworthiness of responses with citations, tracking of source content, etc.
- Player integration to jump directly to the answer relevant part in the video.
IMPORTANT: To deploy and run this example, you must have an Azure subscription with access enabled for the Azure OpenAI service. You can request access here. You can also visit this page to get some free Azure credits to get you started.
NOTE: Your Azure Account must have Microsoft.Authorization/roleAssignments/write permissions, such as User Access Administrator or Owner.
AZURE RESOURCE COSTS by default this sample will create an Azure App Service and Azure AI Search resources that have a monthly cost.
- PowerShell > 7.4.2
- Azure Developer CLI
- Python 3+
- Important: Python and the pip package manager must be in the path in Windows for the setup scripts to work.
- Important: Ensure you can run
python --versionfrom console to check that you have the correct version. - Important: On Ubuntu, you might need to run
sudo apt install python-is-python3to linkpythontopython3.
- Node.js
- Git
- Powershell 7+ (pwsh) - For Windows users only.
- Important: Ensure you can run
pwsh.exefrom a PowerShell command. If this fails, you likely need to upgrade PowerShell.
- Important: Ensure you can run
- Install Azure Developer CLI (azd) using the command
winget install Microsoft.Azdand run the following commands:azd auth loginazd env new vi-playground-llm-demo
-
Create resources
Create a resource group to contain all the resources below.
-
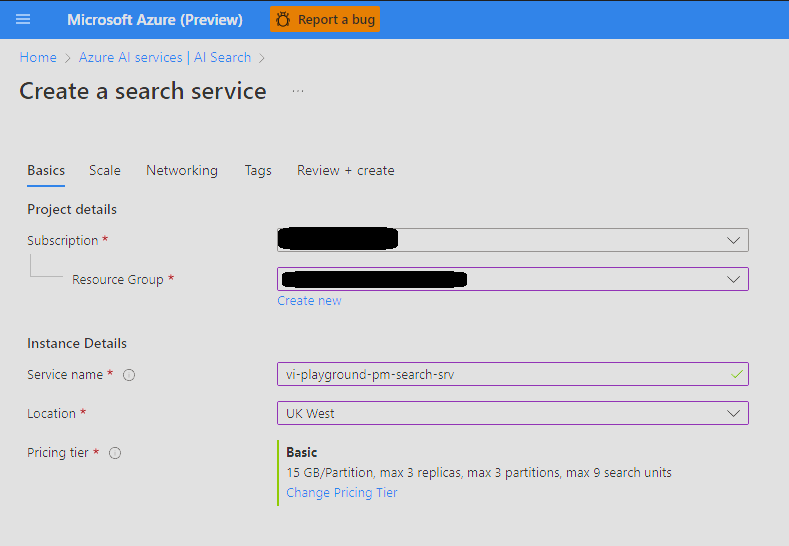
Set up Azure AI Search
-
Change pricing tier to Basic.
-
Enter the newly created resource, and note the API key under Settings > Keys, to be used later in the process. You will use the admin key for write permissions to create new indexes.

-
-
Set up Azure OpenAI
- Create Azure OpenAI instance.
- Create model deployments:
- text-embedding-ada-002 for embeddings
- gpt3.5 turbo or gpt4 turbo or gpt-4o as the LLM model.
- Note the deployment names to be used later in the process.
- Note API key under Resource management -> Keys and Endpoint to be used later in the process.
-
Index video archive
-
Index videos in VI account.
-
Make all videos public access.
-
Define the following azd parameters using
azd env set <Config Key> <Config Value>:-
AZURE_OPENAI_API_KEY (Azure OpenAI API key)
-
AZURE_OPENAI_CHATGPT_DEPLOYMENT (Azure OpenAI Chat LLM deployment name}
-
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT {Azure OpenAI embeddings model deployment name)
-
AZURE_OPENAI_RESOURCE_GROUP (Resource Group name of the Azure OpenAI resource)
-
AZURE_OPENAI_SERVICE (Azure OpenAI resource name)
-
AZURE_SEARCH_KEY (Azure AI Search API key)
-
AZURE_SEARCH_SERVICE (Azure AI Search resource name)
-
AZURE_SEARCH_LOCATION (Azure AI Search instance location, e.g. ukwest)
-
AZURE_SEARCH_SERVICE_RESOURCE_GROUP (Resource Group name of the Azure AI Search resource)
-
AZURE_TENANT_ID (Azure Tenant ID)
-
LANGUAGE_MODEL ("openai")
-
PROMPT_CONTENT_DB (Either: "azure_search" / "chromadb")
-
PROMPT_CONTENT_DB_NAME (Some DB name with this format "vi-db-name-index")
-
-
Index the archive into a new Azure AI Search index (Vector DB) by following these steps:
-
Install python dependencies with:
pip install -r .\app\backend\requirements.txt -
Create a
.envfile that holds your Azure AI Video Indexer details (taken from Azure portal) in the following format:AccountName='YOUR_VI_ACCOUNT_NAME' ResourceGroup='RESOURCE_GROUP_NAME' SubscriptionId='SUBSCRIPTION_ID' -
Optionally make changes in
.\app\backend\vi_search\prep_db.py -
Save and run the following commands in PowerShell from the workspace root directory:
$env:PYTHONPATH += ";$(Get-Location)"(to add the current directory to the Python path)python .\app\backend\vi_search\prep_db.py(to run the indexing into vector db script)
-
Wait for the Vector DB indexing to finish. The process can take some time, as it calls Azure OpenAI to create embeddings of the entire archive, and persists it to Azure AI Search or Chroma DB in batches of 100.
-
If you are using Chroma DB, which is now configured to save the DB locally, make sure it will be available to the deployment as well.
-
-
Deploy
- Install and use PowerShell from https://www.microsoft.com/store/productId/9MZ1SNWT0N5D?ocid=pdpshare
- Run
azd upcommand to setup the app service resources. - Select subscription and location where to create the app service deployment.
- Run
azd deploycommand to deploy the app service and any further changes in the python app service code.


Question: Why do we need to break up the video insights.json into chunks using the Prompt Content API?
Answer: The sections retrieved from the Video Indexer Prompt Content API allow for the creation of granular records in the vector database. Each of these sections corresponds to a small part of the video. Once the section embedding is generated and subsequently retrieved, the user is shown the relevant time segment in the video.
If you see this error while running azd deploy:
read /tmp/azd1992237260/backend_env/lib64: is a directory
delete the ./app/backend/backend_env folder and re-run the azd deploy command.
This issue is being tracked here: Azure/azure-dev#1237
If the web app fails to deploy and you receive a '404 Not Found' message in your browser, run 'azd deploy'.