| Python | Linux CPU |
Linux GPU |
|---|---|---|
| 2.7.8 |  |
|
| 2.7 | |
|
| 3.3 | |
|
| 3.4 | |
|
| 3.5 | |
|
| Nightly | |
The project is still under active development and is likely to drastically change in short periods of time. We will be announcing API changes and important developments via a newsletter, github issues and post a link to the issues on slack. Please remember that at this stage, this is an invite-only closed alpha, and please don't distribute code further. This is done so that we can control development tightly and rapidly during the initial phases with feedback from you.
- Anaconda
conda install pytorch -c https://conda.anaconda.org/t/6N-MsQ4WZ7jo/soumithpip install -r requirements.txt
pip install .A more comprehensive Getting Started section will be filled in soon. For now, there's two pointers:
- The MNIST example: https://github.com/pytorch/examples
- The API Reference: http://pytorch.org/api/
- github issues: bug reports, feature requests, install issues, RFCs, thoughts, etc.
- slack: general chat, online discussions, collaboration etc. https://pytorch.slack.com/ . If you need a slack invite, ping me at [email protected]
- newsletter: no-noise, one-way email newsletter with important announcements about pytorch. You can sign-up here: http://eepurl.com/cbG0rv
We will run the alpha releases weekly for 6 weeks. After that, we will reevaluate progress, and if we are ready, we will hit beta-0. If not, we will do another two weeks of alpha.
alpha-0: Working versions of torch, cutorch, nn, cunn, optim fully unit tested with seamless numpy conversionsalpha-1: Serialization to/from disk with sharing intact. initial release of the new neuralnets package based on a Chainer-like designalpha-2: sharing tensors across processes for hogwild training or data-loading processes. a rewritten optim package for this new nn.- ~~alpha-3: binary installs, contbuilds, etc.
- alpha-4: a ton of examples across vision, nlp, speech, RL -- this phase might make us rethink parts of the APIs, and hence want to do this in alpha than beta
- alpha-5: Putting a simple and efficient story around multi-machine training. Probably simplistic like torch-distlearn. Building the website, release scripts, more documentation, etc.
- alpha-6: [no plan yet]
The beta phases will be leaning more towards working with all of you, convering your use-cases, active development on non-core aspects.
We've decided that it's time to rewrite/update parts of the old torch API, even if it means losing some of backward compatibility (we can hack up a model converter that converts correctly). This section lists the biggest changes, and suggests how to shift from torch to pytorch.
For now there's no pytorch documentation. Since all currently implemented modules are very similar to the old ones, it's best to use torch7 docs for now (having in mind several differences described below).
All core modules are merged into a single repository. Most of them will be rewritten and will be completely new (more on this below), but we're providing a Python version of old packages under torch.legacy namespace.
- torch (torch)
- cutorch (torch.cuda)
- nn (torch.legacy.nn)
- cunn (torch.legacy.cunn)
- optim (torch.legacy.optim)
- nngraph (torch.legacy.nngraph - not implemented yet)
pytorch uses 0-based indexing everywhere.
This includes arguments to index* functions and nn criterion weights.
Under the hood, on the C side, we've changed logic on TH / THC / THNN / THCUNN to introduce a TH_INDEX_BASE compile-time definition to switch between 0 and 1 indexing logic.
All methods operating on tensors are now out-of-place by default.
This means that although a.add(b) used to have a side-effect of mutating the elements in a, it will now return a new Tensor, holding the result.
All methods that mutate the Tensor/Storage are now marked with a trailing underscore (including copy -> copy_, fill -> fill_, set -> set_, etc.).
Most of math methods have their in-place counterparts, so an equivalent to a.add(b) in Lua is now a.add_(b) (or torch.add(a, a, b), which is not recommended in this case)
All tensors have their CUDA counterparts in torch.cuda module.
There is no torch.cuda.setDevice anymore. By default always the 0th device is selected, but code can be placed in a with statement to change it:
with torch.cuda.device(1):
a = torch.cuda.FloatTensor(10) # a is allocated on GPU1Calling .cuda() on tensors no longer converts it to a GPU float tensor, but to a CUDA tensor of the same type located on a currently selected device.
So, for example: a = torch.LongTensor(10).cuda() # a is a CudaLongTensor
Calling .cuda(3) will send it to the third device.
.cuda() can be also used to transfer CUDA tensors between devices (calling it on a GPU tensor, with a different device selected will copy it into the current device).
a = torch.LongTensor(10)
b = a.cuda() # b is a torch.cuda.LongTensor placed on GPU0
c = a.cuda(2) # c is a torch.cuda.LongTensor placed on GPU2
with torch.cuda.device(1):
d = b.cuda() # d is a copy of b, but on GPU1
e = d.cuda() # a no-op, d is already on current GPU, e is d == TrueAlso, setting device is now only important to specify where to allocate new Tensors. You can perform operations on CUDA Tensors irrespective of currently selected device (but all arguments have to be on the same device) - result will be also allocated there. See below for an example:
a = torch.randn(2, 2).cuda()
b = torch.randn(2, 2).cuda()
with torch.cuda.device(1):
c = a + b # c is on GPU0
d = torch.randn(2, 2).cuda() # d is on GPU1In the near future, we also plan to use a CUDA allocator, which allows to alleviate problems with cudaMalloc/cudaFree being a sync point. This will help us to not worry about using buffers for every intermediate computation in a module if one wants to do multi-GPU training, for example. See: torch/cutorch#443
Because numpy is a core numerical package in Python, and is used by many other libraries like matplotlib, we've implemented a two-way bridge between pytorch and numpy.
a = torch.randn(2, 2)
b = a.numpy() # b is a numpy array of type corresponding to a
# no memory copy is performed, they share the same storage
c = numpy.zeros(5, 5)
d = torch.DoubleTensor(c) # it's possible to construct Tensors from numpy arrays
# d shares memory with b - there's no copyAfter looking at several framework designs, looking at the current design of nn and thinking through a few original design ideas, this is what we've converged to:
- Adopt a Chainer-like design
- Makes it extremely natural to express Recurrent Nets and weight sharing
- Each module can operate in-place, but marks used variables as dirty - errors will be raised if they're used again
- RNN example:
class Network(nn.Container):
def __init__(self):
super(Network, self).__init__(
conv1=nn.SpatialConvolution(3, 16, 3, 3, 1, 1),
relu1=nn.ReLU(True),
lstm=nn.LSTM(),
)
def __call__(self, input):
y = self.conv(input)
y = self.relu1(y)
y = self.lstm(y)
return y
model = Network()
input = nn.Variable(torch.zeros(256, 3, 224, 224))
output = model(input)
loss = 0
for i in range(ITERS):
input, target = ...
# That's all you need for an RNN
for t in range(TIMESTEPS):
loss += loss_fn(model(input), target)
loss.backward()- Here, nn.Variable will have a complete tape-based automatic differentiation implemented
- To access states, have hooks for forward / backward (this also makes multi-GPU easier to implement)
- This has the advantage of not having to worry about in-place / out-of-place operators for accessing .output or .gradInput
- When writing the module, make sure debuggability is straight forward. Dropping into pdb and inspecting things should be natural, especially when going over the backward graph.
- Pulling handles to a module after constructing a chain should be very natural (apart from having a handle at construction)
- It's easy, since modules are assigned as Container properties
- Drop overly verbose names. Example:
- SpatialConvolution → conv2d
- VolumetricConvolution → conv3d
As shown above, structure of the networks is fully defined by control-flow embedded in the code. There are no rigid containers known from Lua. You can put an if in the middle of your model and freely branch depending on any condition you can come up with. All operations are registered in the computational graph history.
There are two main objects that make this possible - variables and functions. They will be denoted as squares and circles respectively.

Variables are the objects that hold a reference to a tensor (and optionally to gradient w.r.t. that tensor), and to the function in the computational graph that created it. Variables created explicitly by the user (Variable(tensor)) have a Leaf function node associated with them.
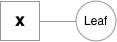
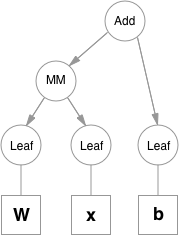
Functions are simple classes that define a function from a tuple of inputs to a tuple of outputs, and a formula for computing gradient w.r.t. it's inputs. Function objects are instantiated to hold references to other functions, and these references allow to reconstruct the history of a computation. An example graph for a linear layer (Wx + b) is shown below.
Please note that function objects never hold references to Variable objects, except for when they're necessary in the backward pass. This allows to free all the unnecessary intermediate values. A good example for this is addition when computing e.g. (y = Wx + My):
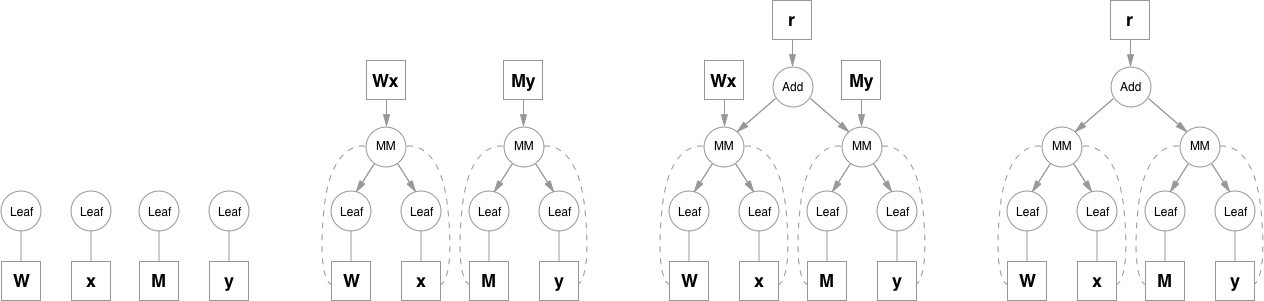
Matrix multiplication operation keeps references to it's inputs because it will need them, but addition doesn't need Wx and My after it computes the result, so as soon as they go out of scope they are freed. To access intermediate values in the forward pass you can either copy them when you still have a reference, or you can use a system of hooks that can be attached to any function. Hooks also allow to access and inspect gradients inside the graph.
Another nice thing about this is that a single layer doesn't hold any state other than it's parameters (all intermediate values are alive as long as the graph references them), so it can be used multiple times before calling backward. This is especially convenient when training RNNs. You can use the same network for all timesteps and the gradients will sum up automatically.
To compute backward pass you can call .backward() on a variable if it's a scalar (a 1-element Variable), or you can provide a gradient tensor of matching shape if it's not. This creates an execution engine object that manages the whole backward pass. It's been introduced, so that the code for analyzing the graph and scheduling node processing order is decoupled from other parts, and can be easily replaced. Right now it's simply processing the nodes in topological order, without any prioritization, but in the future we can implement algorithms and heuristics for scheduling independent nodes on different GPU streams, deciding which branches to compute first, etc.
Pickling tensors is supported, but requires making a temporary copy of all data and breaks sharing.
For this reason we're providing torch.load and torch.save, that are free of these problems.
They have the same interfaces as pickle.load (file object) and pickle.dump (serialized object, file object) respectively.
For now the only requirement is that the file should have a fileno method, which returns a file descriptor number (this is already implemented by objects returned by open).
Objects are serialized in a tar archive consisting of four files:
sys_info - protocol version, byte order, long size, etc.
pickle - pickled object
tensors - tensor metadata
storages - serialized data
Proposed solutions need to address:
- Kernel launch latency
- without affecting the user's code
- Implementation should be as transparent as possible
- Should we expose DPT as:
- Split
- ParallelApply (scheduling kernels in breadth first order, to address launch latency)
- Join
- Should we expose DPT as:
- In backward phase, send parameters as soon as the module finishes computation
Rough solution:
# This is an example of a network that has a data parallel part inside
#
# B is data parallel
# +->A+-->B+-+
# +--+ +->D
# +->C+------+
class Network(nn.Container):
__init__(self):
super(Network, self).__init__(
A = ...,
B = GPUReplicate(B, [0, 1, 2, 3]), # Copies the module onto a list of GPUs
C = ...,
D = ...
)
__call__(self, x):
a = self.A(x)
c = self.C(x)
a_split = Split(a) # a_split is a list of Tensors placed on different devices
b = ParallelApply(self.B, a_split) # self.B is a list-like object containing copies of B
d_input = Join(b + [c]) # gathers Tensors on a single GPU
return self.D(d_input)Each module is assigned to a single GPU.
For Kernel Launch Latency:
- Python threading
- Generators
For parameter reductions ASAP:
- In the forward pass, register a hooks on a every parameter which are evaluated as soon as the last backward is executed for that parameter. The hook will then “all-reduce” those parameters across GPUs
- Problem with multiple forward calls - how do you know that the parameters won't be used anymore?
- Well, last usage in backward graph = first usage in forward graph, so this should be straightforward
- Problem with multiple forward calls - how do you know that the parameters won't be used anymore?
In Torch, or in general, one uses "threads" to build parallel data loaders, as well as to do Hogwild training. Threads are powerful, as one can share Tensors between threads. This allows you to:
- transfer data between threads with efficiently with zero memory copy and serialization overhead.
- share tensors among threads for parameter sharing models
Sharing Tensors among threads is very useful when you do Hogwild training, i.e. if you want to train several models in parallel, but want to share their underlying parameters. This is often used in non ConvNets, like training word embeddings, RL-for-games, etc.
With Python, one cannot use threads because of a few technical issues. Python has what is called Global Interpreter Lock, which does not allow threads to concurrently execute python code.
Hence, the most pythonic way to use multiple CPU cores is multiprocessing
We made PyTorch to seamlessly integrate with python multiprocessing. This involved solving some complex technical problems to make this an air-tight solution, and more can be read in this in-depth technical discussion.
What this means for you as the end-user is that you can simply use multiprocessing in this way:
# loaders.py
# Functions from this file run in the workers
def fill(queue):
while True:
tensor = queue.get()
tensor.fill_(10)
queue.put(tensor)
def fill_pool(tensor):
tensor.fill_(10)# Example 1: Using multiple persistent processes and a Queue
# process.py
import torch
import torch.multiprocessing as multiprocessing
from loaders import fill
# torch.multiprocessing.Queue automatically moves Tensor data to shared memory
# So the main process and worker share the data
queue = multiprocessing.Queue()
buffers = [torch.Tensor(2, 2) for i in range(4)]
for b in buffers:
queue.put(b)
processes = [multiprocessing.Process(target=fill, args=(queue,)).start() for i in range(10)]# Example 2: Using a process pool
# pool.py
import torch
from torch.multiprocessing import Pool
from loaders import fill_pool
tensors = [torch.Tensor(2, 2) for i in range(100)]
pool = Pool(10)
pool.map(fill_pool, tensors)