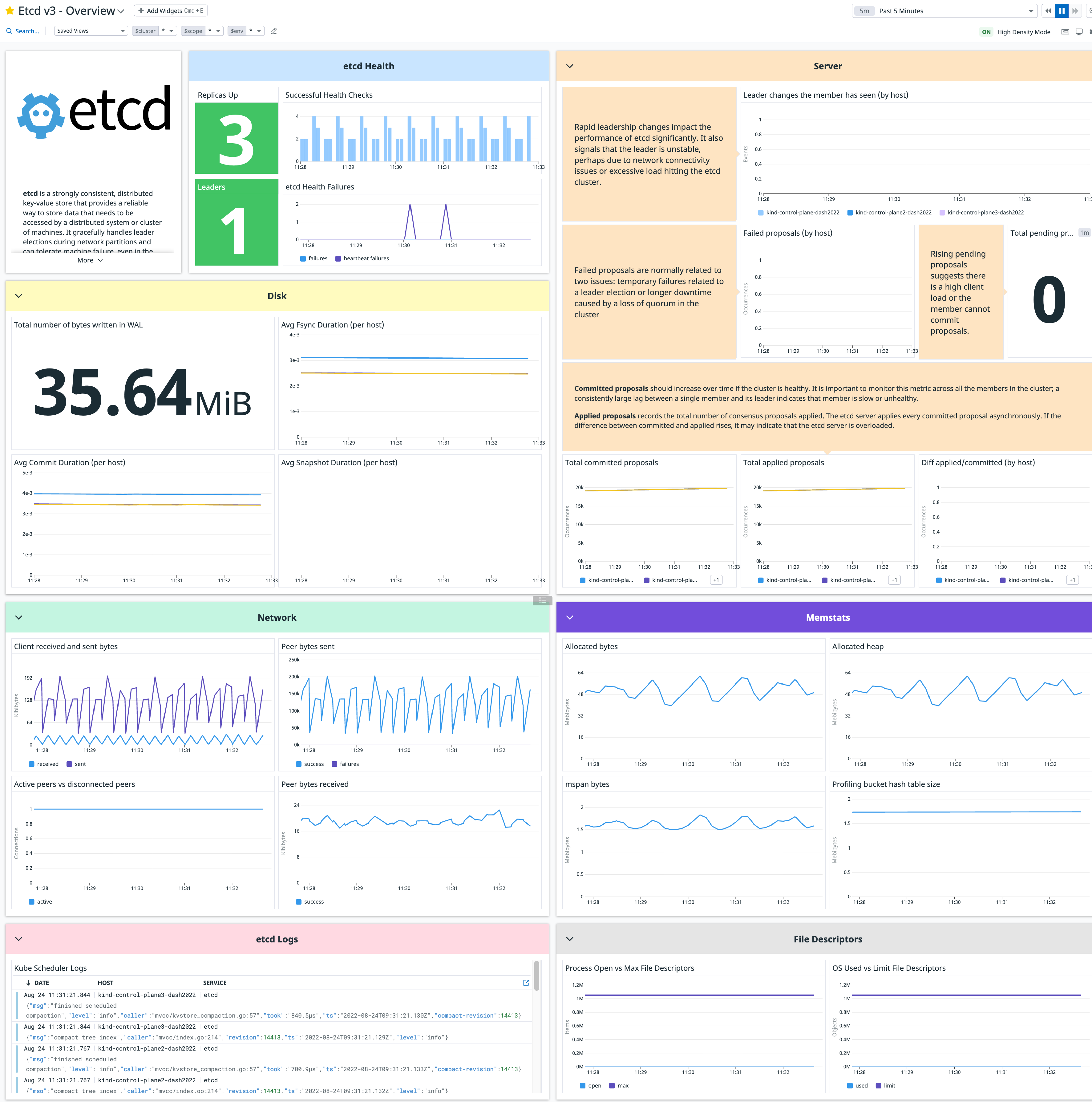
Collect Etcd metrics to:
- Monitor the health of your Etcd cluster.
- Know when host configurations may be out of sync.
- Correlate the performance of Etcd with the rest of your applications.
The Etcd check is included in the Datadog Agent package, so you don't need to install anything else on your Etcd instance(s).
Follow the instructions below to configure this check for an Agent running on a host. For containerized environments, see the Containerized section.
- Edit the
etcd.d/conf.yamlfile, in theconf.d/folder at the root of your Agent's configuration directory to start collecting your Etcd performance data. See the sample etcd.d/conf.yaml for all available configuration options. - Restart the Agent
For containerized environments, see the Autodiscovery Integration Templates for guidance on applying the parameters below.
| Parameter | Value |
|---|---|
<INTEGRATION_NAME> |
etcd |
<INIT_CONFIG> |
blank or {} |
<INSTANCE_CONFIG> |
{"prometheus_url": "http://%%host%%:2379/metrics"} |
Run the Agent's status subcommand and look for etcd under the Checks section.
See metadata.csv for a list of metrics provided by this integration.
Etcd metrics are tagged with etcd_state:leader or etcd_state:follower, depending on the node status, so you can easily aggregate metrics by status.
The Etcd check does not include any events.
etcd.can_connect:
Returns 'Critical' if the Agent cannot collect metrics from your Etcd API endpoint.
etcd.healthy:
Returns 'Critical' if a member node is not healthy. Returns 'Unknown' if the Agent can't reach the /health endpoint, or if the health status is missing.
Need help? Contact Datadog support.
To get a better idea of how (or why) to integrate Etcd with Datadog, check out our blog post about it.