| title | shortTitle | category | tag | description | author | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
解决中文乱码:字符编码全攻略 - ASCII、Unicode、UTF-8、GB2312详解 |
中文乱码及字符编码全攻略 |
|
|
本文深入探讨中文乱码及字符编码问题,详细介绍了ASCII、Unicode、UTF-8、GB2312等编码格式的原理与特点。通过理解字符编码的发展历程,可以更好地解决中文乱码问题。本文还将探讨不同编码之间的转换方法,帮助程序员在编程过程中轻松应对字符编码问题,提高代码质量和可读性。 |
沉默王二 |
|
就在昨天,我在二哥的编程星球里看到这样一张截图,有球友反馈说支付宝的理财页面出现了中文乱码,估计不少小伙伴和我一样,都惊呆了😮!阿里这种大厂还能出现这种低级错误?
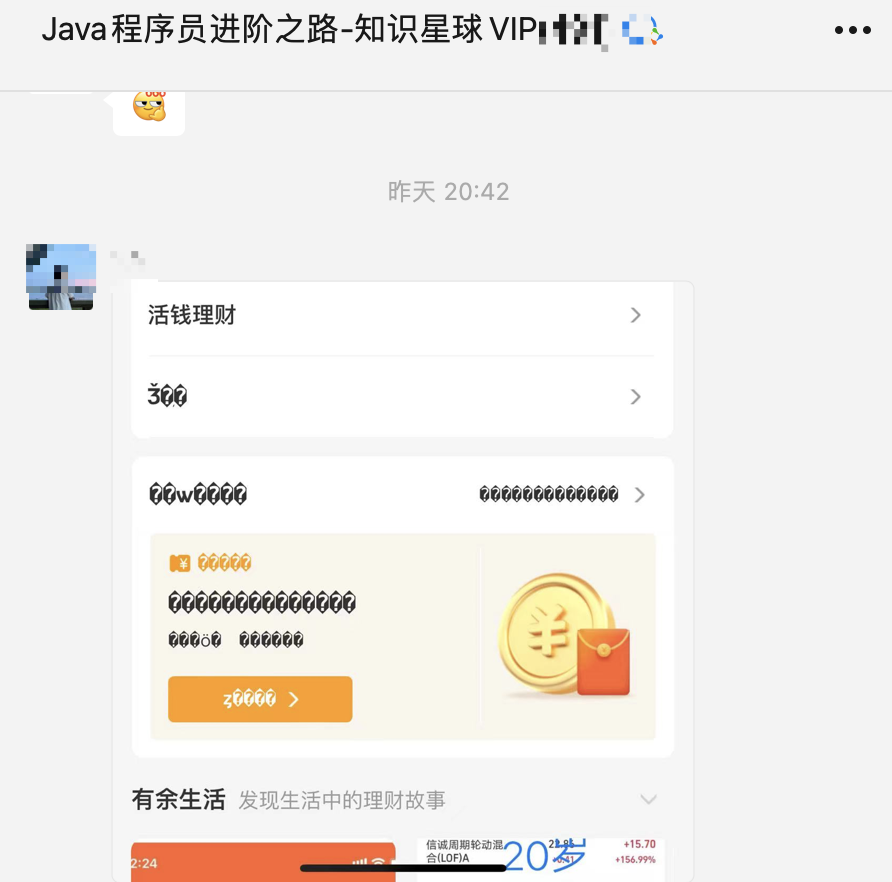
难道昨天的人力都投入到“通义千问”的突然发布上了?
那借这个机会,我就来和大家探讨一下,中文乱码是怎么出现的,以及如何快速解决乱码问题。
Q:什么是中文乱码?
GPT4:中文乱码是指在计算机系统或软件中,由于字符编码不一致或处理不当,导致中文字符无法正常显示,出现乱码现象。这种现象通常表现为中文字符被替换成其他不相关的字符、符号或乱码。
比如说,历史上著名的“锟斤拷”同学,就是中文乱码的绝佳代言人。
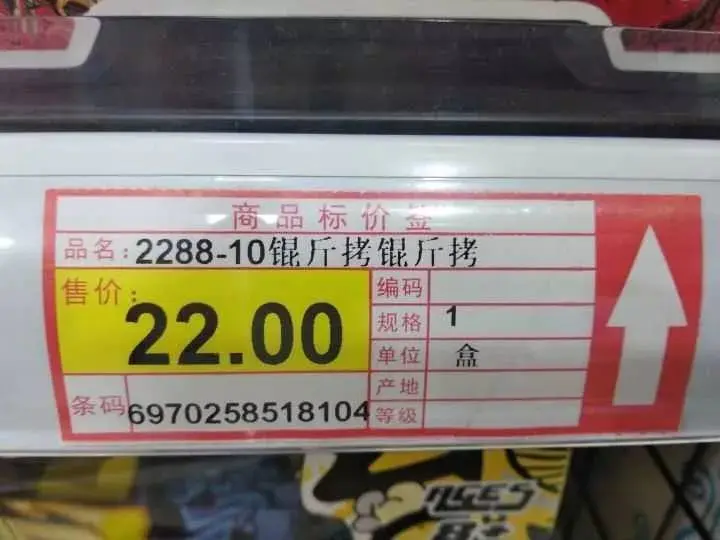
Q:那什么是字符编码呢?
GPT4:字符编码(Character Encoding)是一种规则或约定,它将字符(如字母、数字、标点符号等)映射到计算机中的二进制数据。简单来说,字符编码就是将人类可读的字符转换为计算机可以处理的二进制数据的过程。
对于计算机来说,只认 0 和 1,所有的信息最终都是一个二进制数。一个二进制数要么是 0,要么是 1。8 个二进制数放在一起是一个字节,就会组合出 256 种状态,也就是 2 的 8 次方(2^8),从 00000000 到 11111111。
为了让计算机能够识别和处理各种字符,需要使用字符编码来对字符进行编码和解码。常见的字符编码包括 ASCII、UTF-8、UTF-16、GBK、GB2312 等。
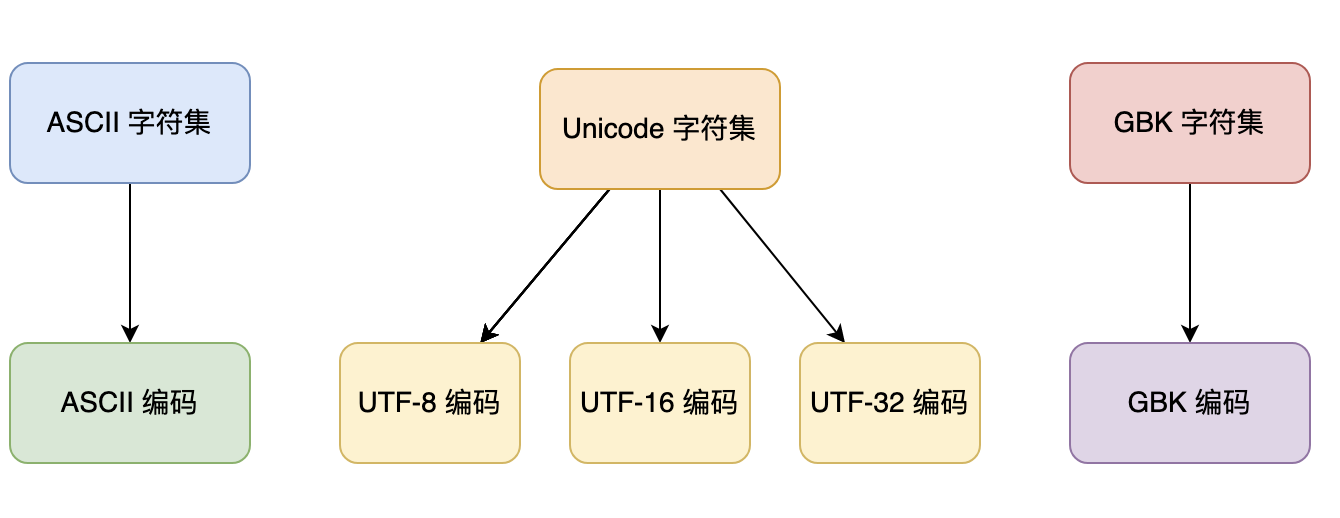
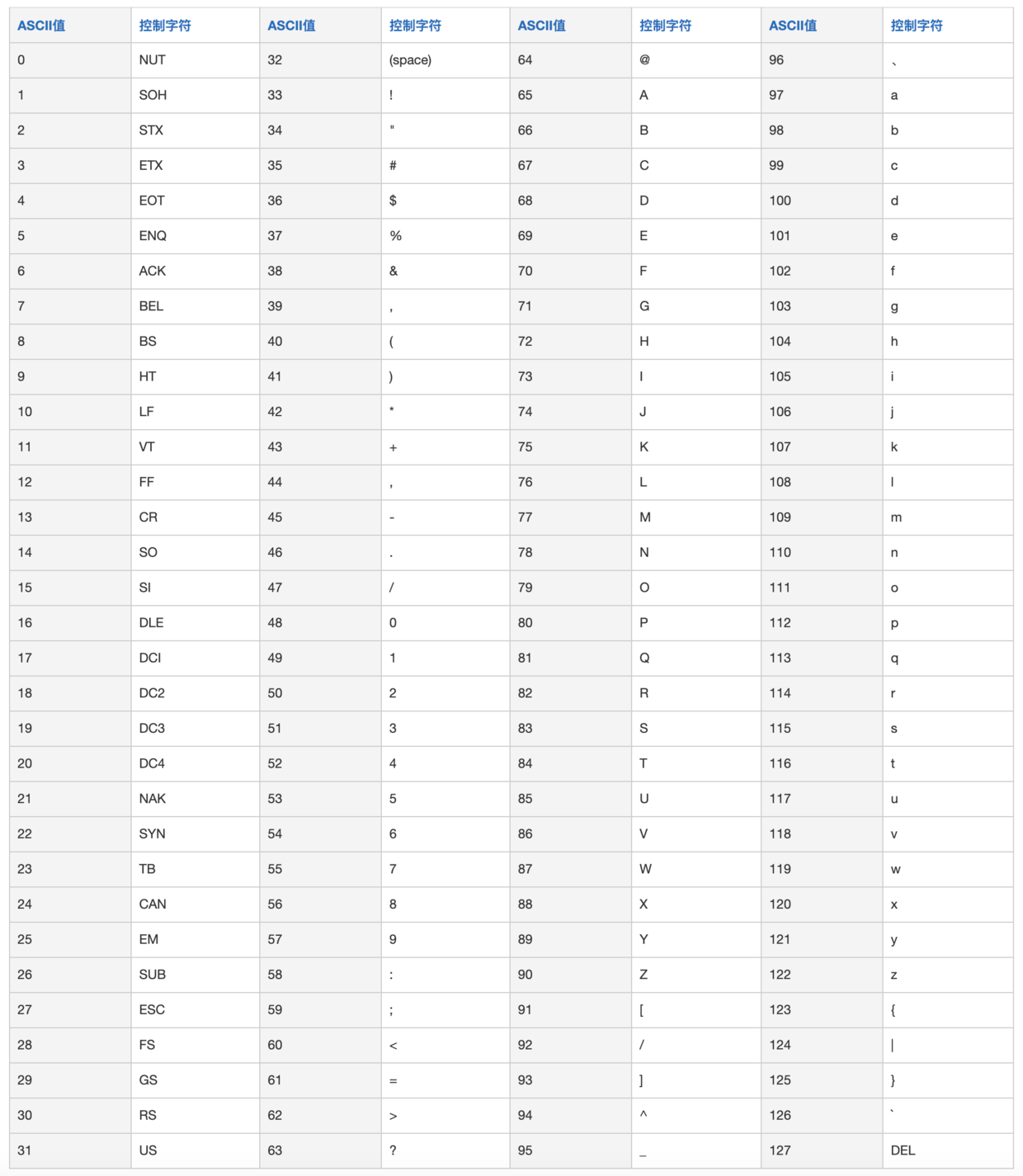
ASCII 码由电报码发展而来,第一版标准发布于 1963 年,最后一次更新则是在 1986 年,至今为止共定义了 128 个字符。其中 33 个字符无法显示在一般的设备上,需要用特殊的设备才能显示。
ASCII 码的局限在于只能显示 26 个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语,对于其他一些语言则无能无力,比如在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
PS:拉丁字母(也称为罗马字母)是多数欧洲语言采用的字母系统,是世界上最通行的字母文字系统,是罗马文明的成果之一。
虽然名称上叫作拉丁字母,但拉丁文中并没有用 J、U 和 W 这三个字母。
在我的印象中,可能说拉丁字母多少有些陌生,说英语字母可能就有直观的印象了。

阿拉伯数字,我们都很熟悉了。

但是,阿拉伯数字并非起源于阿拉伯,而是起源于古印度。学过历史的你应该有一些印象,阿拉伯分布于西亚和北非,以阿拉伯语为主要语言,以伊斯兰教为主要信仰。

处在这样的地理位置,做起东亚和欧洲的一些生意就很有优势,于是阿拉伯数字就由阿拉伯人传到了欧洲,因此得名。
英式标点符号,也叫英文标点符号,和中文标点符号很相近。标点符号是辅助文字记录语言的符号,是书面语的组成部分,用来表示停顿、加强语气等。
英文标点符号在 16 世纪时,分为朗诵学派和句法学派,主要由古典时期的希腊文和拉丁文演变而来,在 17 世纪后进入稳定阶段。俄文的标点符号依据希腊文而来,到了 18 世纪后也采用了英文标点符号。
在很多人的印象中,古文是没有标点符号的,但管锡华博士研究指出,中国早在先秦时代就有标点符号了,后来融合了一些英文标点符号后,逐渐形成了现在的中文标点符号。
这个世界上,除了英语,还有法语、葡萄牙语、西班牙语、德语、俄语、阿拉伯语、韩语、日语等等等等。ASCII 码用来表示英语是绰绰有余的,但其他这些语言就没办法了。
像我的主人二哥的母语——中文,就博大精深,与其对应的汉字数量很多很多,东汉的《说文解字》收字 9353 个,清朝《康熙字典》收字 47035 个,当代的《汉语大字典》收字 60370 个。1994 年中华书局、中国友谊出版公司出版的《中华字海》收字 85568 个。
常用字大概 2500 个,次常用字 1000 个。
一个字节只能表示 256 种符号,所以如果拿 ASCII 码来表示汉字的话,是远远不够用的,那就必须要用更多的字节。简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,理论上最多可以表示 256 x 256 = 65536 个符号。
要知道,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
- 编码就是将原始数据(比如说文本、图像、视频、音频等)转换为二进制形式。
- 解码就是将二进制数据转换为原始数据,是一个反向的过程。
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会彻底消失。
这个艰巨的任务由谁来完成呢?Unicode,中文译作万国码、国际码、统一码、单一码,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 至今仍在不断增修,每个新版本都会加入更多新的字符。目前最新的版本为 2020 年 3 月公布的 13.0,收录了 13 万个字符。

Unicode 是一个很大的集合,现在的规模可以容纳 100 多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A,U+4E25 表示汉字严。
具体的符号对应表,可以查询:
- unicode.org:http://www.unicode.org
- 汉字对应表:ttp://www.chi2ko.com/tool/CJK.htm
曾有人这样说:
Unicode 支持的字符上限是 65536 个,Unicode 字符必须占两个字节。
但这是一种误解,记住,Unicode 只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节,所以它可以无穷大。
Unicode 虽然统一了全世界字符的编码,但没有规定如何存储。如果统一规定的话,每个符号就要用 3 个或 4 个字节表示,因为 2 个字节只能表示 65536 个,根本表示不全。
那怎么办呢?
UTF(Unicode Transformation Formats,Unicode 的编码方式)来了!最常见的就是 UTF-8 和 UTF-16。
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:一个字节;
- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是一种可变长度的编码方式——这是它的优势也是劣势。
怎么讲呢?优势就是它包罗万象,劣势就是浪费空间。举例来说吧,UTF-8 采用了 3 个字节(256*256*256=16777216)来编码常用的汉字,但常用的汉字没有这么多,这对于计算机来说,就是一种严重的资源浪费。
基于这样的考虑,中国国家标准总局于 1980 年发布了 GB2312 编码,即中华人民共和国国家标准简体中文字符集。GB2312 标准共收录 6763 个汉字(2 个字节就够用了),其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GB2312 的出现,基本满足了汉字的计算机处理需求。对于人名、古汉语等方面出现的罕用字和繁体字,GB2312 不能处理,就有了 GBK(K 为“扩展”的汉语拼音(kuòzhǎn)第一个声母)。
Q:来一串出现中文乱码的 demo,中文为沉默王二
GPT4:下面是一个可能导致中文乱码的示例。首先使用 GBK 编码将中文字符串 "沉默王二" 转换为字节数组,然后使用 UTF-8 编码将字节数组转回字符串。这将导致字符串在解码时出现乱码。
public class EncodingDemo {
public static void main(String[] args) {
String originalStr = "沉默王二";
String encodedStr = "";
try {
byte[] bytes = originalStr.getBytes("GBK");
encodedStr = new String(bytes, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
System.out.println("转码前: " + originalStr);
System.out.println("转码后: " + encodedStr);
}
}程序会输出什么呢?
转码前: 沉默王二
转码后: ��Ĭ����
嘿嘿,乱码来了!在 Unicode 中,� 是一个特殊的符号,它用来表示无法显示,它的十六进制是 0xEF 0xBF 0xBD。那么两个 �� 就是 0xEF 0xBF 0xBD 0xEF 0xBF 0xBD,如果用 GBK 进行解码的话,就是大名鼎鼎的“锟斤拷”。
可以通过代码来验证一下:
// 输出 efbfbdefbfbd
char[] kuijinkao = HexUtil.encodeHex("��", StandardCharsets.UTF_8);
System.out.println(kuijinkao);
// 借助 hutool 转成二进制
byte[] testBytes = HexUtil.decodeHex(kuijinkao);
// 使用 GBK 解码
String testResult = new String(testBytes, Charset.forName("GBK"));
// 输出锟斤拷
System.out.println(testResult);来看一下输出结果:
efbfbdefbfbd
锟斤拷所以,以后再见到锟斤拷,第一时间想到 UTF-8 和 GBK 的转换问题准没错。
Q:如何解决中文乱码呢?
GPT4:解决中文乱码问题需要确保在编码和解码过程中使用相同的字符编码。这是一个修改过的示例,展示了如何避免中文乱码问题:
String originalStr = "沉默王二";
byte[] bytes = originalStr.getBytes(StandardCharsets.UTF_8);
String encodedStr = new String(bytes, StandardCharsets.UTF_8);
System.out.println("正确转码前: " + originalStr);
System.out.println("正确转码后: " + encodedStr);输出结果:
正确转码前: 沉默王二
正确转码后: 沉默王二除此之外,以下是一些避免乱码的实践:
- 使用统一的字符编码,如 UTF-8。它包含了所有 Unicode 字符,并且广泛支持。确保在所有平台和系统上使用相同的编码。
- 在处理文本文件时,始终明确指定字符编码。例如,在 Java 中使用 InputStreamReader、OutputStreamWriter 时,指定编码参数。
- 在 HTML、XML 等文档中,指定字符编码。例如,在 HTML 页面中添加
<meta charset="UTF-8">。 - 对于数据库,确保使用正确的字符集。在创建数据库和表时,明确指定字符集,如 utf8mb4。
当与第三方服务通信时,确保双方使用相同的字符编码。在处理 API 请求和响应时,检查字符编码是否匹配。
Q:针对支付宝这种生产环境事故,如何快速定位并解决问题呢?
GPT4:
1、收集信息:了解问题的具体表现,例如哪些页面或功能受到影响,问题的严重程度,以及用户反馈。这将有助于快速定位问题范围。
2、检查日志:查看服务器日志和应用程序日志,检查是否存在异常信息或错误。日志信息有助于识别问题发生的时间和具体原因。
3、复现问题:在测试环境中尝试复现问题,以便更深入地了解问题细节。如果无法复现问题,可能需要进一步收集生产环境的详细信息。
4、定位问题:根据收集到的信息,确定问题可能发生的代码或系统部分。检查相关代码,特别是涉及字符编码、数据传输、数据库操作的部分。
5、解决问题:修复问题代码,确保字符编码在整个系统中保持一致。进行单元测试和集成测试,验证问题是否已解决。
6、部署修复:将修复后的代码部署到生产环境。为了避免影响正常服务,可以考虑先在一个小规模的生产环境中进行验证,然后逐步扩大部署范围。
7、监控:在修复后持续关注系统运行状况,确保问题已得到解决。收集用户反馈,确认用户满意度。
8、总结经验:针对此次问题,总结经验教训,分析问题产生的根本原因,优化开发和测试流程,避免类似问题再次发生。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
