
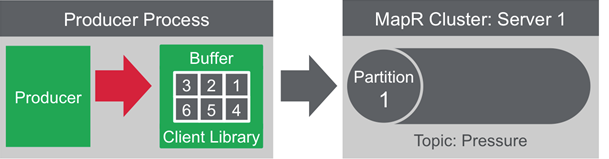
- Partition Id
- Hash of messageId
- Round-Robin
mapr streamanalyzer -path /mapr/dp.prod.zur/vantage/orchestr/streams/my-own-test -topics cherkavi-test -printMessages true -countMessages
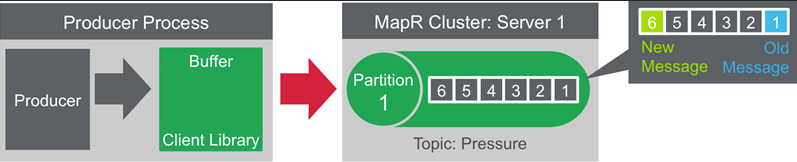
- by partition number
- by message key
- round-robin ( without previous two )
- properties.put("streams.patitioner.class", "my.package.MyClassName.class")
public class MyClassName implements Partitioner{
public int partition( String topic, Object, key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){}
}


- Read cursor ( client request it and broker sent )
- Committed cursor ( client confirmed/commited reading )

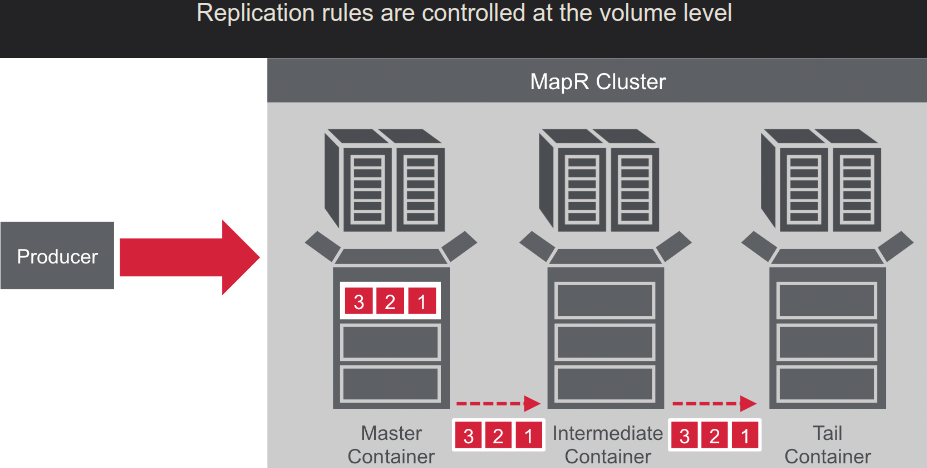
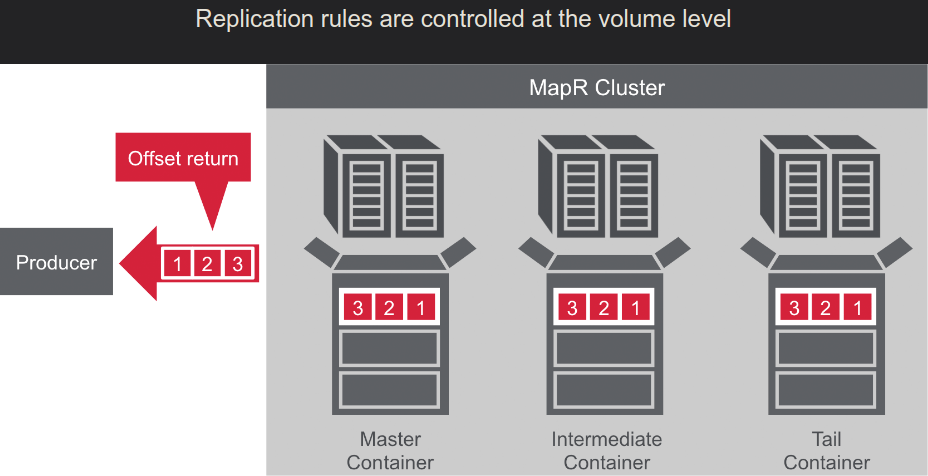
- Master->Slave
- Many->One
- MultiMaster: Master<-->Master
- Stream replications: Node-->Node2-->Node3-->Node4 ... ( with loop preventing )
maprcli node listcldbs
maprcli stream create -path <filepath & name>
maprcli stream create -path <filepath & name> -consumeperm u:<userId> -produceperm u:<userId> -topicperm u:<userId>
maprcli stream create -path <filepath & name> -consumeperm "u:<userId>" -produceperm "u:<userId>" -topicperm "u:<userId>" -adminperm "u:<userId1> | u:<userId2>"
maprcli stream info -path {filepath}
maprcli stream delete -path <filepath & name>
maprcli stream topic create -path <path and name of the stream> -topic <name of the topic>
maprcli stream topic delete -path <path and name of the stream> -topic <name of the topic>
maprcli stream topic list -path <path and name of the stream>
javac -classpath `mapr classpath` MyConsumer.java
java -classpath kafka-clients-1.1.1-mapr-1808.jar:slf4j-api-1.7.12.jar:slf4j-log4j12-1.7.12.jar:log4j-1.2.17.jar:mapr-streams-6.1.0-mapr.jar:maprfs-6.1.0-mapr.jar:protobuf-java-2.5.0.jar:hadoop-common-2.7.0.jar:commons-logging-1.1.3-api.jar:commons-logging-1.1.3.jar:guava-14.0.1.jar:commons-collections-3.2.2.jar:hadoop-auth-2.7.0-mapr-1808.jar:commons-configuration-1.6.jar:commons-lang-2.6.jar:jackson-core-2.9.5.jar:. MyConsumer
Properties properties = new Properties();
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("client.id", <client id>)
import org.apache.kafka.clients.producer.KafkaProducer;
KafkaProducer producer = new KafkaProducer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, messageTextKey, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, partitionIntNumber, textOfMessage);
Callback callback = new Callback(){
public void onCompletion(RecordMetadata meta, Exception ex){
meta.offset();
}
};
producer.send(record, callback);
producer.close();

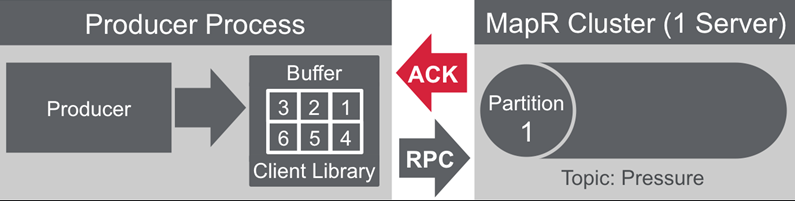
streams.parallel.flushers.per.partition default true:
- does not wait for ACK before sending more messages
- possible for messages to arrive out of order
streams.parallel.flushers.per.partition set to false:
- client library will wait for ACK from server
- slower than default setting
metadata.max.age.ms
How frequently to fetch metadata
Properties properties = new Properties();
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("auto.offset.reset", <Earliest, Latest, None>)
// properties.put("group.id", <group identificator>)
// properties.put("enable.auto.commit", <true - default | false >), use consumer.commitSync() if false
// properties.put("auto.commit.interval.ms", <default value 1000ms>)
import org.apache.kafka.clients.consumer.KafkaConsumer;
KafkaConsumer consumer = new KafkaConsumer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
consumer.subscribe(Arrays.asList(topic));
// consumer.subscribe(topic, new RebalanceListener());
ConsumerRecords<String, String> messages = consumer.poll(1000L); // reading with timeout
messages.iterator().next().toString(); // "/streams/my-stream:topic-name, parition=1, offset=256, key=one, value=text"
public class RebalanceListener implements ConsumerRebalanceListener{
onPartitionAssigned(Collection<TopicPartition> partitions)
onPartitionRevoked(Collection<TopicPartition> partitions)
}
(maven repository)[https://repository.mapr.com/nexus/content/repositories/releases/]
<repositories>
<repository>
<id>mapr-maven</id>
<url>http://repository.mapr.com/maven</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0-mapr-1602-streams-5.1.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
execute on cluster
mapr classpath
java -cp `mapr classpath`:my-own-app.jar mypackage.MainClass
curl_user="cluster_user"
curl_pass="cluster_user_password"
stream_path="%2Fvantage%2Forchestration%2Fstreams%2Fpipeline"
topic_name="gateway"
host="https://ubsdpdesp000001.vantage.org"
port=8082
# maprcli stream topic list -path $stream_path # need to replace %2 with /
curl -u $curl_user:$curl_pass \
--insecure -s -X GET \
-H "Content-Type: application/vnd.kafka.v2+json" \
$host:$port/topics/$stream_path%3A$topic_namemaprlogin password -user {your cluster username}
# long term ticket
maprlogin password -user {your cluster username} -duration 30:0:0 -renewal 90:0:0
maprlogin print
maprlogin logout
maprlogin print -ticketfile <your ticketfile>
# you will see expiration date like
# on 07.05.2019 13:56:47 created = 'Tue Apr 23 13:56:47 UTC 2019', expires = 'Tue May 07 13:56:47 UTC 2019'
maprcli dashboard info -json
keys
$ wget -O - https://package.mapr.com/releases/pub/maprgpg.key | sudo apt-key add -add these lines to /etc/apt/sources.list:
deb https://package.mapr.com/releases/v6.1.0/ubuntu binary trusty
deb https://package.mapr.com/releases/MEP/MEP-6.0.0/ubuntu binary trusty
installation
apt-get update
# apt-get install mapr-posix-client-basic
apt-get install mapr-posix-client-platinumconfiguration
sudo mkdir /mapr
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/mapr-clusters.conf /opt/mapr/conf/mapr-clusters.conf
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/ssl_truststore /opt/mapr/conf/ssl_truststorelogin
echo "$PASSWORD" | maprlogin password -user $USERNAME -out /tmp/mapruserticket