This is an absurd project.
It implements a backend for sql.js (sqlite3 compiled for the web) that treats IndexedDB like a disk and stores data in blocks there. That means your sqlite3 database is persisted. And not in the terrible way of reading and writing the whole image at once -- it reads and writes your db in small chunks.
It basically stores a whole database into another database. Which is absurd.
IndexedDB is not a great database. It's slow, hard to work with, and has very few advantages for small local apps. Most cases are served better with SQL.
It works absurdly well. It consistently beats IndexedDB performance up to 10x:
Read performance: doing something like SELECT SUM(value) FROM kv:

Write performance: doing a bulk insert:
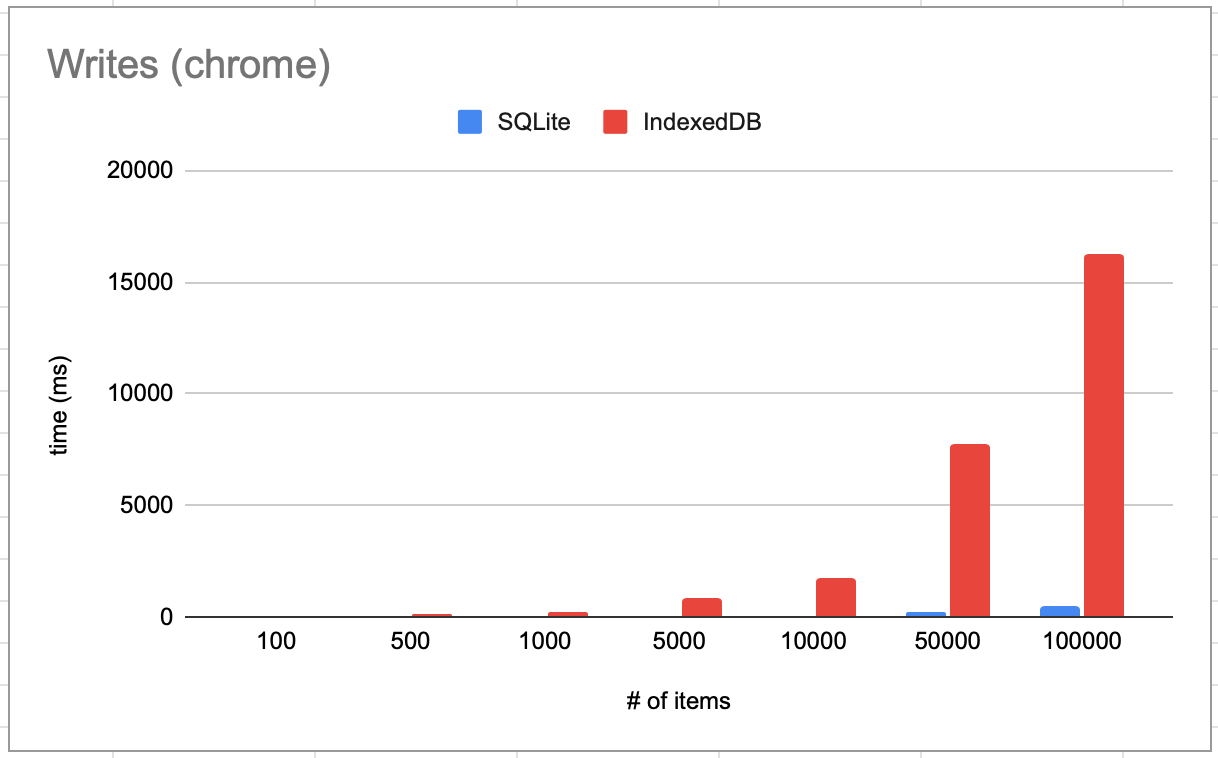
Why? It's simple once you think about it: since we are reading/writing data in 4K chunks (size is configurable), we automatically batch reads and writes. If you want to store 1 million objects into IDB, you need to do 1 million writes. With this absurd backend, it only needs to do ~12500 writes.
Usually when doing this kind of thing, there is a serious downside. But in this case, there isn't really. We get access to tons of features we didn't have before: views, full-text search, proper indexes, anything sqlite3 can do. It's a win-win.
The only real downside is you have to download a 1MB WebAssembly file. That might be a non-starter for you, but for any real apps that's fine.
There's one catch: it requires SharedArrayBuffer. Safari is the last browser to not enable it yet, but it's going to. In other browsers you need some special headers to enable it, but this is fine. In the future it will be available in all browsers.
This is very early stages, but first you install the packages:
yarn add @jlongster/sql.js absurd-sql.js-backend
Right now you need to use my fork of sql.js, but I'm going to open a PR and hopefully get it merged. The changes are minimal.
The following code will get you up and running:
import initSqlJS from '@jlongster/sql.js';
import { SqliteFS } from 'absurd-sql.js-backend';
import IndexedDBBackend from 'absurd-sql.js-backend/dist/indexeddb-backend');
async function run() {
// Initialize sql.js (loads wasm)
let SQL = await initSqlJS();
// Create the backend and filesystem
let backend = new IndexedDBBackend(4096);
let BFS = new SqliteFS(SQL.FS, backend);
// For now, we need to initialize some internal state. This
// API will be improved
SQL.register_for_idb(BFS);
await BFS.init();
// Mount the filesystem
FS.mount(BFS, {}, '/blocked');
let db = new SQL.Database('/blocked/db.sqlite', { filename: true });
// Always use a memory journal; writing it makes no sense
db.exec('PRAGMA journal_mode=MEMORY;')
// Use sqlite and never lose data!
}If you look in your IndexedDB database, you should see something like this:

I will write this out more later, but there are many fun tricks that make this work:
The biggest problem is when sqlite does a read or write, the API is totally synchronous because it's based on the C API. Accessing IndexedDB is always async, so how do we get around that?
We spawn a read/write process and give it a SharedArrayBuffer and then use the Atomics API to communicate via the buffer. For example, our backends writes a read request into the shared buffer, and the worker reads it, performs the read async, and then writes the result back.
The real magic is the Atomics.wait API. It's a beautiful thing. When you call it, it completely blocks JS until the condition is met. You use it to wait on some data in the SharedArrayBuffer, and this is what enables us to turn the async read/write into a sync one. The backend calls it to wait on the result from the worker and blocks until it's done.
IndexedDB has an awful behavior where it auto-commits transactions once the event loop is done processing. This makes it impossible to use a transaction over time, and requires you to create a new one if you are doing many reads over time. Creating a transaction is super slow and this is a massive perf hit.
However, Atomics.wait is so great. We also use it in the read/write worker to block the process which keeps transactions alive. That means while processing requests from the backend, we can reuse a transaction for all of them. If 1000 reads come through, we will use the same readonly transaction for all of them, which is a massive speedup.
Because we can keep a transaction for reads over time, we can use IndexedDB cursors to iterate over data when handling sequential read requests. There's a lot of interesting tradeoffs here because opening a cursor is actually super slow in some browsers, but iterating is a lot faster than many get requests. This backend will intelligently detect when several sequential reads happen and automatically switch to using a cursor
We fully embrace IndexedDB transaction semantics to ensure correct ordering of read/writes. We map sqlite's lock/unlock requests to transactions in a way that works (still needs to be 100% verified), and the best thing about this is a database can never leave a lock open.
Browsers already handle terminating IDB transactions in weird situations. Because we only rely on IDB transactions, our locks will get properly terminated as well.
If you look at the demo, we insert 1,000,000 items into a database and scan through all of them with a SELECT COUNT(*) FROM kv). This causes a lot of reads. We've recorded a lot of statistics for how IDB performs across browsers and will write out more soon.
For now, here are a couple things. This is a graph of all the reads recorded during that SQL query. The X axis is the time at which the read finished (ms), and Y axis is the time the read took (ms). There are a total of ~12500 reads.
Chrome has a p50 read time of .280ms and a total time of ~4.2s:

Firefox has a p50 read time .101 and a total time of ~.1.8s:

Look how nicely consistent that is.
The demo works in the latest version of Safari Technical Preview if you enable SharedArrayBuffer, but unfortunately high resolution timers are not available. That's sad because Safari seem to have great perf, similar to Firefox. Chrome is the real slow one here.
I haven't tried other browsers.
We should run these stats with a lot of other types of queries as well, and I'll do that in the future.