We already have several ready-made components that allow us to link LLM with external data in the form of files provided as URLs or paths to files saved on disk. Additionally, we discussed the websearch example, which allowed us a simple connection of the model with the Internet.
The thing is, data sources can also have a different nature. Examples include environmental information (location, apps running on the phone, current weather, or currently playing music). Some of them may be fetched in real-time, while others will be updated cyclically and loaded only when needed. We are thus talking about situations where data do not come from the user but are fetched programmatically, and our system has the right to load them when necessary.
The last example of data also includes those provided by the user or other AI agents during interaction. For instance, during a longer conversation, it is advisable to build the conversation context, which is not entirely delivered to the system prompt.
There is still a missing ability to create content and save files. We have seen several examples of this in previous weeks of AI_devs, but now we will combine them into tools that the model will use.
In this lesson, we will discuss the web example, which combines the logic of examples like loader, summary, translate, websearch, hybrid, and others. This time, however, the responsibility for how to use the tools will largely fall into the hands of the model, although the available logic will still have a fairly linear character and does not provide much room for 'model creativity'.
Below we see a message exchange in which I asked for downloading content from three PDF files containing invoices, loading the specified information, and delivering the result as a link to the .csv file.
It is not difficult to guess that such commands can be automatically sent, e.g., with links to email attachments marked with a selected label. The data source could also be photos from our phone or files uploaded to Dropbox.
However, this is not the end, as various combinations of tool selection allow sending a long file with a request for translation while maintaining full formatting. As you can see, the translation was performed correctly, despite exceeding the "output tokens" limit.
Ultimately, we also have the possibility of downloading selected web page content, which can also be performed by scripts and automations working for us in the background.
The logic of the example is thus to:
- Understand the user's request and arrange a plan based on it.
- Execute individual steps, with the ability to pass context between them. So if the first step is 'browsing the Internet', its result will be available in further stages.
- Among the available actions, there is also the option to upload a file to a server and generate a direct link for it.
- After completing all steps, the model generates the final response.
However, the whole is not ready for every possible scenario and is intended to work for repetitive tasks such as the aforementioned document processing or cyclic information fetching from the Internet.
IMPORTANT: The web logic can handle the following situations:
- Load
file_linkand translate from Polish to English and give me a link to the ready document. - Fetch AI-related entries from
https://news.ycombinator.com/newest. - Summarize this document:
link. - Go to
blogand download today's articles (if there are any). - Go to
blog, download today's articles (if there are any) and summarize them for me.
So we are talking about simple messages that can include processing several sources and passing information between stages.
Language models do not have major problems with generating content for text documents. Markdown, JSON, or CSV can also be programmatically converted into binary formats such as PDF, docx, or xlsx. However, placing the file on disk and generating a link to it must have the form of a tool.
In practice, we will need two file creation methods. One will be available to the user and the other to LLM. For this reason, in the web example, I created the /api/upload endpoint. Although we will not be using it now, it is worth noting a few things:
- The file is loaded as a document and saved in the database.
- The file's metadata includes a conversation identifier.
- In the response, information about the file is returned, including the URL that LLM can use.
Important: In production implementations of such solutions, you need to ensure that:
- We check the
mimeTypeof the uploaded file and reject those that do not comply with the supported formats. - Besides the file type, we should also check its size.
- The link directing to the file should require authentication, e.g., an API key or an active user session.
This endpoint allows us to send files to the application and use them later during conversations based on conversation_uuid.
Creating a file with LLM's help is more complex because we also need to include writing the content. In the web example, the model can save files whose content is entered by it "manually." However, it may happen that the saved file must be a previously generated translation. In this case, we want to avoid rewriting the document, especially since due to the output tokens limit, we may not have such an option. Therefore, I use here a known 'trick' with [[uuid]], indicating documents in context to be replaced with the proper content.
The exact same possibility exists in responses sent to the user. In the image below, we see a fragment of the system prompt containing the documents section with an entry from the previous statement in the form of a list of tools.
So creating files in the case of LLM involves only generating the name and indicating identifiers to be loaded as content. Optionally, the model may include additional formatting of this content and its comments.
Using tools by LLM is a combination of two elements: the programming interface and prompts. The logic can have a more linear character, which we have seen many times so far, or an agency character, capable of stepping outside the established scheme and solving "open-ended" type problems.
This time, we are interested in this "middle" scenario where the model equipped with a series of tools can use them in any order and number of steps. However, it cannot change an already established plan or return to earlier stages. Besides, the system itself is not resistant to 'unforeseen' scenarios, so user commands should be precise. For this reason, it will not work for us in this form productively but can work 'in the background' and save the effects of its work in the database or send them via email.
Such a limitation creates a natural problem of limited initial knowledge. We cannot, therefore, generate all the parameters needed to run the necessary tools immediately. Instead, we can establish a list of steps and note or query them, which have the nature of commands the model generates 'to itself.' The only condition here is to maintain the order of actions.
From lesson S04E01 — Interface, we know that tools must have unique names and operating instructions. Now we find that this will not always be obvious because they can have different complexity and subcategories. For example, file_process, responsible for document processing, currently has 5 different types. Their descriptions are not needed in the initial planning stage, but only when a given type is selected.
Until LLMs have greater attention retention capability (potentially with Differential Transformer), the process of planning and taking action must be divided into small, specialized prompts. The difficulty lies in supplying all the data needed to take further actions at a given stage without adding unnecessary 'noise.'
The web example saves all content in the database as documents, which we discussed in lesson S03E01. Each entry is linked to the current conversation and can optionally be added to search engines. This allows us not only to later use these documents as context but also to flexibly use them in the current interaction.
Below, we see one of such records, whose main content is only the product price read from the invoice. In the metadata, however, there is information providing context about what these numbers are and where they come from.
Information saved in this way can be recalled at any time to the system prompt context along with information about where they come from and where we can learn more about them.
This is how we will save data from external sources and then load them into the conversation as "state," an object representing the model's "short-term memory." In one of my projects, the state includes:
- context (available skills, environmental information, list of actions taken, loaded documents, conversation summaries, discussed keywords, or loaded memories),
- reasoning-related information (current status, available steps, current action plan, reflection on it and active tool),
- conversation information: interaction identifier (for LangFuse purposes), conversation identifier, message list, and related settings.
In other words, when thinking about the conversation context, we will think about combining three things: knowledge from the current interaction, knowledge from long-term memory, and variables controlling logic on the programming side.
The conversation context is a key element of agency systems because it allows executing more complex tasks. Even our web example, despite limitations resulting from its assumptions, can use a simple context allowing information to be passed between stages.
Below we see that the user did not provide the article content in the form of a URL, but only indicated the source from which it should be retrieved.

The assistant correctly broke down this task into smaller steps and used the available context appropriately, passing it between stages.
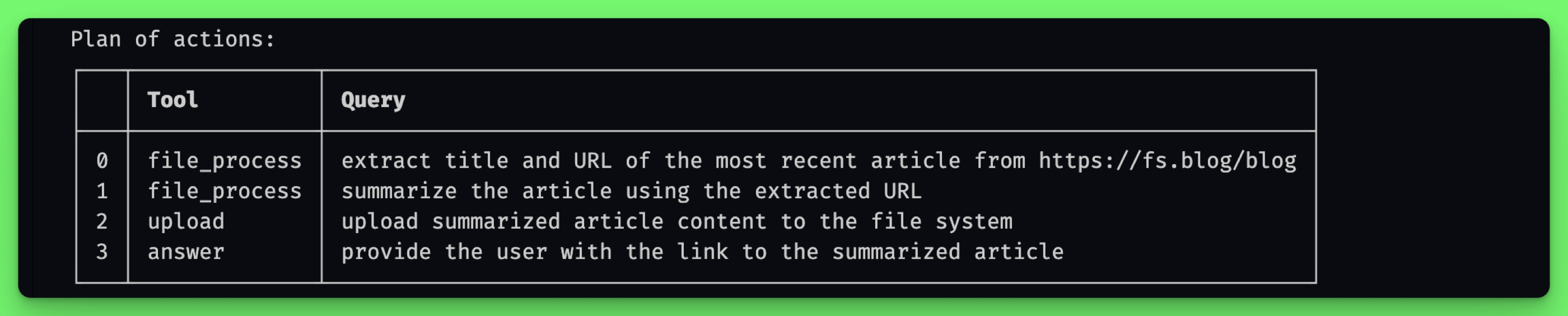
The logic of browsing web pages in the web example is based on generating a list of queries for the search engine and deciding which pages' content should be downloaded. This process may alternatively be shortened to merely retrieving content from a specified URL.
However, there are tools like Code Interpreter (e.g., e2b), BrowserBase, or perhaps familiar to you Playwright or Puppeteer. Specifically, we are talking about automation that involves running generated code and combining the ability to understand text and images for the purposes of making dynamic actions.
Although there are examples online showing the possibilities of autonomous research and Internet browsing for information gathering, it is currently hard to talk about high effectiveness without imposing limitations. Even web scraping itself does not allow for unrestricted browsing of any page and should be configured for access to selected addresses or rely on external solutions like apify.
The web example shows us that an LLM equipped with tools and the mechanics of building and using context can perform complex tasks independently without human intervention. However, the necessary condition (at least for now) is the precise specification of what is available to the model and what is not. Otherwise, problems quickly arise concerning either the model's capabilities or the barriers resulting from the technology itself (e.g., the necessity of logging into a website).