- Elasticsearch
There are a few concepts that are core to Elasticsearch. Understanding these concepts from the outset will tremendously help ease the learning process.
Elasticsearch is a near real time search platform -> slight latency (~1 second) from the time you index a document until the time it becomes searchable.
- A cluster is a collection of one or more nodes (servers) that together holds your entire data and pprovides federated indexing and search capabilities across all nodes.
- A cluster is identified by a unique name which by default is "elasticsearch".
- A node is a single server that is part of your cluster, stores your data, and participates in the cluster's indexing and search capabilities.
- A node is identified by a name which by default is a random Universally Unique IDentifier (UUID) that is assigned to the node at the startup.
- An index is a collection of documents that have somewhat similar characterisitics.
- An index is identified by a name (that must be all lowercase) and this name is sued to refer to the index when performing indexing search, update, and delete operations against the documents in it.
- A document is a basic unit of information that can be indexed.
- The document is expressed in JSON.
- Within an index, you can store as many documents as you want.
- An index can potentially store a large amount of data that can exceed the hardware limits of a single node.
- To solve this problem, Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent "index" that be hosted on any node in the cluster.
- Sharding is important for two primary reasons:
- It allows you to horizontally split/scale your content volume.
- It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput.
- Failover mechanism in case a shard/node somehow goes offline or disappears for whatever reasons: Make one/more copies of index's shards into what are called replica shards or replicas for short.
- Replication is important for two primary reasons:
- It provides high availability in case a shard/node fails. A replica shard is never allocated on the same node as the original/primary shard that it was copied from.
- It allows you to scale out your search volume/throughput since searches can be executed on all replicas in parallel.
- To summarize, each index can be split into multiple shards. An index can also be replicated zero (meaning no replicas) or more times. Once replicated, each index will have primary shards (the original shards that were replicated from) and replica shards.
- By default, each index is allocated 5 primary shards and 1 replica (2 nodes -> index - 5 primary shards and another 5 replica shards (1 complete replica) -> 10 shards/index)
- Elasticsearch is built on top of Lucene, which is a data storage and retrieval engine. What are called "shards" in Elasticsearch parlance are technically Lucene instances.
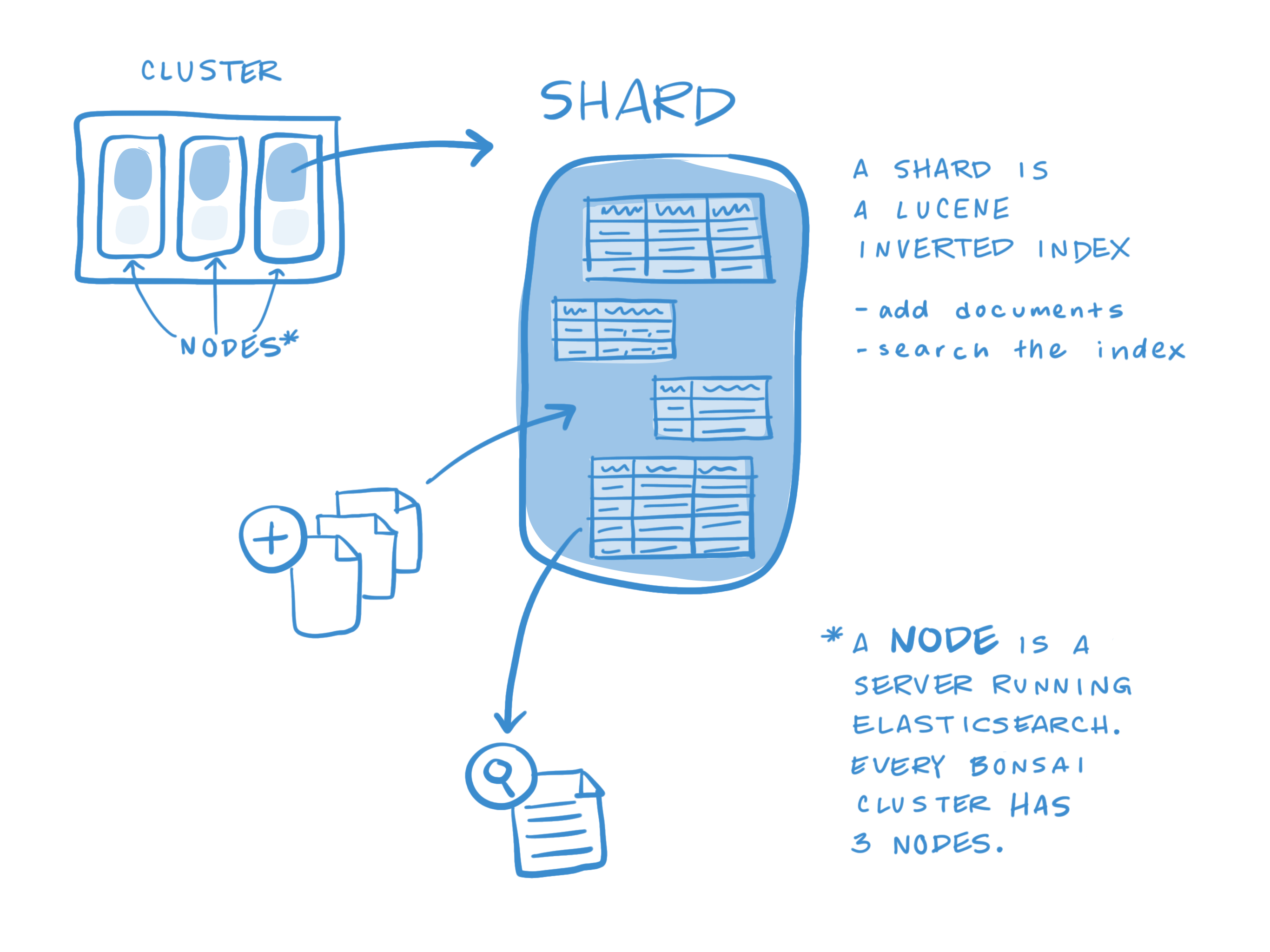
- Elasticsearch index is created -> will be composed of one or more shards.
- Shards play one of two roles: primary or replica.
- The number of primary shards can not be changed after an index has been created, but replica can.
- Replica shards are not only capable of serving search traffic, but they also provide a level of protection against data loss. If a node hosting a primary shard is taken offline for some reason, Elasticsearch will promote its replica to a primary role.
- Replicas are a multiplier on the primary shards, and the total is calculated as
primary * (1+replicas).

- Measure your cluster's index and shard usage"
$ curl -XGET http://<elasticsearch>/_cat/shards?v
index shard pri rep state docs store ip node
-
Deleting Unneeded Indices
-
Use a Different sharding scheme. _Reduce replication _ Data collocation
-
How to change the default amount of shards and replicas of indices? * Option 1: Change in
elasticsearch.ymlfile:index.number_of_shards: 7 index.number_of_replicas: 2* Option 2: Use index templatePUT _template/all { "template": "*", "settings": { "number_of_shards": 7, "number_of_replicas": 2 } }
-
Once analyzed strings have been loaded into fielddata -> sit there until evicted (or node crashed) -> Check memory usage
-
Query, return 100 hits, but fielddata will be loaded for all documents.
-
Load all fielddata structure values once, keep in memory.
-
The JVM heap - choose a Heap Size - $ES_HEAP_SIZE
- Check JVM heap:
GET /_nodes/stats/jvm?pretty- No more than 50% of available RAM: Lucense makes good use of the filesystem cache, which are managed by the kernel. Without enough filesystem cache space, performance will suffer.
- No more than 32GB: If the heap < 32 GB, the JVM can use compressed pointers which saves a lot of memory: 4 bytes per pointers instead of 8 bytes.
- Swapping is the Death of Performance: An in-memory operation is one that needs to execute quickly. If memory swaps to disk, 100-microsecond operation becomes one that take 10 milliseconds. The best thing to do is disable swap completely.
-
Fielddata Size: the
indices.fielddata.cache.sizecontrols how much heap space is allocated to fielddata. -
Monitoring fielddata:
- per-index using the
indices-stats API:
GET /_stats/fielddata?fields=*- per-node using the
nodes-stats API:
GET /_nodes/stats/indices/fielddata?fields=*- Or even per-index per-node:
GET /_nodes/stats/indices/fielddata?level=indices&fields=* - per-index using the
-
Circuit Breaker
-
Refs:
- Elasticsearch provides failover capabilities by keep multiple copies of your data in the cluster.
- Source
node-statsAPI:
GET _nodes/stats
"indices": {
"docs": { # docs show how many documents reside on this node, as well as the number deleted docs that haven't been purged from segment yet.
"count": 6163666,
"deleted": 0
},
"store": { # How much physical storage is consumed by the node.
"size_in_bytes": 2301398179,
"throttle_time_in_millis": 122850
},
"indexing": { # Show the number of docs that have been indexed.
"index_total": 803441,
"index_time_in_millis": 367654,
"index_current": 99,
"delete_total": 0,
"delete_time_in_millis": 0,
"delete_current": 0
},
"get": {
"total": 6,
"time_in_millis": 2,
"exists_total": 5,
"exists_time_in_millis": 2,
"missing_total": 1,
"missing_time_in_millis": 0,
"current": 0
},
"search": {
"open_contexts": 0,https://sematext.com/blog/elasticsearch-guide
"fetch_time_in_millis": 55,
"fetch_current": 0
},
"merges": {
"current": 0,
"current_docs": 0,
"current_size_in_bytes": 0,
"total": 1128,
"total_time_in_millis": 21338523,
"total_docs": 7241313,
"total_size_in_bytes": 5724869463
},"jvm": {
"timestamp": 1408556438203,
"uptime_in_millis": 14457,
"mem": { # General stas about heap memory usage
"heap_used_in_bytes": 457252160,
"heap_used_percent": 44, # Elasticsearch is configured to initiate GCs when the heap reachs 75% full. If heap_used_percent >=75%, memory pressure. if heap_used_percent >- 85%, trouble. if heap_used_percent >= 90-95%, very bad.
"heap_committed_in_bytes": 1038876672,
"heap_max_in_bytes": 1038876672,
"non_heap_used_in_bytes": 38680680,
"non_heap_committed_in_bytes": 38993920,
...
"pools": { # Memory usage of each generation in the GC.
"young": {
"used_in_bytes": 138467752,
"max_in_bytes": 279183360,
"peak_used_in_bytes": 279183360,
"peak_max_in_bytes": 279183360
},
"survivor": {
"used_in_bytes": 34865152,
"max_in_bytes": 34865152,
"peak_used_in_bytes": 34865152,
"peak_max_in_bytes": 34865152
},
"old": {
"used_in_bytes": 283919256,
"max_in_bytes": 724828160,
"peak_used_in_bytes": 283919256,
"peak_max_in_bytes": 724828160
}
}
...
"gc": { # Show the garbage collection counts and cumulative time for both young & old generations.
"collectors": {
"young": {
"collection_count": 13,
"collection_time_in_millis": 923
},
"old": {
"collection_count": 0,
"collection_time_in_millis": 0
}
}
}
},
- Maintains threadpools internally.
"index": {
"threads": 1, # number of threads
"queue": 0, # How many work untils are sitting in a queue
"active": 0, # How many of those threads are actively processing somw work
"rejected": 0,
"largest": 1,
"completed": 1
}
- Keep an eye on:
- "indexing": Threadpool for normal indexing requests
- "bulk": Bulk requests, which are distinct from the nonbuilk indexing requests
- "get": Get-by-ID operations
- "search": All search and query requests
- "merging": Threadpool dedicated to manager Lucene merges