edited predictor.py for caching
![]()
📌 MobileSAMv2, available at ResearchGate and arXiv, replaces the grid-search prompt sampling in SAM with object-aware prompt sampling for faster segment everything(SegEvery).
📌 MobileSAM, available at ResearchGate and arXiv, replaces the heavyweight image encoder in SAM with a lightweight image encoder for faster segment anything(SegAny).
Support for ONNX model export. Feel free to test it on your devices and share your results with us.
A demo of MobileSAM running on CPU is open at hugging face demo. On our own Mac i5 CPU, it takes around 3s. On the hugging face demo, the interface and inferior CPUs make it slower but still works fine. Stayed tuned for a new version with more features! You can also run a demo of MobileSAM on your local PC.
🍇 Media coverage and Projects that adapt from SAM to MobileSAM (Thank you all!)
-
2023/07/03: joliGEN supports MobileSAM for faster and lightweight mask refinement for image inpainting with Diffusion and GAN.
-
2023/07/03: MobileSAM-in-the-Browser shows a demo of running MobileSAM on the browser of your local PC or Mobile phone.
-
2023/07/02: Inpaint-Anything supports MobileSAM for faster and lightweight Inpaint Anything
-
2023/07/02: Personalize-SAM supports MobileSAM for faster and lightweight Personalize Segment Anything with 1 Shot
-
2023/07/01: MobileSAM-in-the-Browser makes an example implementation of MobileSAM in the browser.
-
2023/06/30: SegmentAnythingin3D supports MobileSAM to segment anything in 3D efficiently.
-
2023/06/30: MobileSAM has been featured by AK for the second time, see the link AK's MobileSAM tweet. Welcome to retweet.
-
2023/06/29: AnyLabeling supports MobileSAM for auto-labeling.
-
2023/06/29: SonarSAM supports MobileSAM for Image encoder full-finetuing.
-
2023/06/29: Stable Diffusion WebUIv supports MobileSAM.
-
2023/06/28: Grounding-SAM supports MobileSAM with Grounded-MobileSAM.
-
2023/06/27: MobileSAM has been featured by AK, see the link AK's MobileSAM tweet. Welcome to retweet.
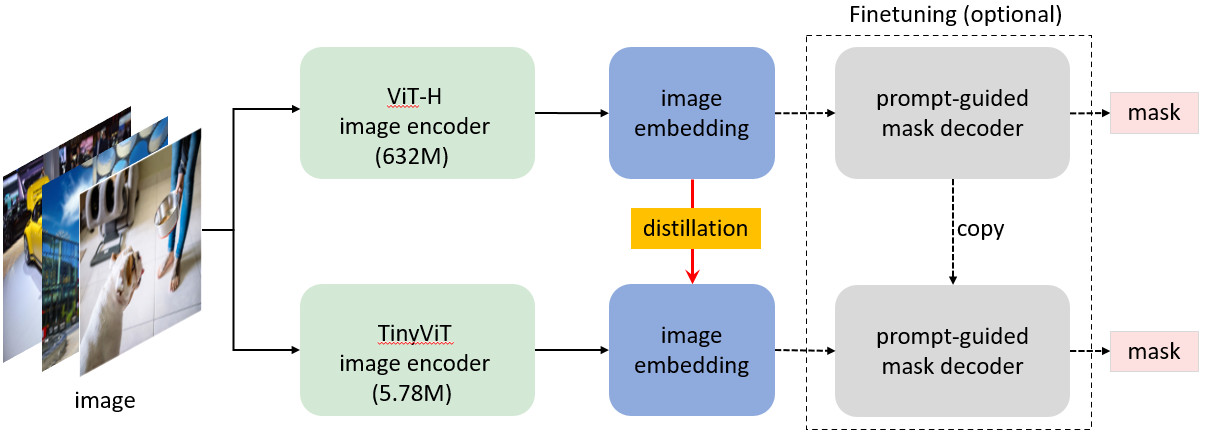

⭐ How is MobileSAM trained? MobileSAM is trained on a single GPU with 100k datasets (1% of the original images) for less than a day. The training code will be available soon.
⭐ How to Adapt from SAM to MobileSAM? Since MobileSAM keeps exactly the same pipeline as the original SAM, we inherit pre-processing, post-processing, and all other interfaces from the original SAM. Therefore, by assuming everything is exactly the same except for a smaller image encoder, those who use the original SAM for their projects can adapt to MobileSAM with almost zero effort.
⭐ MobileSAM performs on par with the original SAM (at least visually) and keeps exactly the same pipeline as the original SAM except for a change on the image encoder. Specifically, we replace the original heavyweight ViT-H encoder (632M) with a much smaller Tiny-ViT (5M). On a single GPU, MobileSAM runs around 12ms per image: 8ms on the image encoder and 4ms on the mask decoder.
-
The comparison of ViT-based image encoder is summarzed as follows:
Image Encoder Original SAM MobileSAM Parameters 611M 5M Speed 452ms 8ms -
Original SAM and MobileSAM have exactly the same prompt-guided mask decoder:
Mask Decoder Original SAM MobileSAM Parameters 3.876M 3.876M Speed 4ms 4ms -
The comparison of the whole pipeline is summarized as follows:
Whole Pipeline (Enc+Dec) Original SAM MobileSAM Parameters 615M 9.66M Speed 456ms 12ms
⭐ Original SAM and MobileSAM with a point as the prompt.

⭐ Original SAM and MobileSAM with a box as the prompt.

💪 Is MobileSAM faster and smaller than FastSAM? Yes! MobileSAM is around 7 times smaller and around 5 times faster than the concurrent FastSAM. The comparison of the whole pipeline is summarzed as follows:
| Whole Pipeline (Enc+Dec) | FastSAM | MobileSAM |
|---|---|---|
| Parameters | 68M | 9.66M |
| Speed | 64ms | 12ms |
💪 Does MobileSAM aign better with the original SAM than FastSAM? Yes! FastSAM is suggested to work with multiple points, thus we compare the mIoU with two prompt points (with different pixel distances) and show the resutls as follows. Higher mIoU indicates higher alignment.
| mIoU | FastSAM | MobileSAM |
|---|---|---|
| 100 | 0.27 | 0.73 |
| 200 | 0.33 | 0.71 |
| 300 | 0.37 | 0.74 |
| 400 | 0.41 | 0.73 |
| 500 | 0.41 | 0.73 |
The code requires python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8. Please follow the instructions here to install both PyTorch and TorchVision dependencies. Installing both PyTorch and TorchVision with CUDA support is strongly recommended.
Install Mobile Segment Anything:
pip install git+https://github.com/ChaoningZhang/MobileSAM.git
or clone the repository locally and install with
git clone [email protected]:ChaoningZhang/MobileSAM.git
cd MobileSAM; pip install -e .
Once installed MobileSAM, you can run demo on your local PC or check out our HuggingFace Demo.
It requires latest version of gradio.
cd app
python app.py
The MobileSAM can be loaded in the following ways:
from mobile_sam import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
model_type = "vit_t"
sam_checkpoint = "./weights/mobile_sam.pt"
device = "cuda" if torch.cuda.is_available() else "cpu"
mobile_sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
mobile_sam.to(device=device)
mobile_sam.eval()
predictor = SamPredictor(mobile_sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
or generate masks for an entire image:
from mobile_sam import SamAutomaticMaskGenerator
mask_generator = SamAutomaticMaskGenerator(mobile_sam)
masks = mask_generator.generate(<your_image>)
Download the model weights from the checkpoints.
After downloading the model weights, faster SegEvery with MobileSAMv2 can be simply used as follows:
cd MobileSAMv2
bash ./experiments/mobilesamv2.sh
MobileSAM now supports ONNX export. Export the model with
python scripts/export_onnx_model.py --checkpoint ./weights/mobile_sam.pt --model-type vit_t --output ./mobile_sam.onnx
Also check the example notebook to follow detailed steps.
We recommend to use onnx==1.12.0 and onnxruntime==1.13.1 which is tested.
If you use MobileSAM in your research, please use the following BibTeX entry. 📣 Thank you!
@article{mobile_sam,
title={Faster Segment Anything: Towards Lightweight SAM for Mobile Applications},
author={Zhang, Chaoning and Han, Dongshen and Qiao, Yu and Kim, Jung Uk and Bae, Sung-Ho and Lee, Seungkyu and Hong, Choong Seon},
journal={arXiv preprint arXiv:2306.14289},
year={2023}
}This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.RS-2022-00155911, Artificial Intelligence Convergence Innovation Human Resources Development (Kyung Hee University))
SAM (Segment Anything) [bib]
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}TinyViT (TinyViT: Fast Pretraining Distillation for Small Vision Transformers) [bib]
@InProceedings{tiny_vit,
title={TinyViT: Fast Pretraining Distillation for Small Vision Transformers},
author={Wu, Kan and Zhang, Jinnian and Peng, Houwen and Liu, Mengchen and Xiao, Bin and Fu, Jianlong and Yuan, Lu},
booktitle={European conference on computer vision (ECCV)},
year={2022}