Open source framework for processing, monitoring, and alerting on time series data
There are two different ways to consume Kapacitor.
- Define tasks that process streams of data. This method provides low latency (order of 100ms) processing but without aggregations or anything, just the raw data stream.
- Define tasks that process batches of data. The batches are the results of scheduled queries. This method is higher latency (order of 10s) but allows for aggregations or anything else you can do with a query.
-
Start Kapacitor
$ kapacitord
-
Start a data stream. Configure telegraf with an output to Kapacitor.
-
Create a replayable snapshot
-
Select data from an existing InfluxDB host and save it:
$ kapacitor record stream --host address_of_influxdb --query 'select value from cpu_idle where time > start and time < stop' RecordingID=2869246 -
Or record the live stream for a bit:
$ kapacitor start-recording $ sleep 60 $ kapacitor stop-recording RecordingID=2869246
-
Define a Kapacitor
streamer. Astreameris an entity that defines what data should be processed and how.$ kapacitor define streamer \ --name alert_cpu_idle_any_host \ --from cpu_idle \ --where "cpu = 'cpu-total'" \ --script path/to/dsl/script -
Replay the recording to test the
streamer.$ kapacitor replay 2869246 alert_cpu_idle_any_host
-
Edit the
streamerand test until its working$ kapacitor define streamer \ --name alert_cpu_idle_any_host \ --from cpu_idle \ --where "cpu = 'cpu-total'" \ --script path/to/dsl/script $ kapacitor replay 2869246 alert_cpu_idle_any_host -
Enable or push the
streameronce you are satisfied that it is working$ # enable the streamer locally $ kapacitor enable alert_cpu_idle_any_host $ # or push the tested streamer to a prod server $ kapacitor push --remote address_to_remote_kapacitor alert_cpu_idle_any_host
-
Start Kapacitor
$ kapacitord
-
Define a
batcher. Like astreamerabatcherdefines what data to process and how, only it operates on batches of data instead of streams.$ kapacitor define batcher \ --name alert_mean_cpu_idle_logs_by_dc \ --query "select mean(value) from cpu_idle where role = 'logs' group by dc" \ --period 15m \ `# or --cron */15 * * * *` \ --group-by 1h \ --script path/to/dsl/script -
Save a batch of data for replaying using the definition in the
batcher.$ kapacitor record batch alert_mean_cpu_idle_logs_by_dc RecordingID=2869246
-
Replay the batch of data to the
batcher.$ kapacitor replay 2869246 alert_mean_cpu_idle_logs_by_dc
-
Iterate on the
batcherdefinition until it works$ kapacitor define batcher \ --name alert_mean_cpu_idle_logs_by_dc \ --query "select max(value) from cpu_idle where role = 'logs' group by dc" \ --period 15m \ `# or --cron */15 * * * *` \ --group-by 1h \ --script path/to/dsl/script $ kapacitor replay 2869246 alert_mean_cpu_idle_logs_by_dc -
Once it works enable locally or push to remote
$ # enable the batcher locally $ kapacitor enable alert_mean_cpu_idle_logs_by_dc $ # or push the tested batcher to a prod server $ kapacitor push --remote address_to_remote_kapacitor alert_mean_cpu_idle_logs_by_dc
Processing data follows a pipeline and depending on the processing needs that pipeline can vary significantly. Kapacitor models the different data processing pipelines as a DAGs (Directed Acyclic Graphs) and allows the user to specify the structure of the DAG via a DSL.
There are two approaches to constructing a DAG for stream processing based on the current popular tools.
-
Explicitly define a DAG and what each node does. For example Storm Storm
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("words", new TestWordSpout(), 10); builder.setBolt("exclaim1", new ExclamationBolt(), 3) .shuffleGrouping("words"); builder.setBolt("exclaim2", new ExclamationBolt(), 2) .shuffleGrouping("exclaim1"); builder.setBolt("finish", new FinishBolt(), 2) .shuffleGrouping("exclaim1") .shuffleGrouping("exclaim2");
Here you create a DAGs explicitly via linking named nodes. You define a
boltat each node which is essentially a function that transforms the data. This way of defining the DAG requires that you follow the chain of names to reconstruct a visual layout of the DAG.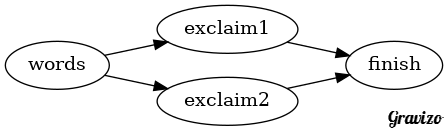
-
Implicitly define the DAG via operators and invocation chaining. For example Flink defines a DAGs like this:
val windowedStream = stream .window(Time.of(10, SECONDS)).every(Time.of(5, SECONDS)) //Compute some simple statistics on a rolling window val lowest = windowedStream.minBy("cpu_idle") val maxByStock = windowedStream.groupBy("host").maxBy("cpu_idle") val rollingMean = windowedStream.groupBy("host").mapWindow(mean _)
Notice the use of the methods
window,minBy,maxByandmapWindow. These method create new nodes in the DAG resulting a in data processing pipeline like: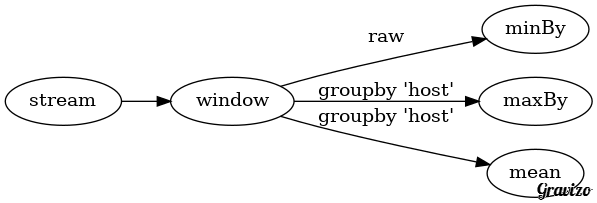
This method give you control over the DAGs but you do not have to link it all up via named nodes. The plumbing is done via invocation chaining method calls.
Based on how the DAG is constructed you can use the DSL to both construct the DAG and define what each node does via built-in functions.
The following is an example DSL script that triggers an alert if idle cpu drops below 30%. In this DSL the keyword stream represents the stream of fields and values from the data points.
var window = stream.window().period(10s).every(5s)
var avg = window.map(mean, "value")
avg.filter(< , 30).alert()
This script maintains a window of data for 10s and emits the current window every 5s.
Then the average is calculated for each emitted window.
Finally all values less than 30 pass through the filter and make it to the alert node, which triggers the alert.
The DAG that is constructed from the script looks like this:

We have not mentioned parallelism yet, by adding groupby and parallelism statements we can see how to easily scale out each layer of the DAG.
var window = stream.window().period(10s).every(5s)
var avg = window.groupby("dc").map(mean, "value")
avg.filter(<, 30).parallelism(4).alert().parallelism(2)
The DAG that is constructed is similar, but with parallelism explicitly shown.:
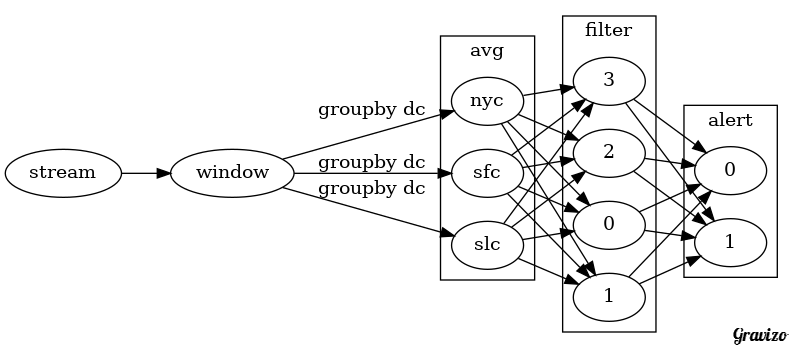
Parellelism is easily achieved and scaled at each layer.
The advantages of the stream based DSL is we define both the data pipeline and each transformation in the same script.
Batch processors work similarly to the stream processing.
Example DSL for batchers where we are running a query every minute and want to alert on cpu. The query: select mean(value) from cpu_idle group by dc, time(1m).
batch.filter(<, 30).alert()
- Define the DAG for your data pipeline needs.
- Window data. Windowing can be done by time or by number of data points and various other conditions, see this.
- Aggregate data. The list of aggregation functions currently supported by InfluxQL is probably a good place to start.
- Transform data via built-in functions.
- Filter down streams/batches of data.
- Emit data into a new stream.
- Emit data into an InfluxDB database.
- Trigger events/notifications.
- Define custom functions in the DSL. You can call out to custom functions defined via a plugin mechanism. The DSL will be too slow to actually process any of the data but is used simply to define the data flow.
- We like the idea of writing our own lexer and parser to keep the DSL simple and flexible for us.
- DSL should be EBNF.
So to see if we were headed down the right path I built a proof of concept a little DSL to API system. For example the following DSL script gets parsed and via reflection calls the following go code.
DSL:
var w = stream.window();
w.period(10s);
w.every(1s);
Go equivalent:
s := &Stream{}
w := s.Window()
w.Period(time.Duration(10) * time.Second)
w.Every(time.Duration(1) * time.Second)Local scope is populate so that stream is a go Stream object.
When the DSL is parsed and then evaluated the window method gets called directly on the stream instance.
Each method is called via reflection so as we update the Go API the DSL dynamically maps to it.
Since the DSL is only used to setup the DAG we wont likely have to worry about the performance hit of reflection.
Example Go code that consumes the DSL to build a DAG:
var dslScript = `
var w = stream.window();
w.period(10s);
w.every(1s);
`
s, err := dsl.CreatePipeline(dslScript)
if err != nil {
return err
log.Fatal(err)
}
s.Start() //start the stream pipeline.Since s in the above example is just an instance of a Stream object we could have created it directly in go or via the DSL as shown.
Now that we have a reference to the s stream we no longer need or execute code from the DSL.
This means that we can build out a golang API similar to Flink's and then instead of shipping jars around with compiled code we can ship DSL scripts around and have nearly the same features and performance. The only piece that is missing in this model are user defined functions; but using the DSL to define and execute those is going to be way to slow. We just need to figure out a way over sockets etc for users to define their own functions, (which was the plan from the beginning).
Below are the logical components to make the workflow possible.
- Kapacitor daemon
kapacitordthat listens on a net/unix socket and manages the rest of the components. - Matching -- uses the
whereclause of a streamer to map points in the data stream to a streamer instance. - Interpreter for DSL -- executes the DSL based on incoming metrics.
- Stream engine -- keeps track of various streams and their topologies.
- Batch engine -- handles the results of scheduled queries and passes them to batchers for processing.
- Replay engine -- records and replays bits of the data stream to the stream engine. Can replay metrics to independent streams so testing can be done in isolation of live stream. Can also save the result of a query for replaying.
- Query Scheduler -- keeps track of schedules for various script and executes them passing data to the batch engine.
- Streamer/Batcher manager -- handles defining, updating and shipping streamers and batchers around.
- API -- HTTP API for accessing method of other components.
- CLI --
kapacitorcommand line utility to call the HTTP API.
-
Q: How do we scale beyond a single instance?
-
A: We could use the matching component to shard and route different series within the stream to the specific nodes within the cluster. AKA consistent sharding.
-
A: We could make the DSL and plugins in general a Map-Reduce framework so that each instance only handles a portion of the stream. We will need to provide an all-in-one solution so that you don't have to deal with the complexities MR if you don't want to. Storm and Spark both apache projects have a workflow where you can define MR jobs for streaming data. Storm is a DAG based approach where the developer get to define the topology and the transformation at each node. Spark has a rich set of operators that have implicit topologies, so the workflow with Spark is to choose a predefine operator like MR and then define the transformations within the topology. I like the DAG approach as it is explicit and will be easier to debug. In contrast Spark makes it easier to get up and running because they solve part of the problem for you. Maybe we build some predefine DAGs that are easy to use, like the all-in-one idea mentioned above.
-
Other ideas?
-
Q: Do we need a different DSL for
streamerss vsbatchers?- A: Hopefully not, but we need to make sure that it is clear how they work (and good error messages) since a DSL script written for a
streamerwill not work for abatcherand vice versa.
- A: Hopefully not, but we need to make sure that it is clear how they work (and good error messages) since a DSL script written for a
-
Q: Should the DSL contain the
from,where,query,period, andgroupby_intervaloptions within it? Example:type: streamer from: cpu_idle where: cpu = 'cpu-total' var window = stream.window().period(10s).every(10s)or
type: batcher query: select mean(value) from cpu_idle where role = 'logs' group by dc period: 15m groupby_interval: 1h batch.filter(<, 30).alert()I like the simplicity of putting all the information in a single file. I can also see issues where you have a single script that processes data from several different sources and duplicating/importing or otherwise maintaining that association could get difficult.
Based on my POC it is helpful to know where the DSL script is a streamer or batcher script before parsing so I think we should leave the DSL as just the script and not the meta information. We should probably find a way to encapsulate the meta information in a config file or something though so its not all CLI args.
-
Q: How is Kapacitor different than other stream processing engines like Storm, Spark, and Flink, apart from its golang and specific to the TICK stack? A: I think we need to understand where we are going to be different than these other tools so we can adjust correctly from their design patterns. One thing that comes to mind is 'ease of use'. Like we discussed earlier, if people need incredible performance they are going to build it themselves; so we want to build an out-of-the box solution.