Open source framework for processing, monitoring, and alerting on time series data
There are two different ways to consume Kapacitor.
- Define tasks that process streams of data. This method provides low latency (order of 100ms) processing but without aggregations or anything, just the raw data stream.
- Define tasks that process batches of data. The batches are the results of scheduled queries. This method is higher latency (order of minutes) but allows for aggregations or anything else you can do with a query.
-
Start Kapacitor
$ kapacitord
-
Start a data stream. Configure telegraf with an output to Kapacitor.
-
Create a replayable snapshot
-
Select data from an existing InfluxDB host and save it:
$ kapacitor record stream --host address_of_influxdb --query 'select value from cpu_idle where time > start and time < stop' RecordingID=2869246 -
Or record the live stream for a bit:
$ kapacitor start-recording $ sleep 60 $ kapacitor stop-recording RecordingID=2869246
-
Define a Kapacitor
streamer. Astreameris an entity that defines what data should be processed and how.$ kapacitor define streamer \ --name alert_cpu_idle_any_host \ --from cpu_idle \ --where "cpu = 'cpu-total'" \ --script path/to/dsl/script -
Replay the recording to test the
streamer.$ kapacitor replay 2869246 alert_cpu_idle_any_host
-
Edit the
streamerand test until its working$ kapacitor define streamer \ --name alert_cpu_idle_any_host \ --from cpu_idle \ --where "cpu = 'cpu-total'" \ --script path/to/dsl/script $ kapacitor replay 2869246 alert_cpu_idle_any_host -
Enable or push the
streameronce you are satisfied that it is working$ # enable the streamer locally $ kapacitor enable alert_cpu_idle_any_host $ # or push the tested streamer to a prod server $ kapacitor push --remote address_to_remote_kapacitor alert_cpu_idle_any_host
-
Start Kapacitor
$ kapacitord
-
Define a
batcher. Like astreamerabatcherdefines what data to process and how, only it operates on batches of data instead of streams.$ kapacitor define batcher \ --name alert_mean_cpu_idle_logs_by_dc \ --query "select mean(value) from cpu_idle where role = 'logs' group by dc" \ --period 15m \ --group-by 1h \ --script path/to/dsl/script -
Save a batch of data for replaying using the definition in the
batcher.$ kapacitor record batch alert_mean_cpu_idle_logs_by_dc RecordingID=2869246
-
Replay the batch of data to the
batcher.$ kapacitor replay 2869246 alert_mean_cpu_idle_logs_by_dc
-
Iterate on the
batcherdefinition until it works$ kapacitor define batcher \ --name alert_mean_cpu_idle_logs_by_dc \ --query "select max(value) from cpu_idle where role = 'logs' group by dc" \ --period 15m \ --group-by 1h \ --script path/to/dsl/script $ kapacitor replay 2869246 alert_mean_cpu_idle_logs_by_dc -
Once it works enable locally or push to remote
$ # enable the batcher locally $ kapacitor enable alert_mean_cpu_idle_logs_by_dc $ # or push the tested batcher to a prod server $ kapacitor push --remote address_to_remote_kapacitor alert_mean_cpu_idle_logs_by_dc
Below are the logical components to make the workflow possible.
- Kapacitor daemon
kapacitordthat listens on a net/unix socket and manages the rest of the components. - Matching -- uses the
whereclause of a streamer to map points in the data stream to a streamer instance. - Interpreter for DSL -- executes the DSL based on incoming metrics.
- Stream engine -- keeps track of various streams and their topologies.
- Batch engine -- handles the results of scheduled queries and passes them to batchers for processing.
- Replay engine -- records and replays bits of the data stream to the stream engine. Can replay metrics to independent streams so testing can be done in isolation of live stream. Can also save the result of a query for replaying.
- Query Scheduler -- keeps track of schedules for various script and executes them passing data to the batch engine.
- Streamer/Batcher manager -- handles defining, updating and shipping streamers and batchers around.
- API -- HTTP API for accessing method of other components.
- CLI --
kapacitorcommand line utility to call the HTTP API.
This part is a brain dump of some of my ideas. I don't have any concrete ideas for the DSL yet so I expect this to change a lot before we like it.
What should the DSL look like? Things we have already discussed:
- We don't like Lua, it doesn't provide anymore power over a completely custom DSL and could have serious negative performance issues. Lua would provide too much flexibility that would be hard to keep a clean performance profile compared to a predefined DSL. And people don't want to write in Lua anymore than a custom DSL.
- Lex and Yacc are over kill writing a lexer and parser is not difficult we have already done it here at InfluxDB
- We like the idea of writing our own lexer and parser to keep the DSL simple and flexible for us.
-
C-Style functions seem like the right approach since they are familiar and if done right are easy to parse. Trivial example to illustrate what I mean by C-style:
avg(value) -
We definitely want the DSL to be EBNF.
What would a complete full DSL script look like?
Let's say we want to fire an alert if the avg cpu_idle for a host is less than 30% for the last 10 data points( or some duration).
My guess it that we will populate the scope of the script with the values and names of the fields in the data point.
In our example the cpu_idle has one field called value so the identifier value in the script will contain the cpu_idle value.
alert(avg(window(value, 10)), <, 30)
My interpretation of the above script.
- The
windowfunction is essentially a ring buffer and waits till it has 10 data points to emit a value. It seems more useful if the buffer were by time instead of number of data points but that is harder to work with so for now keeping it simple with a ring buffer. - Once the buffer is full it passes the full buffer to the
avgfunction. It continues to emit a full buffer every time it gets a new data point. - The
avgfunction computes the avg of the buffer. - The
alertfunction receives a scalar which is the average cpu_idle of the last 10 data points. - The
alertfunction use the<operator to compare the average cpu_idle and30. If the expression is true an alert fires. What firing an alert does can come later and is not part of the DSL.
Using this nested function method, makes it easy to parse and evaluate since there are only literals, functions, and variables populated by the incoming data point.
Data flow of the script:
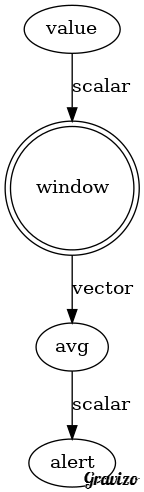
To keep the type system simple we could treat everything as a vector and scalars are just vectors of length 1. But we can't really talk about the type system right now until we get earlier things more solidified.
-
Q: How do we scale beyond a single instance?
-
A: We could use the matching component to shard and route different series within the stream to the specific nodes within the cluster. AKA consistent sharding.
-
A: We could make the DSL and plugins in general a Map-Reduce framework so that each instance only handles a portion of the stream. We will need to provide an all-in-one solution so that you don't have to deal with the complexities MR if you don't want to. Storm and Spark both apache projects have a workflow where you can define MR jobs for streaming data. Storm is a DAG based approach where the developer get to define the topology and the transformation at each node. Spark has a rich set of operators that have implicit topologies, so the workflow with Spark is to choose a predefine operator like MR and then define the transformations within the topology. I like the DAG approach as it is explicit and will be easier to debug. In contrast Spark makes it easier to get up and running because they solve part of the problem for you. Maybe we build some predefine DAGs that are easy to use, like the all-in-one idea mentioned above.
-
Other ideas?
-
Q: How should we treat scheduled plugins vs stream plugins?
- A: We could treat them as completely different entities and the workflow would be different for each. Seems like they naturally have different workflows so maybe this is better.
- A: We could treat them the same but just ones that have
whereclauses are stream plugins and ones that have a schedule and aselectstatement are scheduled plugins. Not a good idea right now.
-
Q: Do we need a different DSL for
streamerss vsbatchers?- A: Hopefully not, but we need to make sure that it is clear how they work (and good error messages) since a DSL script written for a
streamerwill not work for abatcherand vice versa.
- A: Hopefully not, but we need to make sure that it is clear how they work (and good error messages) since a DSL script written for a