While Levanter's main focus is pretraining, we can also use it for fine-tuning. As an example, we'll show how to reproduce Stanford Alpaca, using Levanter and either Llama 1 or Llama 2 7B. The script we develop will be designed for Alpaca, defaulting to using its dataset and prompts, but it should work for any single-turn instruction-following task.
This tutorial is meant to cover "full finetuning," where you start with a pretrained model and modify
all of its parameters to fit some final task, rather than something like LoRA that adds a (small) number
of additional parameters. (See our LoRA tutorial for that.)
It also documents how to work with datasets that aren't just single "text"s, which is what we use in pretraining.
Alpaca is a fine tune of Llama 1 on a dataset of 52000 input/output pairs, which
were generated by taking a seed set from self-instruct and asking
text-davinci-003 to generate more examples.
The original Alpaca script is here.
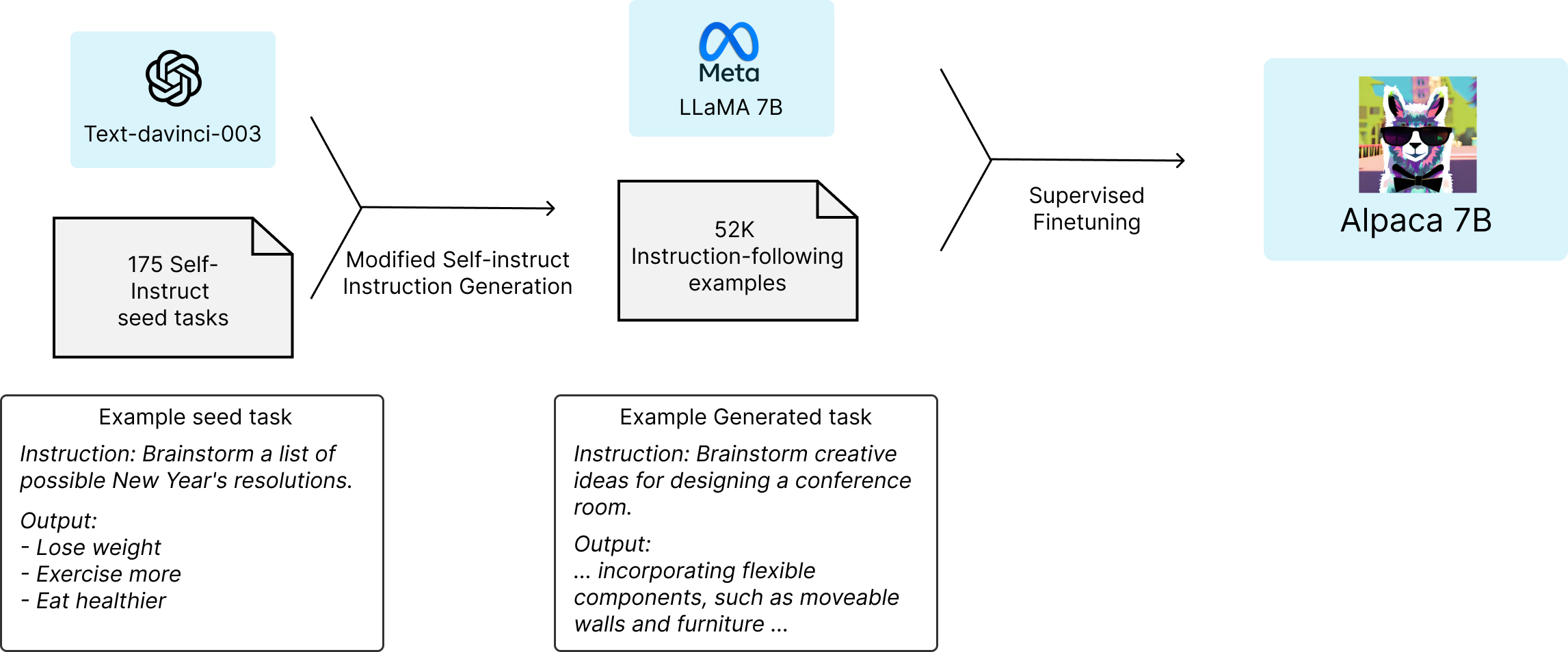
Llama 1 7B is a ≈7 billion parameter causal language model trained on 1 trillion tokens from various mostly English sources. It's described in the Llama 1 paper. Llama 2 is a similar model, just trained on more data (and with some slight tweaks to the architecture for larger models).
The Alpaca dataset is composed of triples of (instruction, input, output), where the instruction is a prompt describing the task. A bit less than 40% of the examples have inputs, and the rest are just the instruction and output.
Here are some example inputs, instructions, and outputs:
| Instruction | Input | Output |
|---|---|---|
| Translate the following phrase into French. | I love you. | Je t'aime. |
| Compute the area of a rectangle with length 10cm and width 5cm. | The area of the rectangle is 50 cm2. | |
| Classify the following statement as true or false. | The Supreme Court is the highest court in the US. | True |
| Name two types of desert biomes. | Two types of desert biomes are xeric and subpolar deserts. |
Not all of the examples make a lot of sense, some are just plain wrong, and some are weird. (The dataset was generated by an LLM after all.) But it's a good example of the kind of data you might want to fine tune on.
Because Llama is a causal language model, we need to do some preprocessing to turn the pairs/triples into a single sequence. The usual thing is to interpolate the strings into a prompt that provides some context/guidance to the LM. We'll have two prompts, depending on whether or not there's an input or just an instruction and output.
For example, the first example above would be turned into:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Translate the following phrase into French.
### Input:
I love you.
### Response:
Je t'aime.
While the second would be:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Compute the area of a rectangle with length 10cm and width 5cm.
### Response:
The area of the rectangle is 50 cm2.
From there, the original Alpaca script masks out the loss for all tokens before the start of the output. This gets the model to learn to mimic outputs conditioned on inputs, rather than getting the model to learn the prompts and inputs along with the outputs.
Rather than going through the code first, we'll jump straight to running the script. We'll cover the code in the Code Walkthrough section below.
!!! tip
Make sure you go through either the [GPU](./Getting-Started-GPU.md) or [TPU](./Getting-Started-TPU-VM.md) setup, depending on what you want to use.
Follow the instructions in the Getting Started with GPUs guide to create a conda environment or virtualenv and to install JAX with CUDA. Then, if you haven't already done so, clone the Levanter repository and install it in editable mode:
git clone https://github.com/stanford-crfm/levanter.git
cd levanter
pip install -e .You'll also want to log into WANDB.
wandb loginTo use Llama 2, you'll need to request access to the model from Llama 2's Hugging Face page. Then, you'll need to log into the Hugging Face CLI:
huggingface-cli loginThe example commands below demonstrate how to launch a training job on a node with 8 A100 GPUs, but should work for other single node GPU configurations. For example, we've also tested Alpaca replication with a node of 8 RTX 6000 Ada Generation 49.1GB GPUs. (Levanter works best with Ada or later generation NVIDIA GPUs.)
To replicate Alpaca, you can run the following command:
python examples/alpaca/alpaca.py --config_path levanter/examples/alpaca/alpaca.yamlTo use Llama 2:
python examples/alpaca/alpaca.py --config_path levanter/examples/alpaca/alpaca-llama2.yamlAlternatively:
python examples/alpaca/alpaca.py --config_path levanter/examples/alpaca/alpaca-llama2.yaml --model_name_or_path meta-llama/Llama-2-7b-hf!!! warning
Fine-tuning a 7B parameter model needs **a lot** of accelerator memory: you will need more than 80GB of GPU memory in
aggregate to run this job. Because Levanter makes heavy use of FSDP, you can use several smaller cards.
If you don't have enough memory, you can try reducing the `train_batch_size` or the `per_device_parallelism` in
the config.
At some point the run will spit out a WandB link. You can click on that to see the training progress. There's not a ton to see there (yet), but you can see the training loss go down over time.
On an 8xA100 box, training should take about ~3.5 hours, similar to the original Alpaca script. It should take ~8.5 hours on 8 RTX 6000 Ada Generation GPUs.
For TPUs, please follow the instructions in the Getting Started with TPUs. Once you have, you can run something like this to get a v3-32 TPU VM:
bash infra/spin-up-vm.sh llama-32 -z us-east1-d -t v3-32 --preemptibleYou might need to change the zone and/or the TPU type depending on what's available. You can also use preemptible TPUs if you want to save money (or that's what your quota is). Training Alpaca should work on a v3-8, but we don't have any of those.
Launching the run on TPU is a bit more complex because you need to specify a lot of paths to GCS buckets. You will also likely need to run the command on multiple machines, because a v3-32 VM is actually 4 distinct machines, each controlling 8 TPUs.
This is what the command looks like:
export GCS_BASE="gs://<somewhere>"
gcloud compute tpus tpu-vm ssh llama-32 --zone us-east1-d --worker=all \
--command="WANDB_API_KEY=${YOUR TOKEN HERE} \
HUGGING_FACE_HUB_TOKEN=${YOUR TOKEN HERE} \
bash levanter/infra/run.sh python \
levanter/examples/alpaca/alpaca.py \
--config_path levanter/examples/alpaca/alpaca-llama2.yaml \
--data_cache_dir ${GCS_BASE}/data \
--trainer.checkpointer.base_path ${GCS_BASE}/ckpts \
--hf_save_path ${GCS_BASE}/hf_ckptsIf you're using preemptible or TRC TPUs, you'll want to add --trainer.id <some id> to the command line.
Alternatively, you can use the babysitting script to automatically restart the
VM and job if it gets preempted. (It will also set a run id automatically.) That would look like this:
infra/babysit-tpu-vm.sh llama-32 -z us-east1-d -t v3-32 --preemptible -- \
WANDB_API_KEY=${YOUR TOKEN HERE} \
HUGGING_FACE_HUB_TOKEN=${YOUR TOKEN HERE} \
bash levanter/infra/run.sh python \
levanter/examples/alpaca/alpaca.py \
--config_path levanter/examples/alpaca/alpaca-llama2.yaml \
--trainer.checkpointer.base_path gs://<somewhere> \
--hf_save_path gs://<somewhere> \You should see a link to the WandB run in the output. You can click on that to see the training progress. Similar to an 8xA100 box, training should take about ~3.5 hours on a v3-32.
That should be all you need to run the script and replicate Alpaca.
However, if you want to customize the script, you can do so by modifying the config.
We have two configs for Alpaca: one for Llama 1 and one for Llama 2. The only difference is the model_name_or_path field.
# cf https://github.com/tatsu-lab/stanford_alpaca#fine-tuning
data: tatsu-lab/alpaca
model_name_or_path: huggyllama/llama-7b
trainer:
mp: p=f32,c=bfloat16 # Mixed precision training with fp32 parameters/optimizer state and bf16 activations
wandb:
project: "levanter-alpaca"
num_train_steps: 1218 # 128 * 1218 = 155904, which is almost but not quite 3 epochs, which is what alpaca did
train_batch_size: 128
optimizer:
learning_rate: 2e-5
weight_decay: 0.0
prompts:
# |- means multiline string, keeping all but the final newline
prompt_input: |-
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
prompt_no_input: |-
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:This config uses mixed fp32/bf16 precision and sets the number of training steps to be roughly 3 epochs. It sets up the optimizer
to use a learning rate of 2e-5 and no weight decay. trainer.per_device_parallelism is roughly equivalent to HF's
per_device_train_batch_size.
The Llama 2 config is identical, except for the model id. If you haven't already, go to Llama 2's Hugging Face page and request access to the model.
Once you have access, go to Hugging Face's Tokens page to get an API token. You'll need to provide this to the TPU VM as an environment variable. (We'll show you how to do this later.)
The script in this tutorial is designed for Alpaca, but it should work for any single-turn instruction-following task. For instance, to train a Code Alpaca model, you could modify the config like this:
data: lucasmccabe-lmi/CodeAlpaca-20k # a dataset on the Hugging Face hub
data_cache_dir: code_alpaca_cache # some path to store the cacheThe dataset can also be a path to a JSON or JSONL file, or compressed versions of those.
You can also change the model_name_or_path field to point to the model you want to use. This
can be any Hugging Face model, or a path to a local checkpoint. Currently, Levanter supports GPT-2, Llama, MPT, and
Backpack checkpoints.
model_name_or_path: "meta-llama/Llama-2-7b-chat-hf"Or on the command line:
python examples/alpaca/alpaca.py --config_path levanter/examples/alpaca/alpaca.yaml --model_name_or_path "meta-llama/Llama-2-7b-chat-hf"If you want to use your own prompts, you can modify the prompts field. By default, the prompts are set to be the same
as the original Alpaca, but you can change them to whatever you want. They are formatted using Python's
format strings, meaning you can use {instruction} and {input}.
You should have two prompts: one for when there's an input and one for when there isn't. For example, here is
a more minimal prompt:
prompts:
prompt_input: |-
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_no_input: |-
### Instruction: {instruction}
### Output:We use YAML's multiline string syntax to make the prompts easier to read. You can also specify a path to a json file containing the prompts if you'd prefer.
On a single machine, you can just modify the config and run the script. On TPU, however, you'll need to upload the config to a Google Cloud Storage bucket so that all the workers can access it. You can do this with:
gsutil cp my-config.yaml gs://<somewhere>/my-config.yamlAnd then using --config_path gs://<somewhere>/my-config instead of --config_path levanter/examples/alpaca/train-alpaca.yaml
in the command line. Levanter knows how to read from Google Cloud Storage, so you don't need to do anything else.
Say you save the above Alpaca training command as a bash script called train_alpaca.sh. Then
you could launch a training job on a slurm cluster with srun as follows:
srun --account=nlp --cpus-per-task=32 --gpus-per-node=8 --mem=400G --open-mode=append --partition=sphinx --nodes=1 --pty bash train_alpaca.sh(This is for the Stanford NLP Cluster. Adjust as necessary for your cluster.)
When you're done, you can download the Hugging Face model with:
gsutil cp -r gs://<somewhere>/<run_id>/step-<something> ./my-alpacaThe model should work out-of-the-box as a Hugging Face model. For a quick test, you can use it like this:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("./my-alpaca")
tokenizer = AutoTokenizer.from_pretrained("./my-alpaca")
instruction = "Translate the following phrase into French."
input = "I love you."
input = ("Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
f"### Instruction:\n {instruction}\n### Input:\n {input}\n### Response: \n")
input_ids = tokenizer(input, return_tensors="pt")["input_ids"]
output_ids = model.generate(input_ids, do_sample=True, max_length=100, num_beams=5, num_return_sequences=5)
for output_id in output_ids:
print(tokenizer.decode(output_id, skip_special_tokens=True))You can also hook it up to your favorite inference server for faster inference.
In this section, we'll walk through the code that we use to fine-tune Llama 1 on Alpaca. You can find the full script here.
If you want to just run the script, you can skip to the Setup section.
Levanter's existing main entry points are designed for "pure" causal language modeling, where you have a single sequence and don't have any prompts or custom formatting. So we'll instead write a custom script that does the following:
- Preprocesses the dataset into a single sequence, interpolating prompts as we go. We'll also construct a
loss_maskand do any padding. - Loads the model and resizes the vocabulary to match the tokenizer.
- Runs the training loop.
- Export the final model to Hugging Face.
We'll use the original Alpaca script as a reference. We only cover preprocessing in this tutorial. You can look at the script if you want more information.
The first step is to get the dataset. We'll use the Hugging Face Dataset version to do this. (You can also download it directly from the dataset page, but Levanter's integration with Hugging Face datasets means we don't need to do that.)
def _get_data_source(path_or_id):
"""The original alpaca.py used a json file, but it's since been moved to the HF dataset hub. You can use any
dataset that's compatible with the structure of the alpaca dataset."""
if fsspec_utils.exists(path_or_id):
return JsonDataset([path_or_id])
else:
return levanter.data.datasource_from_hf(path_or_id, split="train")Preprocessing in Levanter typically happens in two phases:
- creating an on-disk cache of the "heavy" preprocessing, like tokenization; and
- transforming examples from the cache into the examples that the model expects.
Here's the first phase, where we create the cache. We basically want to interpolate the prompt with the input and instructions, and then tokenize the result. We also want to keep track of the length of the input, so we can mask out the loss appropriately.
def mk_dataset(config: TrainArgs, tokenizer: transformers.PreTrainedTokenizerBase):
dataset = _get_data_source(config.data)
prompts = get_prompts(config.prompts)
def preprocess(batch):
def format_example(ex):
if ex.get("input", "") == "":
return prompts["prompt_no_input"].format_map(ex)
else:
return prompts["prompt_input"].format_map(ex)
sources = [format_example(example) for example in batch]
targets = [f"{example['output']}{tokenizer.eos_token}" for example in batch]
# TODO: this seems pretty wasteful since you end up tokenizing twice, but it's how the original code does it.
examples = [s + t for s, t in zip(sources, targets)]
sources_tokenized = tokenizer(sources, return_tensors="np", padding=False, truncation=True)
examples_tokenized = tokenizer(examples, return_tensors="np", padding=False, truncation=True)
source_lens = [len(s) for s in sources_tokenized["input_ids"]]
return {
"input_ids": examples_tokenized["input_ids"],
"source_lens": source_lens,
}
dataset = dataset.map_batches(preprocess, batch_size=128, num_cpus=num_cpus_used_by_tokenizer(tokenizer))
dataset = dataset.build_or_load_cache(config.data_cache_dir, await_finished=True)
dataset = SupervisedDataset(dataset, tokenizer, mask_inputs=config.mask_inputs)
return datasetSupervisedDataset is a class that we'll define later that does the final transformation from the cache to the
LmExample objects that the model expects. LmExamples look like this:
class LmExample(eqx.Module):
tokens: hax.NamedArray
loss_mask: hax.NamedArray
attn_mask: AttentionMask = AttentionMask.causal()So we need to populate the first two fields. tokens is the input sequence, and loss_mask is a boolean mask
that tells the model which tokens to compute the loss for. (We mask out the loss for everything before the start
of the output.)
class SupervisedDataset(Dataset[LmExample]):
def __init__(self, preproc_dataset, tokenizer):
self.preproc_dataset = preproc_dataset
self.tokenizer = tokenizer
def __iter__(self):
for ex in self.preproc_dataset:
# annoyingly, pad expects things to be batched so we have to prepend a batch axis
ex = self.tokenizer.pad(
{k: np.expand_dims(v, 0) for k, v in ex.items()}, return_tensors="np", padding="max_length"
)
ex = {k: v[0] for k, v in ex.items()}
input_ids = hax.named(ex["input_ids"], "position")
# mask out padding and anything before the start of the target
Pos = input_ids.resolve_axis("position")
loss_mask = hax.arange(Pos) >= ex["source_lens"]
# don't predict the padding
targets = hax.roll(input_ids, -1, Pos)
loss_mask = loss_mask & (targets != self.tokenizer.pad_token_id)
yield LmExample(input_ids, loss_mask)The rest is boilerplate: setting up the model, optimizer, and trainer, and then running the training loop. We'll skip over that in this tutorial, but you can see the full script here if you want to see how it works.
That's it for this tutorial: you should now be able to fine-tune Llama 1 or Llama 2 on Alpaca or any other single-turn instruction-following task. If you want to learn more about Levanter, check out the Levanter docs or the Levanter repo. For discussion, you can find us on Discord.
Let us know what you'd like to see next!