
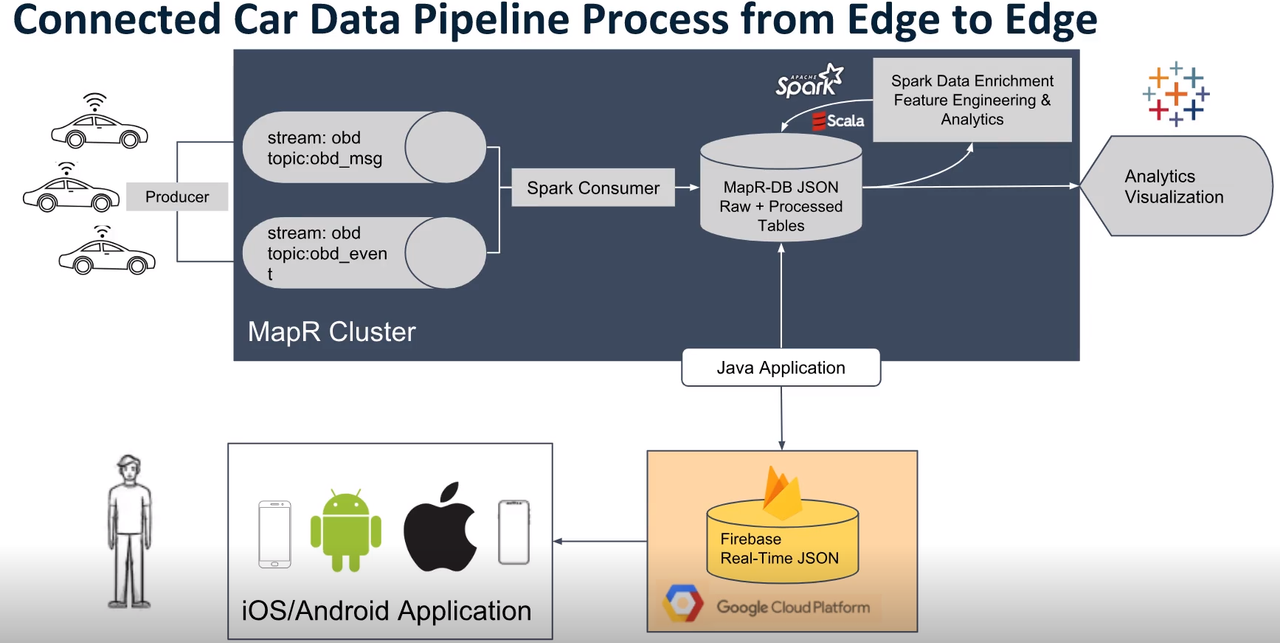
- Partition Id
- Hash of messageId
- Round-Robin
mapr streamanalyzer -path /mapr/dp.prod.zur/vantage/orchestr/streams/my-own-test -topics cherkavi-test -printMessages true -countMessages
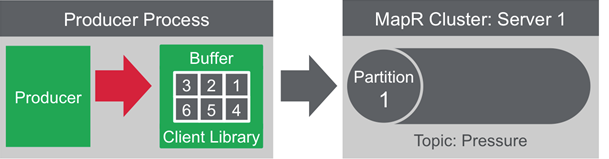
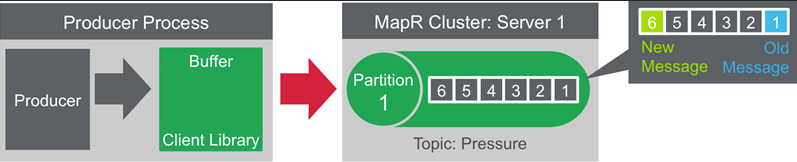
- by partition number
- by message key
- round-robin ( without previous two )
- properties.put("streams.patitioner.class", "my.package.MyClassName.class")
public class MyClassName implements Partitioner{
public int partition( String topic, Object, key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){}
}
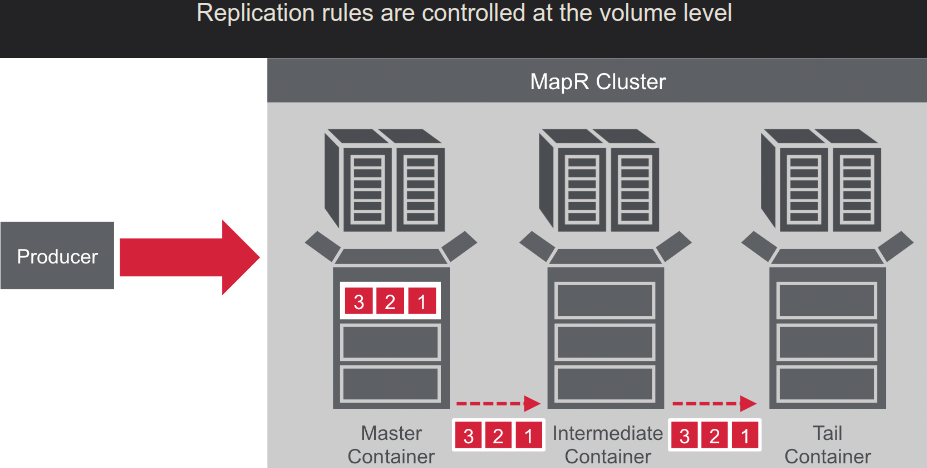


- Read cursor ( client request it and broker sent )
- Committed cursor ( client confirmed/commited reading )

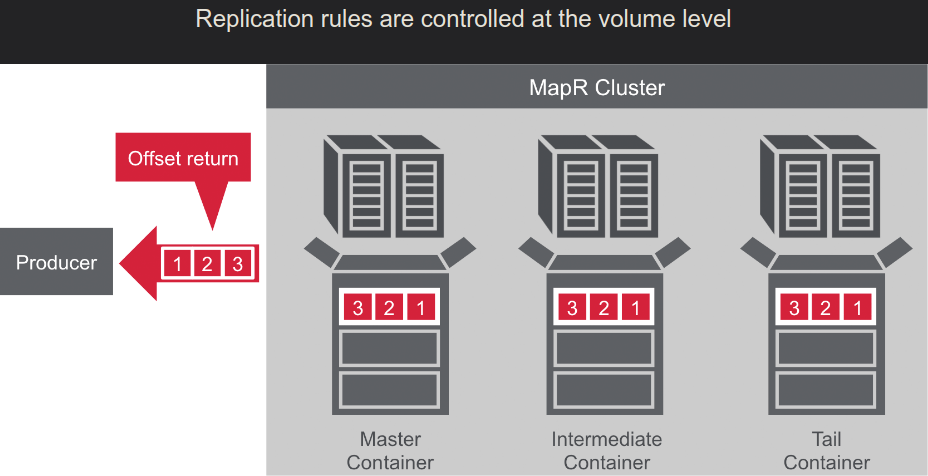
- Master->Slave
- Many->One
- MultiMaster: Master<-->Master
- Stream replications: Node-->Node2-->Node3-->Node4 ... ( with loop preventing )
maprcli node listcldbs
maprcli stream create -path <filepath & name>
maprcli stream create -path <filepath & name> -consumeperm u:<userId> -produceperm u:<userId> -topicperm u:<userId>
maprcli stream create -path <filepath & name> -consumeperm "u:<userId>" -produceperm "u:<userId>" -topicperm "u:<userId>" -adminperm "u:<userId1> | u:<userId2>"
maprcli stream info -path {filepath}
maprcli stream delete -path <filepath & name>
maprcli stream topic create -path <path and name of the stream> -topic <name of the topic>
maprcli stream topic delete -path <path and name of the stream> -topic <name of the topic>
maprcli stream topic list -path <path and name of the stream>
javac -classpath `mapr classpath` MyConsumer.java
java -classpath kafka-clients-1.1.1-mapr-1808.jar:slf4j-api-1.7.12.jar:slf4j-log4j12-1.7.12.jar:log4j-1.2.17.jar:mapr-streams-6.1.0-mapr.jar:maprfs-6.1.0-mapr.jar:protobuf-java-2.5.0.jar:hadoop-common-2.7.0.jar:commons-logging-1.1.3-api.jar:commons-logging-1.1.3.jar:guava-14.0.1.jar:commons-collections-3.2.2.jar:hadoop-auth-2.7.0-mapr-1808.jar:commons-configuration-1.6.jar:commons-lang-2.6.jar:jackson-core-2.9.5.jar:. MyConsumer
Properties properties = new Properties();
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("client.id", <client id>)
import org.apache.kafka.clients.producer.KafkaProducer;
KafkaProducer producer = new KafkaProducer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, messageTextKey, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, partitionIntNumber, textOfMessage);
Callback callback = new Callback(){
public void onCompletion(RecordMetadata meta, Exception ex){
meta.offset();
}
};
producer.send(record, callback);
producer.close();

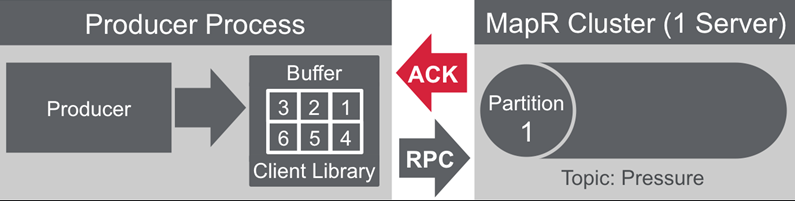
streams.parallel.flushers.per.partition default true:
- does not wait for ACK before sending more messages
- possible for messages to arrive out of order
streams.parallel.flushers.per.partition set to false:
- client library will wait for ACK from server
- slower than default setting
metadata.max.age.ms
How frequently to fetch metadata
Properties properties = new Properties();
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("auto.offset.reset", <Earliest, Latest, None>)
// properties.put("group.id", <group identificator>)
// properties.put("enable.auto.commit", <true - default | false >), use consumer.commitSync() if false
// properties.put("auto.commit.interval.ms", <default value 1000ms>)
import org.apache.kafka.clients.consumer.KafkaConsumer;
KafkaConsumer consumer = new KafkaConsumer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
consumer.subscribe(Arrays.asList(topic));
// consumer.subscribe(topic, new RebalanceListener());
ConsumerRecords<String, String> messages = consumer.poll(1000L); // reading with timeout
messages.iterator().next().toString(); // "/streams/my-stream:topic-name, parition=1, offset=256, key=one, value=text"
public class RebalanceListener implements ConsumerRebalanceListener{
onPartitionAssigned(Collection<TopicPartition> partitions)
onPartitionRevoked(Collection<TopicPartition> partitions)
}
(maven repository)[https://repository.mapr.com/nexus/content/repositories/releases/]
<repositories>
<repository>
<id>mapr-maven</id>
<url>http://repository.mapr.com/maven</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0-mapr-1602-streams-5.1.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
execute on cluster
mapr classpath
java -cp `mapr classpath`:my-own-app.jar mypackage.MainClass
curl_user="cluster_user"
curl_pass="cluster_user_password"
stream_path="%2Fvantage%2Forchestration%2Fstreams%2Fpipeline"
topic_name="gateway"
host="https://ubsdpdesp000001.vantage.org"
port=8082
# maprcli stream topic list -path $stream_path # need to replace %2 with /
curl -u $curl_user:$curl_pass \
--insecure -s -X GET \
-H "Content-Type: application/vnd.kafka.v2+json" \
$host:$port/topics/$stream_path%3A$topic_namemaprlogin password -user {your cluster username}
# long term ticket
maprlogin password -user {your cluster username} -duration 30:0:0 -renewal 90:0:0
maprlogin print
maprlogin logout
execution_string="echo '"$CLUSTER_PASS"' | maprlogin password -user cherkavi "
ssh $CLUSTER_USER@$CLUSTER_NODE $execution_string
maprlogin print -ticketfile <your ticketfile>
# you will see expiration date like
# on 07.05.2019 13:56:47 created = 'Tue Apr 23 13:56:47 UTC 2019', expires = 'Tue May 07 13:56:47 UTC 2019'
maprcli dashboard info -json
$ wget -O - https://package.mapr.com/releases/pub/maprgpg.key | sudo apt-key add -deb https://package.mapr.com/releases/v6.1.0/ubuntu binary trusty
deb https://package.mapr.com/releases/MEP/MEP-6.0.0/ubuntu binary trusty
apt-get update
# apt-get install mapr-posix-client-basic
apt-get install mapr-posix-client-platinumsudo mkdir /mapr
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/mapr-clusters.conf /opt/mapr/conf/mapr-clusters.conf
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/ssl_truststore /opt/mapr/conf/ssl_truststoreecho "$PASSWORD" | maprlogin password -user $USERNAME -out /tmp/mapruserticketyarn application -list -appStates ALL
yarn logs -applicationId application_1540813402987_9262
# login
maprlogin password
echo $CLUSTER_PASSWORD | maprlogin password -user $CLUSTER_USER
export MAPR_TICKETFILE_LOCATION=$(maprlogin print | grep "keyfile" | awk '{print $3}')
# open drill
/opt/mapr/drill/drill-1.14.0/bin/sqlline -u "jdbc:drill:drillbit=ubs000103.vantagedp.com:31010;auth=MAPRSASL"# start recording console to file, write output
!record out.txt
# stop recording
recordshow databases; -- show schemas;
select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/0171eabfceff/reprocessable/part-00000-63dbcc0d1bed-c000.snappy.parquet`;
-- or even
select sessionId, isReprocessable from dfs.`/mapr/dp.prod.zurich/vantage/data/store/processed/*/*/part-00000-63dbcc0d1bed-c000.snappy.parquet`;!!! important: you should avoid colon ':' symbol in path ( explicitly or implicitly with asterix )
# check status
curl --insecure -X GET https://mapr-web.vantage.zur:21103/status
# obtain cookie from server
curl -H "Content-Type: application/x-www-form-urlencoded" \
-k -c cookies.txt -s \
-d "j_username=$DRILL_USER" \
--data-urlencode "j_password=$DRILL_PASS" \
https://mapr-web.vantage.zur:21103/j_security_check
# obtain version
curl -k -b cookies.txt -X POST \
-H "Content-Type: application/json" \
-w "response-code: %{http_code}\n" \
-d '{"queryType":"SQL", "query": "select * from sys.version"}' \
https://mapr-web.vantage.zur:21103/query.json
# SQL request
curl -k -b cookies.txt -X POST \
-H "Content-Type: application/json" \
-w "response-code: %{http_code}\n" \
-d '{"queryType":"SQL", "query": "select loggerTimestamp, key, `value` from dfs.`/mapr/dp.zurich/some-file-on-cluster` limit 10"}' \
https://mapr-web.vantage.zur:21103/query.json/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222/jre/bin/java \
-Ddrill.customAuthFactories=org.apache.drill.exec.rpc.security.maprsasl.MapRSaslFactory \
-Djava.security.auth.login.config=/opt/mapr/conf/mapr.login.conf \
-Dzookeeper.sasl.client=false \
-Dlog.path=/opt/mapr/drill/drill-1.14.0/logs/sqlline.log \
-Dlog.query.path=/opt/mapr/drill/drill-1.14.0/logs/sqlline_queries/data_api-s_sqlline_queries.json \
-cp /opt/mapr/drill/drill-1.14.0/conf:/opt/mapr/drill/drill-1.14.0/jars/*:/opt/mapr/drill/drill-1.14.0/jars/ext/*:/opt/mapr/drill/drill-1.14.0/jars/3rdparty/*:/opt/mapr/drill/drill-1.14.0/jars/classb/*:/opt/mapr/drill/drill-1.14.0/jars/3rdparty/linux/*:drill_jdbc-1.0-SNAPSHOT.jar \
DrillCollaborationincreasing amount of parallel processing threads
set planner.width.max_per_node=10;show errors in log
ALTER SESSION SET `exec.errors.verbose`=true;https://docs.datafabric.hpe.com/61/ReferenceGuide/tablecommands.html Create table
maprclitable create -path <path_in_maprfs> Show info
maprcli table info -path /vantage/deploy/data-access-video/images -jsonGranting Access Permissions for User
maprcli table cf edit -path /vantage/deploy/data-access-video/images -cfname default -readperm u:tech_user_name
maprcli table cf edit -path /vantage/deploy/data-access-video/images -cfname default -readperm "u:tech_user_name | u:tech_user_name2"Information about table
maprcli table info -path /vantage/data/store/processed/markers
maprcli table cf list -path /vantage/data/store/processed/markers
Create an index for the thumbnail MapR JSON DB in order to speed up: (query to find all sessionIds with existing thumbnails)
--query {"$select":"sessionId","$where":{"$eq":{"frameThumbnail":0}}}
maprcli table index add -path /vantage/deploy/data-access-video/images -index frameNumber_id -indexedfields frameThumbnail
# maprclitable index add -path <path> -index <name> -indexedfields<fields>
maprclitable index list -path <path>
maprclitable cfcreate / delete / listDescribe data, describe table
mapr dbshell
desc /full/path/to/maprdb/table
manipulate with MapRDB via DbShell
mapr dbshell
find /mapr/prod/vantage/orchestration/tables/metadata --query '{"$select":["mdf4Path.name","mdf4Path.fullPath"],"$limit":2}'
find /mapr/prod/vantage/orchestration/tables/metadata --fields mdf4Path.name,mdf4Path.fullPath --limit 2 --offset 2 --where {"$eq":{"session_id":"9aaa13577-ad80"}} --orderby created_time
find /mapr/prod/vantage/orchestration/tables/metadata --c {"$eq":{"session_id":"9aaa13577-ad80"}}!!! important !!!, id only, no data in output but "_id": if you don't see all fields in the output, try to change user ( you don't have enough rights )
complex query
find /tbl --q {"$select":"a.c.e",
"$where":{
"$and":[
{"$eq":{"a.b[0].boolean":false}},
{"$or":[
{"$ne":{"a.c.d":5}},
{"$gt":{"a.b[1].decimal":1}},
{"$lt":{"a.b[1].decimal":10}}
]
}
]
}
}query with counting amount of elements in array
find //tables/session --query {"$select":["_id"],"$where":{"$and":[{"$eq":{"vin":"BX77777"}},{"$sizeof":{"labelEvents":{"$ge":1}}}]}}
example of inline execution
echo 'find /mapr/prod/vantage/orchestration/tables/metadata --fields mdf4Path.name,mdf4Path.fullPath --limit 2' | tee script.out
mapr dbshell --cmdfile script.out
rm script.outexample of execution via mapr web, web mapr
MAPR_USER='user'
MAPR_PASSWORD='password'
SESSION='d99-4a-ac-0cbd'
curl --silent --insecure -X GET -u $MAPR_USER:$MAPR_PASSWORD https://mapr-web.vantage.zur:2002/api/v2/table//vantage/orchestration/tables/sessions/document/$SESSION | jq "." | grep labelEvent
curl -X PUT "https://ubssp000007:14000/webhdfs/v1/tmp/example?op=mkdirs" -k -u "user":"passw"
vim /mapr/dc.stg.zurich/tmp/1.txt
curl -X GET "https://ubssp000007:14000/webhdfs/v1/tmp/1.txt?op=open" -k -u "user":"passw"Can not find IP for host: maprdemo.mapr.io
solution
# hard way
rm -rf /opt/mapr
# soft way
vim /opt/mapr/conf/mapr-clusters.confCaused by: javax.security.auth.login.LoginException: Unable to obtain MapR credentials
at com.mapr.security.maprsasl.MaprSecurityLoginModule.login(MaprSecurityLoginModule.java:228)
echo "passw" | maprlogin password -user my_user_name