|
22 | 22 | "colab_type": "text" |
23 | 23 | }, |
24 | 24 | "source": [ |
25 | | - "<a href=\"https://colab.research.google.com/github/cwkeam/blog/blob/cwkeam%2Fconstrained-beam-search/notebooks/53_constrained_beam_search.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" |
| 25 | + "<a href=\"https://colab.research.google.com/github/huggingface/blog/blob/master/notebooks/53_constrained_beam_search.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" |
26 | 26 | ] |
27 | 27 | }, |
28 | 28 | { |
|
55 | 55 | "\n", |
56 | 56 | "$S_{expected} = \\{ s_1, s_2, ..., s_k, t_1, t_2, s_{k+1}, ..., s_n \\}$ \n", |
57 | 57 | "\n", |
58 | | - "The problem is that beam search generates the sequence *token-by-token*. Though not entirely accurate, one can think of beam search as the function $B(\\mathbf{s}_{0:i}) = s_{i+1}$, where it looks as the currently generated sequence of tokens from $0$ to $i$ then predicts the next token at $i+1$. But how can this function know, at an arbitrary step $i < k$, that the tokens must be generated at some future step $k$? Or when it's at the step $i=k$, how can it know for sure that this is the best spot to force the tokens, instead of some future step $i>k$?\n", |
| 58 | + "The problem is that beam search generates the sequence *token-by-token*. Though not entirely accurate, one can think of beam search as the function $B(\\mathbf{s}_{0:i}) = s_{i+1}$, where it looks at the currently generated sequence of tokens from $0$ to $i$ then predicts the next token at $i+1$. But how can this function know, at an arbitrary step $i < k$, that the tokens must be generated at some future step $k$? Or when it's at the step $i=k$, how can it know for sure that this is the best spot to force the tokens, instead of some future step $i>k$?\n", |
59 | 59 | "\n", |
60 | 60 | "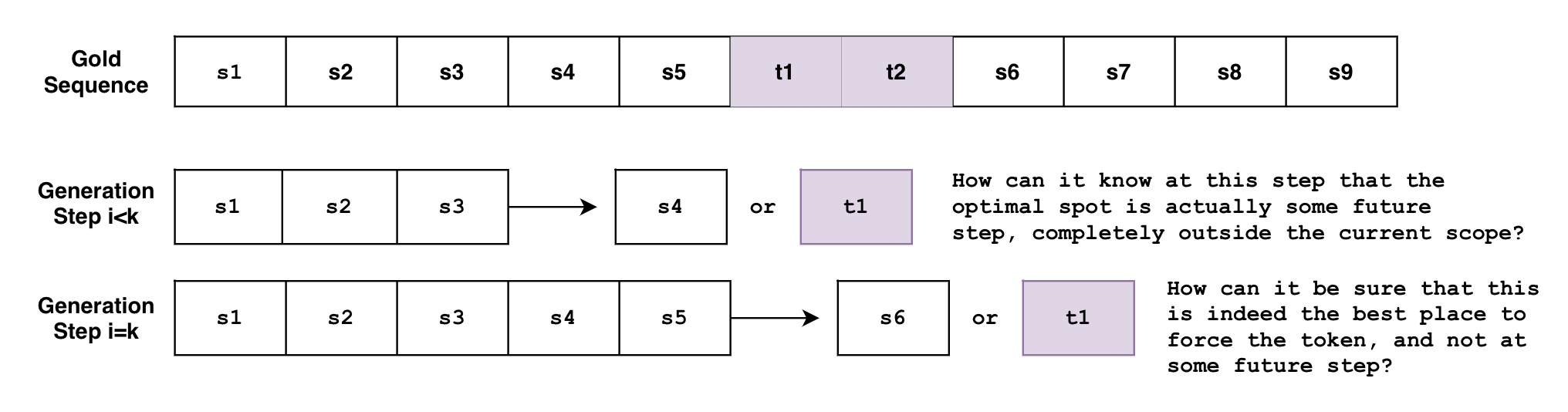\n", |
61 | 61 | "\n", |
62 | 62 | "\n", |
63 | 63 | "And what if you have multiple constraints with varying requirements? What if you want to force the phrase $p_1=\\{t_1, t_2\\}$ *and* also the phrase $p_2=\\{ t_3, t_4, t_5, t_6\\}$? What if you want the model to **choose between** the two phrases? What if we want to force the phrase $p_1$ and force just one phrase among the list of phrases $\\{p_{21}, p_{22}, p_{23}\\}$? \n", |
64 | 64 | "\n", |
65 | | - "The above are actually very reasonable use-cases, as it will be shown below, and the new constrained beam search feature allows for all of them!\n", |
| 65 | + "The above examples are actually very reasonable use-cases, as it will be shown below, and the new constrained beam search feature allows for all of them!\n", |
66 | 66 | "\n", |
67 | 67 | "This post will quickly go over what the new ***constrained beam search*** feature can do for you, and then go into deeper details about how it works under the hood." |
68 | 68 | ] |
|
325 | 325 | "\n", |
326 | 326 | "Though we end up *considering* significantly more than `num_beams` outputs, we reduce them down to `num_beams` at the end of the step. We can't just keep branching out, then the number of `beams` we'd have to keep track of would be $beams^{n}$ for $n$ steps, which becomes very large very quickly ($10$ beams after $10$ steps is $10,000,000,000$ beams!). \n", |
327 | 327 | "\n", |
328 | | - "For the rest of the generation, we repeat the above step until an ending criteria has been met, like generating the `<eos>` token or reaching `max_length`, for example. Branch out, rank, reduce, and repeat.\n", |
| 328 | + "For the rest of the generation, we repeat the above step until the ending criteria has been met, like generating the `<eos>` token or reaching `max_length`, for example. Branch out, rank, reduce, and repeat.\n", |
329 | 329 | "\n", |
330 | 330 | "\n", |
331 | 331 | "\n", |
|
341 | 341 | "\n", |
342 | 342 | "Constrained beam search attempts to fulfill the constraints by *injecting* the desired tokens at every step of the generation. \n", |
343 | 343 | "\n", |
344 | | - "Let's say that we're trying to force the phrase `\"is fast\"` in the generation output. \n", |
| 344 | + "Let's say that we're trying to force the phrase `\"is fast\"` in the generated output. \n", |
345 | 345 | "\n", |
346 | 346 | "In the traditional beam search setting, we find the top `k` most probable next tokens at each branch and append them for consideration. In the constrained setting we actually do the same, but also append the tokens that will take us *closer to fulfilling our constraints*. Here's a demonstration:\n", |
347 | 347 | "\n", |
|
370 | 370 | "\n", |
371 | 371 | "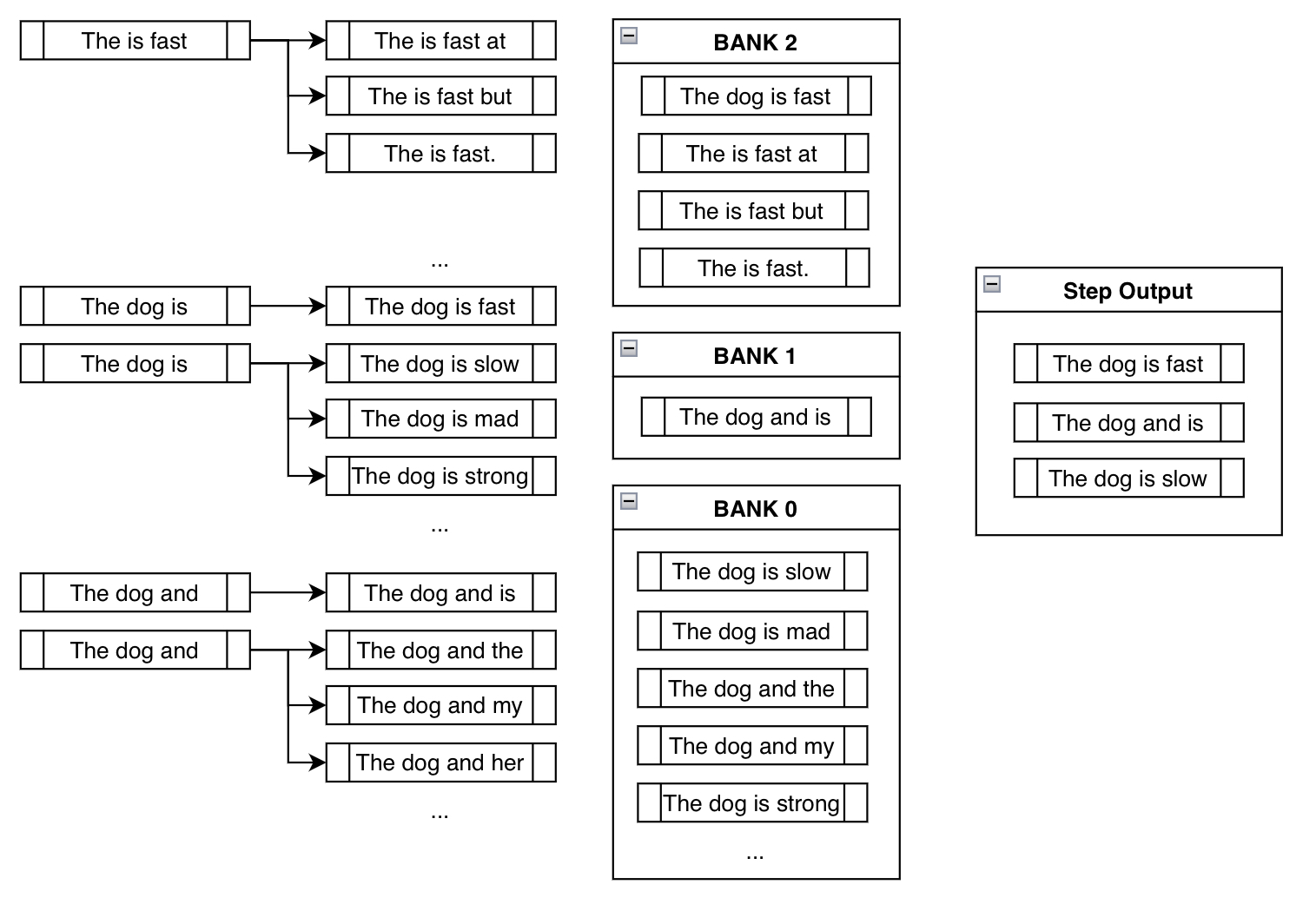\n", |
372 | 372 | "\n", |
373 | | - "Notice how `\"The is fast\"` doesn't require any manual appending of constraint tokens since it's already fulfilled (i.e. already contains the phrase `\"is fast\"`). Also notice how beams like `\"The dog is slow\"` or `\"The dog is mad\"` is actually in Bank 0, since, although it includes the token `\"is\"`, it must restart from the beginning in order to generate `\"is fast\"`. By appending something like `\"slow\"` after `\"is\"`, it has effectively *reset its progress*. \n", |
| 373 | + "Notice how `\"The is fast\"` doesn't require any manual appending of constraint tokens since it's already fulfilled (i.e. already contains the phrase `\"is fast\"`). Also notice how beams like `\"The dog is slow\"` or `\"The dog is mad\"` are actually in Bank 0, since, although it includes the token `\"is\"`, it must restart from the beginning in order to generate `\"is fast\"`. By appending something like `\"slow\"` after `\"is\"`, it has effectively *reset its progress*. \n", |
374 | 374 | "\n", |
375 | 375 | "And finally notice how we ended up at a sensible output that contains our constraint phrase: `\"The dog is fast\"`! \n", |
376 | 376 | "\n", |
|
461 | 461 | "\n", |
462 | 462 | "possible_outputs == [\n", |
463 | 463 | " \"The woman attended the Ross School of Business in Michigan.\",\n", |
464 | | - " \"The woman was the administrator for the Harvard school of Business in MA.\"\n", |
| 464 | + " \"The woman was the administrator for the Harvard School of Business in MA.\"\n", |
465 | 465 | "]\n", |
466 | 466 | "```\n", |
467 | 467 | "\n", |
|
493 | 493 | "\n", |
494 | 494 | "This new feature is based mainly on the following papers:\n", |
495 | 495 | "\n", |
| 496 | + " - [Guided Open Vocabulary Image Captioning with Constrained Beam Search](https://arxiv.org/abs/1612.00576)\n", |
496 | 497 | " - [Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation](https://arxiv.org/abs/1804.06609)\n", |
497 | 498 | " - [Improved Lexically Constrained Decoding for Translation and Monolingual Rewriting](https://aclanthology.org/N19-1090/)\n", |
498 | 499 | " - [Guided Generation of Cause and Effect](https://arxiv.org/pdf/2107.09846.pdf)\n", |
|
0 commit comments