- Deep learning notes from Andrew NG’s course.
- Jay Alammar on NN Part 1, Part 2
- NN in general - 5 introductions tutorials.
- Segmentation examples
MLP: fully connected, input, hidden layers, output. Gradient on the backprop takes a lot of time to calculate. Has vanishing gradient problem, because of multiplications when it reaches the first layers the loss correction is very small (0.1*0.1*01 = 0.001), therefore the early layers train slower than the last ones, and the early ones capture the basics structures so they are the more important ones.
AutoEncoder - unsupervised, drives the input through fully connected layers, sometime reducing their neurons amount, then does the reverse and expands the layer’s size to get to the input (images are multiplied by the transpose matrix, many times over), Comparing the predicted output to the input, correcting the cost using gradient descent and redoing it, until the networks learns the output.
- Convolutional auto encoder
- Denoiser auto encoder - masking areas in order to create an encoder that understands noisy images
- Variational autoencoder - doesnt rely on distance between pixels, rather it maps them to a function (gaussian), eventually the DS should be explained by this mapping, uses 2 new layers added to the network. Gaussian will create blurry images, but similar. Please note that it also works with CNN.
What are logits in neural net - the vector of raw (non-normalized) predictions that a classification model generates, which is ordinarily then passed to a normalization function. If the model is solving a multi-class classification problem, logits typically become an input to the softmax function. The softmax function then generates a vector of (normalized) probabilities with one value for each possible class.
WORD2VEC - based on autoencode, we keep only the hidden layer , Part 2
RBM- restricted (no 2 nodes share a connection) boltzman machine
An Autoencoder of features, tries to encode its own structure.
Works best on pics, video, voice, sensor data. 2 layers, visible and hidden, error and bias calculated via KL Divergence.
- Also known as a shallow network.
- Two layers, input and output, goes back and forth until it learns its output.
DBN - deep belief networks, similar structure to multi layer perceptron. fully connected, input, hidden(s), output layers. Can be thought of as stacks of RBM. training using GPU optimization, accurate and needs smaller labelled data set to complete the training.
Solves the ‘vanishing gradient’ problem, imagine a fully connected network, advancing each 2 layers step by step until each boltzman network (2 layers) learns the output, keeps advancing until finished.. Each layer learns the entire input.
Next step is to fine tune using a labelled test set, improves performance and alters the net. So basically using labeled samples we fine tune and associate features and pattern with a name. Weights and biases are altered slightly and there is also an increase in performance. Unlike CNN which learns features then high level features.
Accurate and reasonable in time, unlike fully connected that has the vanishing gradient problem.
Transfer Learning = like Inception in Tensor flow, use a prebuilt network to solve many problems that “work” similarly to the original network.
- CS course definition - also very good explanation of the common use cases:
- Feature extraction from the CNN part (removing the fully connected layer)
- Fine-tuning, everything or partial selection of the hidden layers, mainly good to keep low level neurons that know what edges and color blobs are, but not dog breeds or something not as general.
- CNN checkpoints for many problems with transfer learning. Has several relevant references
- Such as this “How transferable are features in deep neural networks? “
- (the indian guy on facebook) IMDB transfer learning using cnn vgg and word2vec, the word2vec is interesting, the cnn part is very informative. With python code, keras.
CNN, Convolutional Neural Net (this link explains CNN quite well, 2nd tutorial - both explain about convolution, padding, relu - sparsity, max and avg pooling):
- Common Layers: input->convolution->relu activation->pooling to reduce dimensionality **** ->fully connected layer
- ****repeat several times over as this discover patterns but needs another layer -> fully connected layer
- Then we connect at the end a fully connected layer (fcl) to classify data samples.
- Good for face detection, images etc.
- Requires lots of data, not always possible in a real world situation
- Relu is quite resistant to vanishing gradient & allows for deactivating neurons and for sparsity.
RNN - what is RNN by Andrej Karpathy - The Unreasonable Effectiveness of Recurrent Neural Networks, basically a lot of information about RNNs and their usage cases
- basic NN node with a loop, previous output is merged with current input. for the purpose of remembering history, for time series, to predict the next X based on the previous Y.
- 1 to N = frame captioning
- N to 1 = classification
- N to N = predict frames in a movie
- N\2 with time delay to N\2 = predict supply and demand
- Vanishing gradient is 100 times worse.
- Gate networks like LSTM solves vanishing gradient.
SNN - SELU activation function is inside not outside, results converge better.
Probably useful for feedforward networks
DEEP REINFORCEMENT LEARNING COURSE (for motion planning)or
DEEP RL COURSE (Q-LEARNING?) - using unlabeled data, reward, and probably a CNN to solve games beyond human level.
A brief survey of DL for Reinforcement learning
WIKI has many types of RNN networks (unread)
Unread and potentially good tutorials:
EXAMPLES of Using NN on images:
Deep image prior / denoiser/ high res/ remove artifacts/ etc..
(What are?) batch, stochastic, and mini-batch gradient descent are and the benefits and limitations of each method.
- Gradient descent is an optimization algorithm often used for finding the weights or coefficients of machine learning algorithms, such as artificial neural networks and logistic regression.
- the model makes predictions on training data, then use the error on the predictions to update the model to reduce the error.
- The goal of the algorithm is to find model parameters (e.g. coefficients or weights) that minimize the error of the model on the training dataset. It does this by making changes to the model that move it along a gradient or slope of errors down toward a minimum error value. This gives the algorithm its name of “gradient descent.”
- calculate error and updates the model after every training sample
- calculates the error for each example in the training dataset, but only updates the model after all training examples have been evaluated.
- splits the training dataset into small batches, used to calculate model error and update model coefficients.
- Implementations may choose to sum the gradient over the mini-batch or take the average of the gradient (reduces variance of gradient) (unclear?)
+ Tips on how to choose and train using mini batch in the link above
Dont decay the learning rate, increase batchsize - paper (optimization of a network)
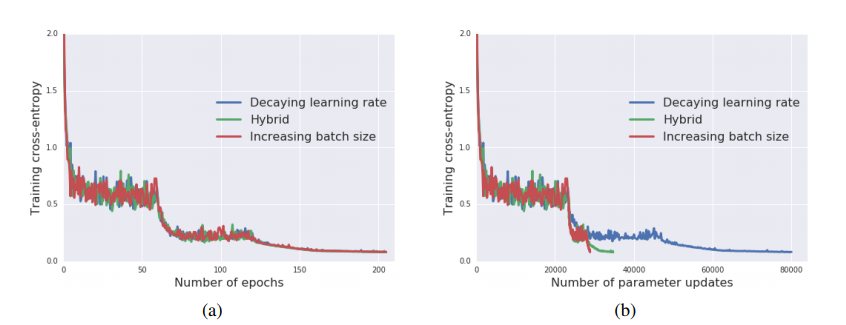
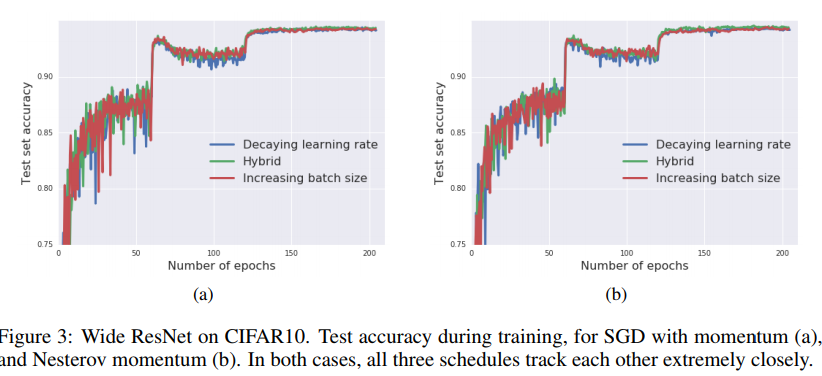
- Big batches are not the cause for the ‘generalization gap’ between mini and big batches, it is not advisable to use large batches because of the low update rate, however if you change that, authors claim its okay.
- So what is a batch size in NN (another source) - and how to find the “right” number. In general terms a good mini bach between 1 and all samples is a good idea. Figure it out empirically.
- one epoch = one forward pass and one backward pass of all the training examples
- batch size = the number of training examples in one forward/backward pass. The higher the batch size, the more memory space you'll need.
- number of iterations = number of passes, each pass using [batch size] number of examples. To be clear, one pass = one forward pass + one backward pass (we do not count the forward pass and backward pass as two different passes).
Example: if you have 1000 training examples, and your batch size is 500, then it will take 2 iterations to complete 1 epoch.
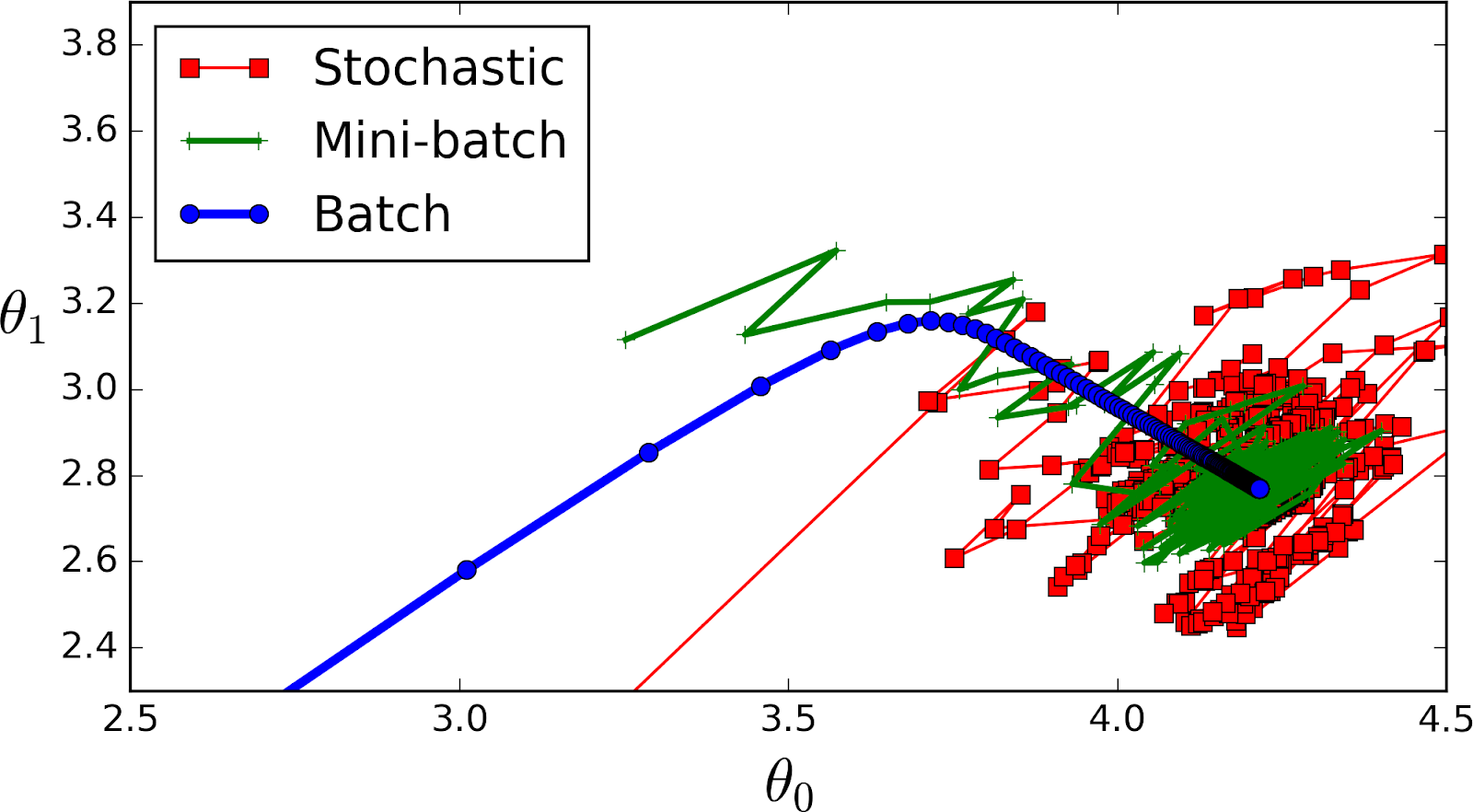
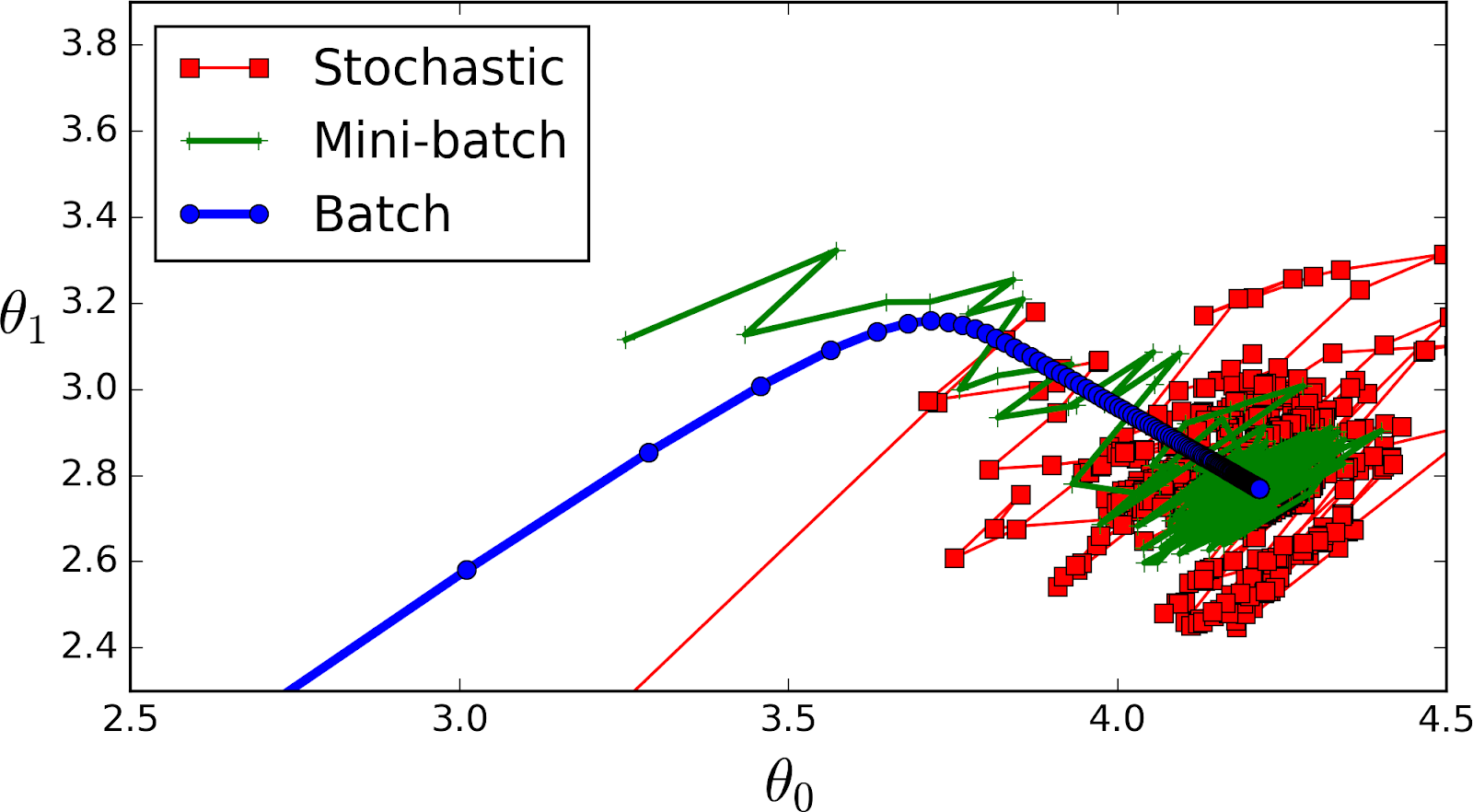
GD with Momentum - explain
(a good read) about batch sizes in keras, specifically LSTM, read this first!
A sequence prediction problem makes a good case for a varied batch size as you may want to have a batch size equal to the training dataset size (batch learning) during training and a batch size of 1 when making predictions for one-step outputs.
power of 2: have some advantages with regards to vectorized operations in certain packages, so if it's close it might be faster to keep your batch_size in a power of 2.
(pushing batches of samples to memory in order to train) -
Batch size defines number of samples that going to be propagated through the network.
For instance, let's say you have 1050 training samples and you want to set up batch_size equal to 100. Algorithm takes first 100 samples (from 1st to 100th) from the training dataset and trains network. Next it takes second 100 samples (from 101st to 200th) and train network again. We can keep doing this procedure until we will propagate through the networks all samples. The problem usually happens with the last set of samples. In our example we've used 1050 which is not divisible by 100 without remainder. The simplest solution is just to get final 50 samples and train the network.
Advantages:
- It requires less memory. Since you train network using less number of samples the overall training procedure requires less memory. It's especially important in case if you are not able to fit dataset in memory.
- Typically networks trains faster with mini-batches. That's because we update weights after each propagation. In our example we've propagated 11 batches (10 of them had 100 samples and 1 had 50 samples) and after each of them we've updated network's parameters. If we used all samples during propagation we would make only 1 update for the network's parameter.
Disadvantages:
- The smaller the batch the less accurate estimate of the gradient. In the figure below you can see that mini-batch (green color) gradient's direction fluctuates compare to the full batch (blue color).
Small batch size has an effect on validation accuracy.

- (unread) about mini batches and performance.
- (unread) tradeoff between bath size and number of iterations
Another observation, probably empirical - to answer your questions on Batch Size and Epochs:
In general: Larger batch sizes result in faster progress in training, but don't always converge as fast. Smaller batch sizes train slower, but can converge faster. It's definitely problem dependent.
In general, the models improve with more epochs of training, to a point. They'll start to plateau in accuracy as they converge. Try something like 50 and plot number of epochs (x axis) vs. accuracy (y axis). You'll see where it levels out.
The role of bias in NN - similarly to the ‘b’ in linear regression.
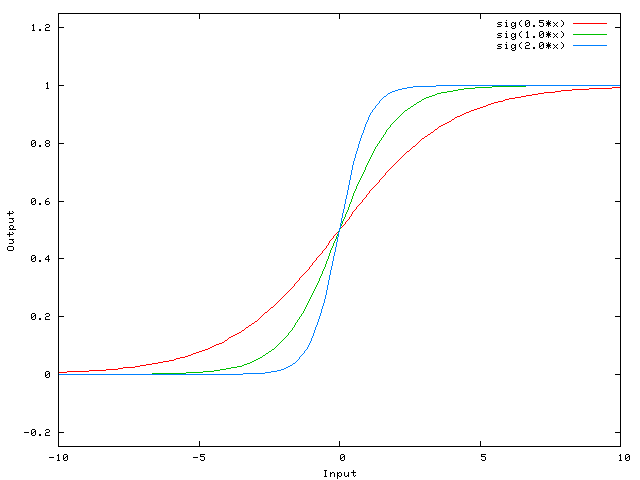
- The best explanation to what is BN and why to use it, including busting the myth that it solves internal covariance shift - shifting input distribution, and saying that it should come after activations as it makes more sense (it does),also a nice quote on where a layer ends is really good - it can end at the activation (or not). How to use BN in the test, hint: use a moving window. Bn allows us to use 2 parameters to control the input distribution instead of controlling all the weights.
- Medium on BN
- Medium on BN
- Ian goodfellow on BN
- Medium #2 - a better one on BN, and adding to VGG
- Reddit on BN, mainly on the paper saying to use it before, but best practice is to use after
- Diff between batch and norm (weak explanation)
- Weight normalization for keras and TF
- Layer normalization keras
- Instance normalization keras
- batch/layer/instance in TF with code
- Layer norm for rnn’s or whatever name it is in this post with code for GRU
What is the diff between batch/layer/recurrent batch and back rnn normalization
- Layer normalization (Ba 2016): Does not use batch statistics. Normalize using the statistics collected from all units within a layer of the current sample. Does not work well with ConvNets.
- Recurrent Batch Normalization (BN) (Cooijmans, 2016; also proposed concurrently by Qianli Liao & Tomaso Poggio, but tested on Recurrent ConvNets, instead of RNN/LSTM): Same as batch normalization. Use different normalization statistics for each time step. You need to store a set of mean and standard deviation for each time step.
- Batch Normalized Recurrent Neural Networks (Laurent, 2015): batch normalization is only applied between the input and hidden state, but not between hidden states. i.e., normalization is not applied over time.
- Streaming Normalization (Liao et al. 2016) : it summarizes existing normalizations and overcomes most issues mentioned above. It works well with ConvNets, recurrent learning and online learning (i.e., small mini-batch or one sample at a time):
- Weight Normalization (Salimans and Kingma 2016): whenever a weight is used, it is divided by its L2 norm first, such that the resulting weight has L2 norm 1. That is, output y=x∗(w/|w|), where x and w denote the input and weight respectively. A scalar scaling factor g is then multiplied to the output y=y∗g. But in my experience g seems not essential for performance (also downstream learnable layers can learn this anyway).
- Cosine Normalization (Luo et al. 2017): weight normalization is very similar to cosine normalization, where the same L2 normalization is applied to both weight and input: y=(x/|x|)∗(w/|w|). Again, manual or automatic differentiation can compute appropriate gradients of x and w.
- Note that both Weight and Cosine Normalization have been extensively used (called normalized dot product) in the 2000s in a class of ConvNets called HMAX (Riesenhuber 1999) to model biological vision. You may find them interesting.
- Layer normalization solves the rnn case that batch couldnt - Is done per feature within the layer and normalized features are replaced
- Instance does it for (cnn?) using per channel normalization
- Group does it for group of channels
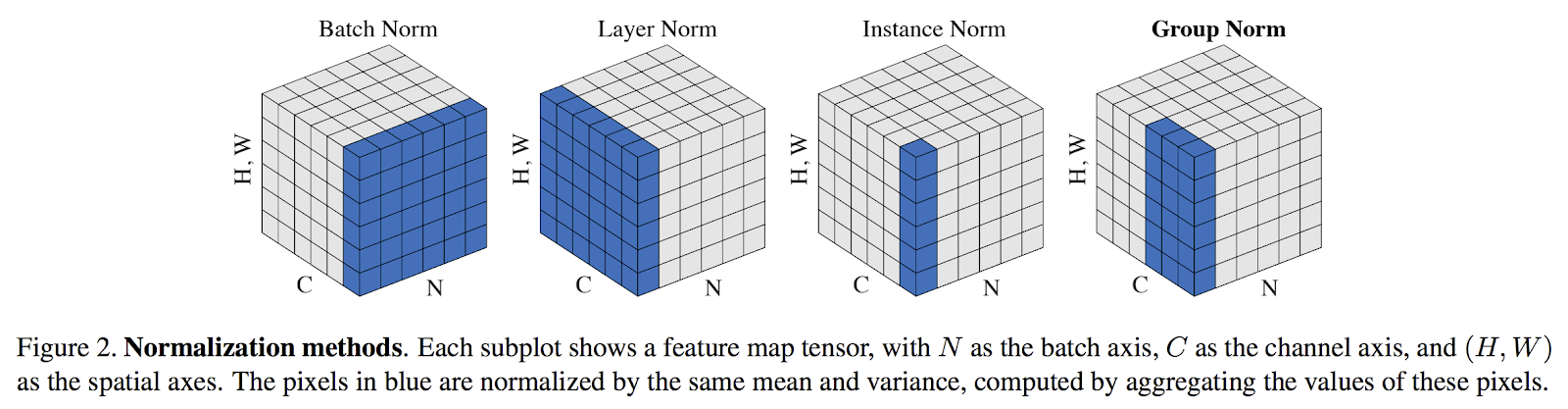
Part1: intuitive explanation to batch normalization
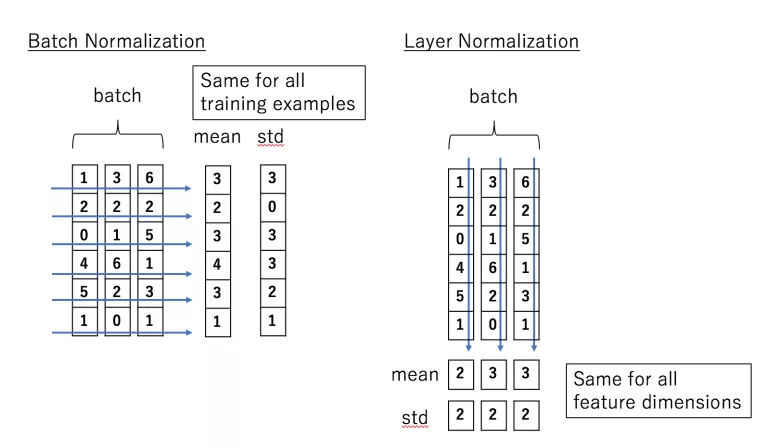
Part2: batch/layer/weight normalization - This is a good resource for advantages for every layer
- Layer, per feature in a batch,
- weight - divided by the norm
Very Basic advice: You should probably switch train/validation repartition to something like 80% training and 20% validation. In most cases it will improve the classifier performance overall (more training data = better performance)
+If Training error and test error are too close (your system is unable to overfit on your training data), this means that your model is too simple. Solution: more layers or more neurons per layer.
Early stopping
If you have never heard about "early-stopping" you should look it up, it's an important concept in the neural network domain : https://en.wikipedia.org/wiki/Early_stopping . To summarize, the idea behind early-stopping is to stop the training once the validation loss starts plateauing. Indeed, when this happens it almost always mean you are starting to overfitt your classifier. The training loss value in itself is not something you should trust, beacause it will continue to increase event when you are overfitting your classifier.
With cross entropy there can be an issue where the accuracy is the same for two cases, one where the loss is decreasing and the other when the loss is not changing much.
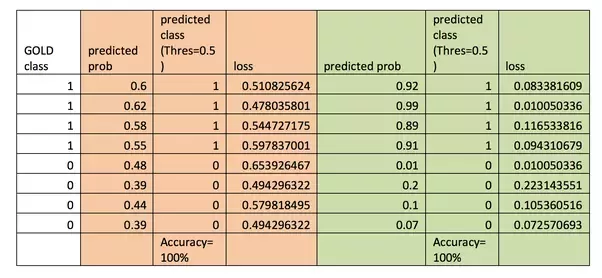
How to read LOSS graphs (and accuracy on top)

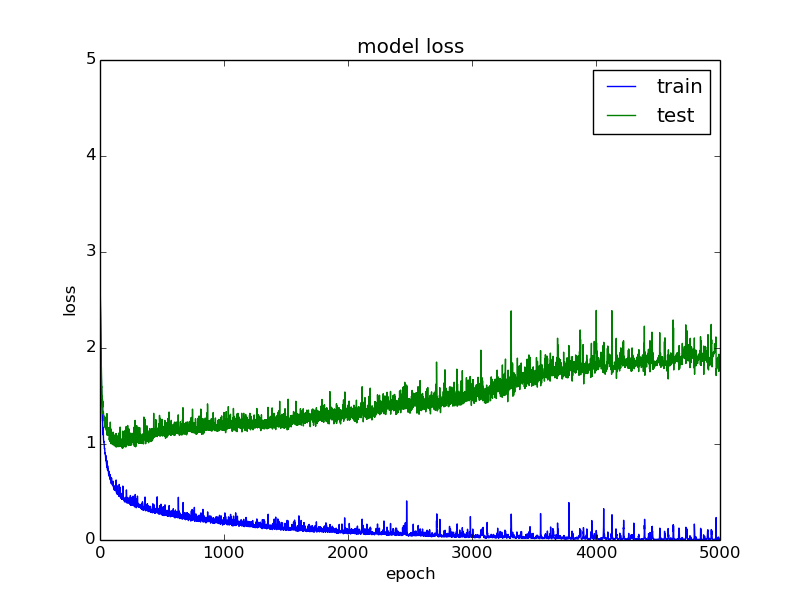
This indicates that the model is overfitting. It continues to get better and better at fitting the data that it sees (training data) while getting worse and worse at fitting the data that it does not see (validation data).
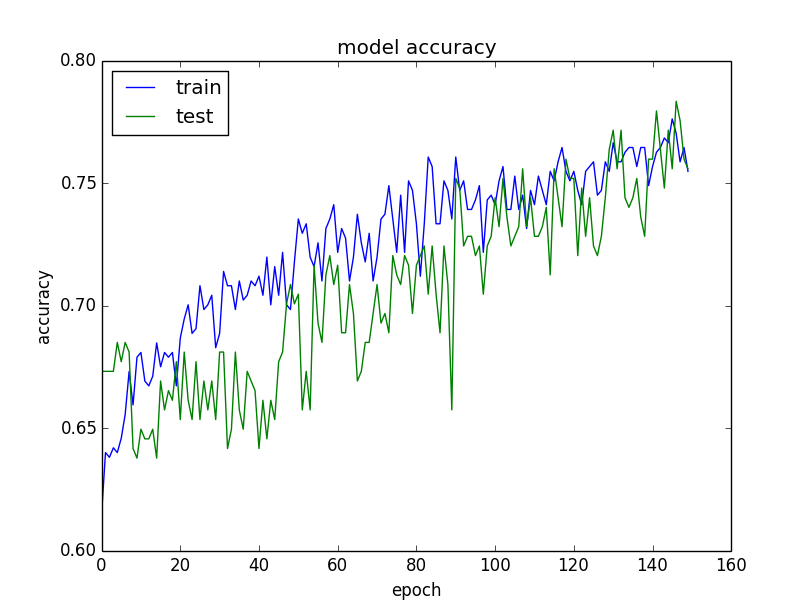
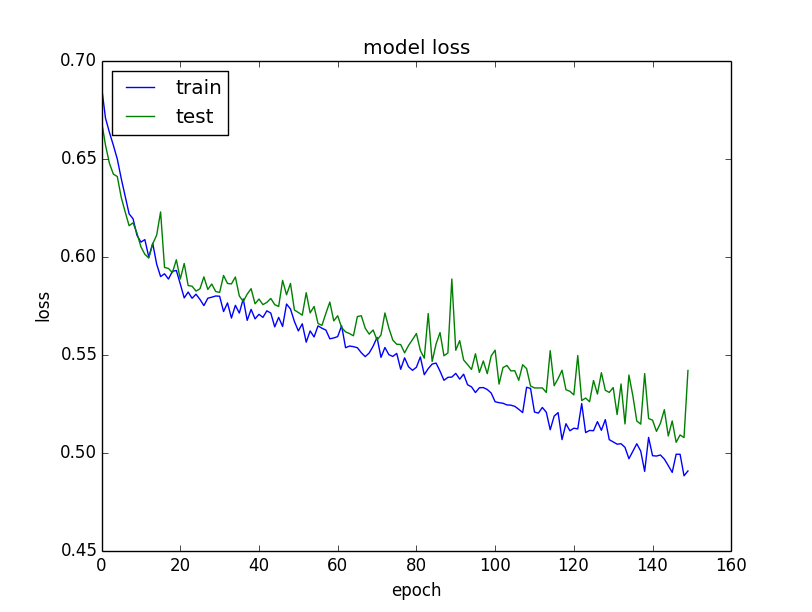
This is a very good example of a train/test loss and an accuracy behavior.
Cross entropy formula with soft labels (probability) rather than classes.
Mastery on cross entropy, brier, roc auc, how to ‘game’ them and calibrate them
Game changer paper - a general adaptive loss search in nn
Intro to Learning Rate methods - what they are doing and what they are fixing in other algos.
Callbacks, especially ReduceLROnPlateau - this callback monitors a quantity and if no improvement is seen for a 'patience' number of epochs, the learning rate is reduced.
Cs123 (very good): explains about many things related to CNN, but also about LR and adaptive methods.
An excellent comparison of several learning rate schedule methods and adaptive methods: (same here but not as good)
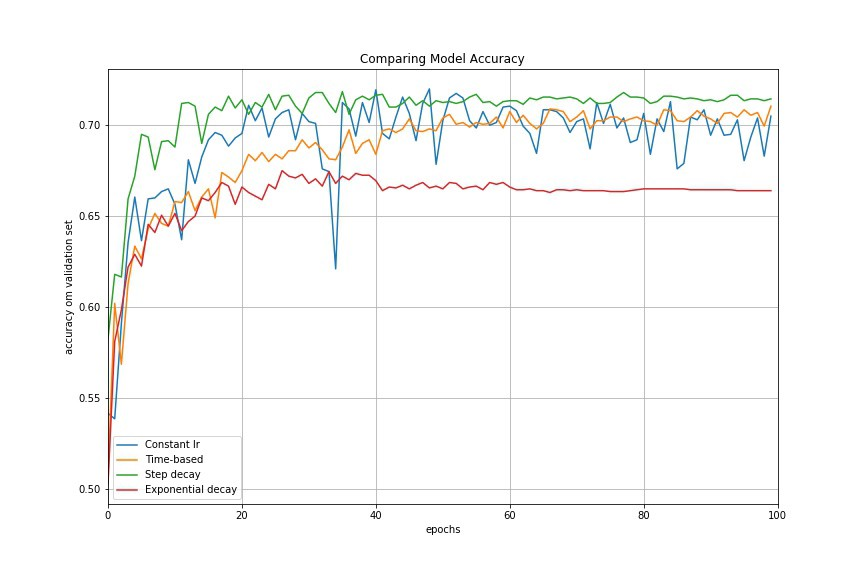
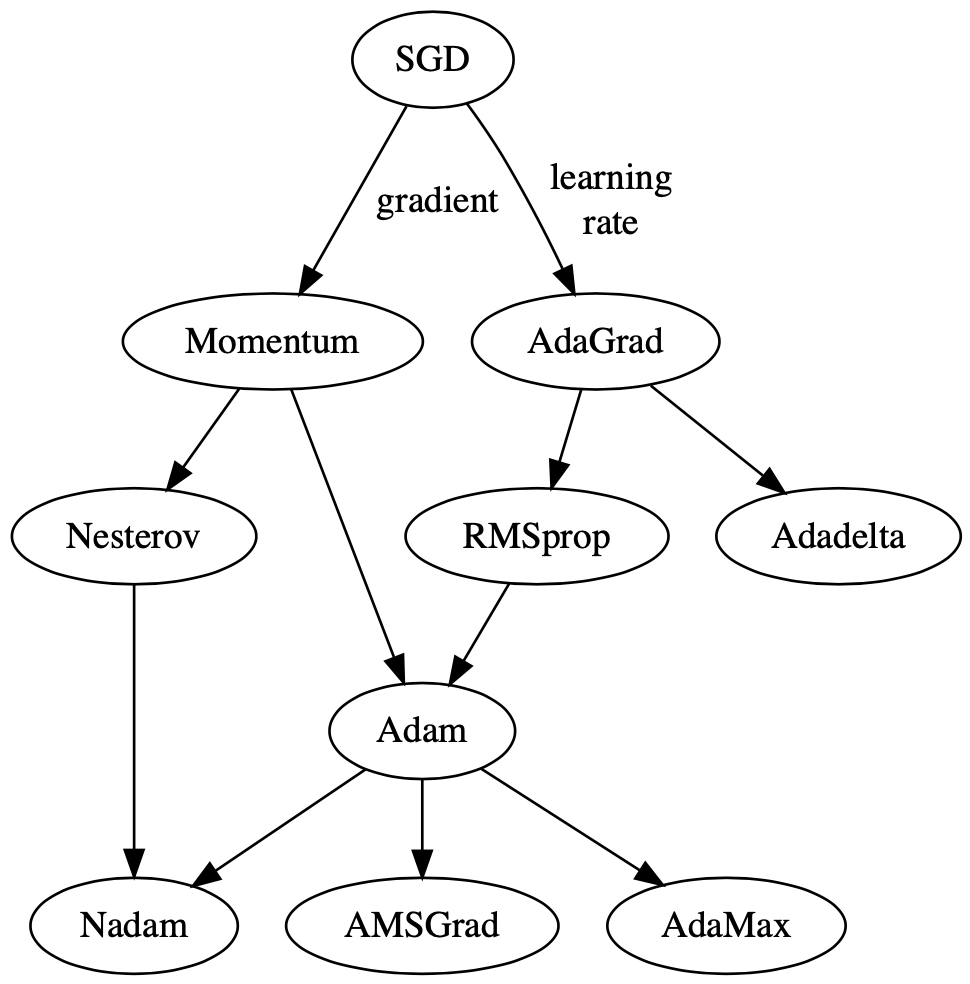
Adaptive gradient descent algorithms such as Adagrad, Adadelta, RMSprop, Adam, provide an alternative to classical SGD.
These per-parameter learning rate methods provide heuristic approach without requiring expensive work in tuning hyperparameters for the learning rate schedule manually.
- Adagrad performs larger updates for more sparse parameters and smaller updates for less sparse parameter. It has good performance with sparse data and training large-scale neural network. However, its monotonic learning rate usually proves too aggressive and stops learning too early when training deep neural networks.
- Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate.
- RMSprop adjusts the Adagrad method in a very simple way in an attempt to reduce its aggressive, monotonically decreasing learning rate.
- Adam is an update to the RMSProp optimizer which is like RMSprop with momentum.
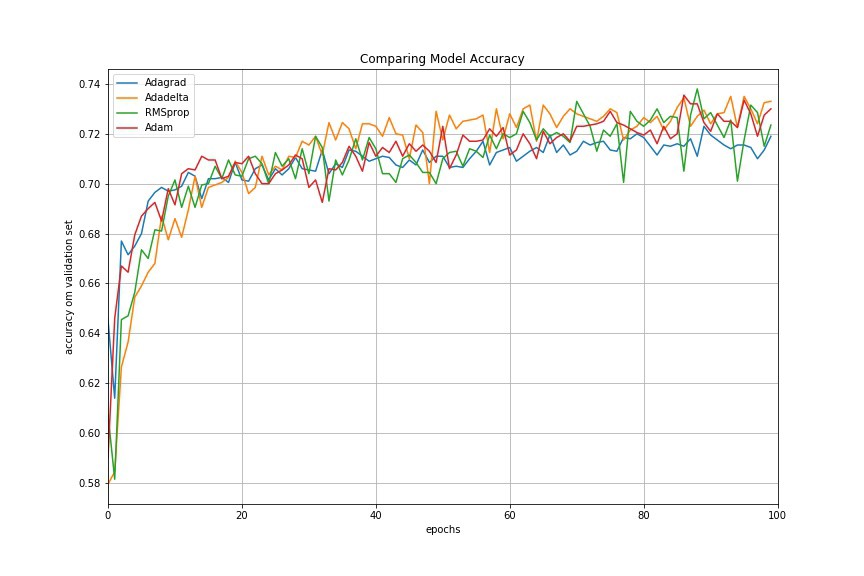
adaptive learning rate methods demonstrate better performance than learning rate schedules, and they require much less effort in hyperparamater settings
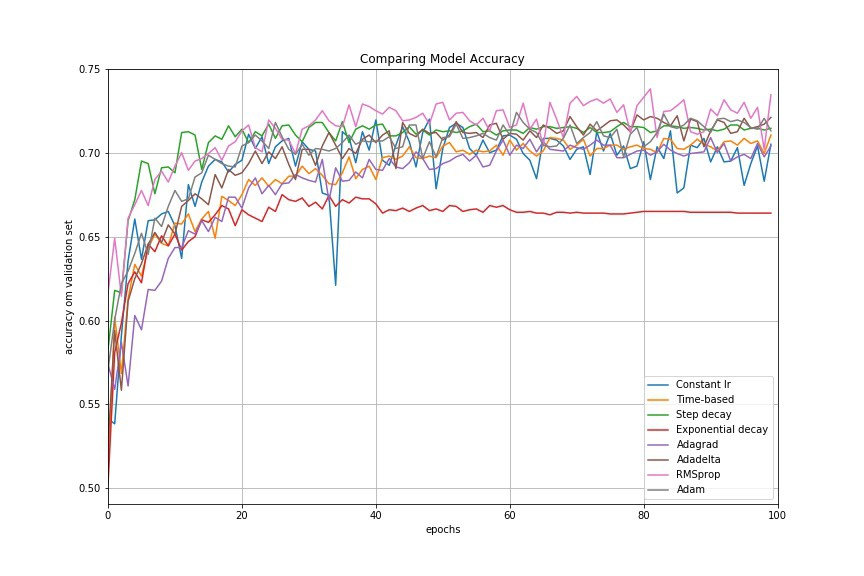
Recommended paper: practical recommendation for gradient based DNN
Another great comparison - pdf paper and webpage link -
- if your input data is sparse, then you likely achieve the best results using one of the adaptive learning-rate methods.
- An additional benefit is that you will not need to tune the learning rate but will likely achieve the best results with the default value.
- In summary, RMSprop is an extension of Adagrad that deals with its radically diminishing learning rates. It is identical to Adadelta, except that Adadelta uses the RMS of parameter updates in the numerator update rule. Adam, finally, adds bias-correction and momentum to RMSprop. Insofar, RMSprop, Adadelta, and Adam are very similar algorithms that do well in similar circumstances. Kingma et al. [10] show that its bias-correction helps Adam slightly outperform RMSprop towards the end of optimization as gradients become sparser. Insofar, Adam might be the best overall choice
The second important quantity to track while training a classifier is the validation/training accuracy. This plot can give you valuable insights into the amount of overfitting in your model:
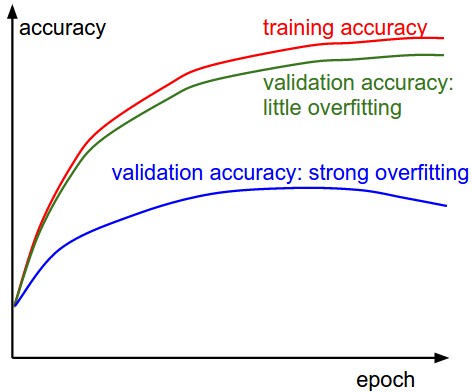
- The gap between the training and validation accuracy indicates the amount of overfitting.
- Two possible cases are shown in the diagram on the left. The blue validation error curve shows very small validation accuracy compared to the training accuracy, indicating strong overfitting (note, it's possible for the validation accuracy to even start to go down after some point).
- NOTE: When you see this in practice you probably want to increase regularization:
- stronger L2 weight penalty
- Dropout
- collect more data.
- The other possible case is when the validation accuracy tracks the training accuracy fairly well. This case indicates that your model capacity is not high enough: make the model larger by increasing the number of parameters.
XAVIER GLOROT:
Why’s Xavier initialization important?
In short, it helps signals reach deep into the network.
- If the weights in a network start too small, then the signal shrinks as it passes through each layer until it’s too tiny to be useful.
- If the weights in a network start too large, then the signal grows as it passes through each layer until it’s too massive to be useful.
Xavier initialization makes sure the weights are ‘just right’, keeping the signal in a reasonable range of values through many layers.
To go any further than this, you’re going to need a small amount of statistics - specifically you need to know about random distributions and their variance.
When to use glorot uniform-over-normal initialization?
However, i am still not seeing anything empirical that says that glorot surpesses everything else under certain conditions (except the glorot paper), most importantly, does it really help in LSTM where the vanishing gradient is ~no longer an issue?
This method of initializing became famous through a paper submitted in 2015 by He et al, and is similar to Xavier initialization, with the factor multiplied by two. In this method, the weights are initialized keeping in mind the size of the previous layer which helps in attaining a global minimum of the cost function faster and more efficiently.
w=np.random.randn(layer_size[l],layer_size[l-1])*np.sqrt(2/layer_size[l-1])
(a bunch of observations, seems like a personal list) -
- Output layer - linear for regression, softmax for classification
- Hidden layers - hyperbolic tangent for shallow networks (less than 3 hidden layers), and ReLU for deep networks
ReLU - The purpose of ReLU is to introduce non-linearity, since most of the real-world data we would want our network to learn would be nonlinear (e.g. convolution is a linear operation – element wise matrix multiplication and addition, so we account for nonlinearity by introducing a nonlinear function like ReLU, e.g here - search for ReLU).
- Relu is quite resistant to vanishing gradient & allows for deactivating neurons and for sparsity.
- Other nonlinear functions such as tanh or sigmoid can also be used instead of ReLU, but ReLU has been found to perform better in most situations.
- Visual + description of activation functions
- A very good explanation + figures about activations functions
Selu - better than RELU? Possibly.
Mish: A Self Regularized Non-Monotonic Neural Activation Function, yam peleg’s code
Mish, Medium, Keras Code, with benchmarks, computationally expensive.
There are several optimizers, each had his 15 minutes of fame, some optimizers are recommended for CNN, Time Series, etc..
There are also what I call ‘experimental’ optimizers, it seems like these pop every now and then, with or without a formal proof. It is recommended to follow the literature and see what are the ‘supposedly’ state of the art optimizers atm.
Adamod deeplearning optimizer with memory
Backstitch - September 17 - supposedly an improvement over SGD for speech recognition using DNN. Note: it wasnt tested with other datasets or other network types.
(how does it work?) take a negative step back, then a positive step forward. I.e., When processing a minibatch, instead of taking a single SGD step, we first take a step with −α times the current learning rate, for α > 0 (e.g. α = 0.3), and then a step with 1 + α times the learning rate, with the same minibatch (and a recomputed gradient). So we are taking a small negative step, and then a larger positive step. This resulted in quite large improvements – around 10% relative improvement [37] – for our best speech recognition DNNs. The recommended hyper parameters are in the paper.
Drawbacks: takes twice to train, momentum not implemented or tested, dropout is mandatory for improvement, slow starter.
Documentation about optimizers in keras
- SGD can be fine tuned
- For others Leave most parameters as they were
Best description on optimizers with momentum etc, from sgd to nadam, formulas and intuition
A very influential paper about dropout and how beneficial it is - bottom line always use it.
OPEN QUESTIONs:
- does a dropout layer improve performance even if an lstm layer has dropout or recurrent dropout.
- What is the diff between a separate layer and inside the lstm layer.
- What is the diff in practice and intuitively between drop and recurrentdrop
Dropout layers in keras, or dropout regularization:
- Dropout is a technique where randomly selected neurons are ignored RANDOMLY during training.
- contribution to the activation of downstream neurons is temporally removed on the forward pass and any weight updates are not applied to the neuron on the backward pass.
- As a neural network learns, neuron weights settle into their context within the network.
- Weights of neurons are tuned for specific features providing some specialization. Neighboring neurons become to rely on this specialization, which if taken too far can result in a fragile model too specialized to the training data. (overfitting)
- This reliant on context for a neuron during training is referred to complex co-adaptations.
- After dropout, other neurons will have to step in and handle the representation required to make predictions for the missing neurons, which is believed to result in multiple independent internal representations being learned by the network.
- Thus, the effect of dropout is that the network becomes less sensitive to the specific weights of neurons.
- This in turn leads to a network with better generalization capability and less likely to overfit the training data.
Another great answer about drop out -
- as a consequence of the 50% dropout, the neural network will learn different, redundant representations; the network can’t rely on the particular neurons and the combination (or interaction) of these to be present.
- Another nice side effect is that training will be faster.
- Rules:
- Dropout is only applied during training,
- Need to rescale the remaining neuron activations. E.g., if you set 50% of the activations in a given layer to zero, you need to scale up the remaining ones by a factor of 2.
- if the training has finished, you’d use the complete network for testing (or in other words, you set the dropout probability to 0).
Implementation of drop out in keras is “inverse dropout” - n the Keras implementation, the output values are corrected during training (by dividing, in addition to randomly dropping out the values) instead of during testing (by multiplying). This is called "inverted dropout".
Inverted dropout is functionally equivalent to original dropout (as per your link to Srivastava's paper), with a nice feature that the network does not use dropout layers at all during test and prediction. This is explained a little in this Keras issue.
Dropout notes and rules of thumb aka “best practice” -
- dropout value of 20%-50% of neurons with 20% providing a good starting point. (A probability too low has minimal effect and a value too high results in underlearning by the network.)
- Use a large network for better performance, i.e., when dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.
- Use dropout on VISIBLE AND HIDDEN. Application of dropout at each layer of the network has shown good results.
- Unclear ? Use a large learning rate with decay and a large momentum. Increase your learning rate by a factor of 10 to 100 and use a high momentum value of 0.9 or 0.99.
- Unclear ? Constrain the size of network weights. A large learning rate can result in very large network weights. Imposing a constraint on the size of network weights such as max-norm regularization with a size of 4 or 5 has been shown to improve results.
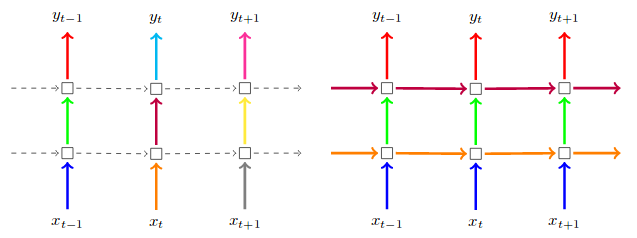
Difference between LSTM ‘dropout’ and ‘recurrent_dropout’ - vertical vs horizontal.
I suggest taking a look at (the first part of) this paper. Regular dropout is applied on the inputs and/or the outputs, meaning the vertical arrows from x_t and to h_t. In you add it as an argument to your layer, it will mask the inputs; you can add a Dropout layer after your recurrent layer to mask the outputs as well. Recurrent dropout masks (or "drops") the connections between the recurrent units; that would be the horizontal arrows in your picture.
This picture is taken from the paper above. On the left, regular dropout on inputs and outputs. On the right, regular dropout PLUS recurrent dropout:
Basically do these after you have a working network
- Dont decay the learning rate, increase batchsize - paper (optimization of a network)
- Add one neuron with skip connection, or to every layer in a binary classification network to get global minimum.
- 3 methods to fine tune, cut softmax layer, smaller learning rate, freeze layers
- Fine tuning on a sunset of data
- (did not fully read) Yoav Goldberg’s course syllabus with lots of relevant topics on DL4NLP, including bidirectional RNNS and tree RNNs.
- (did not fully read) CS224d: Deep Learning for Natural Language Processing, with slides etc.
Deep Learning using Linear Support Vector Machines - 1-3% decrease in error by replacing the softmax layer with a linear support vector machine
- A machine learning framework for multi-output/multi-label and stream data. Inspired by MOA and MEKA, following scikit-learn's philosophy. https://scikit-multiflow.github.io/
- Medium on MO, sklearn and keras
- MO in keras, see functional API on how.
- Deep learning with pytorch - The book
- Pytorch DL course, git - yann lecun
A make sense introduction into keras, has several videos on the topic, going through many network types, creating custom activation functions, going through examples.
+ Two extra videos from the same author, examples and examples-2
Didn’t read:
- Keras cheatsheet
- Seq2Seq RNN
- Stateful LSTM - Example script showing how to use stateful RNNs to model long sequences efficiently.
- CONV LSTM - this script demonstrate the use of a conv LSTM network, used to predict the next frame of an artificially generated move which contains moving squares.
How to force keras to use tensorflow and not teano (set the .bat file)
Callbacks - how to create an AUC ROC score callback with keras - with code example.
Batch size vs. Iterations in NN \ Keras.
Keras metrics - classification regression and custom metrics
Keras Metrics 2 - accuracy, ROC, AUC, classification, regression r^2.
Introduction to regression models in Keras, using MSE, comparing baseline vs wide vs deep networks.
How does Keras calculate accuracy? Formula and explanation
Compares label with the rounded predicted float, i.e. bigger than 0.5 = 1, smaller than = 0
For categorical we take the argmax for the label and the prediction and compare their location.
In both cases, we average the results.
Custom metrics (precision recall) in keras. Which are taken from here, including entropy and f1
KERAS MULTI GPU
- When using SGD only batches between 32-512 are adequate, more can lead to lower performance, less will lead to slow training times.
- Note: probably doesn't reflect on adam, is there a reference?
- Parallel gpu-code for keras. Its a one liner, but remember to scale batches by the amount of GPU used in order to see a (non linear) scaability in training time.
- Pitfalls in GPU training, this is a very important post, be aware that you can corrupt your weights using the wrong combination of batches-to-input-size, in keras-tensorflow. When you do multi-GPU training, it is important to feed all the GPUs with data. It can happen that the very last batch of your epoch has less data than defined (because the size of your dataset can not be divided exactly by the size of your batch). This might cause some GPUs not to receive any data during the last step. Unfortunately some Keras Layers, most notably the Batch Normalization Layer, can’t cope with that leading to nan values appearing in the weights (the running mean and variance in the BN layer).
- 5 things to be aware of for multi gpu using keras, crucial to look at before doing anything
KERAS FUNCTIONAL API
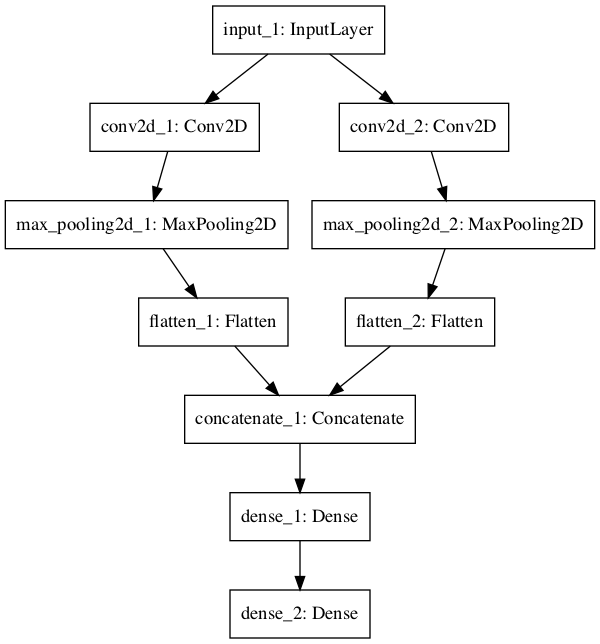
What is and how to use? A flexible way to declare layers in parallel, i.e. parallel ways to deal with input, feature extraction, models and outputs as seen in the following images.
KERAS EMBEDDING LAYER
- Injecting glove to keras embedding layer and using it for classification + what is and how to use the embedding layer in keras.
- Keras blog - using GLOVE for pretrained embedding layers.
- Word embedding using keras, continuous BOW - CBOW, SKIPGRAM, word2vec - really good.
- Fasttext - comparison of key feature against word2vec
- Multiclass classification using word2vec/glove + code
- word2vec/doc2vec/tfidf code in python for text classification
- Lda & word2vec
- Text classification with word2vec
- Gensim word2vec, and another one
- Fasttext paper
Keras: Predict vs Evaluate
.predict() generates output predictions based on the input you pass it (for example, the predicted characters in the MNIST example)
.evaluate() computes the loss based on the input you pass it, along with any other metrics that you requested in the metrics param when you compiled your model (such as accuracy in the MNIST example)
Keras metrics
For classification methods - how does keras calculate accuracy, all functions.
LOSS IN KERAS
Why is the training loss much higher than the testing loss? A Keras model has two modes: training and testing. Regularization mechanisms, such as Dropout and L1/L2 weight regularization, are turned off at testing time.
The training loss is the average of the losses over each batch of training data. Because your model is changing over time, the loss over the first batches of an epoch is generally higher than over the last batches. On the other hand, the testing loss for an epoch is computed using the model as it is at the end of the epoch, resulting in a lower loss.
- How to use AE for dimensionality reduction + code - using keras’ functional API
- Keras.io blog post about AE’s - regular, deep, sparse, regularized, cnn, variational
- A keras.io replicate post but explains AE quite nicely.
- Examples of vanilla, multi layer, CNN and sparse AE’s
- Another example of CNN-AE
- Another AE tutorial
- Hinton’s coursera course on PCA vs AE, basically some info about what PCA does - maximizing variance and projecting and then what AE does and can do to achieve similar but non-linear dense representations
- A great tutorial on how does the clusters look like after applying PCA/ICA/AE
- Another great presentation on PCA vs AE, summarized in the KPCA section of this notebook. +another one +StackExchange
- Autoencoder tutorial with python code and how to encode after, mastery
- Git code for low dimensional auto encoder
- Bart denoising AE, sequence to sequence pre training for NL generation translation and comprehension.
- Attention based seq to seq auto encoder, git
AE for anomaly detection, fraud detection
- Unread - Simple explanation
- Pixel art VAE
- Unread - another VAE
- Pixel GAN VAE
- Disentangled VAE - improves VAE
- Optimus - pretrained VAE, paper, Microsoft blog****

- Git
- Step by step with examples, calculations
- Adds intuition regarding “magnetism”’
- Implementation and faces, intuition towards each node and what it represents in a vision. I.e., each face resembles one of K clusters.
- Medium on kohonen networks, i.e., SOM
- Som on iris, explains inference - averaging, and cons of the method.
- Simple explanation
- Algorithm, formulas
NEAT
NEAT **stands for NeuroEvolution of Augmenting Topologies. It is a method for evolving artificial neural networks with a genetic algorithm.
NEAT implements the idea that it is most effective to start evolution with small, simple networks and allow them to become increasingly complex over generations.**
**That way, just as organisms in nature increased in complexity since the first cell, so do neural networks in NEAT.
This process of continual elaboration allows finding highly sophisticated and complex neural networks.**
HYPER-NEAT
HyperNEAT **computes the connectivity of its neural networks as a function of their geometry.
HyperNEAT is based on a theory of representation that hypothesizes that a good representation for an artificial neural network should be able to describe its pattern of connectivity compactly.**
The encoding in HyperNEAT, called compositional pattern producing networks**, is designed to represent patterns with regularities such as symmetry, repetition, and repetition with variationץ
(WIKI)** Compositional pattern-producing networks (CPPNs) are a variation of artificial neural networks (ANNs) that have an architecture whose evolution is guided by genetic algorithms

A great HyperNeat tutorial on Medium.
The RBFN approach is more intuitive than the MLP.
- An RBFN performs classification by measuring the input’s similarity to examples from the training set.
- Each RBFN neuron stores a “prototype”, which is just one of the examples from the training set.
- When we want to classify a new input, each neuron computes the Euclidean distance between the input and its prototype.
- Roughly speaking, if the input more closely resembles the class A prototypes than the class B prototypes, it is classified as class A.

BNN - (what is?) Bayesian neural network (BNN) according to Uber - architecture that more accurately forecasts time series predictions and uncertainty estimations at scale. “how Uber has successfully applied this model to large-scale time series anomaly detection, enabling better accommodate rider demand during high-traffic intervals.”
Under the BNN framework, prediction uncertainty can be categorized into three types:
- Model uncertainty captures our ignorance of the model parameters and can be reduced as more samples are collected.
- model misspecification
- inherent noise captures the uncertainty in the data generation process and is irreducible.
Note: in a series of articles, uber explains about time series and leads to a BNN architecture.
- Neural networks - training on multi-signal raw data, training X and Y are window-based and the window size(lag) is determined in advance.
Vanilla LSTM did not work properly, therefore an architecture of
Regarding point 1: ‘run prediction with dropout 100 times’
*** MEDIUM with code how to do it.
Why do we need a confidence measure when we have a softmax probability layer? The blog post explains, for example, that with a CNN of apples, oranges, cat and dogs, a non related example such as a frog image may influence the network to decide its an apple, therefore we can’t rely on the probability as a confidence measure. The ‘run prediction with dropout 100 times’ should give us a confidence measure because it draws each weight from a bernoulli distribution.
“By applying dropout to all the weight layers in a neural network, we are essentially drawing each weight from a Bernoulli distribution. In practice, this mean that we can sample from the distribution by running several forward passes through the network. This is referred to as Monte Carlo dropout.”
Taken from Yarin Gal’s blog post . In this figure we see how sporadic is the signal from a forward pass (black line) compared to a much cleaner signal from 100 dropout passes.

Is it applicable for time series? In the figure below he tried to predict the missing signal between each two dotted lines, A is a bad estimation, but with a dropout layer we can see that in most cases the signal is better predicted.

Going back to uber, they are actually using this idea to predict time series with LSTM, using encoder decoder framework.

Note: this is probably applicable in other types of networks.
Phd Thesis by Yarin, he talks about uncertainty in Neural networks and using BNNs. he may have proved this thesis, but I did not read it. This blog post links to his full Phd.
Old note: The idea behind uncertainty is (paper here) that in order to trust your network’s classification, you drop some of the neurons during prediction, you do this ~100 times and you average the results. Intuitively this will give you confidence in your classification and increase your classification accuracy, because only a partial part of your network participated in the classification, randomly, 100 times. Please note that Softmax doesn't give you certainty.
Medium post on prediction with drop out
The solution for keras says to add trainable=true for every dropout layer and add another drop out at the end of the model. Thanks sam.
“import keras
inputs = keras.Input(shape=(10,))
x = keras.layers.Dense(3)(inputs)
outputs = keras.layers.Dropout(0.5)(x, training=True)
model = keras.Model(inputs, outputs)“

(an excellent and thorough explanation about LeNet) -
- Convolution Layer primary purpose is to extract features from the input image. Convolution preserves the spatial relationship between pixels by learning image features using small squares of input data.
- ReLU (more in the activation chapter) - The purpose of ReLU is to introduce non-linearity in our ConvNet
- Spatial Pooling (also called subsampling or downsampling) reduces the dimensionality of each feature map but retains the most important information. Spatial Pooling can be of different types: Max, Average, Sum etc.
- Dense / Fully Connected - a traditional Multi Layer Perceptron that uses a softmax activation function in the output layer to classify. The output from the convolutional and pooling layers represent high-level features of the input image. The purpose of the Fully Connected layer is to use these features for classifying the input image into various classes based on the training dataset.
The overall training process of the Convolutional Network may be summarized as below:
- Step1: We initialize all filters and parameters / weights with random values
- Step2: The network takes a single training image as input, goes through the forward propagation step (convolution, ReLU and pooling operations along with forward propagation in the Fully Connected layer) and finds the output probabilities for each class.
- Let's say the output probabilities for the boat image above are [0.2, 0.4, 0.1, 0.3]
- Since weights are randomly assigned for the first training example, output probabilities are also random.
- Step3: Calculate the total error at the output layer (summation over all 4 classes)
- (L2) Total Error = ∑ ½ (target probability – output probability) ²
- Step4: Use Backpropagation to calculate the gradients of the error with respect to all weights in the network and use gradient descent to update all filter values / weights and parameter values to minimize the output error.
- The weights are adjusted in proportion to their contribution to the total error.
- When the same image is input again, output probabilities might now be [0.1, 0.1, 0.7, 0.1], which is closer to the target vector [0, 0, 1, 0].
- This means that the network has learnt to classify this particular image correctly by adjusting its weights / filters such that the output error is reduced.
- Parameters like number of filters, filter sizes, architecture of the network etc. have all been fixed before Step 1 and do not change during training process – only the values of the filter matrix and connection weights get updated.
- Step5: Repeat steps 2-4 with all images in the training set.
The above steps train the ConvNet – this essentially means that all the weights and parameters of the ConvNet have now been optimized to correctly classify images from the training set.
When a new (unseen) image is input into the ConvNet, the network would go through the forward propagation step and output a probability for each class (for a new image, the output probabilities are calculated using the weights which have been optimized to correctly classify all the previous training examples). If our training set is large enough, the network will (hopefully) generalize well to new images and classify them into correct categories.
Illustrated 10 CNNS architectures
A study that deals with class imbalance in CNN’s - we systematically investigate the impact of class imbalance on classification performance of convolutional neural networks (CNNs) and compare frequently used methods to address the issue
- Over sampling
- Undersampling
- Thresholding probabilities (ROC?)
- Cost sensitive classification -different cost to misclassification
- One class - novelty detection. This is a concept learning technique that recognizes positive instances rather than discriminating between two classes
Using several imbalance scenarios, on several known data sets, such as MNIST

The results indication (loosely) that oversampling is usually better in most cases, and doesn't cause overfitting in CNNs.
CONV-1D
- How to setup a conv1d in keras, most importantly how to reshape your input vector
- Mastery on Character ngram cnn for sentiment analysis
1x1 CNN
- Mastery on 1x1 cnn, for dim reduction, decreasing feature maps and other usages.
- “This is the most common application of this type of filter and in this way, the layer is often called a feature map pooling layer.”
- “In the paper, the authors propose the need for an MLP convolutional layer and the need for cross-channel pooling to promote learning across channels.”
- “the 1×1 filter was used explicitly for dimensionality reduction and for increasing the dimensionality of feature maps after pooling in the design of the inception module, used in the GoogLeNet model”
- “The 1×1 filter was used as a projection technique to match the number of filters of input to the output of residual modules in the design of the residual network “
MASKED R-CNN
1. Using mask rnn for object detection
Invariance in CNN
- Making cnn shift invariance - “Small shifts -- even by a single pixel -- can drastically change the output of a deep network (bars on left). We identify the cause: aliasing during downsampling. We anti-alias modern deep networks with classic signal processing, stabilizing output classifications (bars on right). We even observe accuracy increases (see plot below).
MAX AVERAGE POOLING
Intuitions to the differences between max and average pooling:
- A max-pool layer compressed by taking the maximum activation in a block. If you have a block with mostly small activation, but a small bit of large activation, you will loose the information on the low activations. I think of this as saying "this type of feature was detected in this general area".
- A mean-pool layer compresses by taking the mean activation in a block. If large activations are balanced by negative activations, the overall compressed activations will look like no activation at all. On the other hand, you retain some information about low activations in the previous example.
- MAX pooling In other words: Max pooling roughly means that only those features that are most strongly triggering outputs are used in the subsequent layers. You can look at it a little like focusing the network’s attention on what’s most characteristic for the image at hand.
- GLOBAL MAX pooling: In the last few years, experts have turned to global average pooling (GAP) layers to minimize overfitting by reducing the total number of parameters in the model. Similar to max pooling layers, GAP layers are used to reduce the spatial dimensions of a three-dimensional tensor. However, GAP layers perform a more extreme type of dimensionality reduction,
- Hinton’s controversy thoughts on pooling
Dilated CNN
RESNET, DENSENET UNET
- A https://medium.com/swlh/resnets-densenets-unets-6bbdbcfdf010
- on the trick behind them, concatenating both f(x) = x
Explaination here, with some examples
- The solution to CNN’s shortcomings, where features can be identified without relations to each other in an image, i.e. changing the location of body parts will not affect the classification, and changing the orientation of the image will. The promise of capsule nets is that these two issues are solved.
- Understanding capsule nets - part 2, there are more parts to the series
- To Add keras book chapter 5 (i think)
- Mastery on TL using CNN
- Classifier: The pre-trained model is used directly to classify new images.
- Standalone Feature Extractor: The pre-trained model, or some portion of the model, is used to pre-process images and extract relevant features.
- Integrated Feature Extractor: The pre-trained model, or some portion of the model, is integrated into a new model, but layers of the pre-trained model are frozen during training.
- Weight Initialization: The pre-trained model, or some portion of the model, is integrated into a new model, and the layers of the pre-trained model are trained in concert with the new model.
RNN - a basic NN node with a loop, previous output is merged with current input (using tanh?), for the purpose of remembering history, for time series - to predict the next X based on the previous Y.
(What is RNN?) by Andrej Karpathy - The Unreasonable Effectiveness of Recurrent Neural Networks, basically a lot of information about RNNs and their usage cases 1 to N = frame captioning
- N to 1 = classification
- N to N = predict frames in a movie
- N\2 with time delay to N\2 = predict supply and demand
- Vanishing gradient is 100 times worse.
- Gate networks like LSTM solves vanishing gradient.
(how to initialize?) Benchmarking RNN networks for text - don't worry about initialization, use normalization and GRU for big networks.
** Experimental improvements:
Ref - ”Simplified RNN, with pytorch implementation” - changing the underlying mechanism in RNNs for the purpose of parallelizing calculation, seems to work nicely in terms of speed, not sure about state of the art results. Controversy regarding said work, author claims he already mentioned these ideas (QRNN) first, a year before, however it seems like his ideas have also been reviewed as incremental (PixelRNN). Its probably best to read all 3 papers in chronological order and use the most optimal solution.
RNNCELLS - recurrent shop, enables you to build complex rnns with keras. Details on their significance are inside the link
Masking for RNNs - the ideas is simple, we want to use variable length inputs, although rnns do use that, they require a fixed size input. So masking of 1’s and 0’s will help it understand the real size or where the information is in the input. Motivation: Padded inputs are going to contribute to our loss and we dont want that.
Visual attention RNNS - Same idea as masking but on a window-based cnn. Paper
LSTM
- The best, hands down, lstm post out there
- LSTM - what is? the first reference for LSTM on the web, but you should know the background before reading.
- Hidden state vs cell state - you have to understand this concept before you dive in. i.e, Hidden state is overall state of what we have seen so far. Cell state is selective memory of the past. The hidden state (h) carries the information about what an RNN cell has seen over the time and supply it to the present time such that a loss function is not just dependent upon the data it is seeing in this time instant, but also, data it has seen historically.
- Illustrated rnn lstm gru
- Paper - a comparison of many LSTMs variants and they are pretty much the same performance wise
- Paper - comparison of lstm variants, vanilla is mostly the best, forget and output gates are the most important in terms of performance. Other conclusions in the paper..
- Master on unrolling RNN’s introductory post
- Mastery on under/over fitting lstms - but makes sense for all types of networks
- Mastery on return_sequence and return_state in keras LSTM
- That return sequences return the hidden state output for each input time step.
- That return state returns the hidden state output and cell state for the last input time step.
- That return sequences and return state can be used at the same time.
- Mastery on understanding stateful vs stateless, stateful stateless for time series
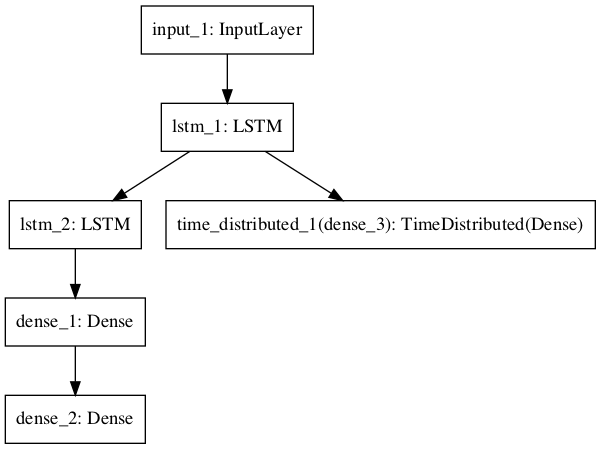
- Mastery on timedistributed layer and seq2seq
- TimeDistributed Layer - used to connect 3d inputs from lstms to dense layers, in order to utilize the time element. Otherwise it gets flattened when the connection is direct, nulling the lstm purpose. Note: nice trick that doesn't increase the dense layer structure multiplied by the number of dense neurons. It loops for each time step! I.e., The TimeDistributed achieves this trick by applying the same Dense layer (same weights) to the LSTMs outputs for one time step at a time. In this way, the output layer only needs one connection to each LSTM unit (plus one bias).

For this reason, the number of training epochs needs to be increased to account for the smaller network capacity. I doubled it from 500 to 1000 to match the first one-to-one example
- Sequence Learning Problem
- One-to-One LSTM for Sequence Prediction
- Many-to-One LSTM for Sequence Prediction (without TimeDistributed)
- Many-to-Many LSTM for Sequence Prediction (with TimeDistributed)
-
- Mastery on wrapping cnn-lstm with time distributed, as a whole model wrap, or on every layer in the model which is equivalent and preferred.
- Master on visual examples for sequence prediction
- Unread - sentiment classification of IMDB movies using Keras and LSTM
- Very important - how to interpret LSTM neurons in keras
- LSTM for time-series - (jakob) single point prediction, sequence prediction and shifted-sequence prediction with code.
Stateful vs Stateless: crucial for understanding how to leverage LSTM networks:
- A good description on what it is and how to use it.
- ML mastery ****
- Philippe remy on stateful vs stateless, intuition mostly with code, but not 100% clear
Machine Learning mastery:
A good tutorial on LSTM: important notes:
1. Scale to -1,1, because the internal activation in the lstm cell is tanh.
2.stateful - True, needs to reset internal states, False =stateless. Great info & results HERE, with seeding, with training resets (and not) and predicting resets (and not) - note: empirically matching the shampoo input, network config, etc.
Another explanation/tutorial about stateful lstm, should be thorough.
3. what is return_sequence, return_states, and how to use each one and both at the same time.
Return_sequence is needed for stacked LSTM layers.
4.stacked LSTM - each layer has represents a higher level of abstraction in TIME!
Keras Input shape - a good explanation about differences between input_shape, dim, and what is. Additionally about layer calculation of inputs and output based on input shape, and sequence model vs API model.
A comparison of LSTM/GRU/MGU with batch normalization and various initializations, GRu/Xavier/Batch are the best and recommended for RNN
Benchmarking LSTM variants: - it looks like LSTM and GRU are competitive to mutation (i believe its only in pytorch) adding a bias to LSTM works (a bias of 1 as recommended in the paper), but generally speaking there is no conclusive empirical evidence that says one type of network is better than the other for all tests, but the mutated networks tend to win over lstm\gru variants.
BIAS 1 in keras - unit_forget_bias: Boolean. If True, add 1 to the bias of the forget gate at initializationSetting it to true will also force bias_initializer="zeros". This is recommended in Jozefowicz et al.

Validation_split arg - The validation split variable in Keras is a value between [0..1]. Keras proportionally split your training set by the value of the variable. The first set is used for training and the 2nd set for validation after each epoch.
This is a nice helper add-on by Keras, and most other Keras examples you have seen the training and test set was passed into the fit method, after you have manually made the split. The value of having a validation set is significant and is a vital step to understand how well your model is training. Ideally on a curve you want your training accuracy to be close to your validation curve, and the moment your validation curve falls below your training curve the alarm bells should go off and your model is probably busy over-fitting.
Keras is a wonderful framework for deep learning, and there are many different ways of doing things with plenty of helpers.
Return_sequence: unclear.
Sequence.pad_sequences - using maxlength it will either pad with zero if smaller than, or truncate it if bigger.
Using batch size for LSTM in Keras
Imbalanced classes? Use class_weights, another explanation here about class_weights and sample_weights.
SKlearn Formula for balanced class weights and why it works, example
Calculate how many params are in an LSTM layer?

Understanding timedistributed in Keras, but with focus on lstm one to one, one to many and many to many - here the timedistributed is applying a dense layer to each output neuron from the lstm, which returned_sequence = true for that purpose.
This tutorial clearly shows how to manipulate input construction, lstm output neurons and the target layer for the purpose of those three problems (1:1, 1:m, m:m).
BIDIRECTIONAL LSTM
(what is?) Wiki - The basic idea of BRNNs is to connect two hidden layers of opposite directions to the same output. By this structure, the output layer can get information from past and future states.
BRNN are especially useful when the context of the input is needed. For example, in handwriting recognition, the performance can be enhanced by knowledge of the letters located before and after the current letter.
Another explanation- It involves duplicating the first recurrent layer in the network so that there are now two layers side-by-side, then providing the input sequence as-is as input to the first layer and providing a reversed copy of the input sequence to the second.
.. It allows you to specify the merge mode, that is how the forward and backward outputs should be combined before being passed on to the next layer. The options are:
- ‘sum‘: The outputs are added together.
- ‘mul‘: The outputs are multiplied together.
- ‘concat‘: The outputs are concatenated together (the default), providing double the number of outputs to the next layer.
- ‘ave‘: The average of the outputs is taken.
The default mode is to concatenate, and this is the method often used in studies of bidirectional LSTMs.
BACK PROPAGATION
UNSUPERVISED LSTM
GRU
A tutorial about GRU - To solve the vanishing gradient problem of a standard RNN, GRU uses, so called, update gate and reset gate. Basically, these are two vectors which decide what information should be passed to the output. The special thing about them is that they can be trained to keep information from long ago, without washing it through time or remove information which is irrelevant to the prediction.
- update gate helps the model to determine how much of the past information (from previous time steps) needs to be passed along to the future.
- Reset gate essentially, this gate is used from the model to decide how much of the past information to forget.
RECURRENT WEIGHTED AVERAGE (RNN-WA)
What is? (a type of cell that converges to higher accuracy faster than LSTM.
it implements attention into the recurrent neural network:
1. the keras implementation is available at https://github.com/keisuke-nakata/rwa ****
2. the whitepaper is at https://arxiv.org/pdf/1703.01253.pdf

QRNN
Potential competitor to the transformer
- (amazing) Why i am luke warm about GNN’s - really good insight to what they do (compressing data, vs adjacy graphs, vs graphs, high dim relations, etc.)
- Learning on graphs youtube - uriel singer
- Benchmarking GNN’s, methodology, git, the works.
- Awesome graph classification on github
- Octavian in medium on graphs, A really good intro to graph networks, too long too summarize, clever, mcgraph, regression, classification, embedding on graphs.
- Application of graph networks ****
- Recommender systems using GNN, w2v, pytorch w2v, networkx, sparse matrices, matrix factorization, dictionary optimization, part 1 here (how to find product relations, important: creating negative samples)
- Transformers are GNN, original: Transformers are graphs, not the typical embedding on a graph, but a more holistic approach to understanding text as a graph.
- Cnn for graphs
- Staring with gnn
- Really good - Basics deep walk and graphsage ****
- Application of gnn
- Michael Bronstein’s Central page for Graph deep learning articles on Medium (worth reading)
- GAT graphi attention networks, paper, examples - The graph attentional layer utilised throughout these networks is computationally efficient (does not require costly matrix operations, and is parallelizable across all nodes in the graph), allows for (implicitly) assigning different importances to different nodes within a neighborhood while dealing with different sized neighborhoods, and does not depend on knowing the entire graph structure upfront—thus addressing many of the theoretical issues with approaches.
- Medium on Intro, basics, deep walk, graph sage
Deep walk
- Git
- Paper
- Medium and medium on W2v, deep walk, graph2vec, n2v
Node2vec
Graphsage
SDNE - structural deep network embedding
Diff2vec

Splitter
, git, paper, “Is a Single Embedding Enough? Learning Node Representations that Capture Multiple Social Contexts”
Recent interest in graph embedding methods has focused on learning a single representation for each node in the graph. But can nodes really be best described by a single vector representation? In this work, we propose a method for learning multiple representations of the nodes in a graph (e.g., the users of a social network). Based on a principled decomposition of the ego-network, each representation encodes the role of the node in a different local community in which the nodes participate. These representations allow for improved reconstruction of the nuanced relationships that occur in the graph a phenomenon that we illustrate through state-of-the-art results on link prediction tasks on a variety of graphs, reducing the error by up to 90%. In addition, we show that these embeddings allow for effective visual analysis of the learned community structure.


16. Self clustering graph embeddings

17. Walklets, similar to deep walk with node skips. - lots of improvements, works in scale due to lower size representations, improves results, etc.
Nodevectors
Git, The fastest network node embeddings in the west

- Fourier Transform - decomposing frequencies
- WAVELETS On youtube (4 videos):
- used for denoising, compression, detect edges, detect features with various orientation, analyse signal power, detect and localize transients, change points in time series data and detect optimal signal representation (peaks etc) of time freq analysis of images and data.
- Can also be used to reconstruct time and frequencies, analyse images in space, frequencies, orientation, identifying coherent time oscillation in time series
- Analyse signal variability and correlation
(did not read) A causal framework for explaining the predictions of black-box sequence-to-sequence models - can this be applied to other time series prediction?
- Siamese CNN, learns a similarity between images, not to classify
- Visual tracking, explains contrastive and triplet loss
- One shot learning, very thorough, baseline vs siamese
- What is triplet loss
PRUNING / KNOWLEDGE DISTILLATION / LOTTERY TICKET
- Awesome Knowledge distillation
- Lottery ticket
- Knowledge distillation 1, 2, 3
- Pruning 1, 2
- Teacher-student knowledge distillation focusing on Knowledge & Ranking distillation
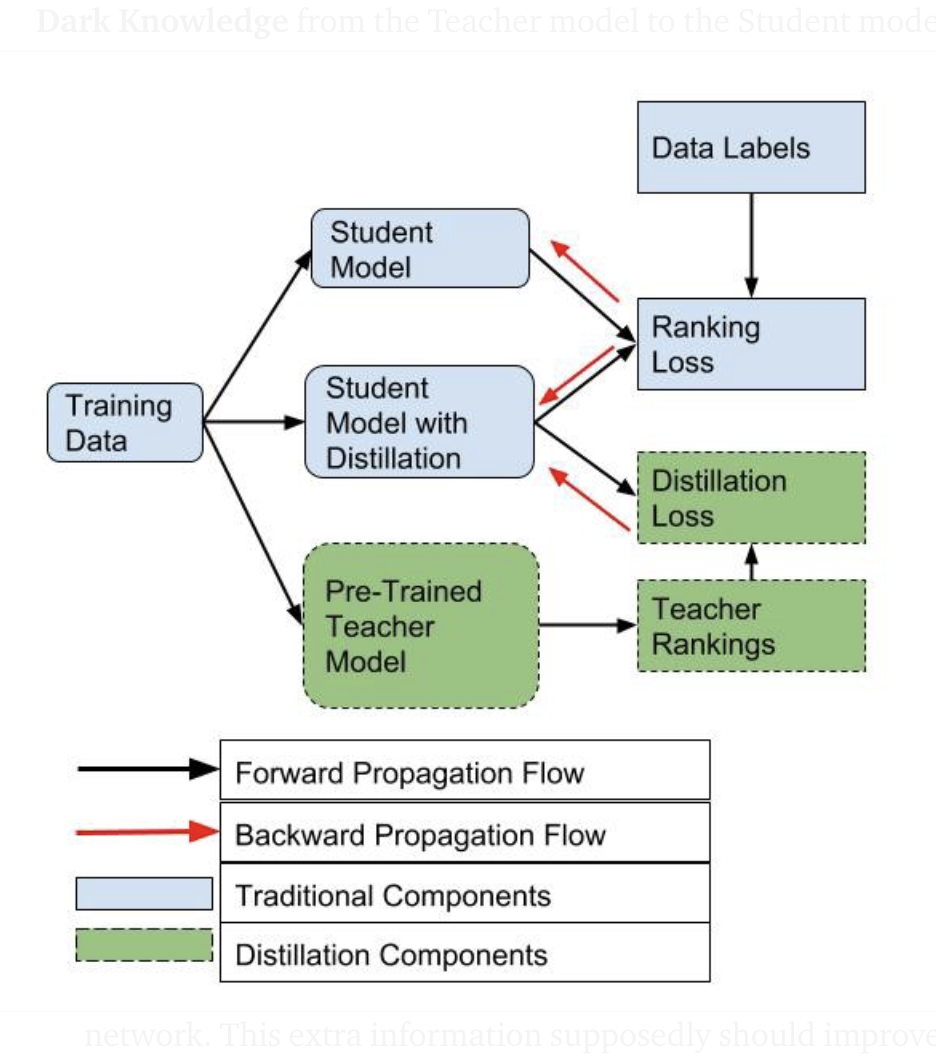
- Deep network compression using teacher student
- Lottery ticket on BERT, magnitude vs structured pruning on a various metrics, i.e., LT works on bert. The classical Lottery Ticket Hypothesis was mostly tested with unstructured pruning, specifically magnitude pruning (m-pruning) where the weights with the lowest magnitude are pruned irrespective of their position in the model. We iteratively prune 10% of the least magnitude weights across the entire fine-tuned model (except the embeddings) and evaluate on dev set, for as long as the performance of the pruned subnetwork is above 90% of the full model.
We also experiment with structured pruning (s-pruning) of entire components of BERT architecture based on their importance scores: specifically, we 'remove' the least important self-attention heads and MLPs by applying a mask. In each iteration, we prune 10% of BERT heads and 1 MLP, for as long as the performance of the pruned subnetwork is above 90% of the full model. To determine which heads/MLPs to prune, we use a loss-based approximation: the importance scores proposed by Michel, Levy and Neubig (2019) for self-attention heads, which we extend to MLPs. Please see our paper and the original formulation for more details.
(37 reasons, 10 more) - copy pasted and rewritten here for convenience, it's pretty thorough, but long and extensive, you should have some sort of intuition and not go through all of these. The following list is has much more insight and information in the article itself.
The author of the original article suggests to turn everything off and then start building your network step by step, i.e., “a divide and conquer ‘debug’ method”.
Dataset Issues
1. Check your input data - for stupid mistakes
2. Try random input - if the error behaves the same on random data, there is a problem in the net. Debug layer by layer
3. Check the data loader - input data is possibly broken. Check the input layer.
4. Make sure input is connected to output - do samples have correct labels, even after shuffling?
5. Is the relationship between input and output too random? - the input are not sufficiently related to the output. Its pretty amorphic, just look at the data.
6. Is there too much noise in the dataset? - badly labelled datasets.
7. Shuffle the dataset - useful to counteract order in the DS, always shuffle input and labels together.
8. Reduce class imbalance - imbalance datasets may add a bias to class prediction. Balance your class, your loss, do something.
9. Do you have enough training examples? - training from scratch? ~1000 images per class, ~probably similar numbers for other types of samples.
10. Make sure your batches don’t contain a single label - this is probably something you wont notice and will waste a lot of time figuring out! In certain cases shuffle the DS to prevent batches from having the same label.
11. Reduce batch size - This paper points out that having a very large batch can reduce the generalization ability of the model. However, please note that I found other references that claim a too small batch will impact performance.
12. Test on well known Datasets
Data Normalization/Augmentation
12. Standardize the features - zero mean and unit variance, sounds like normalization.
13. Do you have too much data augmentation?
Augmentation has a regularizing effect. Too much of this combined with other forms of regularization (weight L2, dropout, etc.) can cause the net to underfit.
14. Check the preprocessing of your pretrained model - with a pretrained model make sure your input data is similar in range[0, 1], [-1, 1] or [0, 255]?
15. Check the preprocessing for train/validation/test set - CS231n points out a common pitfall:
Any preprocessing should be computed ONLY on the training data, then applied to val/test
Implementation issues
16. Try solving a simpler version of the problem -divide and conquer prediction, i.e., class and box coordinates, just use one.
17. Look for correct loss “at chance” - calculat loss for chance level, i.e 10% baseline is -ln(0.1) = 2.3 Softmax loss is the negative log probability. Afterwards increase regularization strength which should increase the loss.
18. Check your custom loss function.
19. Verify loss input - parameter confusion.
20. Adjust loss weights -If your loss is composed of several smaller loss functions, make sure their magnitude relative to each is correct. This might involve testing different combinations of loss weights.
21. Monitor other metrics -like accuracy.
22. Test any custom layers, debugging them.
23. Check for “frozen” layers or variables - accidentally frozen?
24. Increase network size - more layers, more neurons.
25. Check for hidden dimension errors - confusion due to vectors ->(64, 64, 64)
26. Explore Gradient checking -does your backprop work for custon gradients? 1 ****2 ****3.
Training issues
27. Solve for a really small dataset - can you generalize on 2 samples?
28. Check weights initialization - Xavier or He or forget about it for networks such as RNN.
29. Change your hyperparameters - grid search
30. Reduce regularization - too much may underfit, try for dropout, batch norm, weight, bias , L2.
31. Give it more training time as long as the loss is decreasing.
32. Switch from Train to Test mode - not clear.
33. Visualize the training - activations, weights, layer updates, biases. Tensorboard and Crayon. Tips on Deeplearning4j. Expect gaussian distribution for weights, biases start at 0 and end up almost gaussian. Keep an eye out for parameters that are diverging to +/- infinity. Keep an eye out for biases that become very large. This can sometimes occur in the output layer for classification if the distribution of classes is very imbalanced.
34. Try a different optimizer, Check this excellent post about gradient descent optimizers.
35. Exploding / Vanishing gradients - Gradient clipping may help. Tips on: Deeplearning4j: “A good standard deviation for the activations is on the order of 0.5 to 2.0. Significantly outside of this range may indicate vanishing or exploding activations.”
36. Increase/Decrease Learning Rate, or use adaptive learning
37. Overcoming NaNs, big issue for RNN - decrease LR, how to deal with NaNs. evaluate layer by layer, why does it appear.
(amazing) embeddings from the ground up singlelunch
- Faiss - a library for efficient similarity search
- Benchmarking - complete with almost everything imaginable
- Singlestore
- Elastic search - dense vector
- Google cloud vertex matching engine NN search
- search
- Recommendation engines
- Search engines
- Ad targeting systems
- Image classification or image search
- Text classification
- Question answering
- Chat bots
- Features
- Low latency
- High recall
- managed
- Filtering
- scale
- search
- Pinecone - managed vector similarity search - Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
- Nmslib (benchmarked - Benchmarks of approximate nearest neighbor libraries in Python) is a Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
- scann,
- Vespa.ai - Make AI-driven decisions using your data, in real time. At any scale, with unbeatable performance
FLAIR
- Name-Entity Recognition (NER): It can recognise whether a word represents a person, location or names in the text.
- Parts-of-Speech Tagging (PoS): Tags all the words in the given text as to which “part of speech” they belong to.
- Text Classification: Classifying text based on the criteria (labels)
- Training Custom Models: Making our own custom models.
- It comprises of popular and state-of-the-art word embeddings, such as GloVe, BERT, ELMo, Character Embeddings, etc. There are very easy to use thanks to the Flair API
- Flair’s interface allows us to combine different word embeddings and use them to embed documents. This in turn leads to a significant uptick in results
- ‘Flair Embedding’ is the signature embedding provided within the Flair library. It is powered by contextual string embeddings. We’ll understand this concept in detail in the next section
- Flair supports a number of languages – and is always looking to add new ones
HUGGING FACE
- Git
- Hugging face nlp pretrained
- hugging face on emotions
- how to make a custom pyTorch LSTM with custom activation functions,
- how the PackedSequence object works and is built,
- how to convert an attention layer from Keras to pyTorch,
- how to load your data in pyTorch: DataSets and smart Batching,
- how to reproduce Keras weights initialization in pyTorch.
- A thorough tutorial on bert, fine tuning using hugging face transformers package. Code

- History:
- Google’s intro to transformers and multi-head self attention
- How self attention and relative positioning work (great!)
- Rnns are sequential, same word in diff position will have diff encoding due to the input from the previous word, which is inherently different.
- Attention without positional! Will have distinct (Same) encoding.
- Relative look at a window around each word and adds a distance vector in terms of how many words are before and after, which fixes the problem.
- The authors hypothesized that precise relative position information is not useful beyond a certain distance.
- Clipping the maximum distance enables the model to generalize to sequence lengths not seen during training.
- From bert to albert
- All the latest buzz algos
- A Summary of them
- 8 pretrained language embeddings
- Hugging face pytorch transformers
- Hugging face nlp pretrained


Language modelling
- Ruder on language modelling as the next imagenet - Language modelling, the last approach mentioned, has been shown to capture many facets of language relevant for downstream tasks, such as long-term dependencies , hierarchical relations , and sentiment . Compared to related unsupervised tasks such as skip-thoughts and autoencoding, language modelling performs better on syntactic tasks even with less training data.
- A tutorial about w2v skipthought - with code!, specifically language modelling here is important - Our second method is training a language model to represent our sentences. A language model describes the probability of a text existing in a language. For example, the sentence “I like eating bananas” would be more probable than “I like eating convolutions.” We train a language model by slicing windows of n words and predicting what the next word will be in the text
- Unread - universal language model fine tuning for text-classification
- ELMO - medium
- Bert ****python git- We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks.
- Open.ai on language modelling - We’ve obtained state-of-the-art results on a suite of diverse language tasks with a scalable, task-agnostic system, which we’re also releasing. Our approach is a combination of two existing ideas: transformers and unsupervised pre-training. READ PAPER, VIEW CODE.
- Scikit-learn inspired model finetuning for natural language processing.

finetune ships with a pre-trained language model from “Improving Language Understanding by Generative Pre-Training” and builds off the OpenAI/finetune-language-model repository.
- Did not read - The annotated Transformer - jupyter on transformer with annotation
- Medium on Dissecting Bert, appendix
- Medium on distilling 6 patterns from bert
Embedding spaces
- A good overview of sentence embedding methods - w2v ft s2v skip, d2v
- A very good overview of word embeddings
- Intro to word embeddings - lots of images
- A very long and extensive thesis about embeddings
- Sent2vec by gensim - sentence embedding is defined as the average of the source word embeddings of its constituent words. This model is furthermore augmented by also learning source embeddings for not only unigrams but also n-grams of words present in each sentence, and averaging the n-gram embeddings along with the words
- Sent2vec vs fasttext - with info about s2v parameters
- Wordrank vs fasttext vs w2v comparison - the better word similarity algorithm
- W2v vs glove vs sppmi vs svd by gensim
- Medium on a gentle intro to d2v
- Doc2vec tutorial by gensim - Doc2vec (aka paragraph2vec, aka sentence embeddings) modifies the word2vec algorithm to unsupervised learning of continuous representations for larger blocks of text, such as sentences, paragraphs or entire documents. - Most importantly this tutorial has crucial information about the implementation parameters that should be read before using it.
- Git for word embeddings - taken from mastery’s nlp course
- Skip-thought - ****git- Where word2vec attempts to predict surrounding words from certain words in a sentence, skip-thought vector extends this idea to sentences: it predicts surrounding sentences from a given sentence. NOTE: Unlike the other methods, skip-thought vectors require the sentences to be ordered in a semantically meaningful way. This makes this method difficult to use for domains such as social media text, where each snippet of text exists in isolation.
- Fastsent - Skip-thought vectors are slow to train. FastSent attempts to remedy this inefficiency while expanding on the core idea of skip-thought: that predicting surrounding sentences is a powerful way to obtain distributed representations. Formally, FastSent represents sentences as the simple sum of its word embeddings, making training efficient. The word embeddings are learned so that the inner product between the sentence embedding and the word embeddings of surrounding sentences is maximized. NOTE: FastSent sacrifices word order for the sake of efficiency, which can be a large disadvantage depending on the use-case.
- Weighted sum of words - In this method, each word vector is weighted by the factor
where
is a hyperparameter and
is the (estimated) word frequency. This is similar to tf-idf weighting, where more frequent terms are weighted downNOTE: Word order and surrounding sentences are ignored as well, limiting the information that is encoded.
- Infersent by facebook - paper InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language inference data and generalizes well to many different tasks. ABSTRACT: we show how universal sentence representations trained using the supervised data of the Stanford Natural Language Inference datasets can consistently outperform unsupervised methods like SkipThought vectors on a wide range of transfer tasks. Much like how computer vision uses ImageNet to obtain features, which can then be transferred to other tasks, our work tends to indicate the suitability of natural language inference for transfer learning to other NLP tasks.
- Universal sentence encoder - google - notebook, git The Universal Sentence Encoder encodes text into high dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks. The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512 dimensional vector. We apply this model to the STS benchmark for semantic similarity, and the results can be seen in the example notebook made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.
- Multi language universal sentence encoder - no hebrew
- Pair2vec - paper - paper proposes new methods for learning and using embeddings of word pairs that implicitly represent background knowledge about such relationships. I.e., using p2v information with existing models to increase performance. Experiments show that our pair embeddings can complement individual word embeddings, and that they are perhaps capturing information that eludes the traditional interpretation of the Distributional Hypothesis
- Fast text python tutorial


- Part1: Label encoder/ ordinal, One hot, one hot with a rare bucket, hash
- Part2: cat2vec using w2v, and entity embeddings for categorical data

- Star - General purpose embedding paper with code somewhere
- Using embeddings on tabular data, specifically categorical - introduction, using fastai without limiting ourselves to pytorch - the material from this post is covered in much more detail starting around 1:59:45 in the Lesson 3 video and continuing in Lesson 4 of our free, online Practical Deep Learning for Coders course. To see example code of how this approach can be used in practice, check out our Lesson 3 jupyter notebook. Perhaps Saturday and Sunday have similar behavior, and maybe Friday behaves like an average of a weekend and a weekday. Similarly, for zip codes, there may be patterns for zip codes that are geographically near each other, and for zip codes that are of similar socio-economic status. The jupyter notebook doesn't seem to have the embedding example they are talking about.
- Rossman on kaggle, used entity-embeddings, here, github, paper
- Medium on rossman - good
- Embedder - git code for a simplified entity embedding above.
- Finally what they do is label encode each feature using labelEncoder into an int-based feature, then push each feature into its own embedding layer of size 1 with an embedding size defined by a rule of thumb (so it seems), merge all layers, train a synthetic regression/classification and grab the weights of the corresponding embedding layer.
- Entity2vec
- Categorical using keras
- ALL ???-2-VEC ideas
- Fast.ai post regarding embedding for tabular data, i.e., cont and categorical data
- Entity embedding for categorical data + notebook
- Kaggle taxi competition + code
- Ross man competition - entity embeddings, code missing +alternative code
- CODE TO CREATE EMBEDDINGS straight away, based onthe ideas by cheng guo in keras
- PIN2VEC - pinterest embeddings using the same idea
- Tweet2Vec - code in theano, paper.
- Clustering of tweet2vec, paper
- Paper: Character neural embeddings for tweet clustering
- Diff2vec - might be useful on social network graphs, paper, code
- emoji 2vec (below)
- Char2vec ****Git, similarity measure for words with types. ****
EMOJIS
- 1. Deepmoji,
- hugging face on emotions
- how to make a custom pyTorch LSTM with custom activation functions,
- how the PackedSequence object works and is built,
- how to convert an attention layer from Keras to pyTorch,
- how to load your data in pyTorch: DataSets and smart Batching,
- how to reproduce Keras weights initialization in pyTorch.
- Another great emoji paper, how to get vector representations from
- 3. What can we learn from emojis (deep moji)
- Learning millions of for emoji, sentiment, sarcasm, medium
- EMOJI2VEC - medium article with keras code, another paper on classifying tweets using emojis
- Group2vec git and medium, which is a multi input embedding network using a-f below. plus two other methods that involve groupby and applying entropy and join/countvec per class. Really interesting
- Initialize embedding layers for each categorical input;
- For each category, compute dot-products among other embedding representations. These are our ‘groups’ at the categorical level;
- Summarize each ‘group’ adopting an average pooling;
- Concatenate ‘group’ averages;
- Apply regularization techniques such as BatchNormalization or Dropout;
- Output probabilities.
- Medium on Introduction into word embeddings, sentence embeddings, trends in the field. The Indian guy, git notebook, his git,
- Baseline Averaged Sentence Embeddings
- Doc2Vec
- Neural-Net Language Models (Hands-on Demo!)
- Skip-Thought Vectors
- Quick-Thought Vectors
- InferSent
- Universal Sentence Encoder
- Shay palachy on word embedding covering everything from bow to word/doc/sent/phrase.
- Another intro, not as good as the one above
- Using sklearn vectorizer to create custom ones, i.e. a vectorizer that does preprocessing and tfidf and other things.
- TFIDF - n-gram based top weighted tfidf words
- Gensim bi-gram phraser/phrases analyser/converter
- Countvectorizer, stemmer, lemmatization code tutorial
- Current 2018 best universal word and sentence embeddings -> elmo
- 5-part series on word embeddings, part 2, 3, 4 - cross lingual review, 5-future trends
- Word embedding posts
- Facebook github for embedings called starspace
- Medium on Fast text / elmo etc
FastText
- Fasttext - using fast text and upsampling/oversapmling on twitter data
- A great youtube lecture 9m about ft, rarity, loss, class tree speedup ****
- A thorough tutorial about what is FT and how to use it, performance, pros and cons.
- Docs
- Medium: word embeddings with w2v and fast text in gensim , data cleaning and word similarity
- Gensim - fasttext docs, similarity, analogies
- Alternative to gensim - promises speed and out of the box support for many embeddings.
- Comparison of usage w2v fasttext
- Using gensim fast text - recommendation against using the fb version
- A comparison of w2v vs ft using gensim - “Word2Vec embeddings seem to be slightly better than fastText embeddings at the semantic tasks, while the fastText embeddings do significantly better on the syntactic analogies. Makes sense, since fastText embeddings are trained for understanding morphological nuances, and most of the syntactic analogies are morphology based.
- Syntactic means syntax, as in tasks that have to do with the structure of the sentence, these include tree parsing, POS tagging, usually they need less context and a shallower understanding of world knowledge
- Semantic tasks mean meaning related, a higher level of the language tree, these also typically involve a higher level understanding of the text and might involve tasks s.a. question answering, sentiment analysis, etc...
- As for analogies, he is referring to the mathematical operator like properties exhibited by word embedding, in this context a syntactic analogy would be related to plurals, tense or gender, those sort of things, and semantic analogy would be word meaning relationships s.a. man + queen = king, etc... See for instance this article (and many others)
- Skip gram vs CBOW

- Paper on fasttext vs glove vs w2v on a single DS, performance comparison. Ft wins by a small margin
- Medium on w2v/fast text ‘most similar’ words with code
- keras/tf code for a fast text implementation
- Medium on fast text and imbalance data
- Medium on universal Sentence encoder, w2v, Fast text for sentiment with code.
WORD2VEC
- Monitor train loss using callbacks for word2vec
- Cleaning datasets using weighted w2v sentence encoding, then pca and isolation forest to remove outlier sentences.
- Removing ‘gender bias using pair mean pca
- KPCA w2v approach on a very small dataset, similar git for correspondence analysis, paper
- The best w2v/tfidf/bow/ embeddings post ever
- Chris mccormick ml on w2v, ****post #2 - negative sampling “Negative sampling addresses this by having each training sample only modify a small percentage of the weights, rather than all of them. With negative sampling, we are instead going to randomly select just a small number of “negative” words (let’s say 5) to update the weights for. (In this context, a “negative” word is one for which we want the network to output a 0 for). We will also still update the weights for our “positive” word (which is the word “quick” in our current example). The “negative samples” (that is, the 5 output words that we’ll train to output 0) are chosen using a “unigram distribution”. Essentially, the probability for selecting a word as a negative sample is related to its frequency, with more frequent words being more likely to be selected as negative samples.
- Chris mccormick on negative sampling and hierarchical soft max training, i.e., huffman binary tree for the vocabulary, learning internal tree nodes ie.,, the path as the probability vector instead of having len(vocabulary) neurons.
- Great W2V tutorial
- Another gensim-based w2v tutorial, with starter code and some usage examples of similarity
- Clustering using gensim word2vec
- Yet another w2v medium explanation
- Mean w2v
- Sequential w2v embeddings.
- Negative sampling, why does it work in w2v - didnt read
- Semantic contract using w2v/ft - he chose a good food category and selected words that worked best in order to find similar words to good bad etc. lior magen
- Semantic contract, syn-antonym DS, using w2v, a paper that i havent read yet but looks promising
- Amazing w2v most similar tutorial, examples for vectors, misspellings, semantic contrast and relations that may or may not be captured in the network.
- Followup tutorial about genderfying words using ‘he’ ‘she’ similarity
- W2v Analogies using predefined anthologies of the form x:y::a:b, plus code, plus insights of why it works and doesn't. presence : absence :: happy : unhappy absence : presence :: happy : proud abundant : scarce :: happy : glad refuse : accept :: happy : satisfied accurate : inaccurate :: happy : disappointed admit : deny :: happy : delighted never : always :: happy : Said_Hirschbeck modern : ancient :: happy : ecstatic
- Nlpforhackers on bow, w2v embeddings with code on how to use
- Hebrew word embeddings with w2v, ron shemesh, on wiki/twitter
GLOVE
- W2v vs glove vs fasttext, in terms of overfitting and what is the idea behind
- W2v against glove performance comparison - glove wins in % and time.
- How glove and w2v work, but the following has a very good description - “GloVe takes a different approach. Instead of extracting the embeddings from a neural network that is designed to perform a surrogate task (predicting neighbouring words), the embeddings are optimized directly so that the dot product of two word vectors equals the log of the number of times the two words will occur near each other (within 5 words for example). For example if "dog" and "cat" occur near each other 10 times in a corpus, then vec(dog) dot vec(cat) = log(10). This forces the vectors to somehow encode the frequency distribution of which words occur near them.”
- Glove vs w2v, concise explanation
Sense2vec
- Blog, github: Using spacy or not, with w2v using POS/ENTITY TAGS to find similarities.based on reddit. “We follow Trask et al in adding part-of-speech tags and named entity labels to the tokens. Additionally, we merge named entities and base noun phrases into single tokens, so that they receive a single vector.”
- >>> model.similarity('fair_game|NOUN', 'game|NOUN') 0.034977455677555599 >>> model.similarity('multiplayer_game|NOUN', 'game|NOUN') 0.54464530644393849
SENT2VEC aka “skip-thoughts”
- Gensim implementation of sent2vec - usage examples, parallel training, a detailed comparison against gensim doc2vec
- Git implementation
- Another git - worked
USE - Universal sentence encoder
BERT+W2V
DOC2VEC
- Shuffle before training each epoch in d2v in order to fight overfitting
- Illustrated attention- AMAZING
- Illustrated self attention - great
- Jay alamar on attention, the first one is better.
- Attention is all you need (paper)
- The annotated transformer - reviewing the paper
- Lilian weng on attention, self, soft vs hard, global vs local, neural turing machines, pointer networks, transformers, snail, self attention GAN.
- Understanding attention in rnns
- Another good intro with gifs to attention
- Clear insight to what attention is, a must read!
- Transformer NN by google - faster, better, more accurate
- Intuitive explanation to attention
- Attention by vidhya
- Augmented rnns - including turing / attention / adaptive computation time etc. general overview, not as clear as the one below.


- A really good REVIEW on attention and its many forms, historical changes, etc
- Medium on comparing cnn / rnn / han - will change on other data, my impression is that the data is too good in this article
- Mastery on rnn vs attention vs global attention - a really unclear intro
- Mastery on attention - this makes the whole process clear, scoring encoder vs decoder input outputs, normalizing them using softmax (annotation weights), multiplying score and the weight summed on all (i.e., context vector), and then we decode the context vector.
- Soft (above) and hard crisp attention
- Dropping the hidden output - HAN or AB BiLSTM
- Attention concat to input vec
- Global vs local attention
- Mastery on attention with lstm encoding / decoding - a theoretical discussion about many attention architectures. This adds make-sense information to everything above.
- Encoder: The encoder is responsible for stepping through the input time steps and encoding the entire sequence into a fixed length vector called a context vector.
- Decoder: The decoder is responsible for stepping through the output time steps while reading from the context vector.
- A problem with the architecture is that performance is poor on long input or output sequences. The reason is believed to be because of the fixed-sized internal representation used by the encoder.
- Enc-decoder
- Recursive
- Enc-dev with recursive
- Code on GIT:
- HAN - GIT, paper
- Non penalized self attention
- LSTM, BiLSTM attention, paper
- Tushv89, Keras layer attention implementation
- Richliao, hierarchical Attention code for document classification using keras, blog, group chatter

note: word level then sentence level embeddings.
figure= >
- Self Attention pip for keras, git
- Phillip remy on attention in keras, not a single layer, a few of them to make it.
- Self attention with relative positiion representations
- nMT - jointly learning to align and translate ****
- Medium on attention plus code, comparison keras and pytorch
BERT/ROBERTA
- Do attention heads in bert roberta track syntactic dependencies? - tl;dr: The attention weights between tokens in BERT/RoBERTa bear similarity to some syntactic dependency relations, but the results are less conclusive than we’d like as they don’t significantly outperform linguistically uninformed baselines for all types of dependency relations. In the case of MAX, our results indicate that specific heads in the BERT models may correspond to certain dependency relations, whereas for MST, we find much less support “generalist” heads whose attention weights correspond to a full syntactic dependency structure.
In both cases, the metrics do not appear to be representative of the extent of linguistic knowledge learned by the BERT models, based on their strong performance on many NLP tasks. Hence, our takeaway is that while we can tease out some structure from the attention weights of BERT models using the above methods, studying the attention weights alone is unlikely to give us the full picture of BERT’s strength processing natural language.
- Jay alammar on transformers (amazing)
- J.A on Bert Elmo (amazing)
- Jay alammar on a visual guide of bert for the first time
- J.A on GPT2
- Super fast transformers
- A survey of long term context in transformers.
- Lilian Wang on the transformer family (seems like it is constantly updated)
- Hugging face, encoders decoders in transformers for seq2seq
- The annotated transformer
- Large memory layers with product keys - This memory layer allows us to tackle very large scale language modeling tasks. In our experiments we consider a dataset with up to 30 billion words, and we plug our memory layer in a state-of-the-art transformer-based architecture. In particular, we found that a memory augmented model with only 12 layers outperforms a baseline transformer model with 24 layers, while being twice faster at inference time.
- Adaptive sparse transformers - This sparsity is accomplished by replacing softmax with


α-entmax: a differentiable generalization of softmax that allows low-scoring words to receive precisely zero weight. Moreover, we derive a method to automatically learn the
α parameter -- which controls the shape and sparsity of
α-entmax -- allowing attention heads to choose between focused or spread-out behavior. Our adaptively sparse Transformer improves interpretability and head diversity when compared to softmax Transformers on machine translation datasets.
- Short tutorial on elmo, pretrained, new data, incremental(finetune?), using elmo pretrained
- Why you cant use elmo to encode words (contextualized)
- Vidhya on elmo - everything you want to know with code
- Sebastien ruder on language modeling embeddings for the purpose of transfer learning, ELMO, ULMFIT, open AI transformer, BILSTM,
- Another good tutorial on elmo.
- ELMO, tutorial, github
- Elmo on google hub and code
- How to use elmo embeddings, advice for word and sentence
- Using elmo as a lambda embedding layer
- Elmbo tutorial notebook
- Elmo code on git
- Elmo on keras using lambda
- Elmo pretrained models for many languages, for russian too, mean elmo
- Ari’s intro on word embeddings part 2, has elmo and some bert
- Mean elmo, batches, with code and linear regression i
- Elmo projected using TSNE - grouping are not semantically similar
- Tutorial and code by vidhya, medium
- Paper
- Ruder on transfer learning
- Medium on how - unclear
- Fast NLP on how
- Paper: ulmfit
- Fast.ai on ulmfit, this too
- Vidhya on ulmfit using fastai
- Medium on ulmfit
- Building blocks of ulm fit
- Applying ulmfit on entity level sentiment analysis using business news artcles
- Understanding language modelling using Ulmfit, fine tuning etc
- Vidhaya on ulmfit + colab “The one cycle policy provides some form of regularisation”, if you wish to know more about one cycle policy, then feel free to refer to this excellent paper by Leslie Smith – “A disciplined approach to neural network hyper-parameters: Part 1 — learning rate, batch size, momentum, and weight decay”.
- The BERT PAPER
- Prerequisite about transformers and attention - this is not enough
- Embeddings using bert in python - using bert as a service to encode 1024 vectors and do cosine similarity
- Identifying the right meaning with bert - the idea is to classify the word duck into one of three meanings using bert embeddings, which promise contextualized embeddings. I.e., to duck, the Duck, etc
- Google neural machine translation (attention) - too long
- What is bert
- (amazing) Deconstructing bert
- I found some fairly distinctive and surprisingly intuitive attention patterns. Below I identify six key patterns and for each one I show visualizations for a particular layer / head that exhibited the pattern.
- part 1 - attention to the next/previous/ identical/related (same and other sentences), other words predictive of a word, delimeters tokens
- (good) Deconstructing bert part 2 - looking at the visualization and attention heads, focusing on Delimiter attention, bag of words attention, next word attention - patterns.
- Bert demystified (read this first!)
- Read this after, the most coherent explanation on bert, 15% masked word prediction and next sentence prediction. Roberta, xlm bert, albert, distilibert.
- A thorough tutorial on bert, fine tuning using hugging face transformers package. Code

- How to train bert from scratch using TF, with [CLS] [SEP] etc
- Extending a vocabulary for bert, another kind of transfer learning.
- Bert tutorial, on fine tuning, some talk on from scratch and probably not discussed about using embeddings as input
- Bert for summarization thread
- Bert on logs, feature names as labels, finetune bert, predict.
- Bert scikit wrapper for pipelines
- What is bert not good at, also refer to the cited paper (is/is not)
- Jay Alamar on Bert
- Jay Alamar on using distilliBert
- sparse bert, paper - When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters.
- Bert with keras, blog post, colaboratory
- Bert with t-hub
- Bert on medium with code
- Bert on git
- Finetuning - Better sentiment analysis with bert, claims 94% on IMDB. official code here “ it creates a single new layer that will be trained to adapt BERT to our sentiment task (i.e. classifying whether a movie review is positive or negative). This strategy of using a mostly trained model is called fine-tuning.”
- Explain bert - bert visualization tool.
- sentenceBERT paper
- Bert question answering on covid19
- Codebert
- Bert multilabel classification
- Tabert - TaBERT is the first model that has been pretrained to learn representations for both natural language sentences and tabular data.
- All the ways that you can compress BERT
Pruning - Removes unnecessary parts of the network after training. This includes weight magnitude pruning, attention head pruning, layers, and others. Some methods also impose regularization during training to increase prunability (layer dropout).
Weight Factorization - Approximates parameter matrices by factorizing them into a multiplication of two smaller matrices. This imposes a low-rank constraint on the matrix. Weight factorization can be applied to both token embeddings (which saves a lot of memory on disk) or parameters in feed-forward / self-attention layers (for some speed improvements).
Knowledge Distillation - Aka “Student Teacher.” Trains a much smaller Transformer from scratch on the pre-training / downstream-data. Normally this would fail, but utilizing soft labels from a fully-sized model improves optimization for unknown reasons. Some methods also distill BERT into different architectures (LSTMS, etc.) which have faster inference times. Others dig deeper into the teacher, looking not just at the output but at weight matrices and hidden activations.
Weight Sharing - Some weights in the model share the same value as other parameters in the model. For example, ALBERT uses the same weight matrices for every single layer of self-attention in BERT.
Quantization - Truncates floating point numbers to only use a few bits (which causes round-off error). The quantization values can also be learned either during or after training.
Pre-train vs. Downstream - Some methods only compress BERT w.r.t. certain downstream tasks. Others compress BERT in a way that is task-agnostic.
- Bert and nlp in 2019
- HeBert - bert for hebrwe sentiment and emotions
- Kdbuggets on visualizing bert
- What does bert look at, analysis of attention - We further show that certain attention heads correspond well to linguistic notions of syntax and coreference. For example, we find heads that attend to the direct objects of verbs, determiners of nouns, objects of prepositions, and coreferent mentions with remarkably high accuracy. Lastly, we propose an attention-based probing classifier and use it to further demonstrate that substantial syntactic information is captured in BERT’s attention
- Bertviz BertViz is a tool for visualizing attention in the Transformer model, supporting all models from the transformers library (BERT, GPT-2, XLNet, RoBERTa, XLM, CTRL, etc.). It extends the Tensor2Tensor visualization tool by Llion Jones and the transformers library from HuggingFace.
- PMI-masking paper, post - Joint masking of correlated tokens significantly speeds up and improves BERT's pretraining
- (really good/) Examining bert raw embeddings - TL;DR BERT’s raw word embeddings capture useful and separable information (distinct histogram tails) about a word in terms of other words in BERT’s vocabulary. This information can be harvested from both raw embeddings and their transformed versions after they pass through BERT with a Masked language model (MLM) head




- the GPT-2 small algorithm was trained on the task of language modeling — which tests a program’s ability to predict the next word in a given sentence — by ingesting huge numbers of articles, blogs, and websites. By using just this data it achieved state-of-the-art scores on a number of unseen language tests, an achievement known as zero-shot learning. It can also perform other writing-related tasks, such as translating text from one language to another, summarizing long articles, and answering trivia questions.
- Medium code for GPT=2 - big algo
- GPT3 on medium - language models can be used to produce good results on zero-shot, one-shot, or few-shot learning.
- Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
- Xlnet is transformer and bert combined - Actually its quite good explaining it
- git
- (keras) Implementation of a dual encoder model for retrieving images that match natural language queries. - The example demonstrates how to build a dual encoder (also known as two-tower) neural network model to search for images using natural language. The model is inspired by the CLIP approach, introduced by Alec Radford et al. The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their captions into the same embedding space, such that the caption embeddings are located near the embeddings of the images they describe.
-
- What is label flipping and smoothing and usage for making a model more robust against adversarial methodologies - 0
Label flipping is a training technique where one selectively manipulates the labels in order to make the model more robust against label noise and associated attacks - the specifics depend a lot on the nature of the noise. Label flipping bears no benefit only under the assumption that all labels are (and will always be) correct and that no adversaries exist. In cases where noise tolerance is desirable, training with label flipping is beneficial.
Label smoothing is a regularization technique (and then some) aimed at improving model performance. Its effect takes place irrespective of label correctness.
- Paper: when does label smoothing helps? Smoothing the labels in this way prevents the network from becoming overconfident and label smoothing has been used in many state-of-the-art models, including image classification, language translation and speech recognition...Here we show empirically that in addition to improving generalization, label smoothing improves model calibration which can significantly improve beam-search. However, we also observe that if a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective.
- Label smoothing, python code, multi class examples

- Label sanitazation against label flipping poisoning attacks - In this paper we propose an efficient algorithm to perform optimal label flipping poisoning attacks and a mechanism to detect and relabel suspicious data points, mitigating the effect of such poisoning attacks.
- Adversarial label flips attacks on svm - To develop a robust classification algorithm in the adversarial setting, it is important to understand the adversary’s strategy. We address the problem of label flips attack where an adversary contaminates the training set through flipping labels. By analyzing the objective of the adversary, we formulate an optimization framework for finding the label flips that maximize the classification error. An algorithm for attacking support vector machines is derived. Experiments demonstrate that the accuracy of classifiers is significantly degraded under the attack.
- Great advice for training gans, such as label flipping batch norm, etc read!
- Intro to Gans
- A fantastic series about gans, the following two what are gans and applications are there
- What are a GANs?, and cool applications
- Comprehensive overview
- Cycle gan - transferring styles
- Super gan resolution - super res images
- Why gan so hard to train - good for critique
- And how to improve gans performance
- Dcgan good as a starting point in new projects
- Labels to improve gans, cgan, infogan
- Stacked - labels, gan adversarial loss, entropy loss, conditional loss - divide and conquer
- Progressive gans - mini batch discrimination
- Using attention to improve gan
- Least square gan - lsgan
- Unread:
- Wasserstein gan, wgan gp
- Faster training for gans, lower training count rsgan ragan
- Addressing gan stability, ebgan began
- What is wrong with gan cost functions
- Using cost functions for gans inspite of the google brain paper
- Proving gan is js-convergence
- Dragan on minimizing local equilibria, how to stabilize gans, reducing mode collapse
- Unrolled gan for reducing mode collapse
- Measuring gans
- Ways to improve gans performance
- Introduction to gans with tf code
- Intro to gans
- Intro to gan in KERAS
- “GAN” using xgboost and gmm for density sampling
- Reverse engineering
- Siamese for conveyor belt fault prediction
- Burlow, fb post - Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant solutions. Most current methods avoid such solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors.